This chapter mainly takes SMS Spam Collection data set as an example to introduce the identification technology of harassing SMS. This section explains in detail the feature extraction method of harassing SMS with Word2Vec.
Word2Vec model
1, Principle
Word2Vec is an efficient tool that Google opened in 2013 to represent words as real value vectors. The models used include continuous bag of words (CBOW) model and skip gram model. The schematic diagram is shown in the figure below.
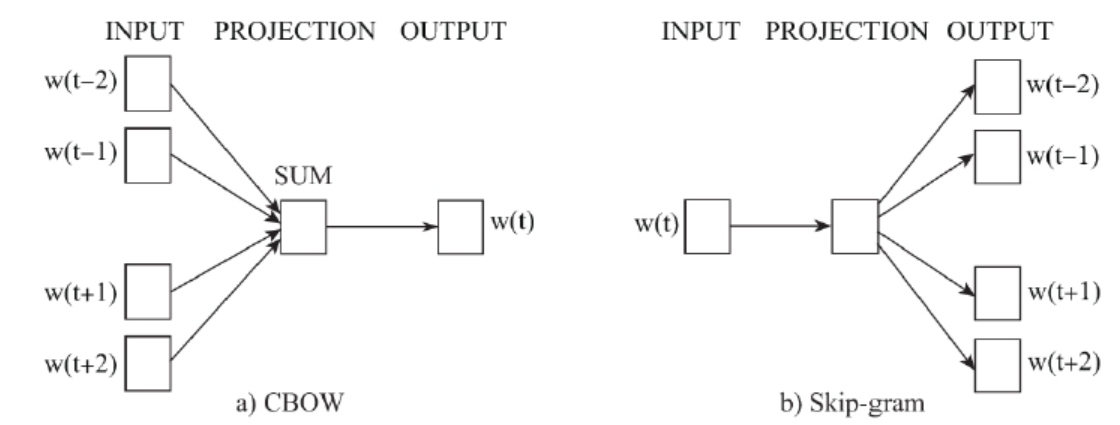
Through training, Word2Vec can simplify the processing of text content into vector operation in K-dimensional vector space, and the similarity in vector space can be used to represent the semantic similarity of text. Therefore, the word vector output by Word2Vec can be used to do a lot of NLP related work, such as clustering, finding synonyms, part of speech analysis and so on
2, Apply
1. Data preprocessing
Compared with the word bag and word set model, word2vec model adds the following processing logic, because there may be some special symbols in the SMS content, which are also helpful to judge the harassing email. The special symbols to be processed are as follows:
punctuation = """.,?!:;(){}[]"""
The common processing method is to add spaces before and after special symbols, and then use the split function to keep these special symbols completely:
def cleanText(corpus):
punctuation = """.,?!:;(){}[]"""
corpus = [z.lower().replace('\n', '') for z in corpus]
corpus = [z.replace('<br />', ' ') for z in corpus]
# treat punctuation as individual words
for c in punctuation:
corpus = [z.replace(c, ' %s ' % c) for z in corpus]
corpus = [z.split() for z in corpus]
return corpusUse the cleanText function to process the training data and test data respectively and combine them into a complete data set x:
x_train=cleanText(x_train)
x_test=cleanText(x_test)
x=x_train+x_test2. Build model
Initialize the Word2Vec object. size represents the number of hidden layer nodes of the neural network training Word2Vec, and also represents the dimension of ord2Vec vector; Window represents the window length of Word2Vec training; min_count indicates that the number of occurrences is less than min_ The word count will not be calculated; iter indicates the times of training Word2Vec. The official document of gensim strongly recommends increasing iter times to improve the quality of generated Word2Vec. The default value is 5:
if os.path.exists(word2ver_bin):
print ("Find cache file %s" % word2ver_bin)
model=gensim.models.Word2Vec.load(word2ver_bin)
else:
model=gensim.models.Word2Vec(size=max_features, window=10, min_count=1, iter=60, workers=1)
model.build_vocab(x)
model.train(x, total_examples=model.corpus_count, epochs=model.iter)
model.save(word2ver_bin)3.Word2Vec feature Vectorization
After the training, the Word2Vec corresponding to the word will be saved in the model variable and can be accessed directly in a dictionary like way. For example, the method to obtain the Word2Vec corresponding to the word love is as follows:
model['love']
Word2Vec has a feature. The meaning of a phrase composed of a sentence or several words can be obtained by adding the Word2Vec values of all words to get the average value, for example:
model['good boy']= (model['good]+ model['boy])/2
Using this feature, you can add the Word2Vec of the words and characters that make up the short message and take the average value:
def buildWordVector(imdb_w2v,text, size):
vec = np.zeros(size).reshape((1, size))
count = 0.
for word in text:
try:
vec += imdb_w2v[word].reshape((1, size))
count += 1.
