1, Channel Selectors
Next, take a look at Channel Selectors
Channel Selectors include: Replicating Channel Selector and Multiplexing Channel Selector
The Replicating Channel Selector is the default Channel selector. It will send the events collected by the Source to all channels
Check the official documentation for an explanation of this default channel selector
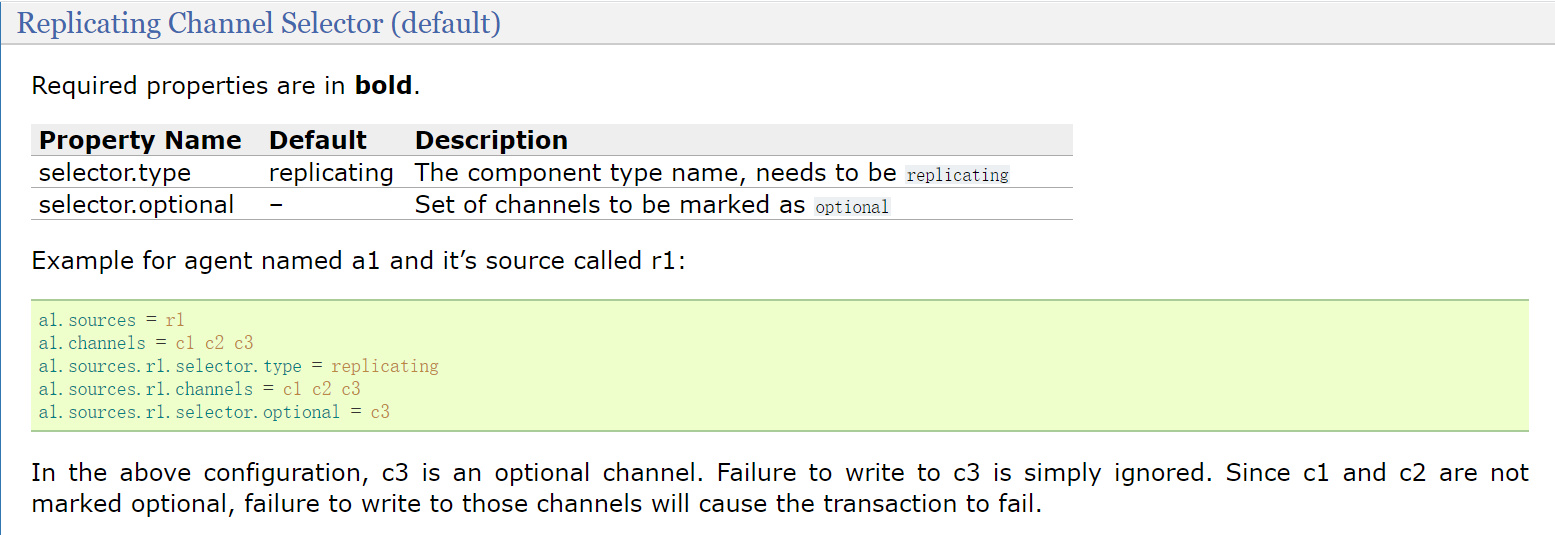
In the configuration of this example, c3 is an optional channel. Failure to write to c3 will be ignored. Since c1 and c2 are not marked as optional, failure to write to these channels will cause the transaction to fail
For this configuration, generally speaking, the data of source will be sent to the three chanles of c1, c2 and c3, which can ensure that c1 and c2 will receive all data, but c3 cannot
This selector The optional parameter is optional and can be used without configuration.
