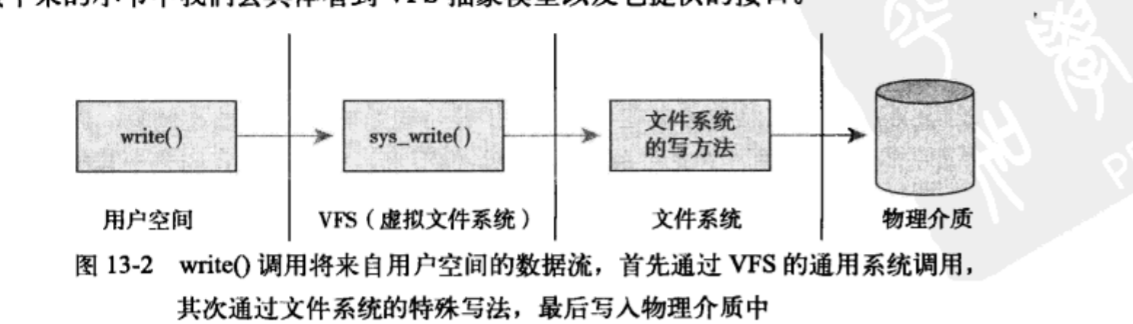
The virtual file system is VFS, and the kernel provides file and file related interfaces. All files in the system not only depend on VFS coexistence, but also rely on VFS coordination.
Common file interfaces, including read, write and open, can be used to read files and hard disks.
The reason why a unified interface can be used to read and write files is that linux provides a unified abstraction layer
1.unix file system
unix uses four abstract concepts: file, directory and index point
2.VFS object and data structure
VFS mainly has four objects, which are
Superblock object
Inode object
Directory object
File object
A directory is another form of file. VFS treats a directory as a file
The four objects are:
super_operation object, including the methods that can be called by a specific file
inode_operation object, including the methods that the kernel can call for specific files, including create and link
dentry_operation object, including methods that can be called by a specific directory, such as d_compare and d_delete
file_operation object, the method that can be called for the opened file, such as read or write open.
3. Superblock object
Various file systems must implement a superblock object, which is used to store specific file system information, usually corresponding to the file system superblock or file system control block stored in the pending sector of a specific disk. For non disk based file systems, they create superblocks in the field and put them in memory
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type;
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_iflags; /* internal SB_I_* flags */
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
int s_count;
atomic_t s_active;
#ifdef CONFIG_SECURITY
void *s_security;
#endif
const struct xattr_handler **s_xattr;
#ifdef CONFIG_FS_ENCRYPTION
const struct fscrypt_operations *s_cop;
struct key *s_master_keys; /* master crypto keys in use */
#endif
#ifdef CONFIG_FS_VERITY
const struct fsverity_operations *s_vop;
#endif
#ifdef CONFIG_UNICODE
struct unicode_map *s_encoding;
__u16 s_encoding_flags;
#endif
struct hlist_bl_head s_roots; /* alternate root dentries for NFS */
struct list_head s_mounts; /* list of mounts; _not_ for fs use */
struct block_device *s_bdev;
struct backing_dev_info *s_bdi;
struct mtd_info *s_mtd;
struct hlist_node s_instances;
unsigned int s_quota_types; /* Bitmask of supported quota types */
struct quota_info s_dquot; /* Diskquota specific options */
struct sb_writers s_writers;
/*
* Keep s_fs_info, s_time_gran, s_fsnotify_mask, and
* s_fsnotify_marks together for cache efficiency. They are frequently
* accessed and rarely modified.
*/
void *s_fs_info; /* Filesystem private info */
/* Granularity of c/m/atime in ns (cannot be worse than a second) */
u32 s_time_gran;
/* Time limits for c/m/atime in seconds */
time64_t s_time_min;
time64_t s_time_max;
#ifdef CONFIG_FSNOTIFY
__u32 s_fsnotify_mask;
struct fsnotify_mark_connector __rcu *s_fsnotify_marks;
#endif
char s_id[32]; /* Informational name */
uuid_t s_uuid; /* UUID */
unsigned int s_max_links;
fmode_t s_mode;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
const char *s_subtype;
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/*
* Saved pool identifier for cleancache (-1 means none)
*/
int cleancache_poolid;
struct shrinker s_shrink; /* per-sb shrinker handle */
/* Number of inodes with nlink == 0 but still referenced */
atomic_long_t s_remove_count;
/* Pending fsnotify inode refs */
atomic_long_t s_fsnotify_inode_refs;
/* Being remounted read-only */
int s_readonly_remount;
/* per-sb errseq_t for reporting writeback errors via syncfs */
errseq_t s_wb_err;
/* AIO completions deferred from interrupt context */
struct workqueue_struct *s_dio_done_wq;
struct hlist_head s_pins;
/*
* Owning user namespace and default context in which to
* interpret filesystem uids, gids, quotas, device nodes,
* xattrs and security labels.
*/
struct user_namespace *s_user_ns;
/*
* The list_lru structure is essentially just a pointer to a table
* of per-node lru lists, each of which has its own spinlock.
* There is no need to put them into separate cachelines.
*/
struct list_lru s_dentry_lru;
/*
* The list_lru structure is essentially just a pointer to a table
* of per-node lru lists, each of which has its own spinlock.
* There is no need to put them into separate cachelines.
*/
struct list_lru s_dentry_lru;
struct list_lru s_inode_lru;
struct rcu_head rcu;
struct work_struct destroy_work;
struct mutex s_sync_lock; /* sync serialisation lock */
/*
* Indicates how deep in a filesystem stack this SB is
*/
int s_stack_depth;
/* s_inode_list_lock protects s_inodes */
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes; /* all inodes */
spinlock_t s_inode_wblist_lock;
struct list_head s_inodes_wb; /* writeback inodes */
} __randomize_layout;

