Before, I completed the caffe to pytorch of several networks.
refinenet https://www.cnblogs.com/yanghailin/p/13096258.html
refinedet https://www.cnblogs.com/yanghailin/p/12965695.html
The above is to extract the coffee weight and then transfer it to libtorch. The following is the conversion of the directly corresponding pytorch version to libtorch. A lot of post-processing is completed with libtorch. Later, colleagues also completed the direct conversion of coffee weight to libtorch.
Nothing unexpected. All the above are completed by compiling the python interface of caffe. However, the general engineering scenario is that we only use caffe c + +, and sometimes there is no corresponding Python project. Then compiling the python interface and calling it will have some trouble.
Later, I thought, why do we have to do this with one stone? Can't we run the forward c + + project directly with caffe?
In fact, it is OK, but the source code of caffe is complex and I can't understand it at the beginning.
This series of blogs directly use caffe's c + + project to directly extract weights, build the same pytorch network, and fill in caffe weights to directly run forward reasoning.
This is how I handle it. First, compile the cpu version of caffe lstm. You can debug in clion. I'm in / caffe_ocr/tools/caffe.cpp deleted the original caffe.cpp, and then replaced it with the code of lstm forward reasoning, which compiled the Caffe source code.
Then I can interrupt the debugging.
caffe source code is a highly abstract project. Layer is used as the base class, and all other algorithm modules are derived from this layer.
Net class is a very important class. It manages and coordinates the whole network. In net class, you can get all the intermediate feature map results of the network and the corresponding weight of each layer.
Because my purpose is to transfer lstm to pytorch. It is very important to understand the implementation method of lstm operator. If you don't know at first sight, you'll look straight at it. The implementation of lstm is really complex! It has its own net class!!! Bidirectional lstm is the integration of two net classes, derived from the class RecurrentLayer.
The lstm principle is the six formulas. You can read this blog:
https://www.jianshu.com/p/9dc9f41f0b29
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
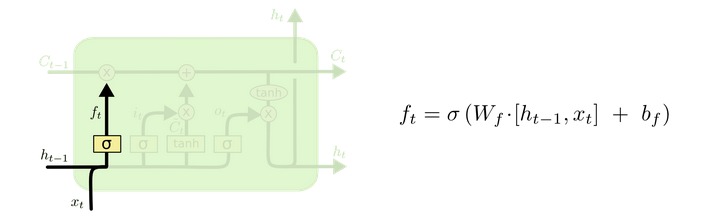
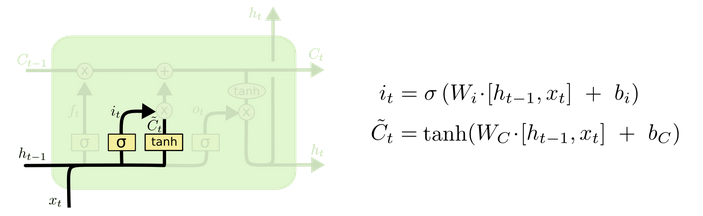


This article does not intend to explain the source code of caffe and the specific implementation of lstm. There will be a chance to open a blog alone later.
This paper explains how to extract the weight of each layer from caffemodel. Weights are generally a large matrix, such as [64,3,7,7]. These weights need to be saved for Python to read.
At the beginning, I also thought in c + + about how to process matrices as easily as Python numpy. I thought about using json, xml or directly using the blob class of cafe, but I can't use it! proto with caffe should be OK, but it won't be used.
Then use the most direct method, that is, directly save the weights one by one in the local TXT. The file name is directly the layer name of the layer. For example, if the layer name is conv1, it is conv1_weight_0.txt,conv1_weight_1.txt. The first row places shapes, such as 64,3,7,7.
Since the weight also exists in the form of blob, I added a function to save the BLOB data to the local txt in the blob source code. You only need to provide the saved address. As follows:
void save_data_to_txt(const string path_txt,bool b_save_shape = true)
{
std::ofstream fOut(path_txt);
if (!fOut)
{
std::cout << "Open output file faild." << std::endl;
}
if(b_save_shape)
{
for(int i=0;i<shape_.size();i++)
{
fOut << shape_[i];
if(i == shape_.size()-1)
{
fOut<<std::endl;
}else
{
fOut<<",";
}
}
}
const Dtype* data_vec = cpu_data();
for (int i = 0; i < count_; ++i) {
fOut << data_vec[i] << std::endl;
}
fOut.close();
}
Next, go directly to my code and save the weight of each layer to txt as follows:
std::cout<<"\n\n\n\n============2021-11-18======================================="<<std::endl;
shared_ptr<Net<float> > net_ = classifier.get_net(); //Here is the Net class from the forward class
vector<shared_ptr<Layer<float> > > layers = net_->layers(); //Get the pointer of Layer operator of each Layer
vector<shared_ptr<Blob<float> > > params = net_->params();//Get all weight pointers
vector<vector<Blob<float>*> > bottom_vecs_ = net_->bottom_vecs();//Get all bottom feature map s
vector<vector<Blob<float>*> > top_vecs_ = net_->top_vecs();//Get all the top feature map s / / pay attention to the layers and the bottom_vecs_ top_vecs_ They all correspond one by one
std::cout<<"size layer=" << layers.size()<<std::endl;
std::cout<<"size params=" << params.size()<<std::endl;
string path_save_dir = "/data_1/Yang/project/save_weight/";
for(int i=0;i<layers.size();i++)
{
shared_ptr<Layer<float> > layer = layers[i];
string name_layer = layer->layer_param().name();//Current layer name
std::cout<<i<<" layer_name="<<name_layer<<" type="<<layer->layer_param().type()<<std::endl;
int bottom_name_size = layer->layer_param().bottom().size();
std::cout<<"=================bottom================"<<std::endl;
if(bottom_name_size>0)
{
for(int ii=0;ii<bottom_name_size;ii++)
{
std::cout<<ii<<" ::bottom name="<<layer->layer_param().bottom(ii)<<std::endl;
Blob<float>* ptr_blob = bottom_vecs_[i][ii];
std::cout<<"bottom shape="<<ptr_blob->shape_string()<<std::endl;
}
} else{
std::cout<<"no bottom"<<std::endl;
}
std::cout<<"=================top================"<<std::endl;
int top_name_size = layer->layer_param().top().size();
if(top_name_size>0)
{
for(int ii=0;ii<top_name_size;ii++)
{
std::cout<<ii<<" ::top name="<<layer->layer_param().top(ii)<<std::endl;
Blob<float>* ptr_blob = top_vecs_[i][ii];
std::cout<<"top shape="<<ptr_blob->shape_string()<<std::endl;
}
} else{
std::cout<<"no top"<<std::endl;
}
vector<shared_ptr<Blob<float> > > params = layer->blobs();
std::cout<<"=================params ================"<<std::endl;
std::cout<<"params size= "<<params.size()<<std::endl;
if(0 == params.size())
{
std::cout<<"has no params"<<std::endl;
} else
{
for(int j=0;j<params.size();j++)
{
std::cout<<"params_"<<j<<" shape="<<params[j]->shape_string()<<std::endl;
params[j]->save_data_to_txt(path_save_dir + name_layer + "_weight_" + std::to_string(j)+".txt");
}
}
std::cout<<std::endl;
}
//To compare whether the output of a layer of caffe and pytorch is consistent, save the feature map output of a layer of caffe first.
