🍑 Source power 😍
For the article, the title is the essence of its concentration. Then for the video, its cover may be the most eye-catching frame. Station B, as a hot short video platform recently, has a variety of dances in its dance area, especially house dance, which is deeply loved by "house men". Don't talk to me about black silk and jk, I really don't like it 😆 )

So I tried to use the crawler to get the cover of station B.
🍉 Web page acquisition
Station B has anti climbing measures. I analyzed it according to the web page at the beginning, but it didn't work.
On second thought, in such a hot station B, I must not be the only one who wants to climb, so I began to search for relevant articles and videos.
Pop, soon, I found an article about crawling the cover picture according to the AV number of station B. I tried it. Eh, it really works 🤩 (ecstatic)
# Get the cover page according to aid https://api.bilibili.com/x/web-interface/view?aid=(aid)
But on second thought, since last year, station B has started to use BV number. Where did you get the AV number for me? Where did the AV number in the article come from? No, I read the date of the article again. 2019, oh, it's okay. People write that meeting. Station B hasn't been changed yet 😂
The method is always more difficult than that. Now at least I know how to use the AV number. Can't I use the BV number to find the AV number? I'm so smart.
Find out. A big man shared the api of BV, Click send to big guy page
I saw, oh, it's still the boss of station B. you don't talk about martial ethics, but you teach others to engage in station B (but I like it) 🤪 )
# Obtain cid according to BV number https://api.bilibili.com/x/player/pagelist?bvid=(bvid, with BV at the beginning!) # Obtain video playlist according to BV number and cid https://api. bilibili. com/x/player/playurl? CID = (CID) & QN = (QN) & bvid = (bvid, start with BV!) # Get aid according to BV number and cid https://api. bilibili. com/x/web-interface/view? CID = (CID) & bvid = (bvid, start with BV!)
Summarize the api of the above content, then the idea will be there. It's just good to have a hand. Just follow the boss! 😏
First find the cid according to the BV number, then get the aid according to the BV number and cid, and then get the cover according to the aid.
And the data in the crawling process is basically json data. Of which:
