Caffe learning (8) unbutun18 Configure Caffe OCR under 04
preface
Whereas https://github.com/senlinuc/caffe_ocr There is no linux version. Here is a record of how to convert the Windows version to the linux version
Preparation stage
https://github.com/senlinuc/caffe_ocr
https://github.com/BVLC/caffe
Installing caffe
Here is mainly to install the caffe version on unbutun without too much description
Transplantation process
Overall process analysis
caffe_ocr mainly includes several points:
1. caffe multi label classification
2. Addition of DenseBlock (DenseBlock_layer.cpp) layer
3. Replacement of lstm
4. Addition of ctclos
Note: in particular, if you want to use Cafe quickly, you can replace DenseBlock and ignore lstm, that is, DenseBlock can be replaced by convolution layer (DenseBlock_layer.cpp not only integrates DenseBlock, but also optimizes the speed to a certain extent), and the actual ocr can directly realize the end-to-end result by cnn+ctc, lstm adds temporal logic, which will be better when the actual long and short text changes.
caffe multi label classification
Here you can refer to
https://blog.csdn.net/mqyw29995/article/details/111541004
Note that there is no need to modify to support floating-point data input.
According to caffe_ The author of OCR
https://blog.csdn.net/hubin232/article/details/50960201
With reference to this, I will make a simplified summary here
Need to modify: io hpp, io.cpp,data_layers.hpp,caffe.proto,data_layer.cpp,image_data_layer.cpp,memory_data_layer.cpp
And convert_imageset generates lmdb. We don't need this, so we can ignore it first
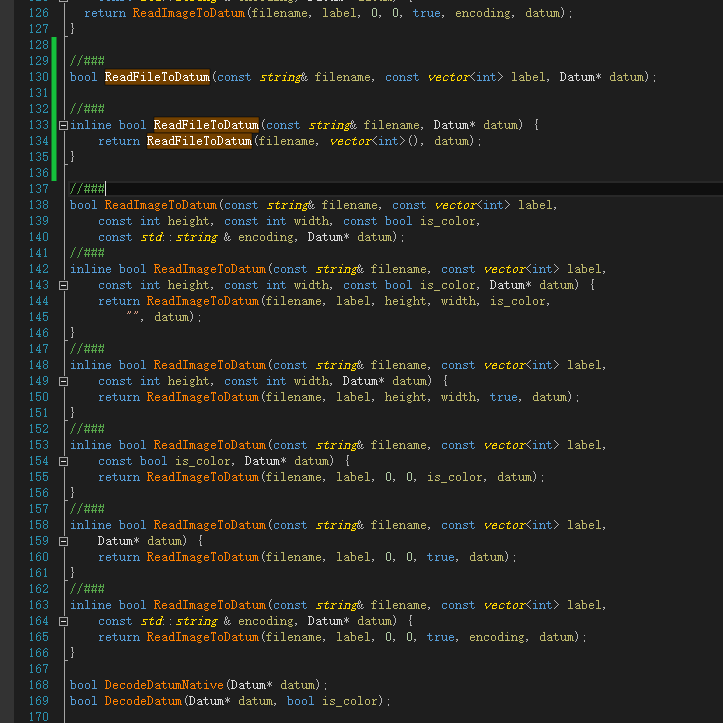
1,io.hpp
Path: Cafe master \ include \ Cafe \ util \ io hpp
Modification point: line 128: the function is modified to support multiple labels. Here you can consider adding it in the last line (c + + supports function overloading)
//###
bool ReadFileToDatum(const string& filename, const vector<int> label, Datum* datum);
//###
inline bool ReadFileToDatum(const string& filename, Datum* datum) {
return ReadFileToDatum(filename, vector<int>(), datum);
}
//###
bool ReadImageToDatum(const string& filename, const vector<int> label,
const int height, const int width, const bool is_color,
const std::string & encoding, Datum* datum);
//###
inline bool ReadImageToDatum(const string& filename, const vector<int> label,
const int height, const int width, const bool is_color, Datum* datum) {
return ReadImageToDatum(filename, label, height, width, is_color,
"", datum);
}
//###
inline bool ReadImageToDatum(const string& filename, const vector<int> label,
const int height, const int width, Datum* datum) {
return ReadImageToDatum(filename, label, height, width, true, datum);
}
//###
inline bool ReadImageToDatum(const string& filename, const vector<int> label,
const bool is_color, Datum* datum) {
