catalogue
1. Write algorithms to solve sequence transformation
1.1 implementation of non template functions
1.2 template function implementation
preface
This experiment will study the standard template library in C + + and write relevant test programs for practice.
Tip: the following is the main content of this article. The following cases can be used for reference
1, Experimental content
1. Write your own algorithms and functions, and combine containers and iterators to solve sequence transformation (such as inversion, square and cube), pixel transformation (binarization, gray stretching);
2. Use set to store student information and add, delete, modify and query;
3. Input a string, count the number of occurrences of each character with map, and output the character and its corresponding number.
2, Experimental process
1. Write algorithms to solve sequence transformation
1.1 implementation of non template functions
void transInv(int a[],int b[],int nNum) //Negate element
{
for(int i=0;i<nNum;i++)
{
b[i] = -a[i];
}
}
void transSqr(int a[],int b[],int nNum) //Square elements
{
for(int i=0;i<nNum;i++)
{
b[i] = a[i]*a[i];
}
}
void transPow(int a[],int b[],int nNum) //Cube elements
{
for(int i=0;i<nNum;i++)
{
b[i] = a[i]*a[i]*a[i];
}
}
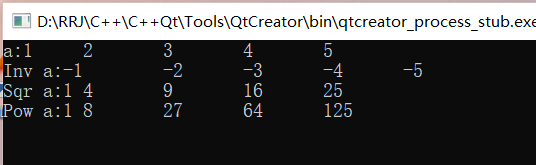
void TestTrans()
{
const int N=5;
int a[N] = {1,2,3,4,5};
outputCont("a",cout,a,a+N);
int b[N];
vector<double> vb(N);
transInv(a,b,N);
outputCont("Inv a",cout,b,b+N);
transSqr(a,b,N);
outputCont("Sqr a",cout,b,b+N);
transPow(a,b,N);
outputCont("Pow a",cout,b,b+N);
transInvT(a,b,N);
}Operation results:
1.2 template function implementation
template <typename T>
void transInvT(T a[],T b[],int nNum) //Negate element
{
for(int i=0;i<nNum;i++)
{
b[i] = -a[i];
}
}
template <typename T>
void transSqrT(T a[],T b[],int nNum) //Square elements
{
for(int i=0;i<nNum;i++)
{
b[i] = a[i]*a[i];
}
}
template <typename T>
void transPow(T a[],T b[],int nNum) //Cube elements
{
for(int i=0;i<nNum;i++)
{
b[i] = a[i]*a[i]*a[i];
}
}
template<typename T>
T InvT(T a)
{
return -a;
}
template <typename inputIter,typename outputIter,typename MyOperator>
void transInvT(inputIter begInput,inputIter endInput,outputIter begOutput,MyOperator op) //Negate element
{
for(;begInput!=endInput;begInput++,begOutput++)
{
//*begOutput = -(*begInput);
*(begOutput) = op(*begInput);
}
}
template <typename T>
void outputCont(string strName,ostream& os,T begin,T end) //Output element
{
os<<strName<<":";
for(;begin!=end;begin++)
{
os<<*begin<<"\t";
}
os<<endl;
}
template<typename T>
class MyThreshold
{
public:
int _nThreshold;
MyThreshold(int n=128):_nThreshold(n){}
int operator()(T val)
{
return val<_nThreshold?0:1; //Less than_ nThreshold returns 0
}
};
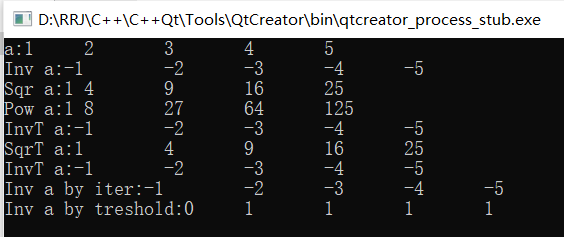
void TestTrans()
{
const int N=5;
int a[N] = {1,2,3,4,5};
outputCont("a",cout,a,a+N);
int b[N];
vector<double> vb(N);
transInv(a,b,N);
outputCont("Inv a",cout,b,b+N);
transSqr(a,b,N);
outputCont("Sqr a",cout,b,b+N);
transPow(a,b,N);
outputCont("Pow a",cout,b,b+N);
transInvT(a,b,N);
outputCont("InvT a",cout,b,b+N);
transSqrT(a,b,N);
outputCont("SqrT a",cout,b,b+N);
transInvT(a,a+N,b,InvT<int>);
outputCont("InvT a",cout,b,b+N);
transInvT(a,a+N,vb.begin(),InvT<int>); //Store the negative result into the container vb
outputCont("Inv a by iter",cout,vb.begin(),vb.end()); //Output results from container
//See how many of a group of data are less than 2, which can be used for image binarization. The pixels are divided into two parts according to the threshold
transInvT(a,a+N,vb.begin(),MyThreshold<int>(2));
outputCont("Inv a by treshold",cout,vb.begin(),vb.end());
}
Operation results:
1.3 sort() function
The Sort function is included in the c + + standard library whose header file is #include < algorithm > (you don't need to know how to implement the sorting method in the standard library, as long as the desired result appears!)