If there are multiple channels, you can specify the names of multiple channels directly after the channels parameter. The names of multiple channels are separated by spaces,
In fact, you can see that the name is channels with s. from the name, you can see that it supports multiple channels
Another Channel selector is the Multiplexing Channel Selector, which means that events will be sent to different channels according to the value in the header in the Event
Take a look at the introduction on the official website
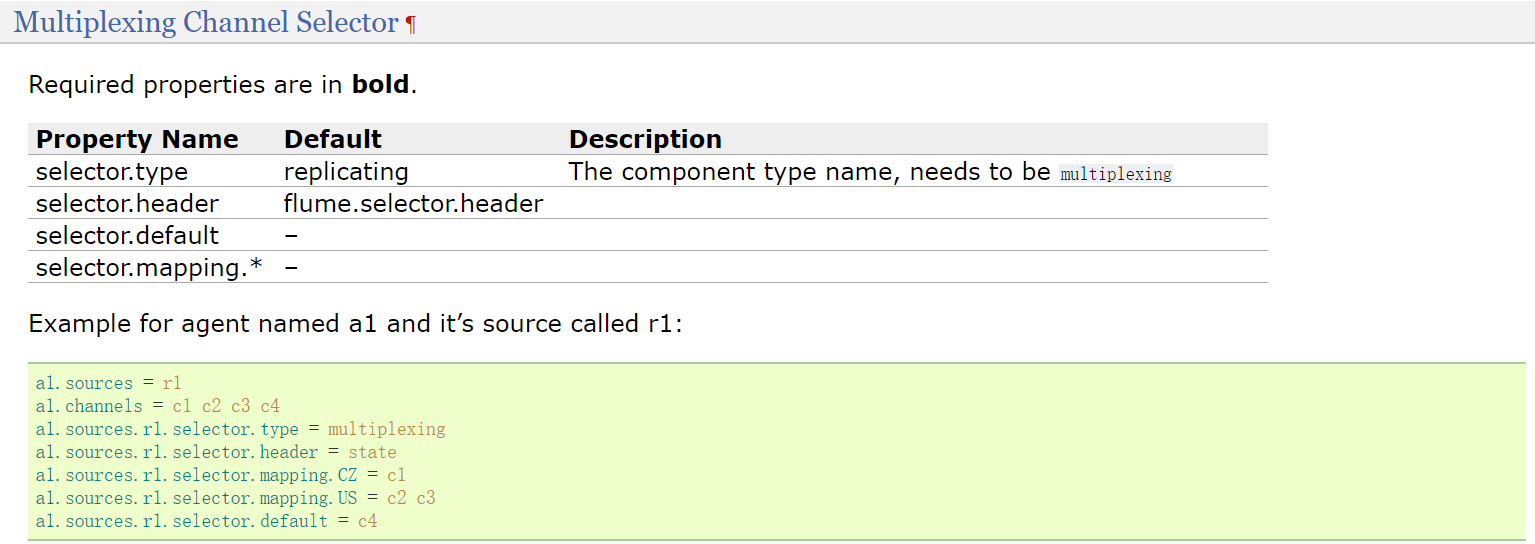
In the configuration of this example, four channels are specified, C1, c2, c3 and c4
The specific channel to which the data collected by source will be sent will be based on the value of the state attribute in the header in the event. This is through the selector Header controlled
If state The value of the property is CZ,Send to c1 If state The value of the property is US,Send to c2 c3 If state If the value of the property is another value, it is sent to c4
These rules are through selector Mapping and selector Default controlled
In this way, the data can be distributed to different channel s according to certain rules.
Next, let's look at a case
2, Replicating Channel Selector for multiple channels
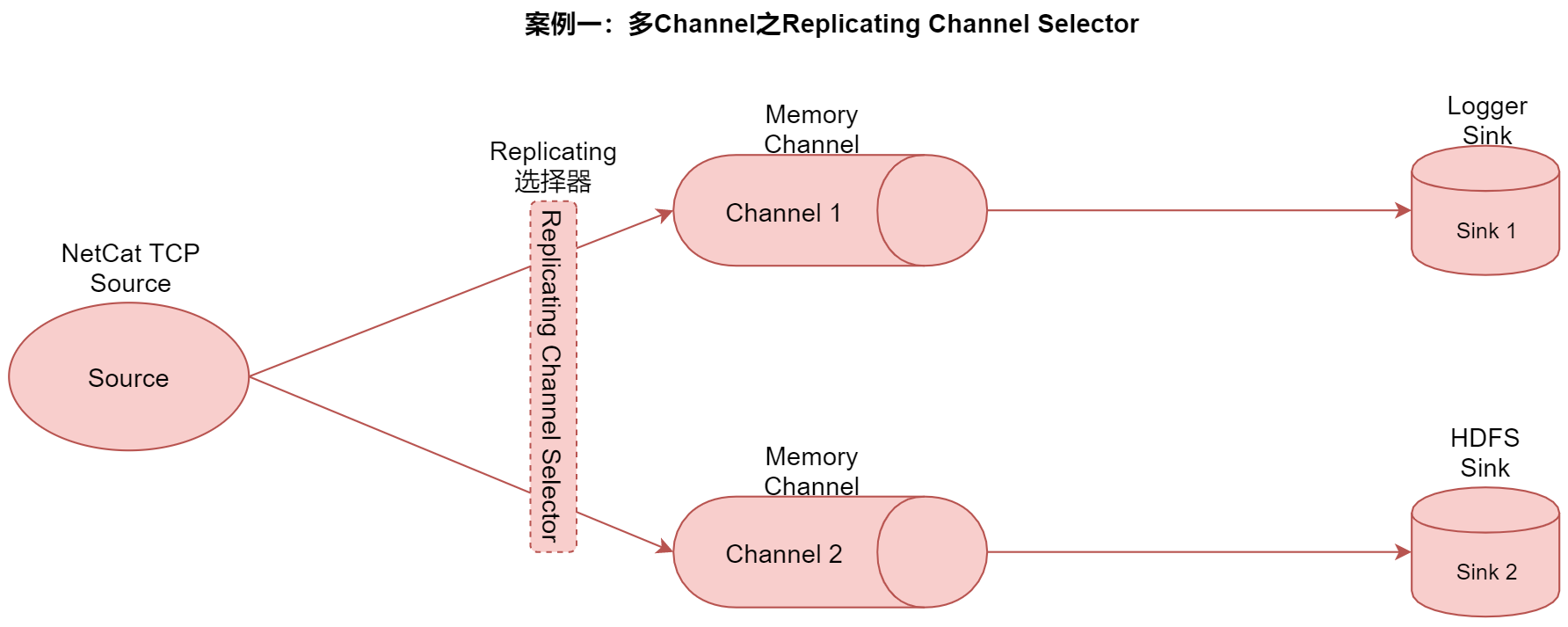
In this case, we use the Replicating selector to repeatedly send the data collected by the source to two channels. Finally, each channel is followed by a sink, which is responsible for storing the data in different storage media for later use.
In practical work, this kind of demand is quite common, that is, we hope to store a data in different storage media after collecting it. The characteristics and application scenarios of different storage media are different, typically hdfssink and kafkasink,
The off-line data is stored on the disk through hdfssink, which is convenient for off-line data calculation later
Real time data storage is realized through kafkasink, which is convenient for real-time calculation later,
Since we haven't learned kafka yet, we use the loggersink agent here first.