string name_aim_top = "premuted_fc";
const shared_ptr<Blob<float>> feature_map = net_->blob_by_name(name_aim_top);
bool b_save_shape = false;
std::cout<<"featuremap shape="<<std::endl;
std::cout<<feature_map->shape_string()<<std::endl;
feature_map->save_data_to_txt("/data_1/Yang/project/myfile/blob_val/"+name_aim_top+".txt",b_save_shape);
If you look at caffe network, you can directly copy the prototext file to the web page.
http://ethereon.github.io/netscope/quickstart.html
This is more intuitive.

What needs special attention here is a local operation. For example, the network connected conv1, conv1_bn,conv1_scale,conv1_ Because their bottom and top names are the same, the operation results of relu through this layer will directly overwrite the bottom, that is, they share a piece of memory.
This is a pit. A colleague was doing similar work before, and then compared and checked the accuracy between different frames. He found that the accuracy of the first few layers was not right. He struggled to find the problem for a week, but he didn't find it. Finally, he asked me to look at it. I found that it was caused by this local operation for more than half a day. You couldn't get the feature map of conv1, What you took actually passed conv1, conv1_bn,conv1_scale,conv1_relu the result of these four steps!
Above, the weight of each layer will be generated. If the layer has multiple weights, it will be directly distinguished by counting 0,1,2 at the end of the file name. The naming method is layerName+_weight_cnt.txt. The first line of the txt file is the weight shape, such as 64,64,1,1.
After that, on the Python side, I first wrote a script, read txt and save these weights in a dictionary.
import os
import numpy as np
#This class is mainly used to assign values to multiple dictionaries
class AutoVivification(dict):
"""Implementation of perl's autovivification feature."""
def __getitem__(self, item):
try:
return dict.__getitem__(self, item)
except KeyError:
value = self[item] = type(self)()
return value
def get_weight_numpy(path_dir):
out = AutoVivification()
list_txt = os.listdir(path_dir)
for cnt,txt in enumerate(list_txt):
print(cnt, " ", txt)
txt_ = txt.replace(".txt","")
layer_name, idx = txt_.split("_weight_")
path_txt = path_dir + txt
with open(path_txt, 'r') as fr:
lines = fr.readlines()
data = []
shape_line = []
for cnt_1, line in enumerate(lines):
if(0 == cnt_1):
shape_line = []
shape_line = line.strip().split(",")
else:
data.append(float(line))
shape_line = map(eval, shape_line)
data = np.array(data).reshape(shape_line)
# new_dict = {}
out[layer_name][int(idx)] = data
return out
if __name__ == "__main__":
path_dir = "/data_1/Yang/project/save_weight/"
out = get_weight_numpy(path_dir)
conv1_weight = out['conv1'][0]
conv1_bias = out['conv1'][1]
The following directly shows how to connect the weight saved by caffe to the built pytorch layer:
# coding=utf-8
import torch
import torchvision
from torch import nn
import torch.nn.functional as F
import cv2
import numpy as np
from weight_numpy import get_weight_numpy
class lstm_general(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
super(lstm_general, self).__init__()
# self.conv1_1 = nn.Conv2d(3, 64, 3, 1, 1)
self.data_bn = nn.BatchNorm2d(3)
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3)
self.conv1_bn = nn.BatchNorm2d(64)
self.conv1_pool = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.layer_64_1_conv1 = nn.Conv2d(64, 64, 1, 1, 0, bias = False)
self.layer_64_1_bn2 = nn.BatchNorm2d(64)
self.layer_64_1_conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.layer_64_1_bn3 = nn.BatchNorm2d(64)
self.layer_64_1_conv3 = nn.Conv2d(64, 256, 1, 1, 0, bias=False)
self.layer_64_1_conv_expand = nn.Conv2d(64, 256, 1, 1, 0, bias=False)
self.layer_128_1_bn1 = nn.BatchNorm2d(256)
self.layer_128_1_conv1 = nn.Conv2d(256, 128, 1, 1, 0, bias=False)
self.layer_128_1_bn2 = nn.BatchNorm2d(128)
self.layer_128_1_conv2 = nn.Conv2d(128, 128, 3, 1, 1, bias=False)
self.layer_128_1_bn3 = nn.BatchNorm2d(128)
self.layer_128_1_conv3 = nn.Conv2d(128, 512, 1, 1, 0, bias=False)
self.layer_128_1_conv_expand = nn.Conv2d(256, 512, 1, 1, 0, bias=False)
self.last_bn = nn.BatchNorm2d(512)
# self.lstm_1 = nn.LSTM(512 * 8, 100, 1, bidirectional=False)
self.lstm_lr = nn.LSTM(512 * 8, 100, 1, bidirectional=True)
self.fc1x1_r2_v2_a = nn.Linear(200,7118)
def forward(self, inputs):
# x = F.relu(self.bn1_1(self.conv1_1(inputs)))
x = self.data_bn(inputs)
x = F.relu(self.conv1_bn(self.conv1(x)))
x = self.conv1_pool(x) #[1,64,8,80]
x = F.relu(self.layer_64_1_bn2(self.layer_64_1_conv1(x))) # 1 64 8 80
layer_64_1_conv1 = x
x = F.relu(self.layer_64_1_bn3(self.layer_64_1_conv2(x)))
x = self.layer_64_1_conv3(x)
layer_64_1_conv_expand = self.layer_64_1_conv_expand(layer_64_1_conv1)
layer_64_3_sum = x + layer_64_1_conv_expand #1 256 8 80
x = F.relu(self.layer_128_1_bn1(layer_64_3_sum))
layer_128_1_bn1 = x
x = F.relu(self.layer_128_1_bn2(self.layer_128_1_conv1(x)))
x = F.relu(self.layer_128_1_bn3(self.layer_128_1_conv2(x)))