The Sort function has three parameters:
The first is the starting address of the array to be sorted.
The second is the end address (the last address to sort)
The third parameter is the sorting method, which can be from large to small or from small to large. The third parameter can not be written. At this time, the default sorting method is from small to large.
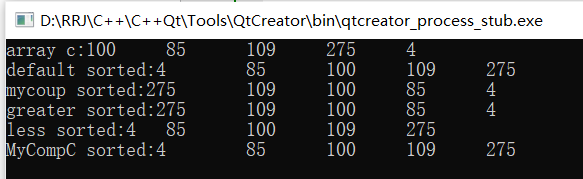
void TestSort()
{
const int N = 5;
int c[N] = {100,85,109,275,4};
outputCont("array c",cout,c,c+N);
sort(c,c+N); //The default is to sort in ascending order
outputCont("default sorted",cout,c,c+N);
//The sort function is contained in the #include < algorithm > standard library. The sort() function has three parameters, which are the start address, end address and sorting method of the data to be sorted
sort(c,c+N,mycoup<int>); //The template function used for comparison is used as the third parameter to specify the sorting method so that it is arranged in descending order
outputCont("mycoup sorted",cout,c,c+N);
//The standard library template class, in the #include < functional > library, indicates that the built-in types are sorted from large to small, and less indicates sorting from small to large
sort(c,c+N,greater<int>());
outputCont("greater sorted",cout,c,c+N);
sort(c,c+N,less<int>());
outputCont("less sorted",cout,c,c+N);
sort(c,c+N,MyCompC<int>()); //Custom template class
outputCont("MyCompC sorted",cout,c,c+N);
}
template <typename T>
bool mycoup(T a,T b)
{
return a>b;
}
template <typename T>
class MyCompC
{
public:
bool operator()(const T& x, const T& y) const
{
return x<y; //Ascending, x > y: descending
}
};Operation results:
2. Container test
Containers in c + + include "sequential storage structure" and "associated storage structure". The former includes vector, list, deque, array, string and forward_ List, all sequential containers provide the ability to quickly access elements in sequence, including set,map, etc.
Associative containers are fundamentally different from sequential containers: Elements in associative containers are saved and accessed by keywords. In contrast, elements in a sequential container are saved and accessed sequentially according to their location in the container.
Associated containers do not support position dependent operations for sequential containers. The reason is that the elements in the associated container are stored according to keywords, and these operations have no meaning to the associated container. Moreover, associative containers do not support constructors or insert operations, which accept an element value and a quantity value. The binary search is used in the set search, that is, if there are 16 elements, the result can be found by comparing at most 4 times, and there are 32 elements, the result can be compared at most 5 times. What about 10000? The maximum number of comparisons is log10000, and the maximum number is 14. What if it is 20000 elements? No more than 15 times. You see, when the amount of data is doubled, the search times are only one more time and 1 / 14 more search time. Therefore, the insertion and search speed of set is very fast and will not be reduced due to the increase of data.
set has two characteristics:
(1) The elements in set are sorted;
(2) The elements in the set are unique and have no duplicates.
