Sorting: assume that the sequence containing n records is{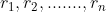 }, the corresponding keywords are{
}, the corresponding keywords are{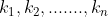 }, need to determine 1, 2, An arrangement of n
}, need to determine 1, 2, An arrangement of n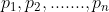 , so that the corresponding keywords meet
, so that the corresponding keywords meet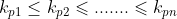 (non decreasing or non increasing) relationship, even if the sequence becomes a sequence ordered by keywords{
(non decreasing or non increasing) relationship, even if the sequence becomes a sequence ordered by keywords{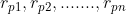 }, such an operation is called sorting.
}, such an operation is called sorting.
Internal sorting: internal sorting is that all records to be sorted are placed in memory during the whole sorting process. External sorting is because there are too many records to be sorted and cannot be placed in memory at the same time. The whole sorting process needs to exchange data between internal and external memory for many times.
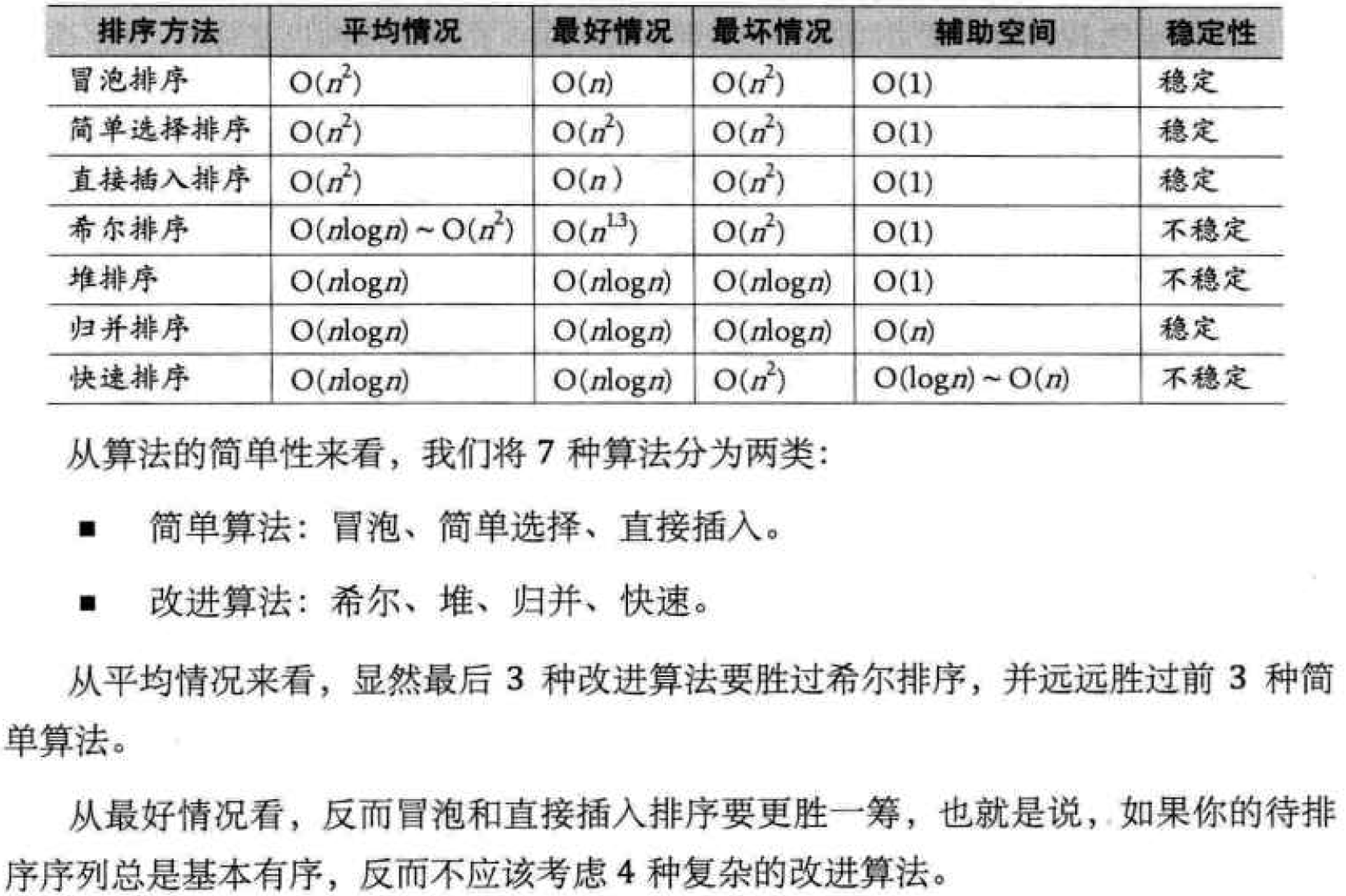
This chapter will explain seven sorting algorithms. According to the complexity of the algorithm, it is divided into two categories: bubble sorting, simple selection sorting and direct insertion sorting. The terms of simple algorithm and Hill sorting, heap sorting, merge sorting and quick sorting are improved algorithms
Structures and functions used in sorting
#define MAXSIZE 10000 / * used to sort the maximum number of arrays, which can be modified as required*/
typedef struct
{
int r[MAXSIZE+1]; /* Used to store the array to be sorted, and r[0] is used as a sentinel or temporary variable */
int length; /* Used to record the length of the sequence table */
}SqList;
/* Swap the values of array r in L with subscripts i and j */
void swap(SqList *L,int i,int j)
{
int temp=L->r[i];
L->r[i]=L->r[j];
L->r[j]=temp;
}Bubble Sort: an exchange sort. Its basic idea is to compare the keywords of adjacent records in pairs. If it is in reverse order, it will be exchanged until there is no reverse order record position.
/* Exchange sort the order table L (bubble sort primary version) */
