Unified and distributed file system designed for excellent performance, reliability and scalability
Ceph is unified in that it can provide file system, block storage and object storage, and distributed in that it can be dynamically expanded
Ceph seems to have developed into a complete set of storage solutions. The upper layer can provide object storage (RGW), block storage (RBD) and CephFS. It can be said that it is a set of storage solutions suitable for various scenarios, which are very flexible and have room to play
assembly
Basic components
Monitor: a Ceph cluster needs a small cluster composed of multiple monitors. They synchronize data through Paxos to save OSD metadata.
OSD: full name: Object Storage Device, that is, the process responsible for returning specific data in response to client requests. A Ceph cluster generally has many OSDs. The main function is for data storage. When a hard disk is directly used as the storage target, a hard disk is called OSD. When a directory is used as the storage target, this directory is also called OSD.
MDS: its full name is Ceph Metadata Server. It is a metadata service that CephFS service depends on. It is not required for object storage and block device storage.
Object: the lowest storage unit of Ceph is an object object. A piece of data and a configuration are all objects. Each object contains ID, metadata and original data.
Pool: pool is a logical partition of storage objects. It usually specifies the type of data redundancy and the number of copies. The default is 3 copies. For different types of storage, separate pools are required, such as RBD.
PG: the full name of Placement Grouops is a logical concept. An OSD contains multiple PG. The PG layer is actually introduced to better allocate and locate data. Each Pool contains many PGs, which is a collection of objects. The smallest unit of server-side data balancing and recovery is PG.
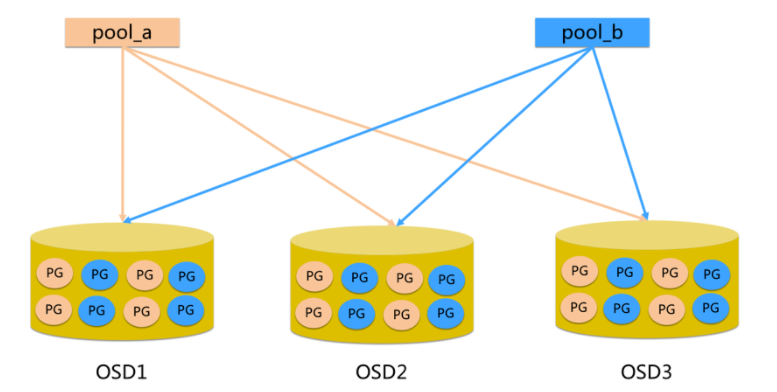
- pool is the logical partition when ceph stores data. It acts as a namespace
- Each pool contains a certain number (configurable) of PG
- Object s in PG are mapped to different objects
- The pool is distributed throughout the cluster
FileStore and BlueStore: FileStore is the back-end storage engine used by default in the old version. If FileStore is used, xfs file system is recommended. BlueStore is a new back-end storage engine, which can directly manage raw hard disks and abandon local file systems such as ext4 and xfs. It can operate the physical hard disk directly, and the efficiency is much higher.
RADOS: the full name Reliable Autonomic Distributed Object Store is the essence of Ceph cluster, which is used for data distribution, Failover and other cluster operations.
Librados: librados is a library provided by Rados. Because Rados is a protocol, it is difficult to access it directly. Therefore, the upper RBD, RGW and CephFS are accessed through librados. At present, it provides PHP, Ruby, Java, Python, C and C + + support.
CRUSH: CRUSH is the data distribution algorithm used by Ceph, which is similar to consistent hash to distribute data to the expected place.
RBD: full name: RADOS Block Device. It is a block device service provided by Ceph externally, such as virtual machine hard disk. It supports snapshot function.
RGW: its full name is RADOS Gateway. It is an object storage service provided by Ceph. The interface is compatible with S3 and Swift.
CephFS: its full name is Ceph File System, which is the file system service provided by Ceph.
Block storage
Typical equipment
Disk array, hard disk, is mainly used to map raw disk space to the host.
advantage
- Data protection is provided by means of Raid and LVM.
- Multiple cheap hard disks are combined to improve capacity.
- A logical disk composed of multiple disks to improve reading and writing efficiency.
shortcoming
- When the SAN architecture is adopted for networking, the optical fiber switch has high cost.
- Data cannot be shared between hosts.
Usage scenario
- Docker container, virtual machine disk storage allocation.
- Log storage
- file store
- ...
file store
In order to overcome the problem that block storage files cannot be shared, the typical devices FTP and NFS server have file storage. Setting up FTP and NFS servers on the server is file storage.
advantage
- The cost is low. Any machine can do it
- Convenient file sharing
shortcoming
- Low read / write rate
- Slow transmission rate
Usage scenario
- Log storage
- File storage with directory structure
- ...
Object storage
Typical equipment
Distributed server with built-in large capacity hard disk (swift, s3); Multiple servers have built-in high-capacity hard disks, installed with object storage management software, and provide external read-write access.
advantage
- High speed read / write with block storage.