return ReadImageToDatum(filename, label, 0, 0, is_color, datum);
}
//###
inline bool ReadImageToDatum(const string& filename, const vector<int> label,
Datum* datum) {
return ReadImageToDatum(filename, label, 0, 0, true, datum);
}
//###
inline bool ReadImageToDatum(const string& filename, const vector<int> label,
const std::string & encoding, Datum* datum) {
return ReadImageToDatum(filename, label, 0, 0, true, encoding, datum);
}
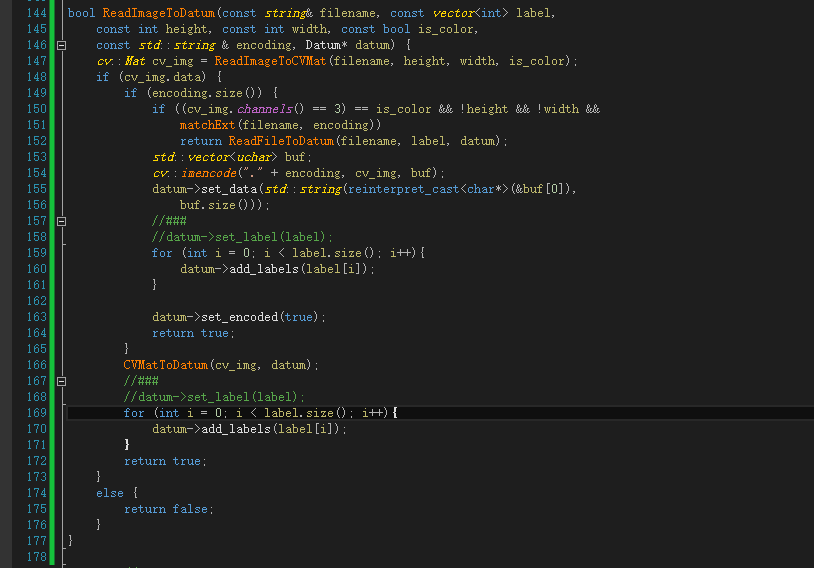
2,io.cpp
Path: Cafe master \ include \ Cafe \ util \ io cpp
Modification point: line 119: the function is modified to support multiple labels. Here, you can consider adding a function after the function (c + + supports function overloading)
line 200: the function is modified to support multiple labels. Here, you can consider adding a function after the function (c + + supports function overloading)
bool ReadImageToDatum(const string& filename, const vector<int> label,
const int height, const int width, const bool is_color,
const std::string & encoding, Datum* datum) {
cv::Mat cv_img = ReadImageToCVMat(filename, height, width, is_color);
if (cv_img.data) {
if (encoding.size()) {
if ((cv_img.channels() == 3) == is_color && !height && !width &&
matchExt(filename, encoding))
return ReadFileToDatum(filename, label, datum);
std::vector<uchar> buf;
cv::imencode("." + encoding, cv_img, buf);
datum->set_data(std::string(reinterpret_cast<char*>(&buf[0]),
buf.size()));
//###
//datum->set_label(label);
for (int i = 0; i < label.size(); i++){
datum->add_labels(label[i]);
}
datum->set_encoded(true);
return true;
}
CVMatToDatum(cv_img, datum);
//###
//datum->set_label(label);
for (int i = 0; i < label.size(); i++){
datum->add_labels(label[i]);
}
return true;
}
else {
return false;
}
}
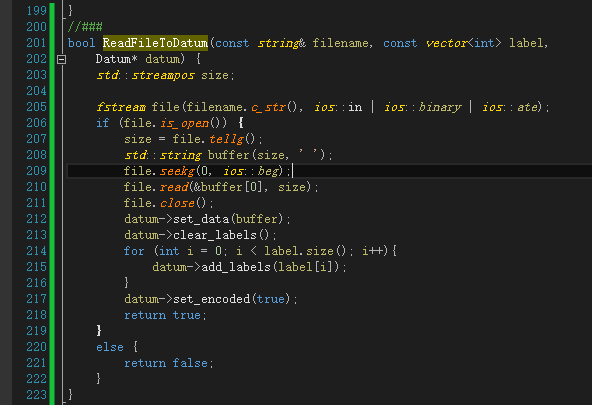
//###
bool ReadFileToDatum(const string& filename, const vector<int> label,
Datum* datum) {
std::streampos size;
fstream file(filename.c_str(), ios::in | ios::binary | ios::ate);
if (file.is_open()) {
size = file.tellg();
std::string buffer(size, ' ');
file.seekg(0, ios::beg);
file.read(&buffer[0], size);
file.close();
datum->set_data(buffer);
datum->clear_labels();
for (int i = 0; i < label.size(); i++){
datum->add_labels(label[i]);
}
datum->set_encoded(true);
return true;
}
else {
return false;
}
}
3, caffe.proto
Path: Cafe master \ SRC \ Cafe \ proto \ cafe proto
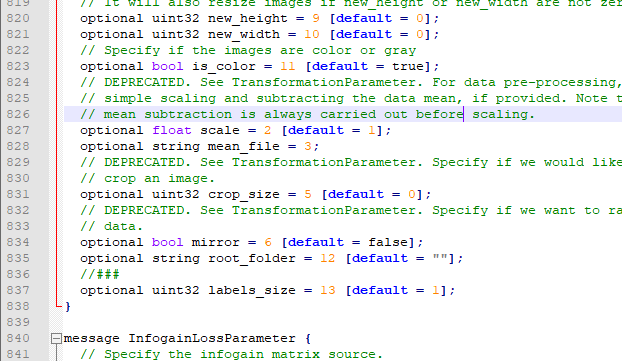
Modification point: add multi category label variable
line 835 add multi category label variable
epeated float labels = 8;
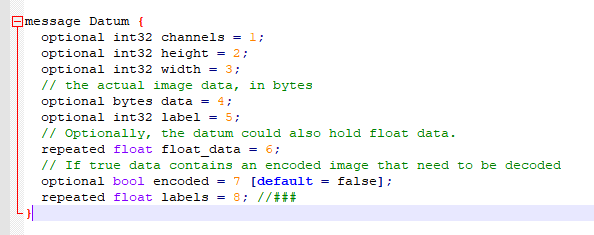
//### optional uint32 labels_size = 13 [default = 1];
4,data_layer.cpp
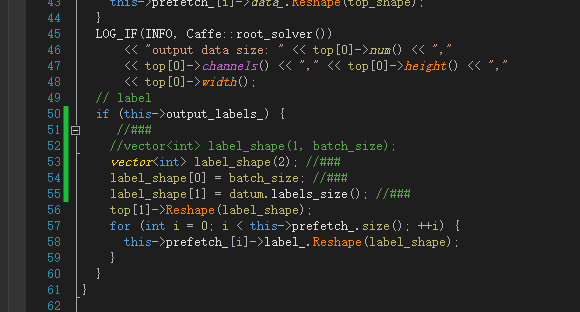
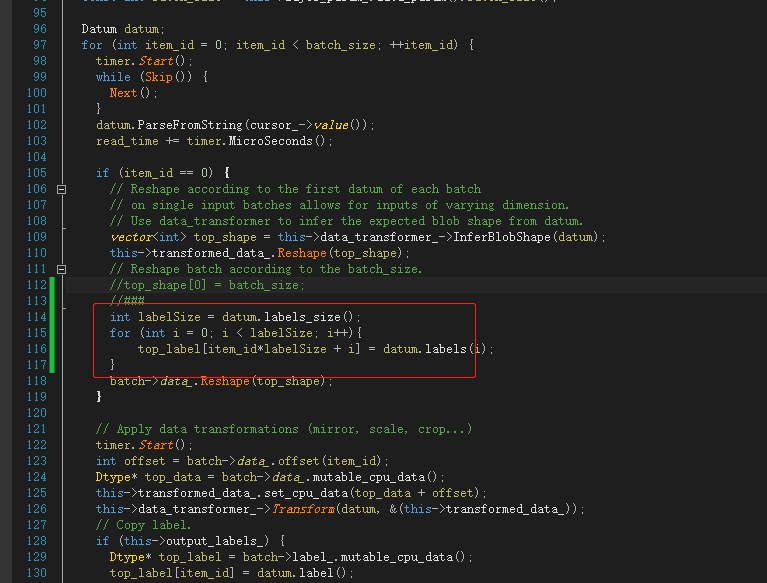
Path: Cafe master \ SRC \ Cafe \ layers \ data_ layer. cpp
Modification point: replace line 51 with read multi label format
