1, Experimental objectives:
Understand the impact of Cache on system performance
2, Experimental environment:
1. Personal computer (Intel CPU)
2. Ubuntu Linux operating system
3, Experiment contents and steps
1. Compile and run program A and record relevant data.
2. When the matrix size is not changed, compile and run program B and record relevant data.
3. Change the matrix size and repeat steps 1 and 2.
Through the above experimental phenomena, the causes of this phenomenon are analyzed.
Procedure A:
#include <sys/time.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc,char *argv[])
{
float *a,*b,*c, temp;
long int i, j, k, size, m;
struct timeval time1,time2;
if(argc<2) {
printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);
exit(-1);
} //if
size = atoi(argv[1]);
m = size*size;
a = (float*)malloc(sizeof(float)*m);
b = (float*)malloc(sizeof(float)*m);
c = (float*)malloc(sizeof(float)*m);
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
a[i*size+j] = (float)(rand()%1000/100.0);
b[i*size+j] = (float)(rand()%1000/100.0);
}
}
gettimeofday(&time1,NULL);
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
c[i*size+j] = 0;
for (k=0;k<size;k++)
c[i*size+j] += a[i*size+k]*b[k*size+j];
}
}
gettimeofday(&time2,NULL);
time2.tv_sec-=time1.tv_sec;
time2.tv_usec-=time1.tv_usec;
if (time2.tv_usec<0L) {
time2.tv_usec+=1000000L;
time2.tv_sec-=1;
}
printf("Executiontime=%ld.%06ld seconds\n",time2.tv_sec,time2.tv_usec);
return(0);
}//main
Procedure B:
#include <sys/time.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc,char *argv[])
{
float *a,*b,*c, temp;
long int i, j, k, size, m;
struct timeval time1,time2;
if(argc<2) {
printf("\n\tUsage:%s <Row of square matrix>\n",argv[0]);
exit(-1);
} //if
size = atoi(argv[1]);
m = size*size;
a = (float*)malloc(sizeof(float)*m);
b = (float*)malloc(sizeof(float)*m);
c = (float*)malloc(sizeof(float)*m);
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
a[i*size+j] = (float)(rand()%1000/100.0);
c[i*size+j] = (float)(rand()%1000/100.0);
}
}
gettimeofday(&time1,NULL);
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
b[i*size+j] = c[j*size+i];
}
}
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
c[i*size+j] = 0;
for (k=0;k<size;k++)
c[i*size+j] += a[i*size+k]*b[j*size+k];
}
}
gettimeofday(&time2,NULL);
time2.tv_sec-=time1.tv_sec;
time2.tv_usec-=time1.tv_usec;
if (time2.tv_usec<0L) {
time2.tv_usec+=1000000L;
time2.tv_sec-=1;
}
printf("Executiontime=%ld.%06ld seconds\n",time2.tv_sec,time2.tv_usec);
return(0);
}//main
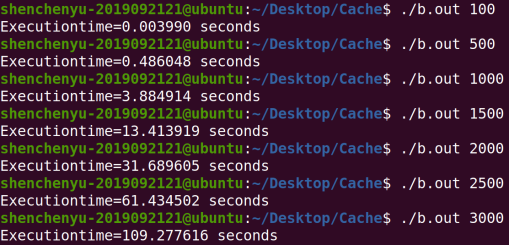
4, Experimental results and analysis
1. Use C language to realize the general algorithm of matrix (square matrix) product (program A), and fill in the following table:

analysis:
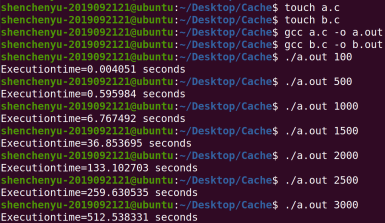
Core code:
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
c[i*size+j] = 0;
for (k=0;k<size;k++)
c[i*size+j] += a[i*size+k]*b[k*size+j];
}
}
The order of access parts of arrays a and b is:
You can see that the access order of b array does not conform to spatial locality.
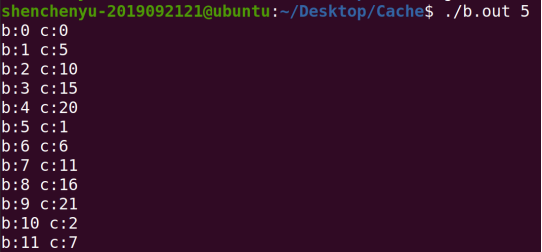
2. Program B is a matrix (square matrix) product optimization algorithm based on Cache. Fill in the following table:

