Sequence is a continuous memory space used to store multiple objects and to store a series of data. It is a data storage method. For example, a sequence of integers [10, 20, 30, 40] can be represented as follows:

The sequence stores the address of the object in memory, not the value. a = [10, 20, 30, 40] is illustrated below:
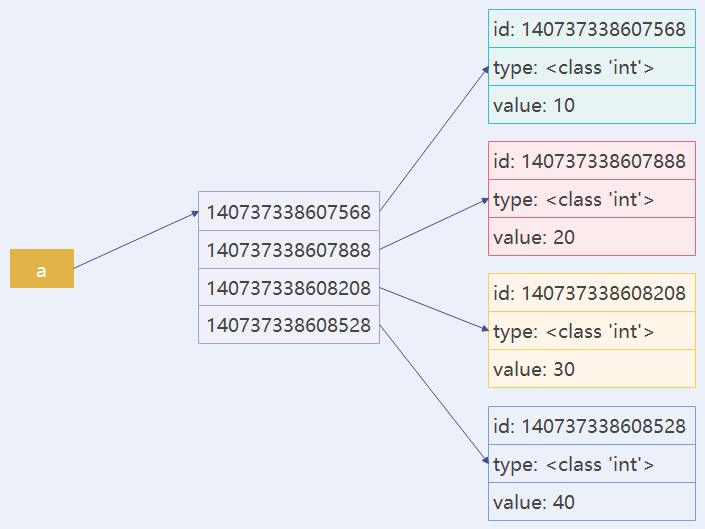
In Python, the common sequence structures are string (str), list, tuple, dictionary (dict), set.
Section 1 Strings
Basic characteristics of strings
The essence of a string is a sequence of characters.
In Python, strings are immutable and we cannot make any changes to the original string. However, you can copy a portion of the string to a newly created string to "look modified".
In Python, single character types are not supported, and a single character is also a string.
Encoding of characters
The default character encoding for Python3 is a 16-bit Unicode encoding.
The built-in function ord() can be used to convert characters to corresponding Unicode codes.
The built-in function chr() can be used to convert decimal numbers to corresponding characters.
String Creation
In Python, use single or double quotation marks to create strings.
s = 'abc' s = "abc"
Multiline strings are created using three consecutive single quotation marks'''or three double quotation marks''.
s = '''abc def gh'''
The original string is created with r''or r', and the characters in quotation marks are not escaped.
str = r'\n\t\r'
| Escape Character | Effect |
|---|---|
| \ (at the end of the line) | Line continuation |
| \\ | Backslash symbol |
| \' | Single quotation mark |
| \" | Double Quotes |
| \b | Backspace |
| \n | Line Break |
| \t | Tab character |
| \r | Enter |
Common operations on strings
Stitching (+)
-
You can use + to stitch together multiple strings. For example:'a'+'b' ==>'a B'
(1) stitching if + are strings on both sides;
(2) If both sides of the + are numbers, the addition operation;
(3) throw an exception if + data types on both sides are inconsistent.
-
Multiple literal strings can be placed directly together for stitching. For example:'a''b' ==>'a B'
Copy (*)
Use * to copy strings. For example:'a'* 3 ='a a A'
Value by index ([])
Strings are character sequences in nature, so you can use [] to extract characters from a string.
Forward search: The first character on the left is numbered 0, the second is 1, and so on until len(str) - 1.
Reverse search: The first character on the far right is numbered -1, the second is -2, and so on until -len(str).
slice
Slices can quickly extract substrings in the standard format: [start index: end index: step step]
When slicing, the start and end indexes are not within the range of [0, len () - 1], and no errors are reported. Start index < 0, treated as 0; Terminate index > (len () - 1) is treated as -1.