- It has the characteristics of file storage and sharing
Usage scenario: (suitable for updating data with less change)
- Picture storage
- Video storage
- ...
characteristic:
1. High performance:
a. abandon the traditional centralized storage metadata addressing scheme and adopt CRUSH algorithm, with balanced data distribution and high parallelism.
b. considering the isolation of disaster recovery domain, it can realize the replica placement rules of various loads, such as cross machine room, rack awareness, etc.
c. It can support the scale of thousands of storage nodes and support terabytes to petabytes of data.
2. High availability:
a. the number of copies can be flexibly controlled.
b. support fault domain separation and strong data consistency.
c. automatic repair and self-healing in a variety of fault scenarios.
d. no single point of failure, automatic management.
3. High scalability:
a. decentralization.
b. flexible expansion.
c. increase linearly with the increase of nodes.
4. Rich features:
a. support three storage interfaces: block storage, file storage and object storage.
b. support user-defined interfaces and multi language drivers.
Detailed configuration
Distributed File System means that the physical storage resources managed by the file system are not necessarily directly connected to the local node, but connected to the node through the computer network.
The design of distributed file system is based on client / server mode
Common distributed file systems
Lustre , Hadoop , FsatDFS , Ceph , GlusterFS
Ceph assembly
OSDs: storage devices
Monitors: cluster monitoring component
MDSs: stores the metadata of the file system (this component is not required for object storage and block storage)
Client: ceph client
1, Prepare the machine
| hostname | ip | role | describe |
|---|---|---|---|
| admin-node | 192.168.0.130 | ceph-deploy | Management node |
| node1 | 192.168.0.131 | mon.node1 | ceph node |
| node2 | 192.168.0.132 | osd.0 | ceph node, OSD node |
| node3 | 192.168.0.133 | osd.1 | ceph node, OSD node |
Management node: admin node
ceph nodes: node1, node2, node3
All nodes: admin node, node1, node2, node3
1. Modify host name
2. Modify hosts file
# vi /etc/hosts 192.168.0.130 admin-node 192.168.0.131 node1 192.168.0.132 node2 192.168.0.133 node3
2, Ceph node installation
1. Install NPT (all nodes)
We recommend that NTP service (especially Ceph Monitor node) be installed on all Ceph nodes to avoid failure due to clock drift. See clock for details.
# sudo yum install ntp ntpdate ntp-doc
2. Configure ssh login without password on the management node
3. Turn off core protection
4. Configure yum source
vi /etc/yum.repos.d/ceph.repo [Ceph] name=Ceph packages for $basearch baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/ enabled=1 gpgcheck=0 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc priority=1 [Ceph-noarch] name=Ceph noarch packages baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/ enabled=1 gpgcheck=0 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc priority=1 [ceph-source] name=Ceph source packages baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS/ enabled=1 gpgcheck=0 type=rpm-md gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc priority=1
3, Build clusters
1. Prepare for installation and create a folder
Create a directory on the management node to store the configuration files and key pairs generated by CEPH deploy.
$ cd ~ $ mkdir my-cluster $ cd my-cluster
Note: if you have trouble after installing ceph, you can use the following commands to clear the package and configure it:
// Remove installation package $ ceph-deploy purge admin-node node1 node2 node3 // Clear configuration $ ceph-deploy purgedata admin-node node1 node2 node3 $ ceph-deploy forgetkeys
2. Create clusters and monitoring nodes
Create a cluster and initialize the monitoring node:
$ ceph-deploy new {initial-monitor-node(s)}
Here node1 is the monitor node, so execute:
$ ceph-deploy new node1
After completion, there are three more files under my clster: CEPH conf,ceph-deploy-ceph.log and CEPH mon. keyring.
- Problem: if "[ceph_deploy] [error] runtimeerror: remote connection got closed, ensure requirement is disabled for node1", execute sudo visudo to comment out the defaults requirement.
3. Modify the configuration file
$ cat ceph.conf
The contents are as follows:
[global] fsid = 89933bbb-257c-4f46-9f77-02f44f4cc95c mon_initial_members = node1 mon_host = 192.168.0.131 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx
Change the default number of copies in Ceph configuration file from 3 to 2, so that only two OSDs can reach the active + clean state. Add osd pool default size = 2 to the [global] section:
$ sed -i '$a\osd pool default size = 2' ceph.conf
If there are multiple network cards,
You can write the public network into the [global] section of Ceph configuration file:
public network = {ip-address}/{netmask}
4. Install Ceph
Install ceph on all nodes:
$ ceph-deploy install admin-node node1 node2 node3
- Question: [ceph_deploy] [error] runtimeerror: failed to execute command: Yum - y install EPEL release
resolvent:
sudo yum -y remove epel-release
5. Configure the initial monitor(s) and collect all keys
$ ceph-deploy mon create-initial
After completing the above operations, these key rings should appear in the current directory:
{cluster-name}.client.admin.keyring
{cluster-name}.bootstrap-osd.keyring
{cluster-name}.bootstrap-mds.keyring
{cluster-name}.bootstrap-rgw.keyring
6. Add 2 OSD s
- Log in to the Ceph node, create a directory for the OSD daemon, and add permissions.