void BubbleSort0(SqList *L)
{
int i,j;
for(i=1;i<L->length;i++)
{
for(j=i+1;j<=L->length;j++)
{
if(L->r[i]>L->r[j])
{
swap(L,i,j);/* Exchange the values of L - > R [i] and L - > R [J] */
}
}
}
}
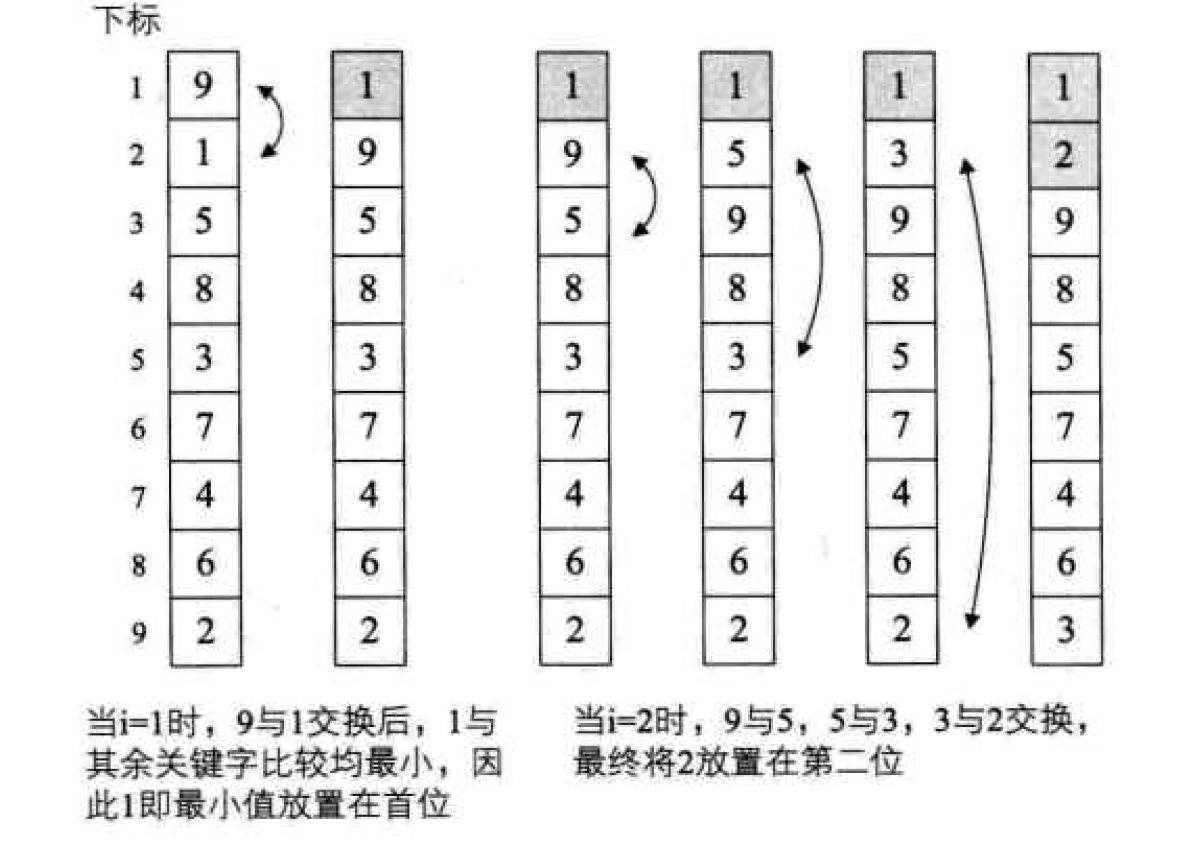
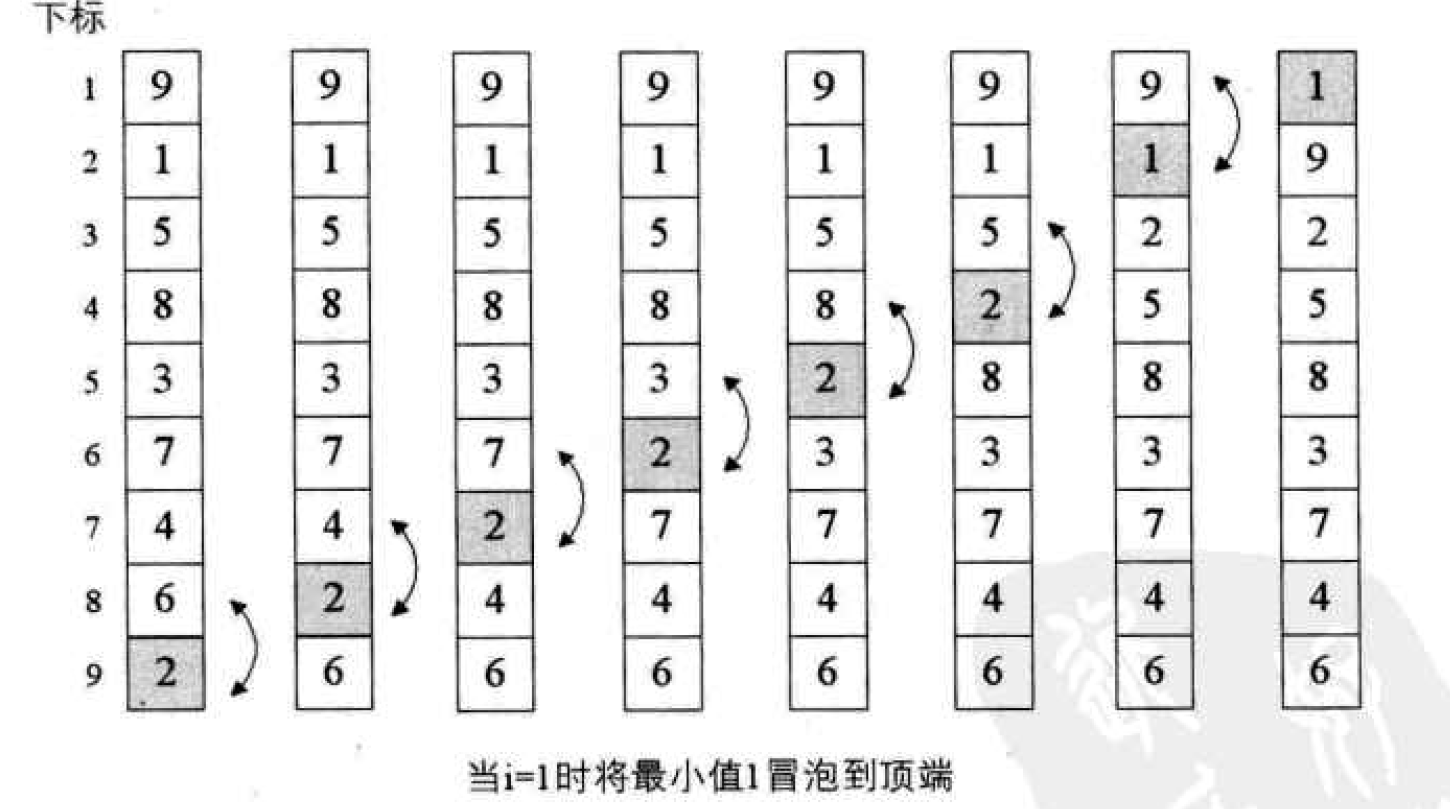
The upper side is the primary bubbling algorithm, and the lower side is authentic
/* Bubble sort the sequence table L */
void BubbleSort(SqList *L)
{
int i,j;
for(i=1;i<L->length;i++)
{
for(j=L->length-1;j>=i;j--) /* Note that j is cycling from back to front */
{
if(L->r[j]>L->r[j+1]) /* If the former is greater than the latter (note the difference between this and the previous algorithm)*/
{
swap(L,j,j+1);/* Exchange the values of L - > R [J] and L - > R [J + 1] */
}
}
}
}
Bubble sorting Optimization: add a flag variable to improve this algorithm:
/* Improved bubbling algorithm for sequence table L */
void BubbleSort2(SqList *L)
{
int i,j;
Status flag=TRUE; /* flag Used as a marker */
for(i=1;i<L->length && flag;i++) /* If the flag is true, it indicates that there has been data exchange, otherwise stop the cycle */
{
flag=FALSE; /* Initially False */
for(j=L->length-1;j>=i;j--)
{
if(L->r[j]>L->r[j+1])
{
swap(L,j,j+1); /* Exchange the values of L - > R [J] and L - > R [J + 1] */
flag=TRUE; /* If there is data exchange, the flag is true */
}
}
}
}
Simple selection sort
Simple Selection Sort is to select the record with the smallest keyword from n-i+1 records through the comparison between n-i secondary keywords, and exchange it with the I (1 ≤ I ≤ n) record.
/* Make a simple selection and sorting for the sequence table L */
void SelectSort(SqList *L)
{
int i,j,min;
for(i=1;i<L->length;i++)
{
min = i; /* Defines the current subscript as the minimum subscript */
for (j = i+1;j<=L->length;j++)/* Data after cycle */
{
if (L->r[min]>L->r[j]) /* If there is a keyword less than the current minimum value */
min = j; /* Assign the subscript of this keyword to min */
}
if(i!=min) /* If min is not equal to i, find the minimum value and exchange */
swap(L,i,min); /* Exchange the values of L - > R [i] and L - > R [min] */
}
}Direct insert sort
The basic operation of Straight Insertion Sort is to insert a record into the ordered table, so as to get a new ordered table with the number of records increased by 1.