Replace line 111 with read multi label format
vector<int> label_shape(2); label_shape[0] = batch_size; label_shape[1] = datum.labels_size();
int labelSize = datum.labels_size();
for (int i = 0; i < labelSize; i++){
top_label[item_id*labelSize + i] = datum.labels(i);
}
batch->data_.Reshape(top_shape);
After modifying the above, make all -j 8 directly
This is the success story.
caffe add DenseBlock layer
DenseBlock layer can use Tongcheng's caffe_ocr also refers to this. Here I use Caffe directly_ In OCR
https://github.com/Tongcheng/caffe
1. Copy denseblock in src\caffe\layers respectively_ layer. CPP and DenseBlock_layer.cu to src\caffe\layers under the target folder
2. Copy denseblock in include\caffe\layers_ layer. HPP to include \ Cafe \ layers under the target folder
3. Modify Caffe master \ SRC \ caffe \ proto \ Caffe proto
line: 425 added in message layerparameter
optional DenseBlockParameter denseblock_param = 200;
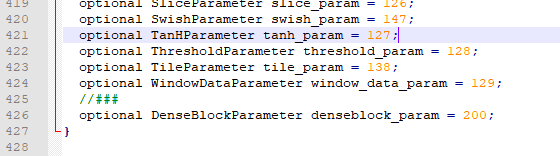
line: 428
message DenseBlockParameter {
//if you don't use BC, BN-ReLU-Conv3 is one transition
//if you use BC, then BN-ReLU-Conv1-BN-ReLU-Conv3 is one transition
optional int32 numTransition = 1 [default = 40];
optional int32 initChannel = 2 [default = 16];
optional int32 growthRate = 3 [default = 12];
//Convolution related parameters
optional int32 pad_h = 4 [default = 1];
optional int32 pad_w = 5 [default = 1];
optional int32 conv_verticalStride = 6 [default = 1];
optional int32 conv_horizentalStride = 7 [default = 1];
optional int32 filter_H = 8 [default = 3];
optional int32 filter_W = 9 [default = 3];
optional FillerParameter Filter_Filler = 10;
//BN related parameters
optional FillerParameter BN_Scaler_Filler = 11;
optional FillerParameter BN_Bias_Filler = 12;
//Performance Related parameters
optional int32 gpuIdx = 15 [default = 0];
//Dropout related parameter
optional bool use_dropout = 16 [default = false];
optional float dropout_amount = 17 [default = 0];
optional bool use_BC = 18 [default = false];
//If it is not ultra space efficient, then it stores output data of conv1
optional bool BC_ultra_space_efficient = 19 [default = false];
optional int32 workspace_MB = 20 [default = 8];
optional float moving_average_fraction = 21 [default = 0.1];
}
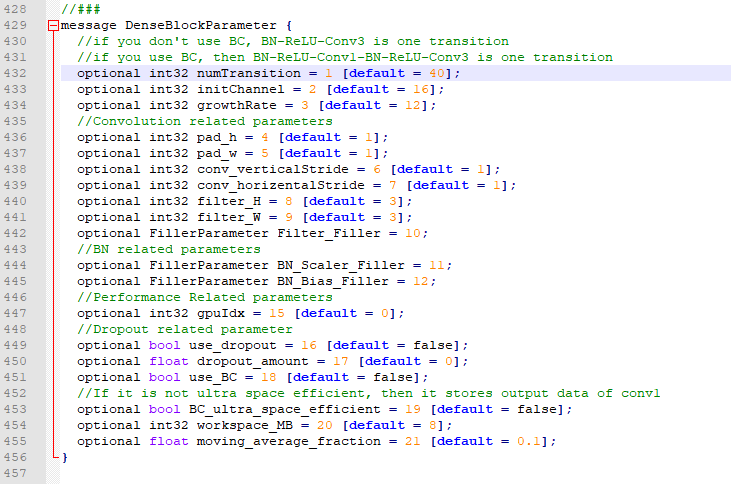
Then recompile and pass it successfully, which means there is no problem
Note here that you need to start use in makeconfig_ Cudnn otherwise, Denseblock compilation will report an error or shield DenseBlock_layer.cu and Denseblock_ layer. The corresponding module calling cudnn in HPP
caffe add transfer layer
Similar to the above operation, Caffe is directly applied_ Transfer in OCR_ layer
1. Copy the transfers in src\caffe\layers respectively_ layer. CPP and transfer_ layer. Cu to src\caffe\layers under the target folder