x = self.layer_128_1_conv3(x) #1, 512, 8, 80
layer_128_1_conv_expand = self.layer_128_1_conv_expand(layer_128_1_bn1) #1, 512, 8, 80
layer_128_4_sum = x + layer_128_1_conv_expand
x = F.relu(self.last_bn(layer_128_4_sum))
x = F.dropout(x, p=0.7, training=False) #1 512 8 80
x = x.permute(3,0,1,2) # 80 1 512 8
x = x.reshape(80,1,512*8)
#
# merge_lstm_rlstmx, (hn, cn) = self.lstm_r(x)
lstm_out,(_,_) = self.lstm_lr(x) #(80,1,200)
out = self.fc1x1_r2_v2_a(lstm_out) #(80,1,7118)
return out
def save_tensor(tensor_in,path_save):
tensor_in = tensor_in.contiguous().view(-1,1)
np_tensor = tensor_in.cpu().detach().numpy()
# np_tensor = np_tensor.view()
np.savetxt(path_save,np_tensor,fmt='%.12e')
def access_pixels(frame):
print(frame.shape) # shape contains three elements: height, width and number of channels in order
height = frame.shape[0]
weight = frame.shape[1]
channels = frame.shape[2]
print("weight : %s, height : %s, channel : %s" % (weight, height, channels))
with open("/data_1/Yang/project/myfile/blob_val/img_stand_python.txt", "w") as fw:
for row in range(height): # Ergodic height
for col in range(weight): # Ergodic width
for c in range(channels): # Convenient access
pv = frame[row, col, c]
fw.write(str(int(pv)))
fw.write("\n")
def LstmImgStandardization(img, ratio=10.0, stand_w=320, stand_h=32):
img_h, img_w, _ = img.shape
if img_h < 2 or img_w < 2:
return
# if 32 == img_h and 320 == img_w:
# return img
ratio_now = img_w * 1.0 / img_h
if ratio_now <= ratio:
mask = np.ones((img_h, int(img_h * ratio), 3), dtype=np.uint8) * 255
mask[0:img_h,0:img_w,:] = img
else:
mask = np.ones((int(img_w*1.0/ratio), img_w, 3), dtype=np.uint8) * 255
mask[0:img_h, 0:img_w, :] = img
mask_stand = cv2.resize(mask,(stand_w, stand_h),interpolation=cv2.INTER_LINEAR)
# access_pixels(mask_stand)
return mask_stand
if __name__ == '__main__':
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
net = lstm_general()
# net.eval()
index = 0
print("*" * 50)
for name, param in list(net.named_parameters()):
print(str(index) + ':', name, param.size())
index += 1
print("*" * 50)
##After building the network, you can see the parameter names required by the network here
for k, v in net.state_dict().items():
print(k)
print(v.shape)
# print(k,v)
print("@" * 50)
# aaa = np.zeros((400,1))
path_dir = "/data_1/Yang/project/OCR/3rdlib/caffe_ocr_2021/myfile/save_weight/"
weight_numpy_dict = get_weight_numpy(path_dir)
from torch import from_numpy
state_dict = {}
state_dict['data_bn.running_mean'] = from_numpy(weight_numpy_dict["data_bn"][0] / weight_numpy_dict["data_bn"][2])
state_dict['data_bn.running_var'] = from_numpy(weight_numpy_dict["data_bn"][1] / weight_numpy_dict["data_bn"][2])
state_dict['data_bn.weight'] = from_numpy(weight_numpy_dict['data_scale'][0])
state_dict['data_bn.bias'] = from_numpy(weight_numpy_dict['data_scale'][1])
state_dict['conv1.weight'] = from_numpy(weight_numpy_dict['conv1'][0])
state_dict['conv1.bias'] = from_numpy(weight_numpy_dict['conv1'][1])
state_dict['conv1_bn.running_mean'] = from_numpy(weight_numpy_dict["conv1_bn"][0] / weight_numpy_dict["conv1_bn"][2])
state_dict['conv1_bn.running_var'] = from_numpy(weight_numpy_dict["conv1_bn"][1] / weight_numpy_dict["conv1_bn"][2])
state_dict['conv1_bn.weight'] = from_numpy(weight_numpy_dict['conv1_scale'][0])
state_dict['conv1_bn.bias'] = from_numpy(weight_numpy_dict['conv1_scale'][1])
state_dict['layer_64_1_conv1.weight'] = from_numpy(weight_numpy_dict['layer_64_1_conv1'][0])
state_dict['layer_64_1_bn2.running_mean'] = from_numpy(weight_numpy_dict["layer_64_1_bn2"][0] / weight_numpy_dict["layer_64_1_bn2"][2])
state_dict['layer_64_1_bn2.running_var'] = from_numpy(weight_numpy_dict["layer_64_1_bn2"][1] / weight_numpy_dict["layer_64_1_bn2"][2])
state_dict['layer_64_1_bn2.weight'] = from_numpy(weight_numpy_dict['layer_64_1_scale2'][0])
state_dict['layer_64_1_bn2.bias'] = from_numpy(weight_numpy_dict['layer_64_1_scale2'][1])
state_dict['layer_64_1_conv2.weight'] = from_numpy(weight_numpy_dict['layer_64_1_conv2'][0])
state_dict['layer_64_1_bn3.running_mean'] = from_numpy(weight_numpy_dict["layer_64_1_bn3"][0] / weight_numpy_dict["layer_64_1_bn3"][2])
state_dict['layer_64_1_bn3.running_var'] = from_numpy(weight_numpy_dict["layer_64_1_bn3"][1] / weight_numpy_dict["layer_64_1_bn3"][2])
state_dict['layer_64_1_bn3.weight'] = from_numpy(weight_numpy_dict['layer_64_1_scale3'][0])
state_dict['layer_64_1_bn3.bias'] = from_numpy(weight_numpy_dict['layer_64_1_scale3'][1])
state_dict['layer_64_1_conv3.weight'] = from_numpy(weight_numpy_dict['layer_64_1_conv3'][0])
state_dict['layer_64_1_conv_expand.weight'] = from_numpy(weight_numpy_dict['layer_64_1_conv_expand'][0])
state_dict['layer_128_1_bn1.running_mean'] = from_numpy(weight_numpy_dict["layer_128_1_bn1"][0] / weight_numpy_dict["layer_128_1_bn1"][2])
state_dict['layer_128_1_bn1.running_var'] = from_numpy(weight_numpy_dict["layer_128_1_bn1"][1] / weight_numpy_dict["layer_128_1_bn1"][2])
state_dict['layer_128_1_bn1.weight'] = from_numpy(weight_numpy_dict['layer_128_1_scale1'][0])