/* Direct insertion sort for sequence table L */
void InsertSort(SqList *L)
{
int i,j;
for(i=2;i<=L->length;i++)
{
if (L->r[i]<L->r[i-1]) /* L - > R [i] needs to be inserted into the ordered sub table */
{
L->r[0]=L->r[i]; /* Set up sentry */
for(j=i-1;L->r[j]>L->r[0];j--)
L->r[j+1]=L->r[j]; /* Record backward */
L->r[j+1]=L->r[0]; /* Insert in the correct position */
}
}
}Shell Sort
/* Sort order table L */
void ShellSort(SqList *L)
{
int i,j,k=0;
int increment=L->length;
do
{
increment=increment/3+1;/* Incremental sequence */
for(i=increment+1;i<=L->length;i++)
{
if (L->r[i]<L->r[i-increment])/* L - > R [i] needs to be inserted into the ordered quantum addition table */
{
L->r[0]=L->r[i]; /* Temporarily existing L - > R [0] */
for(j=i-increment;j>0 && L->r[0]<L->r[j];j-=increment)
L->r[j+increment]=L->r[j]; /* Move the record back to find the insertion position */
L->r[j+increment]=L->r[0]; /* insert */
}
}
printf(" The first%d Sorting result: ",++k);
print(*L);
}
while(increment>1);
}
Heap sort
Heap is a complete binary tree with the following properties: the value of each node is greater than or equal to the value of its left and right child nodes, which is called large top heap; Or the value of each node is less than or equal to the value of its left and right child nodes, which is called small top heap.

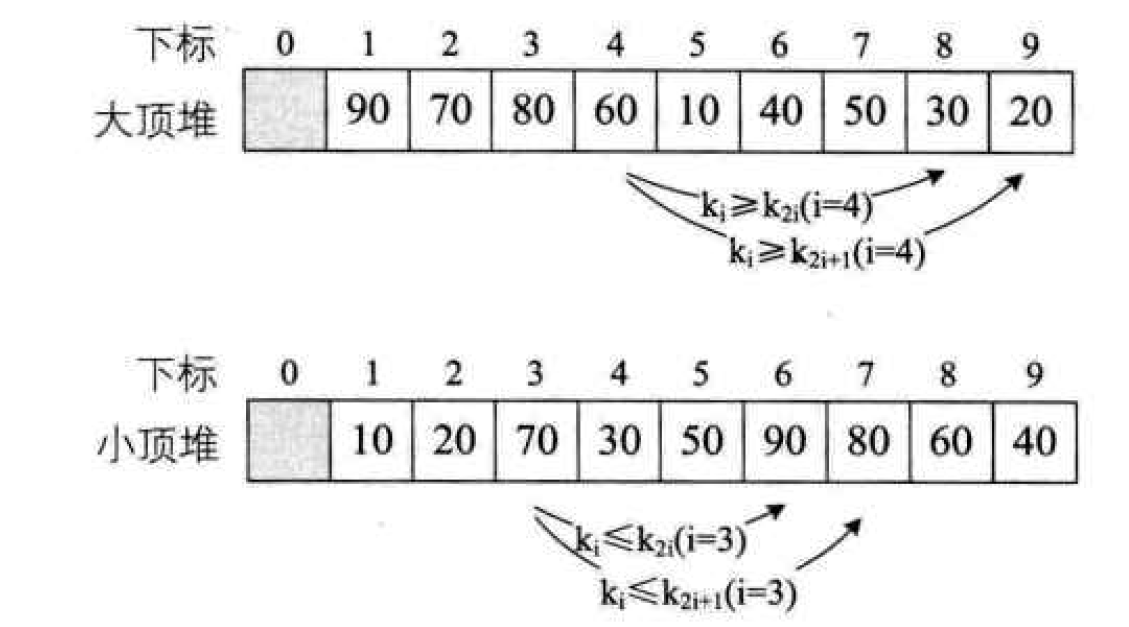
Heap Sort: construct the sequence to be sorted into a large top heap. At this time, the maximum value of the whole sequence is the root node at the top of the heap. Remove it (in fact, it is exchanged with the end element of the heap array, at which time the end element is the maximum value), and then reconstruct the remaining n-1 sequences into a heap, so as to get the second smallest value of n elements. Such repeated execution can get an ordered sequence.