Slices with positive operands
| operation | Effect | Example | Result |
|---|---|---|---|
| [ : ] | Intercept entire string | "abcdef" [:] | "abcdef" |
| [ start : ] | Intercept from start to end | "abcdef" [2:] | "cdef" |
| [ : end ] | Intercept from beginning to (end - 1) | "abcdef" [:2] | "ab" |
| [ start : end ] | start to (end-1) | "abcdef" [2:4] | "abcd" |
| [ start : end : step ] | From start to (end-1), the step is step | "abcdef" [1:5:2] | "bd" |
Slices with negative operands
| Example | Explain | Result |
|---|---|---|
| "abcdef"[-3:] | Truncate the last 3 characters | "def" |
| "abcdef"[-5:-3] | Intercept from the fifth to the third last character | "bc" |
| "abcdef"[::-1] | Negative step size, right-to-left reverse intercept | "fedcba" |
replace
In Python, strings are immutable, and we can [] extract a character at a specified location and throw an exception whenever we change it. If you really need to change some of the characters in the string, you can do this by creating a new string.
str.replace(old, new, count) is a replacement that is achieved by creating a new string.
split
str.split(sep, maxsplit) can separate strings into substrings (stored in a list) based on a specified delimiter. If no separator is specified, blank characters (line breaks, spaces, tabs) are used by default.
Merge
sep.join(iterable) acts exactly the opposite of split(), which is used to concatenate a series of substrings.
String concatenation is not recommended because +generates new string objects each time, resulting in poor performance.
join() is recommended for splicing. Before splicing, join() calculates the length of all strings, then copies them one by one, creating only one object.
import time
start = time.time()
a = ''
for i in range(1000000):
a += "python"
end = time.time()
print("+ Time:", end - start)
start1 = time.time()
li = []
for i in range(1000000):
li.append("python")
a = ''.join(li)
end1 = time.time()
print("join Time:", end1 - start1)
--------------------- results of enforcement ---------------------
+ Time: 2.1248202323913574
join Time: 0.10938239097595215
Member Judgment (in)
in / not in keyword, used to determine whether a substring exists in a string. For example:'a'in'abc'
compare
==Compares the values of strings, is compares whether strings are the same object.
A string that matches the residence mechanism, == identifies the same object.
String dwell mechanism:
String dwell mechanism means that a string resides in a pool with only one identical and immutable string.
In Python, string residence is enabled for strings that conform to the identifier rules (only letters, numbers, underscores).
Common methods of strings
| Method | Effect |
|---|---|
| len(str) | String Length |
| str.startswith('str') | Begins with the specified string |
| str.endswith('str') | End with specified string |
| str.find('str') | Finds the first occurrence of a specified string |
| str.rfind('str') | Finds the last occurrence of a specified string |
| str.count('str') | Count occurrences of specified strings |
| str.isalnum() | Determine if all characters are letters or numbers |
| str.isalpha() | Determine if all characters are letters (including Chinese characters) |
| str.isdigit() | Determine if all characters are numbers |
| str.isspace() | Determine if all characters are blank (spaces, line breaks, tabs) |
| str.isupper() | Determine if all characters are uppercase |
| str.islower() | Determine if all characters are lowercase |
| str.strip('str') | Delete first and last specified characters without reference Default deletion of all first and last blank characters |
| str.lstrip('str') | Delete start specified character |
| str.rstrip('str') | Remove trailing specified characters |
| str.capitalize() | Capitalize the first word |
| str.title() | Capitalize the first letter of each word |
| str.upper() | All letters capitalized |
| str.lower() | All letters lowercase |
| str.swapcase() | All Letter Case Conversions |
| str.center(len[, 'str']) | String is centered by length, whitespace is filled with the second parameter, whitespace is filled by default |
| str.ljust(len[, 'str']) | String is left by length, whitespace is filled with the second parameter, whitespace is filled by default |
| str.rjust(len[, 'str']) | String is right by length, blank is filled with the second parameter, blank is filled by default |
Formatting strings
1.%string formatting
In Python, string formatting is consistent with C, using%? Placeholder implementation.