except KeyError:
continue
if count != 0:
vec /= count
return vecIn addition, since the number of occurrences is less than min_ The word count will not be calculated, and there may be unprocessed special characters in the test sample, so it is necessary to catch KeyError to avoid abnormal exit of the program. Process the training set and test set in turn to obtain the corresponding Word2Vec value, and standardize it with the scale function:
x_train= np.concatenate([buildWordVector(model,z, max_features) for z in x_train])
x_train = scale(x_train)
x_test= np.concatenate([buildWordVector(model,z, max_features) for z in x_test])
x_test = scale(x_test)4.scale standardization
The use of the scale function is to prevent the data of individual dimensions in multidimensional data from being too large or too small, which will affect the classification effect of the algorithm. The scale function will convert the data of each dimension to make the distribution more "even"
from sklearn import preprocessing import numpy as np X = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) X_scaled = preprocessing.scale(X) print(X_scaled)
The output results are as follows:
[[ 0. -1.22474487 1.33630621] [ 1.22474487 0. -0.26726124] [-1.22474487 1.22474487 -1.06904497]]
5. Complete source code
Generally speaking, the processing flow is as follows:
def get_features_by_word2vec():
global max_features
global word2ver_bin
x_train, x_test, y_train, y_test=load_all_files()
print(len(x_train), len(y_train))
x_train=cleanText(x_train)
x_test=cleanText(x_test)
x=x_train+x_test
cores=multiprocessing.cpu_count()
if os.path.exists(word2ver_bin):
print ("Find cache file %s" % word2ver_bin)
model=gensim.models.Word2Vec.load(word2ver_bin)
else:
model=gensim.models.Word2Vec(size=max_features, window=10, min_count=1, iter=60, workers=1)
model.build_vocab(x)
model.train(x, total_examples=model.corpus_count, epochs=model.iter)
model.save(word2ver_bin)
print('before', len(y_train))
x_train= np.concatenate([buildWordVector(model,z, max_features) for z in x_train])
x_train = scale(x_train)
print('after', len(x_train))
print(x_train.shape)
x_test= np.concatenate([buildWordVector(model,z, max_features) for z in x_test])
x_test = scale(x_test)
return x_train, x_test, y_train, y_test
6. Examples
Here, take train[0] as an example to describe the vectorization process. First, initialize the import from the file
x_train, x_test, y_train, y_test=load_all_files()
After calling the above code, X_ The result of train [0] is as follows
If you don't, your prize will go to another customer. T&C at www.t-c.biz 18+ 150p/min Polo Ltd Suite 373 London W1J 6HL Please call back if busy
After executing the cleanText function, after word segmentation, X_ The result of train [0] is as follows
['if', 'you', "don't", ',', 'your', 'prize', 'will', 'go', 'to', 'another', 'customer', '.', 't&c', 'at', 'www', '.', 't-c', '.', 'biz', '18+', '150p/min', 'polo', 'ltd', 'suite', '373', 'london', 'w1j', '6hl', 'please', 'call', 'back', 'if', 'busy']
Next, we use the word2vec model to deal with it
if os.path.exists(word2ver_bin):
print ("Find cache file %s" % word2ver_bin)
model=gensim.models.Word2Vec.load(word2ver_bin)
else:
model=gensim.models.Word2Vec(size=max_features, window=10, min_count=1, iter=60, workers=1)
model.build_vocab(x)
model.train(x, total_examples=model.corpus_count, epochs=model.iter)
model.save(word2ver_bin)
x_train= np.concatenate([buildWordVector(model,z, max_features) for z in x_train])Word2Vec has a feature. The meaning of a phrase composed of one sentence or several words can be obtained by adding the Word2Vec values of all words to get the average value. The processed train[0] is as follows