The data of CID is in ['data'][0]['cid'] of json
The data of aid is in ['data']['aid'] of json
The data of the cover image is in ['data']['pic'] of json
For a more detailed process, I wrote it in the comments of the code 👇
🍇 Complete code
# -*- coding: UTF-8 -*-
# @Time: 2021/8/17 20:12
# @Author: distant star
# @CSDN: https://blog.csdn.net/qq_44921056
import os
import json
import requests
import chardet
from fake_useragent import UserAgent
# Randomly generated request header
ua = UserAgent(verify_ssl=False, path='D:/Pycharm/fake_useragent.json')
# Random handover request header
def random_ua():
headers = {
"accept-encoding": "gzip", # gzip compression coding can improve the file transfer rate
"user-agent": ua.random
}
return headers
# create folder
def path_creat():
_path = "D:/B Station cover/"
if not os.path.exists(_path):
os.mkdir(_path)
return _path
# The crawled page content is processed in json format
def get_text(url):
res = requests.get(url=url, headers=random_ua())
res.encoding = chardet.detect(res.content)['encoding'] # Unified character coding
res = res.text
data = json.loads(res) # json formatting
return data
# Obtain av number according to bv number
def get_aid(bv):
url_1 = 'https://api.bilibili.com/x/player/pagelist?bvid={}'.format(bv)
response = get_text(url_1)
cid = response['data'][0]['cid'] # Get cid
url_2 = 'https://api.bilibili.com/x/web-interface/view?cid={}&bvid={}'.format(cid, bv)
response_2 = get_text(url_2)
aid = response_2['data']['aid'] # Get aid
return aid
# Obtain the cover picture according to the av number
def get_image(aid):
url_3 = 'https://api.bilibili.com/x/web-interface/view?aid={}'.format(aid)
response_3 = get_text(url_3)
image_url = response_3['data']['pic'] # Get picture download connection
image = requests.get(url=image_url, headers=random_ua()).content # Get picture
return image
# Download cover
def download(image, file_name):
with open(file_name, 'wb') as f:
f.write(image)
f.close()
def main():
k = 'Y'
while k == 'Y': # Cycle all the time according to user needs
path = path_creat() # Create a folder to save the cover page of station B
bv = input("Please enter the name of the video bv number:")
image_name = input("Please give the cover you want to download a favorite name:")
aid = get_aid(bv)
image = get_image(aid)
file_name = path + '{}.jpg'.format(image_name)
download(image, file_name)