analysis:
Core code:
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
b[i*size+j] = c[j*size+i];
}
}
The order of accessing parts of b and c arrays is:
Core code:
for(i=0;i<size;i++) {
for(j=0;j<size;j++) {
c[i*size+j] = 0;
for (k=0;k<size;k++)
c[i*size+j] += a[i*size+k]*b[j*size+k];
}
}
The order of access parts of arrays a and b is:
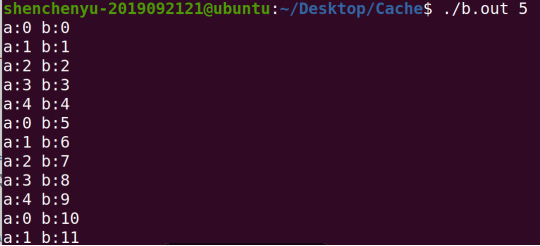
It can be seen that the array access order is in good compliance with spatial locality, which belongs to cache friendly c language code.
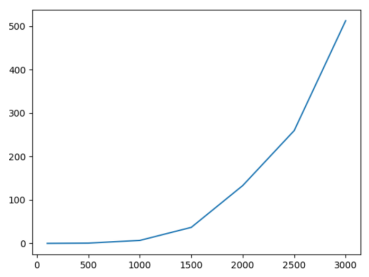
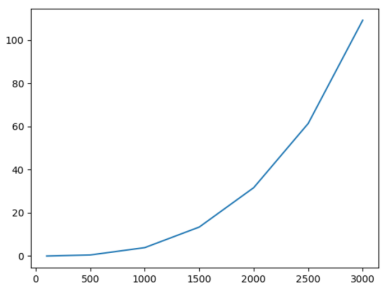
3. Optimized speedup

Definition of acceleration ratio: acceleration ratio = system time before optimization / system time after optimization;
The so-called acceleration ratio is the ratio of the time before optimization to the time after optimization. The higher the acceleration ratio, the more obvious the optimization effect.
analysis:
As can be seen from the figure below, generally speaking, the larger the size, the better the optimization effect on program B, that is, the higher the hit rate and the better the local space
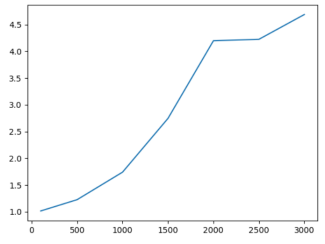
5, Experimental summary and experience
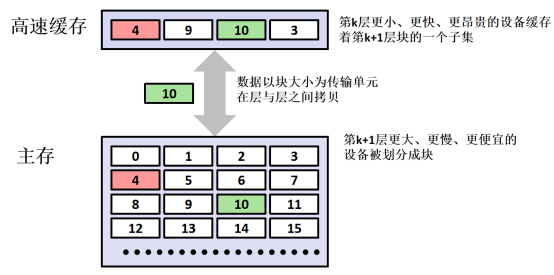
1. Through this experiment, we have a perceptual understanding of the principle of cache, that is, because of the speed gap between CPU and main memory, a one-level or multi-level cache is designed between CPU and main memory. The cache is SRAM (static random access memory). Because the cache clock cycle is significantly higher than main memory, it speeds up the speed of computer;
2. The data transmission between cache and main memory or between cache and cache takes block as the minimum unit, and the block stores data of multiple adjacent addresses. For example, there is an array of int type b[4][4] in the program. The size of the block is 16 bytes. When the array is used for the first time, for example, b[0][0], the block of b[0][0] in main memory will be put into the cache. Because the block stores adjacent data in main memory, it is likely to contain b[0][1], b[0][2] and b[0][3]. If the array is called in the order of b[0][1], b[0][2] and b[0][3], This improves the cache hit rate and reduces the clock cycle. If b[1][0], b[2][0] and b[3][0] are accessed in the order of b[1][0], b[2][0] and b[3][0], the blocks of b[0][0] may be replaced when the blocks of b[1][0], b[2][0] and b[3][0] are introduced. When the CPU uses b[0][1] again, it needs to copy the blocks of b[0][1] from the main memory, which reduces the hit rate of the cache and increases the time cycle.
3. Therefore, we write code that is more cache friendly and consistent with the locality principle to improve the execution efficiency of the code.