2. Copy the transfer in include \ Cafe \ layers_ layer. HPP to include \ Cafe \ layers under the target folder
3. Modify Caffe master \ SRC \ caffe \ proto \ Caffe proto
line 247
optional TransposeParameter transpose_param=201;
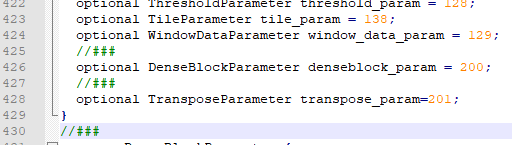
line 1487 added at the end of the document (Note: there is no specific requirement for the adding location)
message TransposeParameter {
// For example, if you want to transpose NxCxHxW into WxNxHxC,
// the parameter should be the following:
// transpose_param { dim: 3 dim: 0 dim: 2 dim: 1 }
// ie, if the i-th dim has value n, then the i-th axis of top is equal to the n-th axis of bottom.
repeated int32 dim=1;
}
Then recompile and pass it successfully, which means there is no problem
Adding ctc layer to caffe
Similar to the above operation, Caffe is directly applied_ Relevant documents in OCR
1. Copy CTC in src\caffe\layers respectively_ decoder_ layer. cpp ,ctcpp_entrypoint.cpp,ctcpp_entrypoint.cu ,warp_ctc_loss_layer.cpp,warp_ctc_loss_layer.cu to src\caffe\layers under the target folder
2. Copy CTC in include \ Cafe \ layers_ decoder_ layer. HPP and warp_ctc_loss_layer.hpp to include \ Cafe \ layers under the target folder
Copy CTC in include \ h,ctcpp.h. detail and contrib to include \ under the target folder
3. Modify Caffe master \ SRC \ caffe \ proto \ Caffe proto
line 429
optional CTCLossParameter ctc_loss_param = 202; optional CTCDecoderParameter ctc_decoder_param = 203;
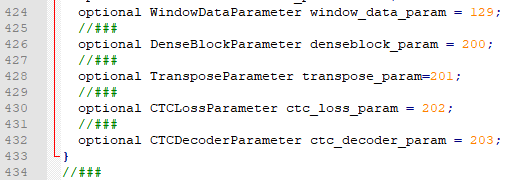
line 699
//###
message CTCDecoderParameter {
// The index of the blank index in the labels. A negative (default)
// value will use the last index
optional int32 blank_index = 1 [default = 0];
// Collapse the repeated labels during the ctc calculation
// e.g. collapse [0bbb11bb11bb0b2] to [01102] instead of [0111102],
// where b means blank label.
// The default behaviour is to merge repeated labels.
// Note: blank labels will be removed in any case.
optional bool ctc_merge_repeated = 2 [default = true];
}
//###
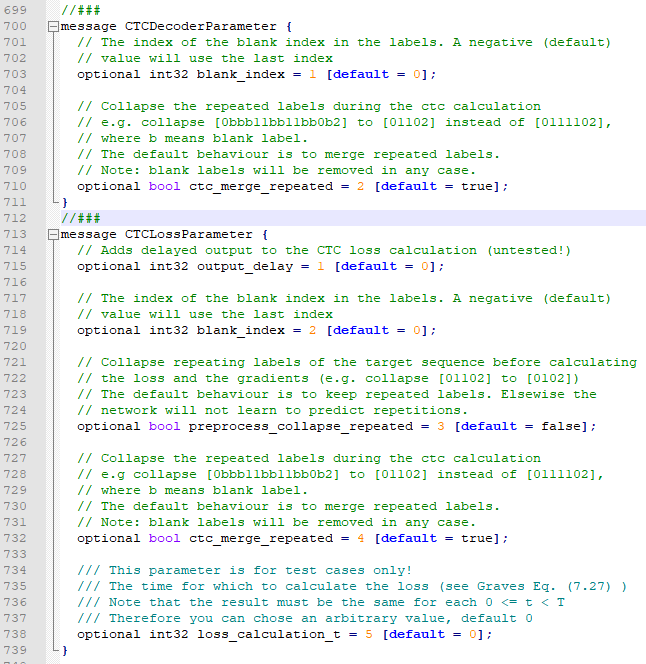
message CTCLossParameter {
// Adds delayed output to the CTC loss calculation (untested!)
optional int32 output_delay = 1 [default = 0];
// The index of the blank index in the labels. A negative (default)
// value will use the last index
optional int32 blank_index = 2 [default = 0];
// Collapse repeating labels of the target sequence before calculating
// the loss and the gradients (e.g. collapse [01102] to [0102])
// The default behaviour is to keep repeated labels. Elsewise the
// network will not learn to predict repetitions.
optional bool preprocess_collapse_repeated = 3 [default = false];
// Collapse the repeated labels during the ctc calculation
// e.g collapse [0bbb11bb11bb0b2] to [01102] instead of [0111102],
// where b means blank label.