Next, use vector and set to store student information and add, delete, modify and query.
2.1 vector storage
class studentInfo{
public:
studentInfo(string strNo,string strName)
{
_strNo = strNo;
_strName = strName;
}
string _strNo;
string _strName;
friend ostream& operator<<(ostream& os, const studentInfo& info)
{
os<<info._strNo<<":"<<info._strName;
return os;
}
friend bool operator<(const studentInfo& info1, const studentInfo& info2) //"<" overrides ascending sort
{
return info1._strNo<info2._strNo;
}
};
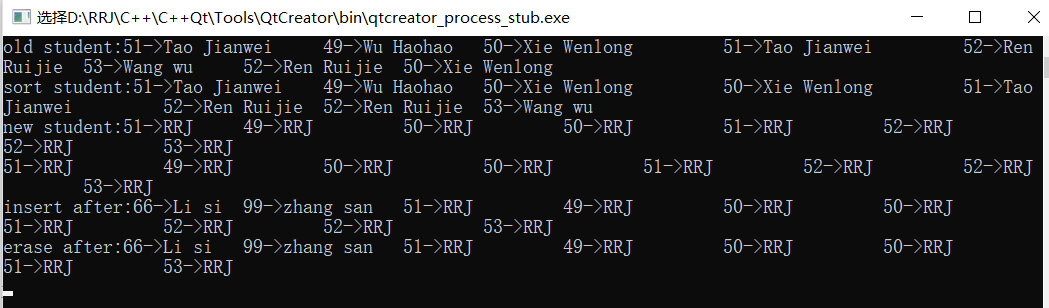
void TestVector()
{
vector<studentInfo> students;
students.push_back(studentInfo("51","Tao Jianwei"));
students.push_back(studentInfo("49","Wu Haohao"));
students.push_back(studentInfo("50","Xie Wenlong"));
students.push_back(studentInfo("51","Tao Jianwei"));
students.push_back(studentInfo("52","Ren Ruijie"));
students.push_back(studentInfo("53","Wang wu"));
students.push_back(studentInfo("52","Ren Ruijie"));
students.push_back(studentInfo("50","Xie Wenlong"));
outputCont("old student",cout,students.begin(),students.end());
vector<studentInfo>::iterator it = students.begin();
advance(it,2); //Skip two elements
sort(it,students.end()); //Sort in ascending order
outputCont("student",cout,students.begin(),students.end());
for(vector<studentInfo>::iterator it = students.begin();it!=students.end();it++)
{
it->_strName = "RRJ";
}
outputCont("new student",cout,students.begin(),students.end());
}Operation results:

You can see that there can be duplicate elements in the vector container, and the sorting will not produce errors due to the occurrence of duplicate elements.
insert() and erase(): insert and delete functions:
vector<studentInfo>::iterator te; //Declare an iterator
te=students.begin();
for(;te!=students.end();te++) //Iterator access vector container (lookup)
{
cout<<*te<<"\t";
}
cout<<endl;
//Adds an element x before the iterator points to the element in the vector
te = students.begin();
te = students.insert(te,studentInfo("99","zhang san"));
te = students.insert(te,studentInfo("66","Li si"));
outputCont("insert after",cout,students.begin(),students.end());
//Delete an element in the vector
for(vector<studentInfo>::iterator it = students.begin();it!=students.end();)
{
if(it->_strNo=="52")
it=students.erase(it); //When deleting, the erase function automatically points to the next location, so there is no need to delete++
else
it++; //When there is no deletion, the iterator + + can delete continuous elements
}
outputCont("erase after",cout,students.begin(),students.end());
//students.clear(); // Empty containerOperation results:
2.2 set storage
void TestSet()
{
vector<studentInfo> students;
students.push_back(studentInfo("51","Tao Jianwei"));
students.push_back(studentInfo("49","Wu Haohao"));
students.push_back(studentInfo("50","Xie Wenlong"));
students.push_back(studentInfo("51","Tao Jianwei"));
students.push_back(studentInfo("52","Ren Ruijie"));
students.push_back(studentInfo("53","Wang wu"));
students.push_back(studentInfo("52","Ren Ruijie"));
students.push_back(studentInfo("50","Xie Wenlong"));
set<studentInfo> studentSet(students.begin(),students.end());
outputCont("student set",cout,studentSet.begin(),studentSet.end());
//Add two elements, insert value and return pair pairing object
studentSet.insert(studentInfo("99","Xiao ming"));
studentSet.insert(studentInfo("66","Liu hua"));
studentSet.insert(studentInfo("77","Li hua"));
outputCont("insert after",cout,studentSet.begin(),studentSet.end());
//The return value is pair < set < int >:: iterator, bool >, bool indicates whether the insertion is successful (use second to indicate the second position of the return value),
//The iterator represents the insertion position (first represents the first position), if key_value is already in set, then the key represented by iterator_ The position of value in set.