state_dict['layer_128_1_bn1.bias'] = from_numpy(weight_numpy_dict['layer_128_1_scale1'][1])
state_dict['layer_128_1_conv1.weight'] = from_numpy(weight_numpy_dict['layer_128_1_conv1'][0])
state_dict['layer_128_1_bn2.running_mean'] = from_numpy(weight_numpy_dict["layer_128_1_bn2"][0] / weight_numpy_dict["layer_128_1_bn2"][2])
state_dict['layer_128_1_bn2.running_var'] = from_numpy(weight_numpy_dict["layer_128_1_bn2"][1] / weight_numpy_dict["layer_128_1_bn2"][2])
state_dict['layer_128_1_bn2.weight'] = from_numpy(weight_numpy_dict['layer_128_1_scale2'][0])
state_dict['layer_128_1_bn2.bias'] = from_numpy(weight_numpy_dict['layer_128_1_scale2'][1])
state_dict['layer_128_1_conv2.weight'] = from_numpy(weight_numpy_dict['layer_128_1_conv2'][0])
state_dict['layer_128_1_bn3.running_mean'] = from_numpy(weight_numpy_dict["layer_128_1_bn3"][0] / weight_numpy_dict["layer_128_1_bn3"][2])
state_dict['layer_128_1_bn3.running_var'] = from_numpy(weight_numpy_dict["layer_128_1_bn3"][1] / weight_numpy_dict["layer_128_1_bn3"][2])
state_dict['layer_128_1_bn3.weight'] = from_numpy(weight_numpy_dict['layer_128_1_scale3'][0])
state_dict['layer_128_1_bn3.bias'] = from_numpy(weight_numpy_dict['layer_128_1_scale3'][1])
state_dict['layer_128_1_conv3.weight'] = from_numpy(weight_numpy_dict['layer_128_1_conv3'][0])
state_dict['layer_128_1_conv_expand.weight'] = from_numpy(weight_numpy_dict['layer_128_1_conv_expand'][0])
state_dict['last_bn.running_mean'] = from_numpy(weight_numpy_dict["last_bn"][0] / weight_numpy_dict["last_bn"][2])
state_dict['last_bn.running_var'] = from_numpy(weight_numpy_dict["last_bn"][1] / weight_numpy_dict["last_bn"][2])
state_dict['last_bn.weight'] = from_numpy(weight_numpy_dict['last_scale'][0])
state_dict['last_bn.bias'] = from_numpy(weight_numpy_dict['last_scale'][1])
## caffe i f o g
## pytorch i f g o
ww = from_numpy(weight_numpy_dict['lstm1x_r2'][0]) # [400,4096]
ww_200_if = ww[:200,:] #[200,4096]
ww_100_o = ww[200:300,:] #[100,4096]
ww_100_g = ww[300:400,:]#[100,4096]
ww_cat_ifgo = torch.cat((ww_200_if,ww_100_g,ww_100_o),0)
state_dict['lstm_lr.weight_ih_l0'] = ww_cat_ifgo
bb = from_numpy(weight_numpy_dict['lstm1x_r2'][1]) # [400]
bb_200_if = bb[:200]
bb_100_o = bb[200:300]
bb_100_g = bb[300:400]
bb_cat_ifgo = torch.cat((bb_200_if, bb_100_g, bb_100_o), 0)
state_dict['lstm_lr.bias_ih_l0'] = bb_cat_ifgo
ww = from_numpy(weight_numpy_dict['lstm1x_r2'][2]) # [400,100]
ww_200_if = ww[:200, :] # [200,100]
ww_100_o = ww[200:300, :] # [100,100]
ww_100_g = ww[300:400, :] # [100,100]
ww_cat_ifgo = torch.cat((ww_200_if, ww_100_g, ww_100_o), 0)
state_dict['lstm_lr.weight_hh_l0'] = ww_cat_ifgo
state_dict['lstm_lr.bias_hh_l0'] = from_numpy(np.zeros((400)))
##########################################
ww = from_numpy(weight_numpy_dict['lstm2x_r2'][0]) # [400,4096]
ww_200_if = ww[:200, :] # [200,4096]
ww_100_o = ww[200:300, :] # [100,4096]
ww_100_g = ww[300:400, :] # [100,4096]
ww_cat_ifgo = torch.cat((ww_200_if, ww_100_g, ww_100_o), 0)
state_dict['lstm_lr.weight_ih_l0_reverse'] = ww_cat_ifgo
bb = from_numpy(weight_numpy_dict['lstm2x_r2'][1]) # [400]
bb_200_if = bb[:200]
bb_100_o = bb[200:300]
bb_100_g = bb[300:400]
bb_cat_ifgo = torch.cat((bb_200_if, bb_100_g, bb_100_o), 0)
state_dict['lstm_lr.bias_ih_l0_reverse'] = bb_cat_ifgo
ww = from_numpy(weight_numpy_dict['lstm2x_r2'][2]) # [400,100]
ww_200_if = ww[:200, :] # [200,100]
ww_100_o = ww[200:300, :] # [100,100]
ww_100_g = ww[300:400, :] # [100,100]
ww_cat_ifgo = torch.cat((ww_200_if, ww_100_g, ww_100_o), 0)
state_dict['lstm_lr.weight_hh_l0_reverse'] = ww_cat_ifgo
state_dict['lstm_lr.bias_hh_l0_reverse'] = from_numpy(np.zeros((400)))
state_dict['fc1x1_r2_v2_a.weight'] = from_numpy(weight_numpy_dict['fc1x1_r2_v2_a'][0])
state_dict['fc1x1_r2_v2_a.bias'] = from_numpy(weight_numpy_dict['fc1x1_r2_v2_a'][1])
####input########################################
path_img = "/data_2/project/1.jpg"
img = cv2.imread(path_img)
# access_pixels(img)
img_stand = LstmImgStandardization(img, ratio=10.0, stand_w=320, stand_h=32)
img_stand = img_stand.astype(np.float32)
# img = (img / 255. - config.DATASET.MEAN) / config.DATASET.STD
img_stand = img_stand.transpose([2, 0, 1])
img_stand = img_stand[None,:,:,:]
img_stand = torch.from_numpy(img_stand)
img_stand = img_stand.type(torch.FloatTensor)
img_stand = img_stand.to(device)
# img_stand = img_stand.view(1, *img.size())
#######net##########################
net.load_state_dict(state_dict)
net.cuda()
net.eval()
preds = net(img_stand)
print("out shape=",preds.shape)
torch.save(net.state_dict(), './lstm_model.pth')
# name_top_caffe_layer = "fc1x_a" #"merge_lstm_rlstmx" #"#"data_bn"
# path_save = "/data_1/Yang/project/myfile/blob_val/" + name_top_caffe_layer + "_torch.txt"
# save_tensor(preds, path_save)
aaa = 0
It should be noted that the bn layer in caffe has three parameters. The first two are the mean and variance, and the third parameter is a coefficient. Both the mean and variance need to be divided by this coefficient, which is a fixed value of 999.982

The scale layer in cafe is the coefficient of the following formula in the figure.