// The default behaviour is to merge repeated labels.
// Note: blank labels will be removed in any case.
optional bool ctc_merge_repeated = 4 [default = true];
/// This parameter is for test cases only!
/// The time for which to calculate the loss (see Graves Eq. (7.27) )
/// Note that the result must be the same for each 0 <= t < T
/// Therefore you can chose an arbitrary value, default 0
optional int32 loss_calculation_t = 5 [default = 0];
}
Note that the CTC needs threads. If you don't add them, you can add them in the makefile
caffe add other layers
1. Copy reduce in SRC \ Cafe \ layers Cu to src\caffe\layers under the target folder
Copy interp cpp,interp.cu to src\caffe\util under the target folder
2. Copy interp. In include\caffe\util HPP to include\caffe\util under the target folder
Copy common. In include \ Cuh to include \ under the target folder
3. Modify Caffe master \ SRC \ caffe \ proto \ Caffe proto
line 434
optional InterpParameter interp_param = 204;

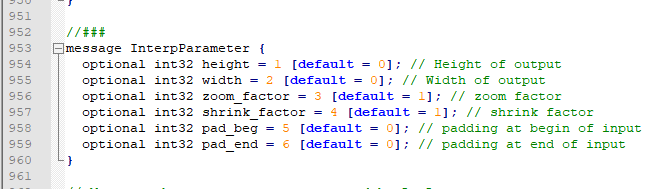
line 952
message InterpParameter {
optional int32 height = 1 [default = 0]; // Height of output
optional int32 width = 2 [default = 0]; // Width of output
optional int32 zoom_factor = 3 [default = 1]; // zoom factor
optional int32 shrink_factor = 4 [default = 1]; // shrink factor
optional int32 pad_beg = 5 [default = 0]; // padding at begin of input
optional int32 pad_end = 6 [default = 0]; // padding at end of input
}
After completing all the above, compile and generate pycaffe, then you can test the densnet+lstm model first
caffe add reverse_layer layer
1. Copy reverse in SRC \ Cafe \ layers_ layer. cpp,reverse_layer.cu,reverse_time_layer.cpp,reverse_time_layer.cu to src\caffe\layers under the target folder
2. Copy reverse in include \ Cafe \ layers_ layer. hpp,reverse_time_layer.hpp to include \ Cafe \ layers under the target folder
3. Modify Caffe master \ SRC \ caffe \ proto \ Caffe proto
lin 435
optional ReverseParameter reverse_param = 205; optional ReverseTimeParameter reverse_time_param = 206;
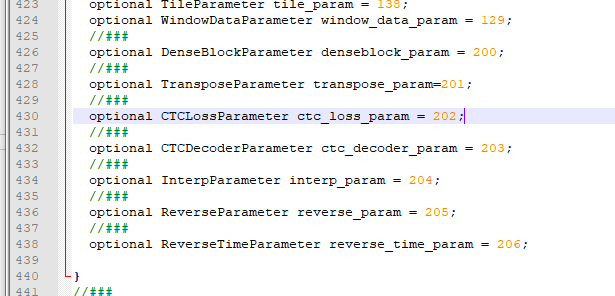
line 1199
//###
message ReverseParameter {
// axis controls the data axis which shall be inverted.
// The layout of the content will not be inverted
//
// The default axis is 0 that means:
// data_previous[n] == data_afterwards[N - n -1]
// where N is the shape of axis(n)
//
// Usually this layer will be used with recurrent layers to invert the
// time axis which is axis 0
// This layer will therefore swap the order in time but not the
// order of the actual data.
optional int32 axis = 1 [default = 0];
}
//###
message ReverseTimeParameter {
// if true the rest of the sequence will not be reversed but copied
// if false no more operation will be performed for the reset.
// this can lead to random numbers in the blob.
optional bool copy_remaining = 1 [default = false];
}
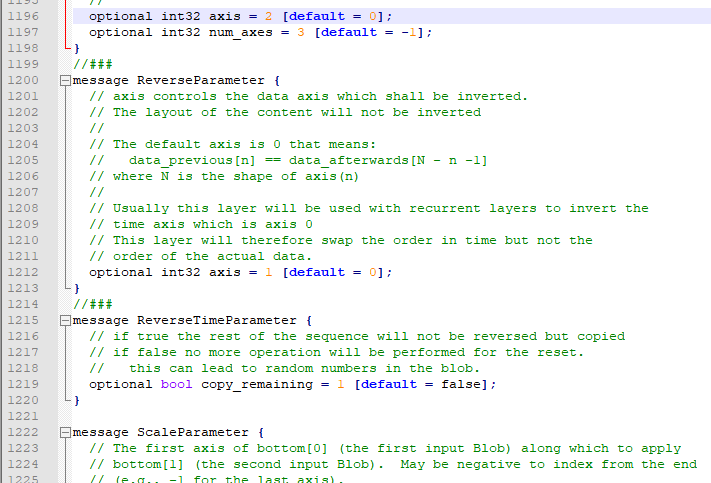
compile
Test prediction effect
After successfully completing the above process, you can start testing Caffe_ Model provided on OCR.