/* Heap sort order table L */
void HeapSort(SqList *L)
{
int i;
for(i=L->length/2;i>0;i--) /* Construct r in L into a large top pile */
HeapAdjust(L,i,L->length);
for(i=L->length;i>1;i--)
{
swap(L,1,i); /* Swap the top of heap record with the last record of the current unordered subsequence */
HeapAdjust(L,1,i-1); /* Readjust L - > R [1.. I-1] to large top stack */
}
}
/* It is known that the keywords recorded in L - > R [s.. M] meet the definition of heap except L - > R [S], */
/* This function adjusts the keyword of L - > R [S] to make L - > R [s.. M] a large top heap */
void HeapAdjust(SqList *L,int s,int m)
{
int temp,j;
temp=L->r[s];
for(j=2*s;j<=m;j*=2) /* Filter down the child nodes with larger keywords */
{
if(j<m && L->r[j]<L->r[j+1])
++j; /* j Subscript for the larger record in the keyword */
if(temp>=L->r[j])
break; /* rc Should be inserted in position s */
L->r[s]=L->r[j];
s=j;
}
L->r[s]=temp; /* insert */
}Merge sort
Merging Sort is a sort method realized by using the idea of merging. Its principle is that if the initial sequence contains n records, it can be regarded as n ordered subsequences. The length of each subsequence is 1, and then merge them in pairs to obtain [n/2]([x] represents the smallest integer not less than x) ordered subsequences with length of 2 or 1; Merge two more, Repeat this until an ordered sequence with length n is obtained. This sorting method is called 2-way merging sorting.
/* Recursive method */
/* Merge SR[s..t] into TR1[s..t] */
void MSort(int SR[],int TR1[],int s, int t)
{
int m;
int TR2[MAXSIZE+1];
if(s==t)
TR1[s]=SR[s];
else
{
m=(s+t)/2; /* Divide SR[s..t] into SR[s..m] and SR[m+1..t] */
MSort(SR,TR2,s,m); /* Recursively merge SR[s..m] into ordered TR2[s..m] */
MSort(SR,TR2,m+1,t); /* Recursively merge SR[m+1..t] into ordered TR2[m+1..t] */
Merge(TR2,TR1,s,m,t); /* Merge TR2[s..m] and TR2[m+1..t] into TR1[s..t] */
}
}
/* Merge and sort the sequence table L */
void MergeSort(SqList *L)
{
MSort(L->r,L->r,1,L->length);
}
/* Merge ordered SR[i..m] and SR[m+1..n] into ordered TR[i..n] */
void Merge(int SR[],int TR[],int i,int m,int n)
{
int j,k,l;
for(j=m+1,k=i;i<=m && j<=n;k++) /* Incorporate the records in SR from small to large into TR */
{
if (SR[i]<SR[j])
TR[k]=SR[i++];
else
TR[k]=SR[j++];
}
if(i<=m)
{
for(l=0;l<=m-i;l++)
TR[k+l]=SR[i+l]; /* Copy remaining SR[i..m] to TR */
}
if(j<=n)
{
for(l=0;l<=n-j;l++)
TR[k+l]=SR[j+l]; /* Copy remaining SR[j..n] to TR */
}
}
Quick sort
Basic idea of Quick Sort: divide the records to be arranged into two independent parts through one-time sorting. If the keywords of one part of the records are smaller than those of the other part, the two parts of the records can be sorted separately to achieve the purpose of ordering the whole sequence.
/* Quick sort of sequence table L */
void QuickSort(SqList *L)
{
QSort(L,1,L->length);
}
/* Quickly sort the subsequence L - > R [low.. high] in the order table L */
void QSort(SqList *L,int low,int high)
{
int pivot;
if(low<high)
{
pivot=Partition(L,low,high); /* Divide L - > R [low.. high] into two and calculate the pivot value pivot */
QSort(L,low,pivot-1); /* Recursively sort low sub tables */
QSort(L,pivot+1,high); /* Recursive sorting of high sub tables */
}
}
/* At this time, the records before (after) it are not (smaller) than it. */
int Partition(SqList *L,int low,int high)
{
int pivotkey;
pivotkey=L->r[low]; /* Use the first record of the sub table as the pivot record */
while(low<high) /* Scan alternately from both ends of the table to the middle */
{
while(low<high&&L->r[high]>=pivotkey)
high--;
swap(L,low,high);/* Swap records smaller than pivot records to the low end */
while(low<high&&L->r[low]<=pivotkey)
low++;
swap(L,low,high);/* Swap records larger than pivot records to high end */
}
return low; /* Return to pivot position */
}
(unfinished,)