Here we also need to talk about the lstm algorithm. Time set in Cafe_ The step is 80, the hidden is set to 100, and the feature map size before input to lstm is 80,1512,8
Then I see that lstm has three weights through the weight of the layer, which are [4004096] [400] [400100] respectively
Through checking the source code, lstm found that there are two full connection layers with parameters, [4004096] [400], which are the parameters required for inner input. 400 is obtained by 100 * 4. As for why it is 4, it depends on the principle of lstm. Here, it is simply multiplied by four groups of h and x.
[400100] is the weight required for implicit h inner.
View the introduction to lstm in the pytorch manual.
https://pytorch.org/docs/1.0.1/nn.html?highlight=lstm#torch.nn.LSTM . Introduction to input parameters.



Then, according to the input parameters, write an lstm operator test separately to see:
import torch
import torch.nn as nn
# rnn = nn.LSTM(512*8, 100, 1, False)
# input = torch.randn(80, 1, 512*8)
#
# output, (hn, cn) = rnn(input)
#
#
# for name,parameters in rnn.named_parameters():
# print(name,':',parameters.size())
# # parm[name]=parameters.detach().numpy()
#
# aa = 0
rnn = nn.LSTM(512*8, 100, 1, bidirectional=True)
input = torch.randn(80, 1, 512*8)
output, (hn, cn) = rnn(input)
print("out shape=",output.shape)
for name,parameters in rnn.named_parameters():
print(name,':',parameters.size())
# parm[name]=parameters.detach().numpy()
aa = 0
The output is as follows:
('out shape=', (80, 1, 200))
('weight_ih_l0', ':', (400, 4096))
('weight_hh_l0', ':', (400, 100))
('bias_ih_l0', ':', (400,))
('bias_hh_l0', ':', (400,))
('weight_ih_l0_reverse', ':', (400, 4096))
('weight_hh_l0_reverse', ':', (400, 100))
('bias_ih_l0_reverse', ':', (400,))
('bias_hh_l0_reverse', ':', (400,))
Process finished with exit code 0
It can be seen that the parameters required for the lstm of pytorch are basically the same as those of caffe. However, there are three lstm parameters of caffe and four lstm parameters of pytorch. Obviously, there is no bias in the inner of the hidden layer of caffe. At that time, just set the bias of a pytorch to 0!
However, things are not plain sailing. The code given above is successful, but I have connected all parameters before, but the accuracy is wrong. After a closer look at the lstm source code, it is found that the calculation order of caffe is as follows:
lstm_unit_layer.cpp
template <typename Dtype>
void LSTMUnitLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int num = bottom[0]->shape(1);//1
const int x_dim = hidden_dim_ * 4;
const Dtype* C_prev = bottom[0]->cpu_data();
const Dtype* X = bottom[1]->cpu_data();
const Dtype* cont = bottom[2]->cpu_data();
Dtype* C = top[0]->mutable_cpu_data();
Dtype* H = top[1]->mutable_cpu_data();
for (int n = 0; n < num; ++n) { //1
for (int d = 0; d < hidden_dim_; ++d) {//100
const Dtype i = sigmoid(X[d]);
const Dtype f = (*cont == 0) ? 0 :
(*cont * sigmoid(X[1 * hidden_dim_ + d]));weight_ih_l[k] – the learnable input-hidden weights of the \text{k}^{th}k
th
layer (W_ii|W_if|W_ig|W_io), of shape (4*hidden_size x input_size)
weight_hh_l[k] – the learnable hidden-hidden weights of the \text{k}^{th}k
th
layer (W_hi|W_hf|W_hg|W_ho), of shape (4*hidden_size x hidden_size)
bias_ih_l[k] – the learnable input-hidden bias of the \text{k}^{th}k
th
layer (b_ii|b_if|b_ig|b_io), of shape (4*hidden_size)
bias_hh_l[k] – the learnable hidden-hidden bias of the \text{k}^{th}k
th
layer (b_hi|b_hf|b_hg|b_ho), of shape (4*hidden_size)
const Dtype o = sigmoid(X[2 * hidden_dim_ + d]);
const Dtype g = tanh(X[3 * hidden_dim_ + d]);
const Dtype c_prev = C_prev[d];
const Dtype c = f * c_prev + i * g;
C[d] = c;
const Dtype tanh_c = tanh(c);
H[d] = o * tanh_c;
}
C_prev += hidden_dim_;
X += x_dim;
C += hidden_dim_;
H += hidden_dim_;
++cont;
}
}
It is found that the computational order of caffe is ifog.
The order in which weights are introduced in the pytorch documentation is
weight_ih_l[k] – the learnable input-hidden weights of the \text{k}^{th}k
th
layer (W_ii|W_if|W_ig|W_io), of shape (4*hidden_size x input_size)
weight_hh_l[k] – the learnable hidden-hidden weights of the \text{k}^{th}k
th
layer (W_hi|W_hf|W_hg|W_ho), of shape (4*hidden_size x hidden_size)
bias_ih_l[k] – the learnable input-hidden bias of the \text{k}^{th}k
th
layer (b_ii|b_if|b_ig|b_io), of shape (4*hidden_size)
bias_hh_l[k] – the learnable hidden-hidden bias of the \text{k}^{th}k
th
layer (b_hi|b_hf|b_hg|b_ho), of shape (4*hidden_size)
It's a little different, so I just need to change the weight order of caffe to be consistent with pytorch. All have the above code:
## caffe i f o g
## pytorch i f g o
ww = from_numpy(weight_numpy_dict['lstm1x_r2'][0]) # [400,4096]
ww_200_if = ww[:200,:] #[200,4096]
ww_100_o = ww[200:300,:] #[100,4096]
ww_100_g = ww[300:400,:]#[100,4096]
ww_cat_ifgo = torch.cat((ww_200_if,ww_100_g,ww_100_o),0)
state_dict['lstm_lr.weight_ih_l0'] = ww_cat_ifgo
Such a whole, successful, consistent accuracy!! Give the code of test accuracy.