>>> 'Hello, %s, you have $%d.' % ('Join', 1000)
'Hello, Join, you have $1000.'
There are several placeholders, followed by several variables or values, which correspond one to one. If there is only one placeholder, parentheses can be omitted.
Common placeholders are:
| placeholder | Meaning |
|---|---|
| %d | integer |
| %f | Floating point number |
| %s | Character string |
| %x | Hexadecimal Number |
Integers and floating-point numbers can specify whether to complement 0 and integers and decimal places, such as%2d,%02d,%.2f, and so on.
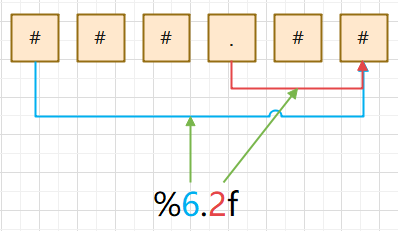
%% in a string can represent a normal value.
2. format string formatting
Beginning with python 3.0, you can use the format() function to format strings and map parameter values by {index}/{parameter name}.
>>> 'name: {0}, age: {1}'.format('lw', 18)
'name: lw, age: 18'
>>> 'name: {name}, age: {age}'.format(age = 18, name = 'lw')
'name: lw, age: 18'
Fill and align
Fill and align are often used together, ^ < > means center, left, right alignment, and back bandwidth, respectively.
: Characters followed by padding can only be one character, and space padding is used by default.
>>> '{:>4}'.format(1)
' 1'
>>> '{:0>4}'.format(1)
'0001'
>>> 'I am{0},My favorite number is{1:-^9}'.format('lw', 888)
'I am lw,My favorite number is---888---'
NumberFormatter
| format | Effect |
|---|---|
| {:.2f} | Keep 2 decimal places after decimal point |
| {:+.2f} | Signed 2-digit decimal after reserving decimal point |
| {:2d} | Minimum width is 2, default space filled |
| {:02d} = {:0>2d} | Minimum width 2, left fill 0 |
| {:,} | Commas every three digits |
| {:.2%} | Percentage format, automatically multiplied by 100, and finally added% |
| {:.2e} | Exponential method |
3. f-string string formatting
Beginning with python 3.6, you can use f-string for string formatting. The format is: {variable:format}, which is what replaces and fills in the string. It can be a variable, an expression, a function, etc. Form is a format descriptor and can be formatted without specifying {format} in the default format.
>>> name = 'Join'
>>> age = 30
>>> f'Hello, {name}, you age is {age}.'
'Hello, Join, you age is 30.'
>>> name = 'Peter'
>>> age = 20
>>> '%s is %d years old.' % (name, age)
'Peter is 20 years old.'
>>> '{0} is {1} years old.'.format(name, age)
'Peter is 20 years old.'
>>> f'{name} is {age} years old.'
'Peter is 20 years old.'
Other operations on strings
1. No Line Break Printing
When print() is typically called, a line break is automatically printed at the end. If we don't want to wrap lines, we can add content at the end by end = "any character".
2. Read strings from console
You can use input() to read keyboard input from the console and return str-type data content.
3. Variable Strings
In Python, strings are immutable. Sometimes, however, you do need to modify a string frequently, so you can use io.StringIO object or array module.
Section 2 List
A list is an ordered, variable sequence, a contiguous memory space containing multiple elements, and is used to store any number or type of data collection.