Test densenet res blstm model
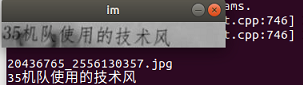
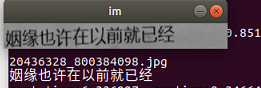
train
caffe needs to be modified before further training
1. Modify image_data_layer.hpp
vector<std::pair<std::string, std::vector<int> > > lines_; vector<std::pair<std::string, std::vector<float> > > regression_lines_;
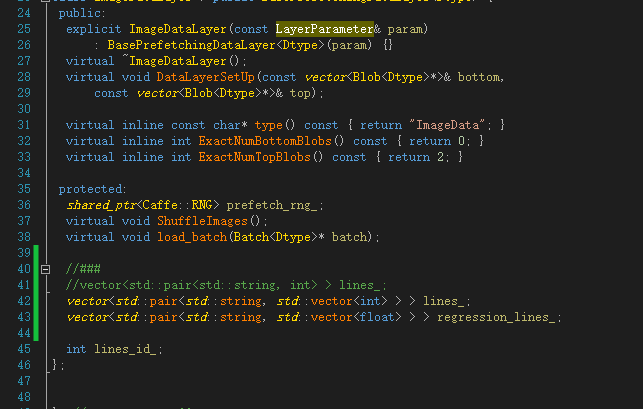
2. Copy group_image_data_layer.hpp to cafe master \ include \ Cafe \ layers
3. Modify memory_data_layer.hpp
int batch_size_, channels_, height_, width_, size_, label_size_;
4. Modify math_function.hpp
template <typename Dtype> void caffe_bound(const int n, const Dtype* a, const Dtype min, const Dtype max, Dtype* y);
5. Modify solver hpp
/**
* @brief Solver that only computes gradients, used as worker
* for multi-GPU training.
*/
template <typename Dtype>
class WorkerSolver : public Solver<Dtype> {
public:
explicit WorkerSolver(const SolverParameter& param,
const Solver<Dtype>* root_solver = NULL)
: Solver<Dtype>(param, root_solver) {}
protected:
void ApplyUpdate() {}
void SnapshotSolverState(const string& model_filename) {
LOG(FATAL) << "Should not be called on worker solver.";
}
void RestoreSolverStateFromBinaryProto(const string& state_file) {
LOG(FATAL) << "Should not be called on worker solver.";
}
void RestoreSolverStateFromHDF5(const string& state_file) {
LOG(FATAL) << "Should not be called on worker solver.";
}
};
6. Copy softmax_loss_layer_multi_label.hpp to cafe master \ include \ Cafe \ layers
7. Copy replace accuracy_ layer. CPP (copy accuracy_layer.cpp to Caffe master \ SRC \ caffe \ layers)
8. Modify data_layer.cpp
if (rand_skip_num_ > 0)
{
unsigned int skip = caffe_rng_rand() % rand_skip_num_;
unsigned int k = 0;
while (k<skip) {
Next();
k++;
}
LOG_IF(INFO, Caffe::root_solver())
<< "skip " << skip;
rand_skip_num_ = 0;//skip once
}