Verification accuracy under different frames https://www.cnblogs.com/yanghailin/p/15593614.html
Give me the code to run the result:
# -*- coding: utf-8
import torch
from torch import nn
import torch.nn.functional as F
import cv2
import numpy as np
import os
from chn_tab import chn_tab
class lstm_general(nn.Module): # SfSNet = PS-Net in SfSNet_deploy.prototxt
def __init__(self):
super(lstm_general, self).__init__()
# self.conv1_1 = nn.Conv2d(3, 64, 3, 1, 1)
self.data_bn = nn.BatchNorm2d(3)
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3)
self.conv1_bn = nn.BatchNorm2d(64)
self.conv1_pool = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.layer_64_1_conv1 = nn.Conv2d(64, 64, 1, 1, 0, bias = False)
self.layer_64_1_bn2 = nn.BatchNorm2d(64)
self.layer_64_1_conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.layer_64_1_bn3 = nn.BatchNorm2d(64)
self.layer_64_1_conv3 = nn.Conv2d(64, 256, 1, 1, 0, bias=False)
self.layer_64_1_conv_expand = nn.Conv2d(64, 256, 1, 1, 0, bias=False)
self.layer_128_1_bn1 = nn.BatchNorm2d(256)
self.layer_128_1_conv1 = nn.Conv2d(256, 128, 1, 1, 0, bias=False)
self.layer_128_1_bn2 = nn.BatchNorm2d(128)
self.layer_128_1_conv2 = nn.Conv2d(128, 128, 3, 1, 1, bias=False)
self.layer_128_1_bn3 = nn.BatchNorm2d(128)
self.layer_128_1_conv3 = nn.Conv2d(128, 512, 1, 1, 0, bias=False)
self.layer_128_1_conv_expand = nn.Conv2d(256, 512, 1, 1, 0, bias=False)
self.last_bn = nn.BatchNorm2d(512)
# self.lstm_1 = nn.LSTM(512 * 8, 100, 1, bidirectional=False)
self.lstm_lr = nn.LSTM(512 * 8, 100, 1, bidirectional=True)
self.fc1x1_r2_v2_a = nn.Linear(200,7118)
def forward(self, inputs):
# x = F.relu(self.bn1_1(self.conv1_1(inputs)))
x = self.data_bn(inputs)
x = F.relu(self.conv1_bn(self.conv1(x)))
x = self.conv1_pool(x) #[1,64,8,80]
x = F.relu(self.layer_64_1_bn2(self.layer_64_1_conv1(x))) # 1 64 8 80
layer_64_1_conv1 = x
x = F.relu(self.layer_64_1_bn3(self.layer_64_1_conv2(x)))
x = self.layer_64_1_conv3(x)
layer_64_1_conv_expand = self.layer_64_1_conv_expand(layer_64_1_conv1)
layer_64_3_sum = x + layer_64_1_conv_expand #1 256 8 80
x = F.relu(self.layer_128_1_bn1(layer_64_3_sum))
layer_128_1_bn1 = x
x = F.relu(self.layer_128_1_bn2(self.layer_128_1_conv1(x)))
x = F.relu(self.layer_128_1_bn3(self.layer_128_1_conv2(x)))
x = self.layer_128_1_conv3(x) #1, 512, 8, 80
layer_128_1_conv_expand = self.layer_128_1_conv_expand(layer_128_1_bn1) #1, 512, 8, 80
layer_128_4_sum = x + layer_128_1_conv_expand
x = F.relu(self.last_bn(layer_128_4_sum))###acc ok
x = F.dropout(x, p=0.7, training=False) #1 512 8 80
x = x.permute(3,0,1,2) # 80 1 512 8
x = x.reshape(80,1,512*8)###acc ok
#
# merge_lstm_rlstmx, (hn, cn) = self.lstm_r(x)
lstm_out,(_,_) = self.lstm_lr(x) #(80,1,200)
return lstm_out
out = self.fc1x1_r2_v2_a(lstm_out) #(80,1,7118)
return out
def LstmImgStandardization(img, ratio=10.0, stand_w=320, stand_h=32):
img_h, img_w, _ = img.shape
if img_h < 2 or img_w < 2:
return
# if 32 == img_h and 320 == img_w:
# return img
ratio_now = img_w * 1.0 / img_h
if ratio_now <= ratio:
mask = np.ones((img_h, int(img_h * ratio), 3), dtype=np.uint8) * 255
mask[0:img_h,0:img_w,:] = img
else:
mask = np.ones((int(img_w*1.0/ratio), img_w, 3), dtype=np.uint8) * 255
mask[0:img_h, 0:img_w, :] = img
mask_stand = cv2.resize(mask,(stand_w, stand_h),interpolation=cv2.INTER_LINEAR)
# access_pixels(mask_stand)
return mask_stand
if __name__ == '__main__':
path_model = "/data_1/everyday/1118/pytorch_lstm_test/lstm_model.pth"
path_img = "/data_2/project_202009/chejian/test_data/model_test/rec_general/1.jpg"
blank_label = 7117
prev_label = blank_label
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
img = cv2.imread(path_img)
img_stand = LstmImgStandardization(img, ratio=10.0, stand_w=320, stand_h=32)
img_stand = img_stand.astype(np.float32)
img_stand = img_stand.transpose([2, 0, 1])
img_stand = img_stand[None, :, :, :]
img_stand = torch.from_numpy(img_stand)
img_stand = img_stand.type(torch.FloatTensor)
img_stand = img_stand.to(device)
net = lstm_general()
checkpoint = torch.load(path_model)
net.load_state_dict(checkpoint)
net.cuda()
net.eval()
# traced_script_module = torch.jit.trace(net, img_stand)
# traced_script_module.save("./lstm.pt")
preds = net(img_stand)
# print("out shape=", preds.shape)
preds_1 = preds.squeeze()
# print("preds_1 out shape=", preds_1.shape)
val, pos = torch.max(preds_1,1)
pos = pos.cpu().numpy()
rec = ""
for predict_label in pos:
if predict_label != blank_label and predict_label != prev_label:
# print("predict_label=",predict_label)
print(chn_tab[predict_label])
rec += chn_tab[predict_label]
prev_label = predict_label
# print("rec=",rec)
print(rec)
It worked, but I was only happy for one day.
My ultimate goal is to run under c + +, so I turned to libtorch. I thought it was easy, but it wasn't that simple.
I found that the accuracy of my libtorch code is not right after passing through the lstm layer. It can be right before that.!!! No solution.