>>> a = [10, True, 'Hello', 20.5]
List Common Methods
| Method | classification | Effect |
|---|---|---|
| list.append(x) | Add Elements | Increase element x to the end of the list |
| list.extend(aList) | Add Elements | Add all elements of the list aList to the end of the list |
| list.insert(index, x) | Add Elements | Insert element x at index of list |
| list.remove(x) | Delete element | Delete the first element x in the list |
| list.pop([index]) | Delete element | Deletes and returns the element at the index of the specified location in the list, defaulting to the last element |
| list.clear() | Delete element | Empty all elements of the list |
| list.index(x) | Get element position | Returns the first occurrence of element x in the list |
| list.count(x) | count | Number of occurrences of statistic element x in list |
| len(list) | Get Length | Return list length |
| list.reverse() | Flip List | Flip all elements of list in place |
| list.sort() | sort | In-place sorting list All elements, ascending |
| list.copy() | shallow copy | Returns a shallow copy of the list of lists |
List Creation
1. Basic Grammar [] Creation
a = [10, 20, 30, 40] a = [] # Create an empty list
2. Objects created with list() and whose parameters are any Iterable object that can be traversed by a for loop
a = list() # Equivalent to a = []
a = list('abc')
a = list(range(10))
3. Use range() to create an integer list
Grammar:
range([start,] end, [,step])
start defaults to 0, step defaults to 1.
range() returns a range object instead of a list and can be converted to a list object using list().
4. List Derivation
Grammar:
[Expression for item in Iterable object] or [Expression for item in Iterable object if criteria]
a = [ x * 2 for x in range(5) ] # a = [0, 2, 4, 6, 8] a = [ x * 2 for x in range(5) if x % 2 == 0 ] # a = [0, 4, 8] >>> t1 = [(row, col) for row in range(1,5) for col in range(1,5)] >>> t1 [(1, 1), (1, 2), (1, 3), (1, 4), (2, 1), (2, 2), (2, 3), (2, 4), (3, 1), (3, 2), (3, 3), (3, 4), (4, 1), (4, 2), (4, 3), (4, 4)]
Add, delete, access list elements
Add Elements
-
Append (element) adds element at the tail in place, the fastest speed, recommended;
-
+It is not really adding elements at the end, but creating a new list, placing the elements of the original list and the list elements that will be added in turn into the newly created list, which is slower;
-
Extend adds the target list element to the end of the current list and operates in place; Acting on + the same;
-
insert() is used to insert a specified element into a specific location in the list, which will move all elements after the insertion location, affecting processing efficiency. Avoid using as many elements as possible; Similarly, remove(), pop(), and del involve all subsequent element movements when deleting non-tail elements.
-
Multiplication extends to produce a new list that repeats the original list elements multiple times.
Delete element
-
del element deletes the specified element, actually copying the following element to the location of the element to be deleted;
-
Pop (index) deletes and returns the specified location element, if the action element is not at the end, it will involve copying all subsequent elements;
-
Remove (Element) Deletes the specified element that first appears without throwing an exception.
When elements in a list are added or deleted, the list is automatically managed in memory, greatly reducing the programmer's burden. However, this feature involves a large number of movement of list elements and is inefficient. Unless necessary, we usually only add and delete elements at the end of the list to make it more efficient.
Access Elements
-
Index method: list [index], index interval [0, len-1].
-
index(value[, start[, end]]), which gets the position of the first occurrence of an element in the list, where start and end specify the scope of the search.
Common actions for lists
-
Number of occurrences of statistical elements
list.count(x) Gets the number of times the specified element x appears in the list. -
List Length
len(list) returns the length of the list, that is, the number of elements in the list. -
List Membership Judgment
Using count(), if 0 is returned, the element does not exist;
Use in / not in judgment. -
List slice operation
As with string slicing, the difference is that the list is returned. -
List traversal
for obj in list: print(obj)
-
sort list
1) Modify the original list without creating a new one
list.sort() default ascending order;
list.sort(reverse = True) in descending order;
random.shuffle(list) shuffle randomly;
2) Create a new list sorting without changing the original list
sorted(list) default ascending order;
sorted(list, reverse = True) in descending order;
3) reversed() returns the inverse iterator
reversed() does not make any changes to the list, but returns an iterator in reverse order.
