preface:
The distributed storage system needs to make the data evenly distributed on the physical devices in the cluster. At the same time, it is particularly important to make the data reach the balance state again after the new devices join and the old devices exit. After the new device is added, the data will be migrated from different old devices. After the old device exits, the data migration is allocated to other devices. Data such as files and block devices are segmented, hashed, and then written to different devices, so as to improve I/O concurrency and aggregation bandwidth as much as possible.
In the actual scenario, how to balance cluster recovery through minimum data migration and how to allocate backups to devices are very important issues to make the data as safe as possible. Ceph solves the above problems after extending the ordinary hash function. Ceph's hash based data distribution algorithm is CRUSH.
CRUSH supports copy, Raid and erasure code data backup strategies, and maps multiple backups of data to underlying devices in different fault domains of the cluster.
straw algorithm
Four basic selection algorithms were initially provided:

By observing the data in the figure, unique has the highest execution efficiency and the worst ability to resist structural changes. The execution efficiency of straw algorithm is worse than that of unique tree, but the ability to resist structural changes is the strongest. Because data reliability is the most important, with the introduction of more and more devices for capacity expansion and the passage of service time, the firmware of cluster devices needs to be replaced frequently. Therefore, at present, Ceph clusters in the basic production environment choose straw algorithm.
Straw algorithm randomly calculates a signature length for each element and selects the element with the longest signature length for output. The longer the signature length, the greater the probability that the element will be selected, and the greater the probability that the data will fall on it. Straw algorithm takes the weight difference between the current element and the previous and subsequent elements as the benchmark for calculating the signature length of the next element. Therefore, irrelevant data migration will be caused every time osd is added or deleted. It was later modified that the signature length calculation is only related to its own weight, which avoids this phenomenon. It is called straw2 algorithm, which is currently the default algorithm of ceph.
cluster map
Cluster map is a logical description of cluster hierarchical topology. Its simple topology is as follows: Data Center - > machining - > host - > disk. Therefore, cluster map adopts the data structure of tree. The root node is the entrance of the whole cluster; All leaf node devices are the real smallest physical storage devices (disks); The intermediate node bucket can be a collection of devices or a collection of low-level buckets.
The hierarchical relationship of cluster map is mapped through a two-dimensional table such as < bucket, items >. Each bucket saves the numbers of all its direct children, that is, items. When items is empty, it indicates that bucket is a leaf node.
The simple diagram is as follows. The lowest leaf node device (such as disk) stores data, the middle is a bucket of host type, and the top root is the cluster entry:
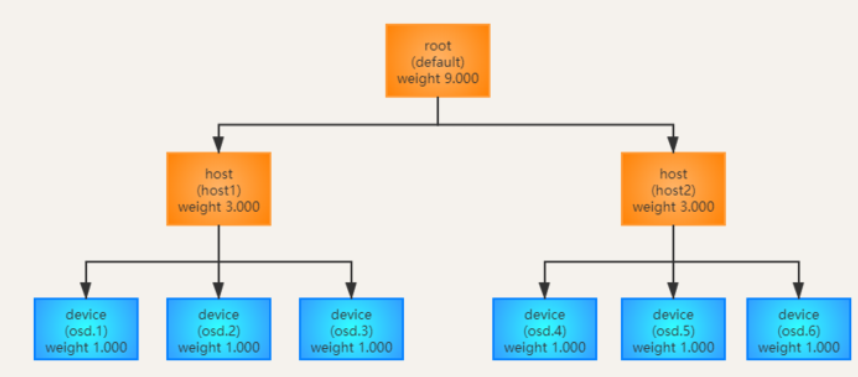
Configuration example:
host default_10.10.10.125 { # Type host, name default_ ten10.10.125 id -3 # The id of the bucket, the digital id of the root and the bucket are all negative values. Only the device is a non negative digital id, indicating that the device is a real device carrying data. # weight 14.126 # Weight, the default is the sum of the weights of child item s alg straw2 # bucket's random selection algorithm, straw2 is used here hash 0 # rjenkins1 # Using the hash function rjinkins1 item osd.0 weight 6.852 # osd. Weight of 0 item osd.1 weight 7.274 # osd. Weight of 1 }
placement rule
cluster map defines the physical topology description of the storage cluster. placement rule completes data mapping, that is, the rule that determines how to select the object copy of a PG. users can customize the distribution of the copy in the cluster.