It may have something to do with the version, because I successfully converted a crnn before using a higher version of libtorch. There is no problem.
https://github.com/wuzuowuyou/crnn_libtorch
This is pytorch version 1.7, and I use version 1.0 now. I've tried for a long time and found that the accuracy is still wrong, which can't be solved, and I don't know where to start to solve this problem. After going through the issue on pytorch github, no one encountered the same problem as me... Unless you look at the source code of pytorch to find a problem, it's too difficult.
issue is raised in github of pytorch
https://github.com/pytorch/pytorch/issues/68864
I know it will sink into the sea.
Here's my messy, unfinished Code:
#include <torch/script.h> // One-stop header.
#include "torch/torch.h"
#include "torch/jit.h"
#include <memory>
#include "opencv2/opencv.hpp"
#include <queue>
#include <dirent.h>
#include <iostream>
#include <cstdlib>
#include <cstring>
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
using namespace cv;
using namespace std;
// cv::Mat m_stand;
#define TABLE_SIZE 7117
static string chn_tab[TABLE_SIZE+1] = {"ah","Ah","AI"
. . .
. . .
. . .
"0","1","2","3","4","5","6","7","8","9",
":",";","<","=",">","?","@",
"A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z",
"[","\\","]","^","_","`",
"a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z",
"{","|","}","~",
" "};
bool LstmImgStandardization_src_1(const cv::Mat &src, const float &ratio, int standard_w, int standard_h, cv::Mat &dst)
{
if(src.empty())return false;
float width=src.cols;
float height=src.rows;
float a=width/ height;
if(a <=ratio)
{
Mat mask(height, ratio*height, CV_8UC3, cv::Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
else
{
Mat mask(width/ratio, width, CV_8UC3, cv::Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
//cv::resize(dst, dst, cv::Size(standard_w,standard_h));
cv::resize(dst, dst, cv::Size(standard_w,standard_h),0,0,cv::INTER_AREA);
return true;
}
bool lstm_img_standardization(cv::Mat src, cv::Mat &dst,float ratio)
{
if(src.empty())return false;
double width=src.cols;
double height=src.rows;
double a=width/height;
if(a <=ratio)//6
{
Mat mask(height, ratio*height, CV_8UC3, Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
else
{
Mat mask(width/ratio, width, CV_8UC3, Scalar(255, 255, 255));
Mat imageROI = mask(Rect(0, 0, width, height));
src.copyTo(imageROI);
dst=mask.clone();
}
// cv::resize(dst, dst, cv::Size(360,60));
cv::resize(dst, dst, cv::Size(320,32));
return true;
}
//torch::Tensor pre_img(cv::Mat &img)
//{
// cv::Mat m_stand;
// float ratio = 10.0;
// if(1 == img.channels()) { cv::cvtColor(img,img,CV_GRAY2BGR); }
// lstm_img_standardization(img, m_stand, ratio);
//
// std::vector<int64_t> sizes = {m_stand.rows, m_stand.cols, m_stand.channels()};
// torch::TensorOptions options = torch::TensorOptions().dtype(torch::kByte);
// torch::Tensor tensor_image = torch::from_blob(m_stand.data, torch::IntList(sizes), options);
// // Permute tensor, shape is (C, H, W)
// tensor_image = tensor_image.permute({2, 0, 1});
//
//
// // Convert tensor dtype to float32, and range from [0, 255] to [0, 1]
// tensor_image = tensor_image.toType(torch::ScalarType::Float);
//
//
//// tensor_image = tensor_image.div_(255.0);
//// // Subtract mean value
//// for (int i = 0; i < std::min<int64_t>(v_mean.size(), tensor_image.size(0)); i++) {
//// tensor_image[i] = tensor_image[i].sub_(v_mean[i]);
//// }
//// // Divide by std value
//// for (int i = 0; i < std::min<int64_t>(v_std.size(), tensor_image.size(0)); i++) {
//// tensor_image[i] = tensor_image[i].div_(v_std[i]);
//// }
// //[c,h,w] --> [1,c,h,w]
// tensor_image.unsqueeze_(0);
// std::cout<<tensor_image;
// return tensor_image;
//}
bool pre_img(cv::Mat &img, torch::Tensor &input_tensor)
{
static cv::Mat m_stand;
float ratio = 10.0;
// if(1 == img.channels()) { cv::cvtColor(img,img,CV_GRAY2BGR); }
lstm_img_standardization(img, m_stand, ratio);
m_stand.convertTo(m_stand, CV_32FC3);
// imshow("m_stand",m_stand);
// waitKey(0);
// Mat m_stand_new;
// m_stand.convertTo(m_stand_new, CV_32FC3);
// int rowNumber = m_stand_new.rows; // Number of rows
// int colNumber = m_stand_new.cols*m_stand_new.channels(); // Number of columns x number of channels = number of elements in each row
// std::ofstream out_file("/data_1/everyday/1123/img_acc/after_CV_32FC3-float-111.txt");
// //Double loop, traversing all pixel values
// For (int i = 0; I < rownumber; I + +) / / line loop
// {
// uchar *data = m_ stand_ new.ptr<uchar>(i); // Get the first address of line I
// For (int j = 0; J < colnumber; j + +) / / column loop
// {
// //------- [start processing each pixel]-------------
// int pix = int(data[j]);
// out_file << pix << std::endl;
// }
// }
//
// out_file.close();
// std::cout<<"==m_stand.convertTo(m_stand, CV_32FC3);=="<<std::endl;
// while(1);
int stand_row = m_stand.rows;
int stand_cols = m_stand.cols;
input_tensor = torch::from_blob(
m_stand.data, {stand_row, stand_cols, 3}).toType(torch::kFloat);
input_tensor = input_tensor.permute({2,0,1});
input_tensor = input_tensor.unsqueeze(0);//.to(torch::kFloat);
// std::cout<<input_tensor;
return true;
}
void GetFileInDir(string dirName, vector<string> &v_path)
{
DIR* Dir = NULL;
struct dirent* file = NULL;
if (dirName[dirName.size()-1] != '/')
{
dirName += "/";
}
if ((Dir = opendir(dirName.c_str())) == NULL)
{
cerr << "Can't open Directory" << endl;
exit(1);
}
while (file = readdir(Dir))
{
//if the file is a normal file
if (file->d_type == DT_REG)
{
v_path.push_back(dirName + file->d_name);
}
//if the file is a directory
else if (file->d_type == DT_DIR && strcmp(file->d_name, ".") != 0 && strcmp(file->d_name, "..") != 0)