//Judge whether the insertion is successful according to. second (Note: value cannot duplicate the element in the set container)
cout<<"insert(77,Li hua).second = ";
if(studentSet.insert(studentInfo("77","Li hua")).second)
{
cout<<"insert success"<<endl;
outputCont("insert studentset",cout,studentSet.begin(),studentSet.end());
}
else
cout<<"insert false"<<endl;
//Delete element
//Method 1: remove all elements whose element value is value in the set container
studentSet.erase(studentInfo("66","Liu hua"));
outputCont("first erase after",cout,studentSet.begin(),studentSet.end());
//Method 2: remove the element in pos position without return value
set<studentInfo>::iterator iter = studentSet.begin();
studentSet.erase(iter);
outputCont("second erase after",cout,studentSet.begin(),studentSet.end());
//Modify the value of the element
for(set<studentInfo>::iterator it = studentSet.begin();it!=studentSet.end();it++)
{
if((it->_strNo)=="77")
{
studentSet.erase(studentInfo("77","Li hua"));
studentSet.insert(studentInfo("77","RRJ"));
}
}
outputCont("revise after",cout,studentSet.begin(),studentSet.end());
//Find element
//Method 1: count(value) returns the number of elements in the set object whose element value is value
cout<<"50,Xie Wenlong is count: "<<studentSet.count(studentInfo("50","Xie Wenlong"))<<endl;
//Method 2: find(value) returns the location of value. If it cannot be found, end() is returned
//Find will find set one by one. If the search is successful, an iterator pointing to the specified element will be returned. If it cannot be found, end() will be returned
cout<<"find (99,xiao ming):";
if(studentSet.find(studentInfo("99","Xiao ming"))!=studentSet.end())
{
cout<<"find it"<<endl;
}
//Clear set
studentSet.clear();
if(studentSet.empty())
{
cout<<"studentSet is NULL"<<endl;
}Operation results:
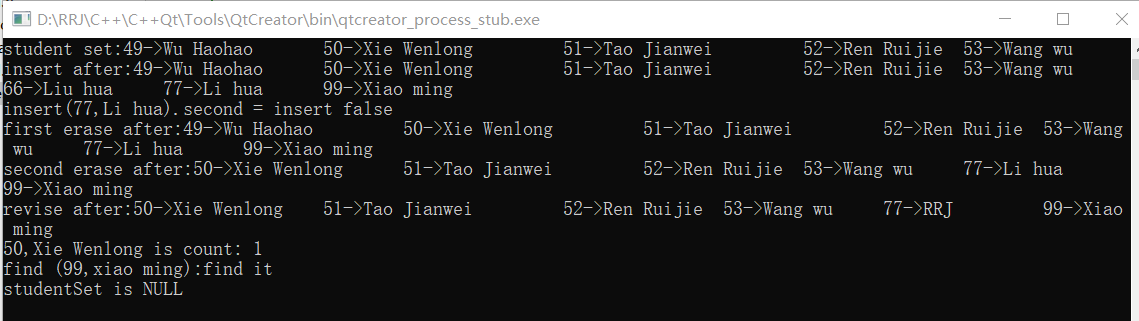
You can see that duplicate values are not allowed in set, and will be sorted automatically during insertion. And there are many standard functions to do Add, delete, modify, query and other related operations. The return value of the insert() function is pair < set < int >:: iterator, bool >, bool indicates whether the insertion is successful (second represents the second position of the return value when used), and iterator represents the insertion position (first represents the first position), if key_value is already in set, then the key represented by iterator_ Position of value in set; Judge whether the insertion is successful according to. Second (Note: value cannot be repeated with elements in the set container).