Superblock operation:

If a system wants to write its own superblock, it needs to call:
sb->s_op->write_super(sb);
See here, I will think, under what circumstances will I write Super blocks
Operation method s_op is very important for each file system. It points to the operation function table of the super block and contains the implementation of a series of operation methods, including:
- Allocate inode
- Destroy inode
- Read and write inode
- File synchronization
- wait
Let's take a look at the usage of super blocks
struct inode *alloc_inode(struct_block* sn);
Creates and initializes a new inode object under a given superblock
Releases the given index point
void destroy_inode(struct inode *inode);
This function is called when the index node is dirty
void dirty_inode(struct inode* inode);
The given index point is written to disk
void write_inode(struct inode* inode, int wait);
This function is triggered when the last index point is released
drop_inode(struct inode* inode);
Delete index point from disk
delete_inode(struct inode* inode)
The given superblock updates the superblock on the disk, and the caller must hold s consistently_ Lock lock
void write_super(struct super_blokck* sb);
Synchronize the data source of the file system with the file system on the disk. The wait parameter specifies whether to synchronize
void sync_fs(struct super_block* sb, int wait);
First prohibit changes to the file system, and then update the superblock on the disk with the given superblock
void write_super_lockfs(struct super_block *sb);
Unlock the file system. It's write_ super_ Inverse operation of lockfs
void unlokcfs(struct super_block *sb);
Get the file status by calling this function. Specifies that the relevant statistics in the file system are placed in statfs.
int statfs(struct super_block* sb, int *flags, char* data);
This function is called when the file system is reinstalled
int remount_fs(struct super_block* sb, int *flags, char* data);
Call this function to release the index point
void clear_inode(struct inode* inode);
Call this function for terminal installation operation. This function is generally used by network programs
umount_begin(struct super_block *sb);
All of these functions are invoked by VFS in the context of the process.
Thinking, I don't seem to come into contact with the super block in my daily work. How does it accompany our daily work? What does the linux super block look like?
I think it's actually a piece of equipment
First of all, what is a super block?
A superblock is part of metadata that contains information about the file system on the block device. Superblock provides the following information about files, binaries, DLLs, metadata, etc.
1) Super block, the first block in the file system is called super block. This block stores the structure information of the file system itself. For example, the superblock records the size of each area, and the superblock also stores the information of unused disk blocks.
There are many file systems in Linux, such as ext2, ext3, ext4, sysfs, rootf, proc, etc. a super block actually corresponds to an independent file system
What does superblock do?
Each file system has a super block structure, and each super block should be linked to a super block linked list. When each file in the file system is opened, an inode structure needs to be allocated in memory, and these inode structures must be linked to the superblock.
After reading, I think the linux super block is like the c disk of windows, but linux is more obscure and will not expose these underlying concepts to users
4. Inode object
The inode object contains all the information when the kernel operates files or directories. If there is no such information, no matter how the information is stored on the disk, all the information must be read from the disk ---- that is, the information is recorded on the inode, which can be read faster and directly in memory instead of on the disk


i_bdev points to the block device structure
c_dev refers to the string device structure
Index point operand

The operation functions are as follows:
VFS calls this function through system calls create and open to create an index node for the dentry object. Use the initial mode of mode when creating
int create(struct inode* dir, struct dentry* dentry, int mode)
Find the index node in a specific directory. The index points correspond to the file name in dentry
struct dentry * lookup(struct inode* dir, struct dentry * dentry)
There are many common
link, unlink, symlink, mkdir, rmdir, readlink

mknod is an interesting command
The mknod command establishes the correspondence between a directory entry and a special file Index node.

