1 problem status
At first, we used the simplest offset+limit paging query method. The pseudo code is as follows:
List<Student> students = new ArrayList<>();
int limit = n;
int offset = 0;
do {
students = SELECT * FROM [table] WHERE status = [status] AND gradeId = [id] LIMIT [limit] OFFSET [offset];
push(pos);
update [table] set updateTime = NOW() where id in students[0].getId, students[1].getId...;
offset += limit;
} while (CollectionUtils.isNotEmptry(students));Through the pressure test, we find that this paging query will have performance problems. For example, assuming that the table size has 500w rows, the query time will be longer and longer with the increase of offset:
SELECT * FROM student WHERE status = 1 AND gradeId = 4 LIMIT 100 OFFSET 10000; //7ms SELECT * FROM student WHERE status = 1 AND gradeId = 4 LIMIT 100 OFFSET 100000; //54ms SELECT * FROM student WHERE status = 1 AND gradeId = 4 LIMIT 100 OFFSET 1000000; //503ms SELECT * FROM student WHERE status = 1 AND gradeId = 4 LIMIT 100 OFFSET 2000000; //1.013s SELECT * FROM student WHERE status = 1 AND gradeId = 4 LIMIT 100 OFFSET 3000000; //1.509s SELECT * FROM student WHERE status = 1 AND gradeId = 4 LIMIT 100 OFFSET 4000000; //2.035 s
When the offset reaches the million level, the query time is more than 1s, which is intolerable in online business. To understand the causes of this phenomenon, we need to understand the following concepts:
2. Cause analysis
-
Clustered & non clustered index
InnoDB's index is implemented based on B + tree. Each InnoDB table has a special index called clustered index. Each leaf node of the clustered index stores a row of real data in the table. The table data store is globally unique, so the cluster index is also unique, which is often generated by using the primary key. The indexes generated by other non primary key columns are non clustered indexes, also known as secondary indexes. In addition to storing the values of the indexed columns, their leaf nodes only store the key values of the primary key, which are associated with the real data through the primary key. In general, the difference between a clustered index and a non clustered index is whether a leaf node stores an entire row of records.
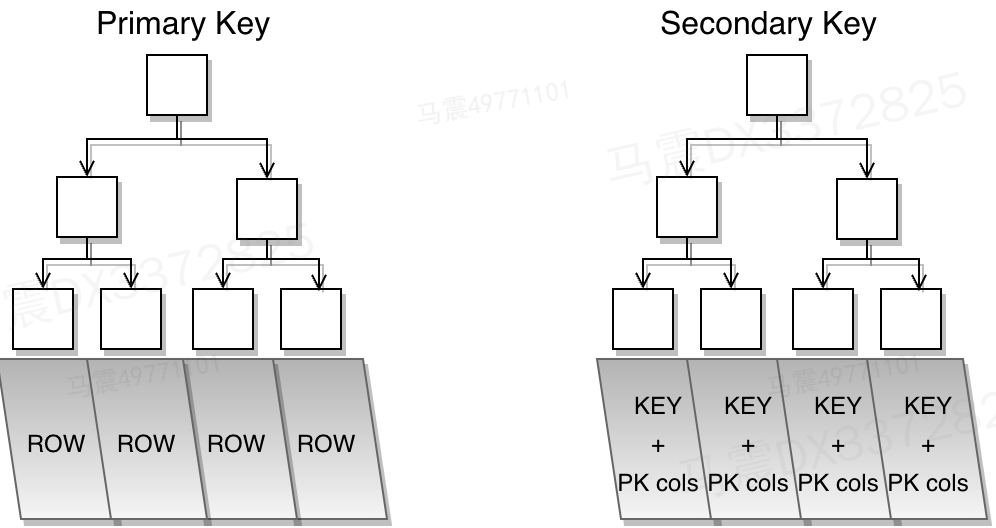
-
OFFSET implementation of InnoDB engine
InnoDB engine is involved in the query execution process of offset. It also queries each row before offset. Specifically, it queries the data block from the first row to the OFFSET+LIMIT row, and then discards the data returned before offset.
3. The student list is structured as follows
CREATE TABLE `student` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Primary key id', `gradeId` int(11) NOT NULL DEFAULT '0' COMMENT 'grade id', `name` varchar(255) NOT NULL DEFAULT '' COMMENT 'Student name', `status` tinyint(4) NOT NULL DEFAULT '0' COMMENT 'Student status, 1: in school, 2: out of school', `creator` varchar(255) NOT NULL DEFAULT '' COMMENT 'Founder', `createTime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time', `updater` varchar(255) NOT NULL DEFAULT '' COMMENT 'Update person', `updateTime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Update time', PRIMARY KEY (`id`), UNIQUE KEY `IX_GradeId` (`gradeId`), KEY `IX_Status` (`status`), KEY `IX_CreateTime` (`createTime`), KEY `IX_UpdateTime` (`updateTime`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
Based on the above two concepts and combined with the structure of the student table, it is not difficult for us to analyze the reasons for the increase in time-consuming, that is, because status and gradeId belong to secondary indexes, it is impossible to query the whole row of data only through them, and a table return operation is required, that is, when using non clustered indexes to find data, It is necessary to search the complete records in the cluster index according to the primary key value, which is time-consuming. With the increase of offset, each row query before offset needs to be returned to the table, resulting in a longer query time.
3 problem solution
Since returning to the table will cause additional IO time, and offset will lead to unnecessary query rows, a natural optimization direction is to carry out paging query directly based on ID. The side effect of ID based paging query is that it will involve all the data in the table. However, due to the optimization of sub table and hot and cold data isolation (see 3.1, data scale optimization), the sub table only contains the subscription data of one online push task, so there is no redundant and invalid data in the table. See the following pseudo code for specific implementation:
List<Student> students = new ArrayList<>();
List<Student> pushedStudents = new ArrayList<>();
int limit = n;
int endId = SELECT id FROM [table] ORDER BY createTime DESC limit 1;
int startId = SELECT id FROM [table] ORDER BY createTime ASC limit 1;
do {
students = SELECT * FROM [table] WHERE id > [endId - limit] and id <= [endId];
for(Student student : students) {
if(status == 1 and gradeId == xxx]){
push(student);
pushedStudents.add(student);
}
}
update [table] set updateTime = NOW() where id in pushedStudents[0].getId, pushedStudents[1].getId...;
endId -= limit;
} while (endId > startId);| Paging query mode | Indexes | Return to table | Number of rows involved |
|---|---|---|---|
| LIMIT+OFFSET | Non clustered index: status, gradeId | yes | OFFSET+LIMIT |
| Based on ID | Cluster index: id | no | LIMIT |
The ID based paging query method directly uses the clustered index without returning to the table or querying the data before the paging offset, which reduces the query time.