The iterator can only be used once, and the inside is empty for the second time because the inside of the iterator is actually a pointer to the last list element, moving forward when using the pointer, and the second time using the pointer is already at the top of the list. -
Maximum and Minimum Elements of List
max(list) min(list) can get the largest and smallest elements of the list. -
Summation of list elements
sum(list) can get the sum of list elements, is not applicable to non-numeric lists, and will cause errors.
Section 3 Tuples
Lists are ordered, variable sequences that can modify elements in a list at will. Tuples are ordered immutable sequences and cannot modify elements in tuples. Therefore, tuples have no way to add elements, delete elements, or modify elements.
Tuple creation
1. Basic grammar () is created, parentheses can be omitted
a = (10, 20, 30) a = 10, 20, 30 a = (10,) a = 10, # If there is only one element in a tuple, a comma must be added after it, or the interpreter will be interpreted as an integer.
2. Objects created with tuple() and whose parameters are any Iterable object that can be traversed by a for loop
a = tuple() # Equivalent to a = ()
a = tuple('abc')
a = tuple(range(5))
a = tuple([1, 2, 3])
3. Generator Derivation
Grammar:
(expression for item in iterative object) or (expression for item in iterative object if criterion)
>>> list = [1, 2, 3, 4] >>> generator = (x * 10 for x in list) >>> generator <generator object <genexpr> at 0x0000026D7E33F660> >>> t1 = tuple(generator) >>> t1 (10, 20, 30, 40)
Formally, generator derivation is similar to list derivation except that generator derivation uses parentheses.
However, list derivation directly generates list objects, while generator derivation does not produce tuples, but a generator object.
We can use tuple() to convert generator objects to tuples, or u next_u () The method is traversed or used directly as an iterator object.
Regardless of the method used, the generator can only be accessed once, similar to an iterator.
Access to tuple elements
-
Tuple elements are not modifiable and error will occur.
-
Tuple elements are accessed as lists, such as slices, but returns are still tuple objects.
-
List of sorting methods in the list.sort() is an in-place modification of a list object, and tuples do not have this method. You can only sort by the built-in function sorted (tuple) and return the result as a new list object.
zip zipper
zip(list1, list2,...) You can group multiple list objects into tuples and return the resulting zip object. Zip is also an iterator object.
list1 = [10, 20, 30] list2 = [40, 50 ,60] list3 = [70, 80, 90] z = zip(list1, list2, list3) z <zip object at 0x00000271B01E7E40> t1 = tuple(z) # list(z) cannot be used >>> t1 ((10, 40, 70), (20, 50, 80), (30, 60, 90))
[Tuple Summary]
- The core features of tuples are: immutable sequences;
- Tuples are accessed and processed faster than lists;
- Like integers and strings, tuples can be used as keys in a dictionary, but lists cannot.
Section 4 Dictionary
A dictionary is an unordered variable sequence that stores "key-value pairs". Each element in a dictionary is a "key-value pair". It contains key objects and value objects, which can be obtained, deleted, and updated by key objects.
The key object is any immutable object, such as integer, floating point number, string, tuple, and so on, and is not repeatable.
Value objects can be arbitrary and repeatable.