mknod can also create device files


I see it's a little messy here. What exactly does the inode object do? Is it related to directories or files?
According to Baidu Encyclopedia, extract some key introductions
linux file system Save the file inode number and file name in the directory at the same time.
Therefore, the directory is just a table combining the file name and its inode number. Each pair of file name and inode number in the directory is called a connection. For a file, there is a unique inode number corresponding to it, but for an inode number, there can be multiple file names corresponding to it. Therefore, the same file on disk can be accessed through different paths.
Let's look at the first data directory first
zhanglei@ubuntu:~$ stat data File: data Size: 4096 Blocks: 8 IO Block: 4096 directory Device: 805h/2053d Inode: 11536259 Links: 32 Access: (0775/drwxrwxr-x) Uid: ( 1000/zhanglei) Gid: ( 1000/zhanglei) Access: 2021-12-30 16:40:23.940211255 +0800 Modify: 2021-12-29 10:27:41.774194959 +0800 Change: 2021-12-29 10:27:41.774194959 +0800 Birth: -
Take another look at the index in the data directory HTML and test log
zhanglei@ubuntu:~/data$ stat index.html File: index.html Size: 14848 Blocks: 32 IO Block: 4096 regular file Device: 805h/2053d Inode: 11535969 Links: 1 Access: (0664/-rw-rw-r--) Uid: ( 1000/zhanglei) Gid: ( 1000/zhanglei) Access: 2021-12-27 16:41:13.534683164 +0800 Modify: 2021-11-04 11:46:49.090311376 +0800 Change: 2021-11-04 11:46:49.090311376 +0800 Birth: - zhanglei@ubuntu:~/data$ stat test.log File: test.log Size: 2124 Blocks: 8 IO Block: 4096 regular file Device: 805h/2053d Inode: 11535967 Links: 1 Access: (0664/-rw-rw-r--) Uid: ( 1000/zhanglei) Gid: ( 1000/zhanglei) Access: 2021-11-02 19:30:36.301627388 +0800 Modify: 2021-11-02 19:30:36.209629723 +0800 Change: 2021-11-02 19:30:36.209629723 +0800 Birth: -
This is a good explanation. Therefore, the directory is just a table combining the file name and its inode number. Each file has its own node id number
5. Directory item object
VFS treats directories and files as files. For example, / bin/vi , is two files, bin file and vi file. However, linux treats directories as a special file to facilitate search
Catalog item object format:

There are three directory states: unused, used, and negative
The negative state is just an identification bit because the inode is deleted. The directory entry may be incorrect, but the inode remains and is still a valid object
Directory items are cached. The directory item cache consists of three parts:
1. Table of contents used. The linked list passes through the I of the index node_ Dentry entries connect related inodes. Because a given inode may consist of multiple directory entry objects, a linked list is used
2. The recently used two-way linked list, which contains unused and negative directory objects. Because this linked list always inserts directory entries from the head. Therefore, the head of the linked list is always newer than the tail. When the internal node must be deleted, it should be deleted from the tail
3. The hash table and corresponding hash functions are used to quickly parse a given path into related directory item objects.
Hash array dentry_hashtable means that each element is a pointer to the linked list of directory item objects with the same key value.
The directory entry operation is simple:

To determine whether directory objects are valid, most file systems set them to null because they think dcache is always valid
int d_revalidate(struct dentry *dentry, struct nameidate*)
This function generates a hash table of the directory and adds the directory item to the hash table
int d_hash(struct dentry* dentry, struct qstr* name);
Compare name1 with Name2. Note that DCache needs to be added_ lock
int d_compare(struct dentry* dentry, struct qstr *name1, struct qstr *name2);
When the directory item counter is 0, the system will call this function
int d_delete(struct dentry* dentry);
This function is called when the directory object is about to be released
void d_release(struct dentry* dentry);
vfs uses this function when a directory entry pair object loses its associated node.
void d_input(struct dentry* dentry, struct inode* inode);
6. Document object
A file object represents a file that has been opened by a process. The process directly operates on the i file object, creating open and closing

I don't write many operation functions. I'm really familiar with them


The kernel uses some standard data structures to manage other related data structures of the file system

Each file system has only one file_system_type structure
When a file system is mounted, a vfsmount structure is created

As I have said many times before, each process maintains an fd_ The table will maintain the relationship between fd and the actual physical media

fs_ The second structure related to the struct process is fs_struct, which contains information about file systems and processes

This structure contains the working directory and root directory of the current process.
The third directory structure is the namespace structure, which is composed of the process descriptor mmt_namespace domain pointing

List is a two-way linked list of installed systems
Each process maintains a count as a reference count to prevent other processes from being destructed when using this data structure
By default, all processes use the same namespace. Clone is used only when clone is used_ The new flag will give the process a unique namespace copy structure. Most processes have the same default namespace
I'm a little curious. Is this the namespace in K8s? Ha ha ha