$ ssh node2 $ sudo mkdir /var/local/osd0 $ sudo chmod 777 /var/local/osd0/ $ exit $ ssh node3 $ sudo mkdir /var/local/osd1 $ sudo chmod 777 /var/local/osd1/ $ exit
- Then, execute CEPH deploy from the management node to prepare the OSD.
$ ceph-deploy osd prepare node2:/var/local/osd0 node3:/var/local/osd1
- Finally, activate OSD.
$ ceph-deploy osd activate node2:/var/local/osd0 node3:/var/local/osd1
7. Copy the configuration file and admin key to the management node and Ceph node
$ ceph-deploy admin admin-node node1 node2 node3
8. Make sure you know CEPH client. admin. Keyring has correct operation permissions
$ sudo chmod +r /etc/ceph/ceph.client.admin.keyring
9. Check the health status of the cluster and OSD nodes
[zeng@admin-node my-cluster]$ ceph health
HEALTH_OK
[zeng@admin-node my-cluster]$ ceph -s
cluster a3dd419e-5c99-4387-b251-58d4eb582995
health HEALTH_OK
monmap e1: 1 mons at {node1=192.168.0.131:6789/0}
election epoch 3, quorum 0 node1
osdmap e10: 2 osds: 2 up, 2 in
flags sortbitwise,require_jewel_osds
pgmap v22: 64 pgs, 1 pools, 0 bytes data, 0 objects
12956 MB used, 21831 MB / 34788 MB avail
64 active+clean
[zeng@admin-node my-cluster]$ ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR PGS
0 0.01659 1.00000 17394M 6478M 10915M 37.24 1.00 64
1 0.01659 1.00000 17394M 6478M 10915M 37.25 1.00 64
TOTAL 34788M 12956M 21831M 37.24
MIN/MAX VAR: 1.00/1.00 STDDEV: 0
4, Expand cluster (capacity expansion)

1. Add OSD
Add an OSD on node1 2.
- Create directory
$ ssh node1 $ sudo mkdir /var/local/osd2 $ sudo chmod 777 /var/local/osd2/ $ exit
- Prepare OSD
$ ceph-deploy osd prepare node1:/var/local/osd2
- Activate OSD
$ ceph-deploy osd activate node1:/var/local/osd2
- Check the cluster status and OSD nodes:
[zeng@admin-node my-cluster]$ ceph -s
cluster a3dd419e-5c99-4387-b251-58d4eb582995
health HEALTH_OK
monmap e1: 1 mons at {node1=192.168.0.131:6789/0}
election epoch 3, quorum 0 node1
osdmap e15: 3 osds: 3 up, 3 in
flags sortbitwise,require_jewel_osds
pgmap v37: 64 pgs, 1 pools, 0 bytes data, 0 objects
19450 MB used, 32731 MB / 52182 MB avail
64 active+clean
[zeng@admin-node my-cluster]$ ceph osd df
ID WEIGHT REWEIGHT SIZE USE AVAIL %USE VAR PGS
0 0.01659 1.00000 17394M 6478M 10915M 37.24 1.00 41
1 0.01659 1.00000 17394M 6478M 10915M 37.24 1.00 43
2 0.01659 1.00000 17394M 6494M 10899M 37.34 1.00 44
TOTAL 52182M 19450M 32731M 37.28
MIN/MAX VAR: 1.00/1.00 STDDEV: 0.04
2. Add MONITORS
Add monitoring nodes in ndoe2 and node3.
- Modify mon_initial_members,mon_host and public network configuration:
[global] fsid = a3dd419e-5c99-4387-b251-58d4eb582995 mon_initial_members = node1,node2,node3 mon_host = 192.168.0.131,192.168.0.132,192.168.0.133 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx osd pool default size = 2 public network = 192.168.0.120/24
- Push to other nodes:
$ ceph-deploy --overwrite-conf config push node1 node2 node3
- Add monitoring node:
$ ceph-deploy mon add node2 node3
- To view cluster status and monitoring nodes:
[zeng@admin-node my-cluster]$ ceph -s
cluster a3dd419e-5c99-4387-b251-58d4eb582995
health HEALTH_OK
monmap e3: 3 mons at {node1=192.168.0.131:6789/0,node2=192.168.0.132:6789/0,node3=192.168.0.133:6789/0}
election epoch 8, quorum 0,1,2 node1,node2,node3
osdmap e25: 3 osds: 3 up, 3 in
flags sortbitwise,require_jewel_osds
pgmap v3919: 64 pgs, 1 pools, 0 bytes data, 0 objects
19494 MB used, 32687 MB / 52182 MB avail
64 active+clean
[zeng@admin-node my-cluster]$ ceph mon stat
e3: 3 mons at {node1=192.168.0.131:6789/0,node2=192.168.0.132:6789/0,node3=192.168.0.133:6789/0}, election epoch 8, quorum 0,1,2 node1,node2,node3