Dictionary Creation
1. Basic Grammar {} Creation
>>> a = {'name' : 'lw', 'age' : 28, 'address' : ['ab', 'cd']}
>>> a
{'name': 'lw', 'age': 28, 'address': ['ab', 'cd']}
>>> b = {}
2. Create using dict()
>>> c = dict(name = 'lw', age = 28, address = ['ab', 'cd'])
>>> d = dict([("name", "lw"), ("age", 28), ("address", ["ab", "cd"])])
>>> e = dict() # Equivalent to {}
3. Create using zip()
>>> keys = ["name", "age", "address"]
>>> values = ["lw", 28, ["ab", "cd"]]
>>> d = dict(zip(keys, values))
>>> d
{'name': 'lw', 'age': 28, 'address': ['ab', 'cd']}
4. Use fromkeys to create a dictionary with an empty value
>>> e = dict.fromkeys(["name", "age", "address"])
>>> e
{'name': None, 'age': None, 'address': None}
5. Dictionary Derivation
Grammar:
{key:value for expression in Iterable object} or {key:value for expression in Iterable object if criteria}
# Count the number of occurrences of characters in text
>>> text = 'i love you, i love python, i love study'
>>> word_cnt = {char:text.count(char) for char in text}
>>> word_cnt
{'i': 3, ' ': 8, 'l': 3, 'o': 5, 'v': 3, 'e': 3, 'y': 3, 'u': 2, ',': 2, 'p': 1, 't': 2, 'h': 1, 'n': 1, 's': 1, 'd': 1}
Access to dictionary elements
a = {'name' : 'lw', 'age' : 28, 'job' : 'programmer'} # Initialize a dictionary object
- Use [key] to get a value and throw an exception if the key does not exist.
>>> a['name'] # Key Exists
'lw'
>>> a[address] # Key does not exist
Traceback (most recent call last):
File "<pyshell#164>", line 1, in <module>
a[address]
NameError: name 'address' is not defined
- Use get (key) to get a value, the key does not exist, returns None, or you can set the default value returned when the key does not exist.
>>> a.get('name')
'lw'
>>> a.get('address')
>>> a.get('address', 'Xi'an')
'Xi'an'
- List all key-value pairs using items(), all keys using keys(), and all values().
>>> a.items()
dict_items([('name', 'lw'), ('age', 28), ('job', 'programmer')])
>>> a.keys()
dict_keys(['name', 'age', 'job'])
>>> a.values()
dict_values(['lw', 28, 'programmer'])
- Number of dictionary elements
len() returns the length of the dictionary, that is, the number of dictionary elements. - Detect if a key is in a dictionary
>>> 'name' in a True
Add, modify, delete dictionary elements
- Use [] to add key-value pairs, overwriting old values if keys exist; If the key does not exist, add a new key-value pair.
>>> a # Original Dictionary
{'name': 'lw', 'age': 28, 'job': 'programmer'}
>>> a['sex'] = 'male' # sex key does not exist, new key-value pair
>>> a
{'name': 'lw', 'age': 28, 'job': 'programmer', 'sex': 'male'}
>>> a['name'] = 'jack' # name key already exists, overwriting old values
>>> a
{'name': 'jack', 'age': 28, 'job': 'programmer', 'sex': 'male'}
- Use update() to add all other dictionary elements to the current dictionary, and if the keys are duplicated, overwrite the old values with the new values.
>>> b = {'name': 'lw', 'age': 28, 'job': 'programmer'}
>>> c = {'name': 'jack', 'sex': 'male'}
>>> b.update(c)
>>> b
{'name': 'jack', 'age': 28, 'job': 'programmer', 'sex': 'male'}
- Delete elements from a dictionary using the del() method; Or use pop() to delete the specified key-value pair and return the corresponding value object; Or use clear() to delete all key-value pairs.
>>> a # Original Dictionary
{'name': 'jack', 'age': 28, 'job': 'programmer', 'sex': 'male'}
>>> del(a['name']) # Delete key-value pairs
>>> a
{'age': 28, 'job': 'programmer', 'sex': 'male'}
>>> a.pop('job') # Delete key-value pairs and return value objects
'programmer'
>>> a
{'age': 28, 'sex': 'male'}
>>> a.clear() # Empty Dictionary
>>> a
{}
- You can use popitem() to randomly delete and return a key-value pair. Because the dictionary is out of order, popitem () randomly pops up an element. You can use this method if you need to remove and process elements one by one.
>>> a
{'age': 28, 'job': 'programmer', 'sex': 'male'}
>>> a.popitem()
('sex', 'male')
Sequence unpacking
Sequence unpacking can be used for tuples, lists, dictionaries and can easily assign values to multiple variables.