The placement rule can contain multiple operations, including the following three types:
1.take: select the bucket with the specified number from the cluster map. The system defaults to the root node
2.select: receive the bucket entered by take and randomly select the specified type and quantity of item s.
step [choose|chooseleaf] [firstn|indep] <Num> type <bucket-type> [choose|chooseleaf]: choose There are different options for operation choose Select out Num Types are bucket-type Son of bucket chooseleaf Select out Num Types are bucket-type Son of bucket,Then recurse to the leaf node to select one OSD equipment [firstn|indep]: ceph There are two select Algorithm (depth first traversal). The difference is that the results of erasure code requirements are orderly. Therefore, if the specified output quantity is 4 and cannot be met: firstn(Multiple copies:[1,2,4] indep(Erasure code:[1,2,CRUSH_ITEM_NONE,4] [Num] : Num == 0,Selected sub buket by pool Number of copies set pool Number of copies > Num > 0,Selected sub buket by Num Num < 0, Selected sub buket by pool Set the number of copies minus Num Absolute value of [type] :Type of fault domain, if yes rack,Ensure that the selected replicas are located on the host disks in different racks. If yes host,Ensure that the selected replica is on a different host. If the selected item cannot be used due to faults, conflicts, etc., it will be executed again select.
3.emit: output selection results
Configuration example:
rule <rulename> { id [a unique whole numeric ID] type [ replicated | erasure ] min_size <min-size> max_size <max-size> step take <bucket-name> [class <device-class>] step [choose|chooseleaf] [firstn|indep] <Number> type <bucket-type> step emit }
For example:
rule data { ruleset 0 //ruleset number type replicated //Multiple copy types min_size 1 //Copy minimum value is 1 max_size 10 //The maximum number of copies is 10 step take default //choice default buket input{take(default)} step chooseleaf firstn 0 type host //Select the number of hosts under the current replica OSD{select(replicas, type)} step emit //Output the to be distributed bucket List of{emit(void)} }
Selection method
CHRUSH algorithm relies on the above algorithm (straw2 by default) to map pg. enter pg_id, Cluster map, Cluster rule, and random factors are hashed to output a group of OSD lists, that is, the number of the PG to fall on the OSD.
However, the selected OSD may conflict or overload, so it needs to be re selected:
1.Conflict: the selected item already exists in the output item, such as osd.1 It already exists in the output list, and the next one is also selected after calculation osd.1,At this time, you need to adjust the random factor and calculate again for selection. 2.Overload or failure: refers to the selected OSD Unable to provide enough space to store data, although CRUSH The algorithm can theoretically make the data in all device(Disk), but this is not the case: Small scale clusters, PG Less, then CRUSH The input sample size is not enough, resulting in uneven distribution of data calculation. crush It is not perfect for the uniform distribution of multi copy mode data. ceph Introduction of overload test reweight Manual intervention on OSD The probability of choice, reweight The higher the value of is set, the higher the probability of passing the test,
Therefore, the overload can be reduced OSD of reweight And increase low load OSD of reweight Balance the data.
The incoming overload test can also distinguish between temporary failure and permanent deletion of OSD
If the OSD temporarily fails (for example, pull out the corresponding disk for a period of time, and ceph sets it to OUT), you can set its reweight value to 0.000, screen it from the candidate entries by using the overload test, and then migrate the data it carries to other OSDs. After recovery, set the reweight to 1.000 to migrate back the data (referring to the new data generated during OSD offline)
If it is permanently deleted, it will be deleted from the candidate entry, even if it is added again later. Because the unique number in the cluster map changes, it carries different data from before, resulting in large-scale data balancing in the cluster.
Transferred from: https://www.likecs.com/default/index/show?id=98612