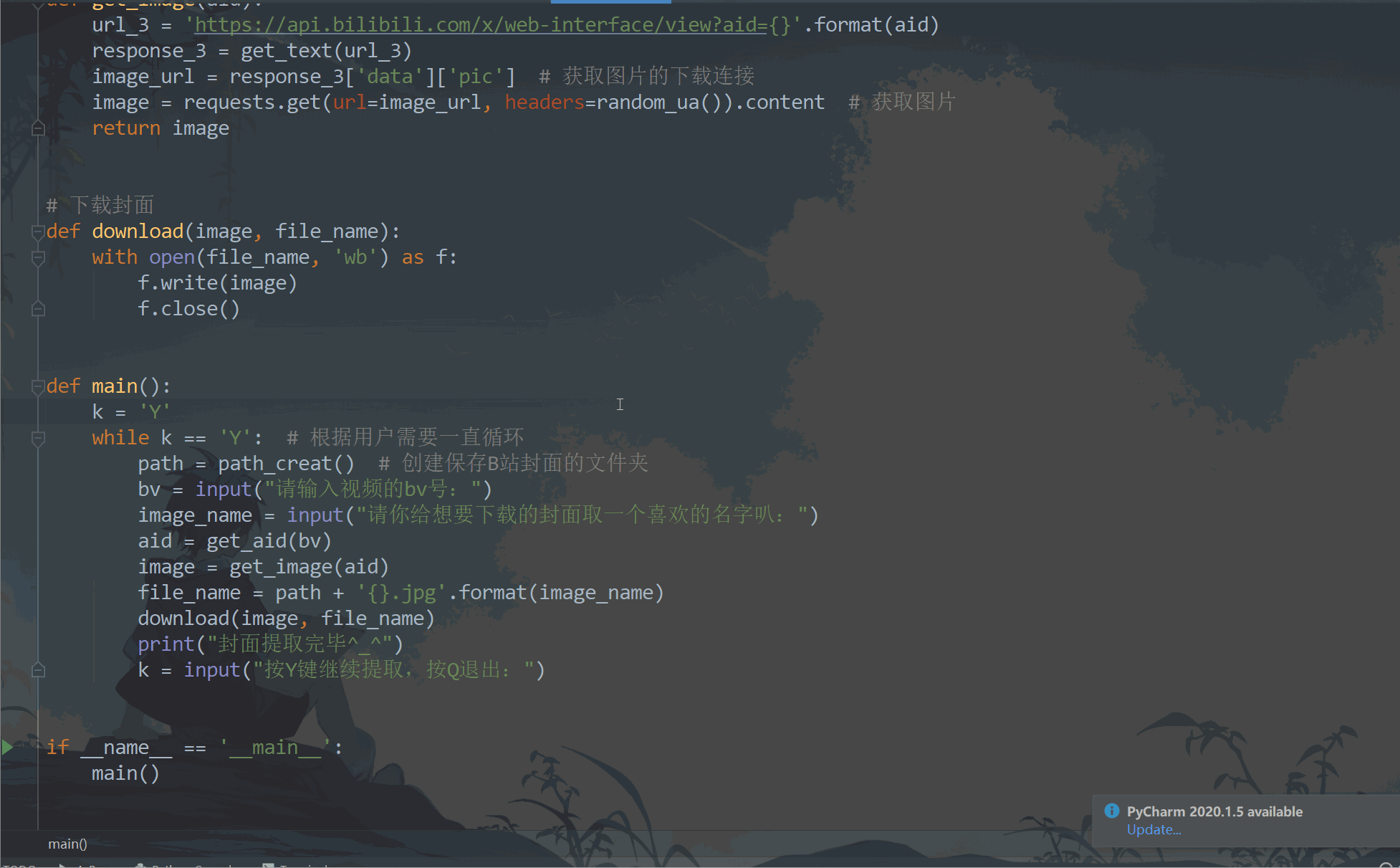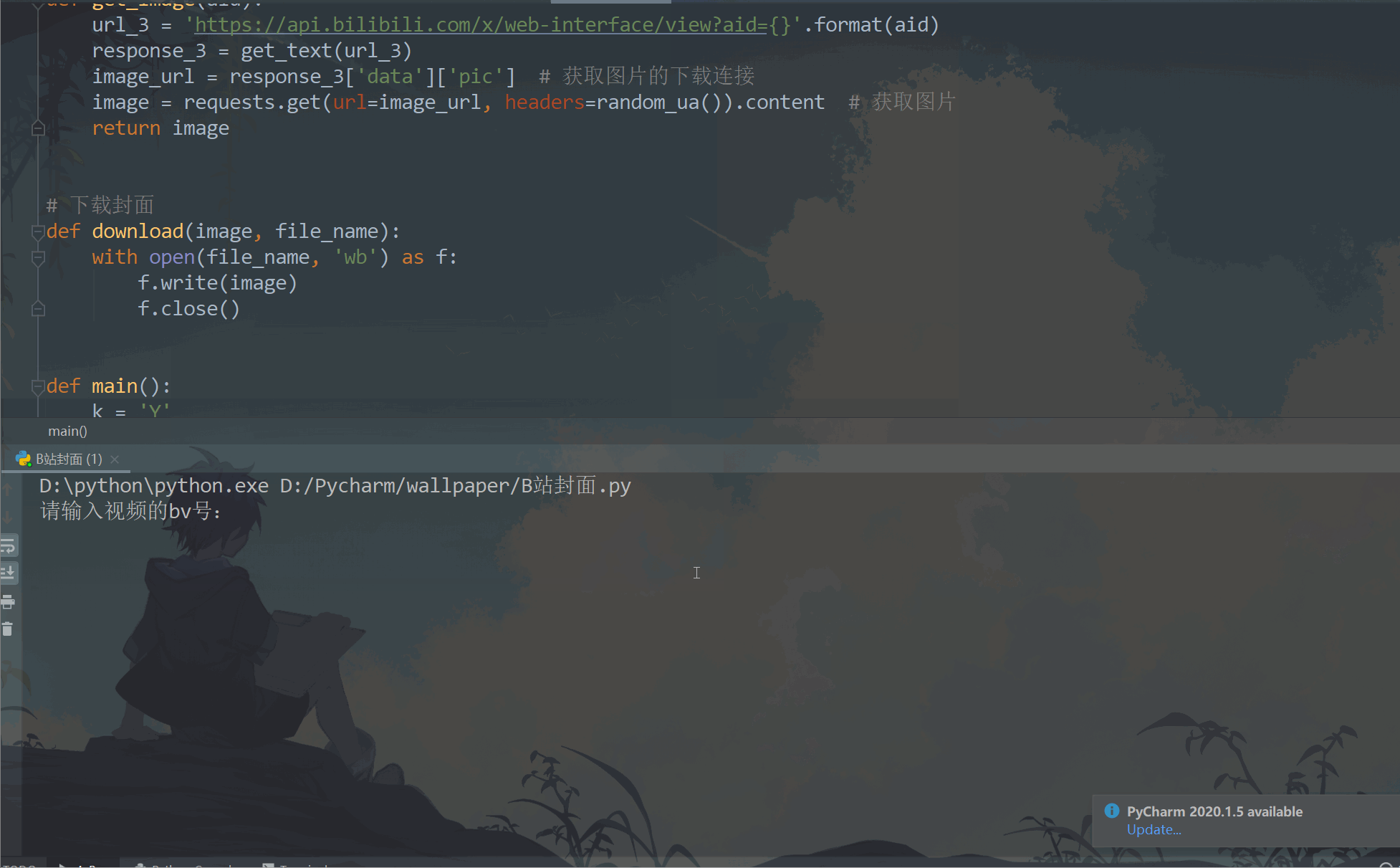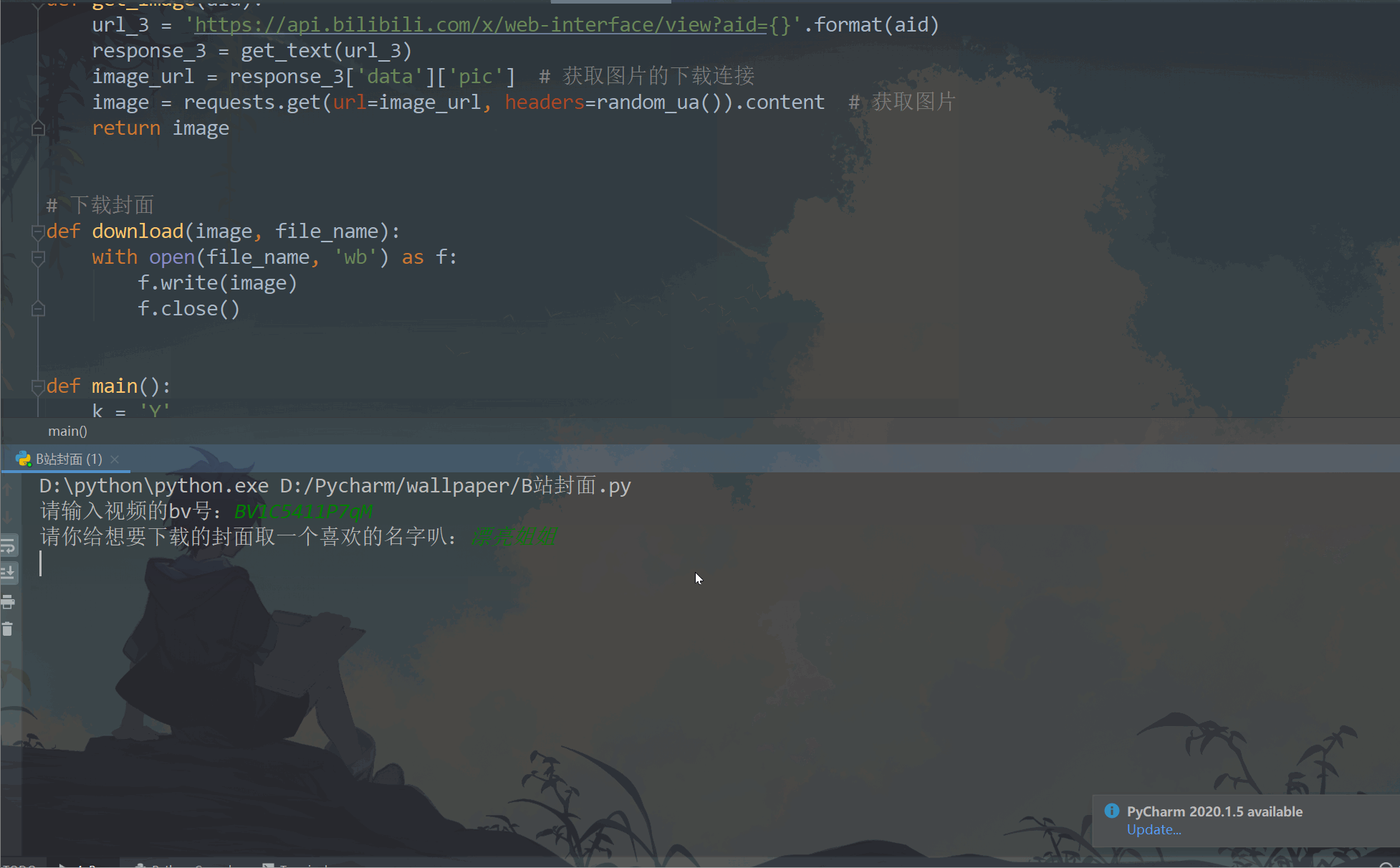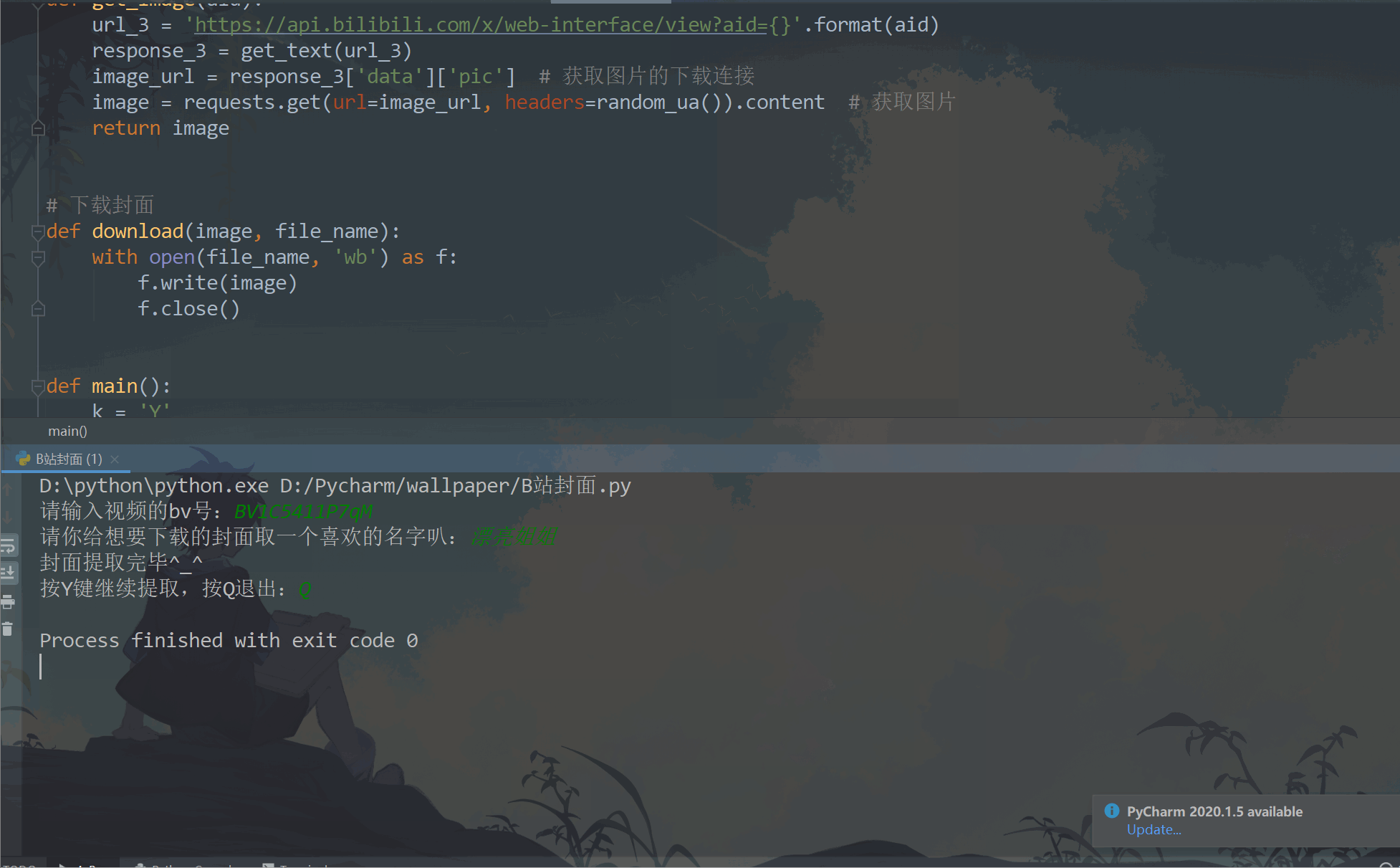
print("Cover extraction completed^_^")
k = input("Press Y Key to continue extraction, press Q sign out:")
if __name__ == '__main__':
main()
The code can be copied and run directly. If it is helpful to you, remember to praise it. It is also the greatest encouragement to the author. For deficiencies, you can make more corrections and communicate in the comment area.
🍋 Operation result: beautiful sister, bring it to you 🤣
- Take the video with BV1C5411P7qM as an example:

🍊 PhotoZoom Pro
Online website: https://bigjpg.com/zh
This can be used online. You can enlarge your picture online. Interested partners can try it by themselves. I think the effect is OK.
🍍 Reference articles
Reference article 1: python crawls the cover of station B
Reference article 2: bilibili's new BV api
Author: distant star
CSDN: https://blog.csdn.net/qq_44921056
This article is only for exchange and learning. It is prohibited to reprint it without the permission of the author, let alone for other purposes. Violators will be prosecuted.