9. Modify memory_data_layer.cpp (3 places in total)
label_size_ = this->layer_param_.memory_data_param().label_size(); ··· vector<int> label_shape;
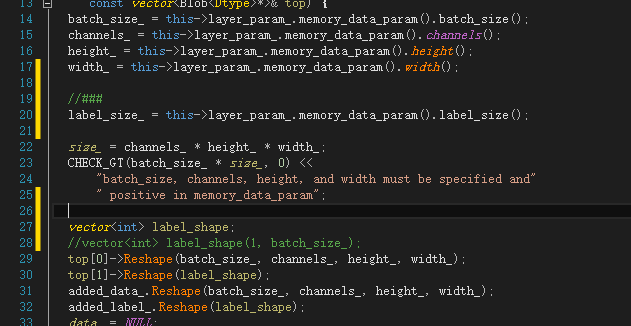
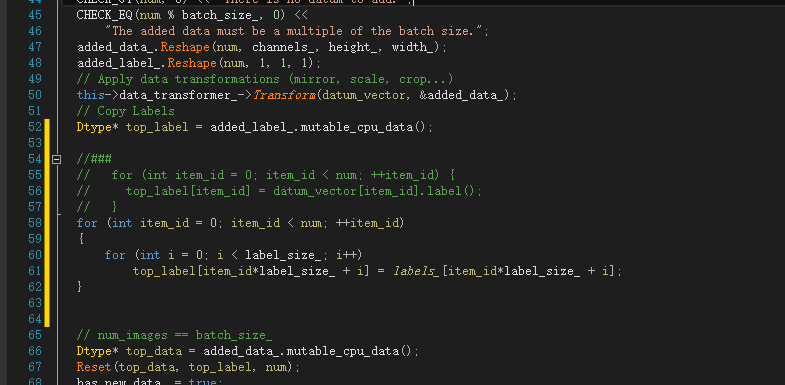
for (int item_id = 0; item_id < num; ++item_id)
{
for (int i = 0; i < label_size_;i++)
top_label[item_id*label_size_ + i] = labels_[item_id*label_size_ + i];
}
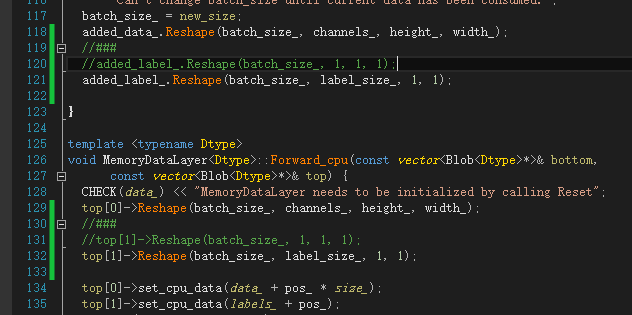
added_label_.Reshape(batch_size_, label_size_, 1, 1); ... top[1]->Reshape(batch_size_, label_size_, 1, 1);
10. Copy softmax_loss_layer_multi_label.cpp,softmax_loss_layer_multi_label.cu to cafe master \ SRC \ Cafe \ layers
11. Modify cafe Proto (5 places in total)
// add noise when train optional bool add_noise = 8 [default = false]; // noise ratio optional float noise_ratio = 9; // If we want to do data augmentation, Scaling factor for randomly scaling input images repeated float scale_factors = 10; // the width for cropped region optional uint32 crop_width = 11 [default = 0]; // the height for cropped region optional uint32 crop_height = 12 [default = 0];
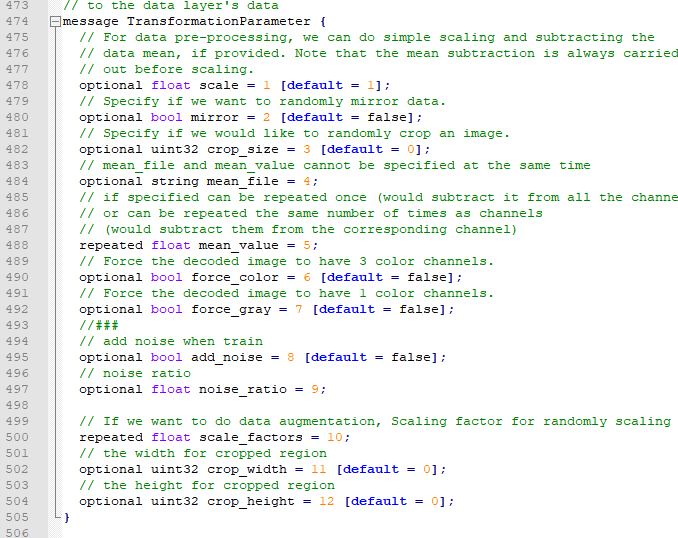
optional bool update_global_stats = 4 [default = false];
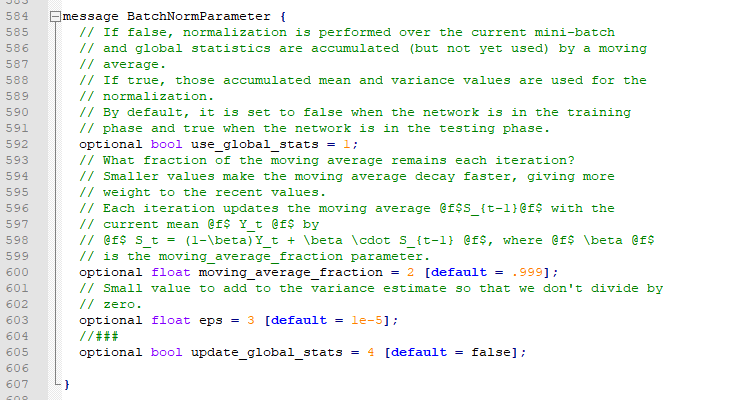
optional uint32 task_class_num = 11 [default = 1];
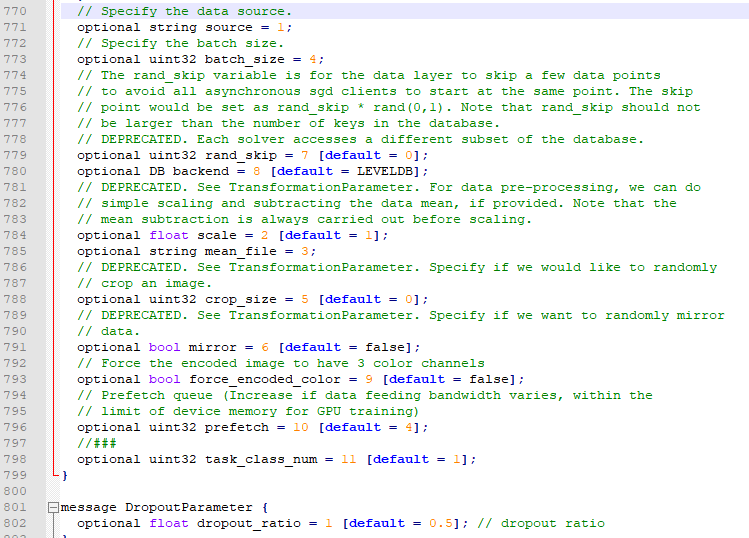
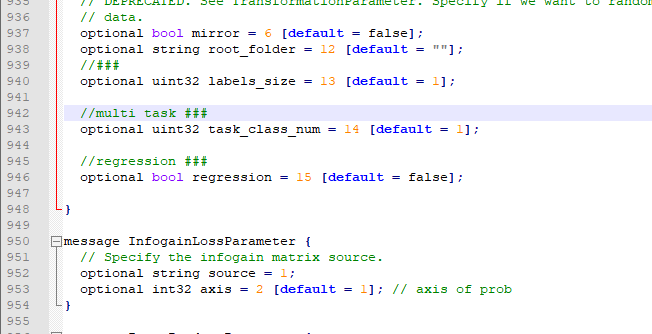
optional uint32 task_class_num = 14 [default = 1]; optional bool regression = 15 [default = false];
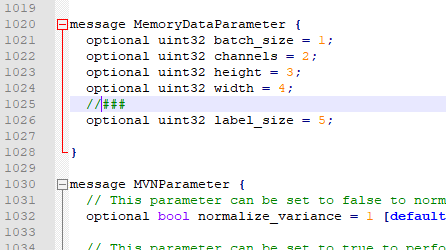
optional uint32 label_size = 5;
11,blocking_ queue. Copy CPP to Caffe master \ SRC \ caffe \ util to replace the original file
12,math_ functions. Copy CPP to Caffe master \ SRC \ caffe \ util to replace the original file
13,data_ reader. Copy CPP to Caffe master \ SRC \ caffe
14,data_ transformer. Copy CPP to Caffe master \ SRC \ caffel to replace the original file