>>> x, y, z = 10, 20, 30
>>> x, y, z = (10, 20, 30)
>>> x, y, z = [30, 40, 50]
>>> (x, y ,z) = (15, 25, 35)
>>> (x, y, z) = [13, 23, 43]
>>> [x, y, z] = [15, 16, 17]
>>> [x, y, z] = (18, 28, 38)
>>> x, y, z = {30, 40, 50}
When sequence unpacking is used in a dictionary, the default is to operate on "keys";
If you need to manipulate "value", you need to use values();
If you need to operate on Key Value Pairs, you need to use items().
>>> a = {'age': 28, 'job': 'programmer', 'sex': 'male'}
>>> x, y, z = a # Default Action Key
>>> x
'age'
>>> y
'job'
>>> z
'sex'
>>> x, y, z = a.items() # items() operation key-value pairs
>>> x
('age', 28)
>>> y
('job', 'programmer')
>>> z
('sex', 'male')
>>> x, y, z = a.values() # values() operation value
>>> x
28
>>> y
'programmer'
>>> z
'male'
Section 5 Collection
A collection is an unordered variable sequence, and elements cannot be repeated. In fact, the bottom level of a collection is implemented using a dictionary, and all the elements of a collection are the "keys" of the dictionary.
In Python, collections are mainly made use of their uniqueness, as well as operations such as union, intersection, and difference, so they cannot be accessed directly through subscripts, but can be converted to list s for re-access when they must be accessed.
Collection Creation
1. Basic Grammar {} Creation
>>> a = {1, 3, 5}
>>> a
{1, 3, 5}
2. Use set() to turn a list, tuple, and other iterative objects into a set. If the original data is duplicated, only one is retained.
>>> t1 = (1, 3, 5, 3)
>>> t1
(1, 3, 5, 3)
>>> s1 = set(t1)
>>> s1
{1, 3, 5}
3. Set Derivation
Grammar:
{key for expression in Iterable object} or {key for expression in Iterable object if criteria}
>>> {i for i in range(1, 100) if i % 9 == 0}
{99, 36, 72, 9, 45, 81, 18, 54, 90, 27, 63}
Addition and deletion of collection elements
1. Add elements using the add() method
>>> a = {1, 3, 5}
>>> a.add(7) # Add Elements
>>> a
{1, 3, 5, 7}
2. Use the remove() method to delete the specified element, there will be an error if the element does not exist
>>> a
{1, 3, 5}
>>> a.remove(5) # Delete element
>>> a
{1, 3}
>>> a.remove(2) # Error if element does not exist
Traceback (most recent call last):
File "<pyshell#37>", line 1, in <module>
a.remove(2)
KeyError: 2
3. Randomly delete and return an element using the pop() method
>>> a = {1, 5, 2, 7, 4, 8}
>>> a.pop()
1
>>> a.pop()
2
4. Use the clear() method to delete all elements in the collection
>>> a
{1, 3}
>>> a.clear() # Empty Collection
>>> a
set()
Intersection, union, difference of sets
Intersection: &, intersection, take elements that exist in both a and b
>>> a = {1, 3, 5}
>>> b = {3, 5, 7}
>>> a & b # intersection
{3, 5}
>>> a.intersection(b) # intersection
{3, 5}
Union: |, union, take all elements of a and b
>>> a | b # Union
{1, 3, 5, 7}
>>> a.union(b) # Union
{1, 3, 5, 7}
>>> a | (b - a) # Union
{1, 3, 5, 7}
Difference set: -, difference, in a, not in b
>>> a - b # Difference set
{1}
>>> a.difference(b) # Difference set
{1}
Peer difference set: ^, symmetric_difference, all elements that do not exist in a and b at the same time
>>> a ^ b # Equal difference set
{1, 7}
>>> a.symmetric_difference(b) # Equal difference set
{1, 7}
>>> (a | b) - (a & b) # Equal difference set
{1, 7}