[ 0.5688461 -0.7963458 -0.53969711 0.42368432 1.7073138 1.17516173 0.32935769 0.1749727 -1.10261336 -1.14618023 -0.64693019 0.03879264 -0.28986312 -0.15053948 0.86447008 1.03759495 -0.22362847 0.54810378 -0.09579477 0.06696273 0.53213082 1.13446066 0.70176198 -0.09194162 -1.00245396 -1.01783227 -0.72731505 0.43077651 -0.00673702 0.54794111 0.28392318 1.21258038 0.6954477 1.35741696 0.52566294 -0.11437557 -0.0698448 -0.06264644 0.00359846 0.19755338 0.02252081 -0.45468214 0.03074975 -0.97560132 -1.3320358 -0.191184 -0.99694834 -0.05791205 0.38126789 1.41985205 0.06165056 0.21995296 -0.25111755 -0.61057136 0.30779555 1.45024929 -1.25652236 0.77137314 0.14340256 -0.48314989 0.6579341 -1.64457267 -0.33124644 0.4243934 -1.32630979 0.37559585 -0.01618847 -0.72842787 0.75744382 0.22936961 0.38842295 0.70630939 -0.5755018 2.28154287 0.1041452 0.35924263 1.8132245 -0.10724146 -1.49230761 -0.32379927 -0.89156985 0.37247643 0.34482669 -0.10076832 -0.53934116 -0.38991501 -0.14401814 1.64303595 -0.50050573 0.32035356 -0.51832154 0.45338105 -1.35904802 -0.74532751 -0.31660083 0.15160747 0.76809469 -0.34191613 0.07772422 0.16559841 0.08473047 -0.10939166 0.1857267 0.02878834 0.64387584 0.45749407 0.69939248 -0.85222505 -1.57294277 -1.62788899 0.35674762 -0.24114483 0.29261773 0.18306259 -1.18492453 -0.52101244 1.15009746 0.97466267 -0.33838688 -1.17274655 0.57668485 1.56703609 1.27791816 -1.14988041 0.28182096 -0.09135877 -0.03609932 0.66226854 -0.35863005 -0.36398623 0.26722192 0.98188737 -0.33385907 0.445007 0.75214935 -0.81884158 1.0510767 0.63771857 0.19482218 -1.80268676 -0.34549945 -0.35621238 0.46528964 -0.55987857 -0.87382452 0.75147679 -0.66485836 -0.15657116 0.18748415 1.10138361 -0.0078085 0.50333768 1.3417442 1.10197353 -0.05941141 0.07282477 -0.19017513 -0.83439085 -0.00832164 0.06593468 -0.53035842 0.95551142 0.35307575 -0.31915962 0.20121204 -0.81100877 -0.91266333 0.03278571 0.26023407 -0.54093813 0.02997342 1.41653465 -0.12427418 -0.82120634 -1.17340946 -1.75454109 -0.76027333 1.2884738 0.17876992 0.26112962 -0.88782072 0.03205944 -0.16476012 -0.14802052 -1.12993536 0.4738586 0.72952233 1.57389264 -0.77677785 -0.6256085 -0.22538952 0.34228583 -0.56924201 0.7434089 1.40698768 0.52310801 -0.87181962 0.32473917 -1.27615191 1.0771901 1.12765643 1.1128303 0.28027994 0.23365211 -1.32999254 1.16263406 -0.24584286 1.32610628 -1.07430174 0.04978786 0.84560452 0.51568605 0.29324713 1.01046356 0.89309483 -0.68883869 -0.10943733 -1.14162474 0.43906249 -1.64726855 0.62657474 0.89747922 0.25619183 0.88133258 0.53152881 0.800173 1.07257533 -0.91345605 1.511324 -0.37129249 -1.21065258 1.41421037 0.63753296 0.77966061 0.34219329 -1.62505142 -0.50154156 -0.84119517 -0.10794676 0.14238391 -0.18933125 0.96618836 -0.09447222 -0.01457627 0.25379729 -0.00239968 -0.01879948 0.24551755 -0.19717246 1.49390844 0.41681463 -1.16918163 -0.7748389 0.6664235 -0.03348684 -0.13785069 -1.38920251 -0.65347069 -0.30330183 0.84497368 1.01966753 0.62513464 -0.61398801 0.17254219 0.47432455 -0.4636558 -0.2835449 -0.38155617 -0.47108328 -1.27081993 -0.09585531 0.49909651 -0.99359911 -0.07502736 -1.39910104 -0.34759668 0.21337289 -1.10769739 0.15850016 0.64950728 0.96845903 -0.71599037 -0.35235105 -0.64243931 -0.31335287 -1.04057976 -0.75755116 0.2656545 -0.91747103 0.51288032 1.12705359 -0.3520552 0.82732871 2.18699482 0.17190736 0.01063382 0.60349575 0.18857134 0.63457147 -1.40435699 -0.24523577 1.07861446 -1.93594107 -0.35640277 0.56313198 0.92719632 -1.19504538 -0.40542724 -0.16996568 -0.03463793 -0.97696206 -0.12556016 0.21483948 0.15585242 0.76265303 -0.65085202 0.65287212 -0.85362963 0.33149502 0.5701018 0.40867361 0.21806052 -1.14224126 1.42919841 -0.22902177 0.5451145 -0.1141489 0.25853344 1.02713966 -0.16200372 -0.23339327 0.87608441 0.75910643 0.18785408 1.23609536 -0.72335459 0.53511046 0.08358996 -0.5598393 0.5004547 -0.11572333 -0.47238923 1.20602503 -0.27158068 -0.65528766 0.25551535 0.32559297 -1.09997926 0.20791183 0.12843725 0.09087898 -0.22888646 -0.71270039 0.78723415 0.4676776 -0.3136612 0.4368007 0.56427676 -0.95792959 -0.12123958 0.25772387 0.27141381 1.62133518 1.0806067 -0.21620892 0.72400364 0.23908486 1.32545448 1.37374568 0.80119068 -1.11050208 0.61139748 0.19350813 -0.42820846 -0.09775806 0.37327079 -1.30432311 0.20804753 0.81459754 -0.36544708 0.00990999 -1.75476784 -1.18515867 -0.15301021 -0.02726374 0.63801717 0.70284723 0.69907364 -0.54179232 -1.13846505 -0.00501522 -0.95063539 -0.3019417 -0.72958836 -0.65496463 -0.22132243 1.35748601 1.41187301 0.82758802 1.23182959]
Note: this chapter is not finished, because there are many notes on harassing SMS recognition in Section 8, which is divided into a series. The next note is entitled "Web security in-depth learning practice". Note: Chapter 8 harassing SMS recognition (4)
For details of follow-up contents, please refer to the series of notes of in-depth learning practice of web security.