15. Copy lstm_layer_Junhyuk.cpp,lstm_layer_Junhyuk.cu to cafe master \ SRC \ Cafe \ layer
Copy lstm_layer_Junhyuk.hpp to cafe master \ include \ Cafe \ layer
Modify cafe proto
optional LSTMParameter lstm_param = 207;
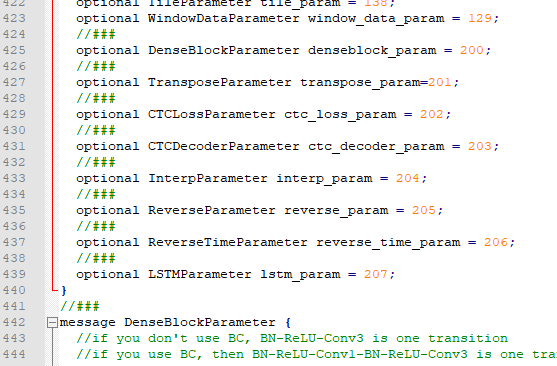
message LSTMParameter {
optional uint32 num_output = 1; // The number of outputs for the layer
optional float clipping_threshold = 2 [default = 0.0];
optional FillerParameter weight_filler = 3; // The filler for weight
optional FillerParameter bias_filler = 4; // The filler for the bias
optional uint32 batch_size = 5 [default = 1];
}
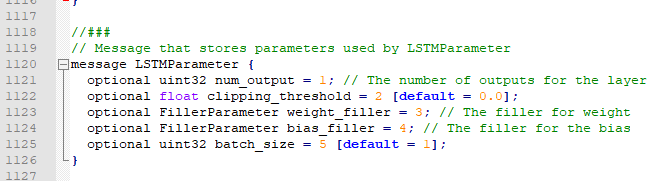
explain:
If compilation errors occur, replace data directly_ layer. cpp,image_data_layer.cpp,io.cpp
Replace data_layer.hpp,io.hpp
Copy data_reader.hpp to cafe master \ include
Modify the part with * * *
message Datum {
optional int32 channels = 1;
optional int32 height = 2;
optional int32 width = 3;
// the actual image data, in bytes
optional bytes data = 4;
repeated int32 label = 5; //***
//optional int32 label = 5; //### ***
// Optionally, the datum could also hold float data.
repeated float float_data = 6;
// If true data contains an encoded image that need to be decoded
optional bool encoded = 7 [default = false];
//repeated float labels = 8; //### ***
}
If there is a save in example, you can directly delete the corresponding folder (three folders in total)
Compile after completing the above operations. After success, you can test the training
Measured training
1. Prepare the training set. Note that ocr supports variable length, but the input data needs to be fixed length, that is, supplement 0 to the same length
2. Training test
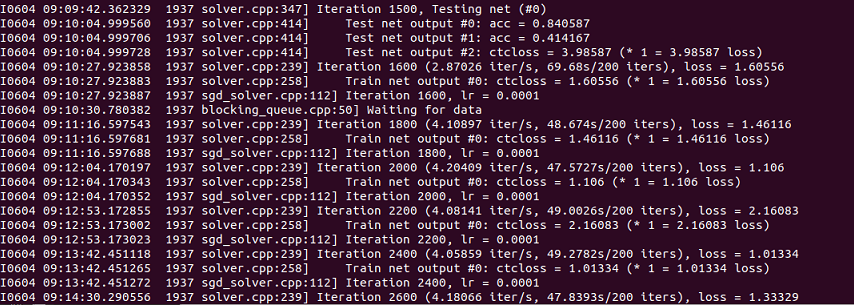
This completes the whole migration
Finally, the whole project is put on github
https://github.com/mqyw/caffe-ocr-linxu-master