{
GetFileInDir(dirName + file->d_name,v_path);
}
}
}
string str_replace(const string &str,const string &str_find,const string &str_replacee)
{
string str_tmp=str;
size_t pos = str_tmp.find(str_find);
while (pos != string::npos)
{
str_tmp.replace(pos, str_find.length(), str_replacee);
size_t pos_t=pos+str_replacee.length();
string str_sub=str_tmp.substr(pos_t,str_tmp.length()-pos_t);
size_t pos_tt=str_sub.find(str_find);
if(string::npos != pos_tt)
{
pos =pos_t + str_sub.find(str_find);
}else
{
pos=string::npos;
}
}
return str_tmp;
}
string get_ans(const string path)
{
int pos_1 = path.find_last_of("_");
int pos_2 = path.find_last_of(".");
string ans = path.substr(pos_1+1,pos_2-pos_1-1);
ans = str_replace(ans,"@","/");
return ans;
}
bool save_tensor_txt(torch::Tensor tensor_in_,string path_txt)
{
#include "fstream"
ofstream outfile(path_txt);
torch::Tensor tensor_in = tensor_in_.clone();
tensor_in = tensor_in.view({-1,1});
tensor_in = tensor_in.to(torch::kCPU);
auto result_data = tensor_in.accessor<float, 2>();
for(int i=0;i<result_data.size(0);i++)
{
float val = result_data[i][0];
// std::cout<<"val="<<val<<std::endl;
outfile<<val<<std::endl;
}
return true;
}
int main()
{
std::string path_pt = "/data_1/everyday/1118/pytorch_lstm_test/lstmunidirectional20211124.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm20211124.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm10000.pt";//"/data_1/everyday/1118/pytorch_lstm_test/lstm.pt";
std::string path_img_dir = "/data_1/2020biaozhushuju/2021_rec/general/test";//"/data_1/everyday/1118/pytorch_lstm_test/test_data";
int blank_label = 7117;
std::ifstream list("/data_1/everyday/1123/list.txt");
int standard_w = 320;
int standard_h = 32;
// vector<string> v_path;
// GetFileInDir(path_img_dir, v_path);
// for(int i=0;i<v_path.size();i++)
// {
// std::cout<<i<<" "<<v_path[i]<<std::endl;
// }
torch::Device m_device(torch::kCUDA);
// torch::Device m_device(torch::kCPU);
std::shared_ptr<torch::jit::script::Module> m_model = torch::jit::load(path_pt);
torch::NoGradGuard no_grad;
m_model->to(m_device);
std::cout<<"success load model"<<std::endl;
int cnt_all = 0;
int cnt_right = 0;
double start = getTickCount();
string file;
while(list >> file)
{
file = "/data_1/everyday/1123/img/bxd_39_Engine number.jpg";
cout<<cnt_all++<<" :: "<<file<<endl;
string jpg=".jpg";
string::size_type idx = file.find( jpg );
if ( idx == string::npos )
continue;
int pos_1 = file.find_last_of("_");
int pos_2 = file.find_last_of(".");
string answer = file.substr(pos_1+1,pos_2-pos_1-1);
cv::Mat img = cv::imread(file);
// int rowNumber = img.rows; // Number of rows
// int colNumber = img.cols*img.channels(); // Number of columns x number of channels = number of elements in each row
// std::ofstream out_file("/data_1/everyday/1123/img_acc/libtorch_img.txt");
// //Double loop, traversing all pixel values
// For (int i = 0; I < rownumber; I + +) / / line loop
// {
// uchar *data = img.ptr<uchar>(i); // Get the first address of line I
// For (int j = 0; J < colnumber; j + +) / / column loop
// {
// //------- [start processing each pixel]-------------
// int pix = int(data[j]);
// out_file << pix << std::endl;
// }
// }
//
// out_file.close();
// while(1);
torch::Tensor tensor_input;
pre_img(img, tensor_input);
tensor_input = tensor_input.to(m_device);
tensor_input.print();
std::cout<<tensor_input[0][2][12][25]<<std::endl;
std::cout<<tensor_input[0][1][15][100]<<std::endl;
std::cout<<tensor_input[0][0][16][132]<<std::endl;
std::cout<<tensor_input[0][1][17][156]<<std::endl;
std::cout<<tensor_input[0][2][5][256]<<std::endl;
std::cout<<tensor_input[0][0][14][205]<<std::endl;
save_tensor_txt(tensor_input, "/data_1/everyday/1124/acc/libtorch_input-100.txt");
torch::Tensor output = m_model->forward({tensor_input}).toTensor();
output.print();
// output = output.squeeze();//80,7118
// output.print();
save_tensor_txt(output, "/data_1/everyday/1124/acc/libtorch-out-100.txt");
//// std::cout<<output<<std::endl;
while(1);
//
torch::Tensor index = torch::argmax(output,1).cpu();//.to(torch::kInt);
index.print();
// std::cout<<index<<std::endl;
// while(1);
int prev_label = blank_label;
string result;
auto result_data = index.accessor<long, 1>();
for(int i=0;i<result_data.size(0);i++)
{
// std::cout<<result_data[i]<<std::endl;
int predict_label = result_data[i];
if (predict_label != blank_label && predict_label != prev_label )
{
{
result = result + chn_tab[predict_label];
}
}
prev_label = predict_label;
}
cout << "answer: " << answer << endl;
cout << "result : " << result << endl;
imshow("src",img);
waitKey(0);
// while(1);
}
// for(int i=0;i<v_path.size();i++)
// {
// cnt_all += 1;
// std::string path_img = v_path[i];
// string ans = get_ans(path_img);
// std::cout<<i<<" path="<<path_img<<" ans="<<ans<<std::endl;
// cv::Mat img = cv::imread(path_img);
// torch::Tensor input = pre_img(img, v_mean, v_std, standard_w, standard_h);
// input = input.to(m_device);
// torch::Tensor output = m_module.forward({input}).toTensor();
//
// std::string rec = get_label(output);
//#if 1 //for show
// std::cout<<"rec="<<rec<<std::endl;
// std::cout<<"ans="<<ans<<std::endl;
// cv::imshow("img",img);
// cv::waitKey(0);
//#endif
//
//#if 0 //In order to test the accuracy
// std::cout<<"rec="<<rec<<std::endl;
// std::cout<<"ans="<<ans<<std::endl;
// if(ans == rec)
// {
// cnt_right += 1;
// }
// std::cout<<"cnt_right="<<cnt_right<<std::endl;
// std::cout<<"cnt_all="<<cnt_all<<std::endl;
// std::cout<<"ratio="<<cnt_right * 1.0 / cnt_all<<std::endl;
//#endif
// }
// double time_cunsume = ((double)getTickCount() - start) / getTickFrequency();
// std::cout<<"ave time="<< time_cunsume * 1.0 / cnt_all * 1000 <<"ms"<<std::endl;
return 0;
}