Next, configure the agent according to the source, channel and sink listed in the figure
Create a TCP - to - replicatingchannel in the conf directory of flume in bigdata04 conf
[root@bigdata04 conf]# vi tcp-to-replicatingchannel.conf # The name of the agent is a1 # Specify the names of source component, channel component and Sink component a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2 # Configure source component a1.sources.r1.type = netcat a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 44444 # Configure CHANLE selector [copying is the default, so it can be omitted] a1.sources.r1.selector.type = replicating # Configuring channel components a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Configuring sink components a1.sinks.k1.type = logger a1.sinks.k2.type = hdfs a1.sinks.k2.hdfs.path = hdfs://192.168.182.100:9000/replicating a1.sinks.k2.hdfs.fileType = DataStream a1.sinks.k2.hdfs.writeFormat = Text a1.sinks.k2.hdfs.rollInterval = 3600 a1.sinks.k2.hdfs.rollSize = 134217728 a1.sinks.k2.hdfs.rollCount = 0 a1.sinks.k2.hdfs.useLocalTimeStamp = true a1.sinks.k2.hdfs.filePrefix = data a1.sinks.k2.hdfs.fileSuffix = .log # Connect the components a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
Start Agent
[root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/tcp-to-replicatingchannel.conf -Dflume.root.logger=INFO,console
Generate test data and connect to socket through telnet
[root@bigdata04 ~]# telnet localhost 44444 Trying ::1... Connected to localhost. Escape character is '^]'. hello OK
Viewing the effect, you can see the log information output by Flume on the console
2020-05-03 09:51:51,123 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
2020-05-03 09:51:51,141 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false
2020-05-03 09:51:51,396 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:246)] Creating hdfs://192.168.182.100:9000/replicating/data.1588470711142.tmp
View the contents of the file generated by sink2 in hdfs
[root@bigdata04 ~]# hdfs dfs -cat hdfs://192.168.182.100:9000/replicating/data.1588470711142.tmp hello
This is the application of Replicating Channel Selector.