3. Map
map and set belong to single Association containers, so they are very similar in usage. Their main difference is that the element type of the set is the key itself, while the mapped element type is a binary composed of keys and additional data. In this way, when searching for an element according to the key in the collection, it is generally used to determine whether the element exists. When searching for an element according to the key in the mapping, in addition to determining its existence, the corresponding additional data can be obtained. Therefore, a common use of mapping is to find additional data based on keys. map provides one-to-one data processing. Key value pairs can be defined by themselves. The first is called keyword and the second is the value of keyword; map is automatically sorted internally.
Access through iterators
map can use it - > first to access the key and it - > second to access the value
Next, test the map, input a string, count the number of occurrences of each character with the map, and output the character and the corresponding number of occurrences
void TestMap()
{
map<string,int> stu;
stu["01"] = 100;
stu["06"] = 99;
stu["10"] = 98;
stu["08"] = 93;
stu["06"] = 90;
cout<<"old map:";
for(map<string,int>::iterator it=stu.begin();it!=stu.end();it++)
{
cout<<it->first<<":"<<it->second<<"\t";
}
cout<<endl;
//Add element
//Insert pair with insert function
stu.insert(pair<string,int>("20", 88));
// Insert value with insert function_ Type data
stu.insert(map<string,int>::value_type("30",96));
// Insert in array
stu["05"] = 86;
stu["07"] = 66;
stu["09"] = 60;
stu["40"] = 70;
stu["11"] = 85;
cout<<"insert after:";
for(map<string,int>::iterator it=stu.begin();it!=stu.end();it++)
{
cout<<it->first<<":"<<it->second<<"\t";
}
cout<<endl;
//Delete element
//Iterator deletion
map<string,int>::iterator it;
it = stu.find("05");
stu.erase(it);
//Keyword deletion
int n = stu.erase(""); //Returns 1 if deleted, 0 otherwise
if(n)
{
cout<<"erase succes"<<endl;
}
cout<<"erase after:";
for(map<string,int>::iterator it=stu.begin();it!=stu.end();it++)
{
cout<<it->first<<":"<<it->second<<"\t";
}
cout<<endl;
int len=stu.size(); //The number of times to get the map in the map
cout<<"len:"<<len<<endl;
//Delete with iterator range: empty the entire map
//stu.erase(stu.begin(), stu.end());
//Equivalent to mapStudent.clear()
map<char,int> s;
char c;
do{
cin>>c; //Enter next character
if(isalpha(c)) //Determine whether it is a letter
{
c=tolower(c); //Convert letters to lowercase
s[c]++; //Increase the frequency of the letter by 1
}
}while(c!='.');
for(map<char,int>::iterator iter=s.begin();iter!=s.end();iter++)
{
cout<<iter->first<<":"<<iter->second<<"\t";
}
cout<<endl;
}In the above procedures, the map can have the same value, but the key value must be unique, and its insertion and deletion of data are also very flexible. When counting the number of letters, directly use the "[]" operator to access the elements mapped to S. when a letter appears for the first time, it will automatically insert a new element into S and set its additional data to 0 (the value generated by int is 0). Each time s[c], the reference of the additional data of the corresponding element will be returned. The value of the additional data can be directly changed by using the "+ +" operator. Although the "[]" operator is convenient and intuitive to use, it can not completely replace insert,find and other functions, because it will automatically create new elements for new creation, so it can not judge whether there are elements with specified keys in the container.
Operation results:

The url used here is the data requested by the network.
summary
Through this experiment, I learned to use the functions of c + + standard library, test the set, map and vector containers, and access the iterator, but there are still some defects. For example, when modifying the element value in set, the program always reports an error, and the overload failure of the "=" operator has not been solved.