Machine translation based on Transformer
Machine translation is the process of using computers to convert one natural language (source language) into another natural language (target language).
This project is the PaddlePaddle implementation of Machine Translation's mainstream model Transformer, including model training, prediction, and use of custom data. Users can build their own translation model based on the published content.
Transformer is a paper Attention Is All You Need A new network structure proposed in to complete sequence to sequence (Seq2Seq) learning tasks such as Machine Translation, which completely uses the Attention mechanism to realize sequence to sequence modeling.
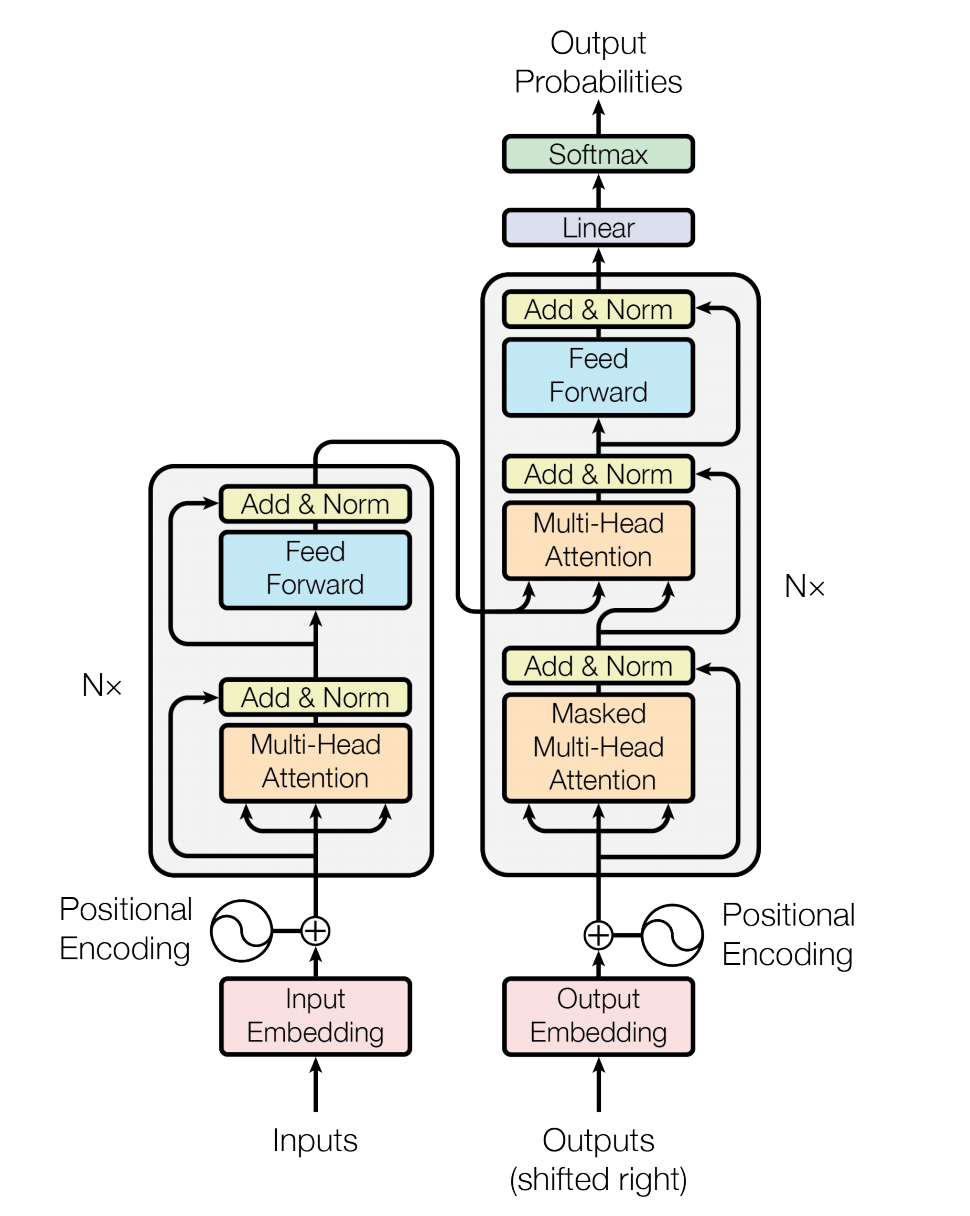
Figure 1: Transformer network structure
Compared with the recurrent neural network (RNN) widely used in the previous Seq2Seq model, using Self Attention to transform input sequence to output sequence mainly has the following advantages:
- Low computational complexity
- For the sequence with feature dimension D and length N, the calculation complexity in RNN is O(n * d * d) (n time steps, each time step calculates the matrix vector multiplication of D dimension), and the calculation complexity in self attention is O(n * n * d) (n time steps calculate the vector dot product of D dimension or other correlation functions in pairs). N is usually less than D.
- High computational parallelism
- The calculation of the current time step in RNN depends on the calculation result of the previous time step; The calculation of each time step in self attention only depends on the input and does not depend on the output of the previous time step. Each time step can be completely parallel.
- Easy to learn long-range dependencies
- The association between two positions with a distance of N in RNN needs n steps to be established; Any two positions in self attention are directly connected; The shorter the path, the easier the signal propagation.
The sequence modeling module structure based on self attention introduced in Transformer has been widely used in semantic representation models such as Bert and achieved remarkable results.
- The association between two positions with a distance of N in RNN needs n steps to be established; Any two positions in self attention are directly connected; The shorter the path, the easier the signal propagation.
More detailed interpretation of Transformer
Environment introduction
-
The PaddlePaddle framework, the AI Studio platform, has installed the latest version of 2.1 by default.
-
Paddelnlp, depth compatible frame 2.1, is the best practice of propeller frame 2.1 in the NLP field.
!unzip -o transformer_mt.zip
%cd transformer_mt/
[Errno 2] No such file or directory: 'transformer_mt/' /home/aistudio/transformer_mt
# Installation dependency !pip install --upgrade paddlenlp -i https://pypi.tuna.tsinghua.edu.cn/simple !pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already up-to-date: paddlenlp in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (2.1.0) Requirement already satisfied, skipping upgrade: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.70.11.1) Requirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1) Requirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2) Requirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4) Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0) Requirement already satisfied, skipping upgrade: paddlefsl==1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.0.0) Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0) Requirement already satisfied, skipping upgrade: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->paddlenlp) (0.3.3) Requirement already satisfied, skipping upgrade: numpy>=1.14.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (1.20.3) Requirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.24.2) Requirement already satisfied, skipping upgrade: tqdm~=4.27.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlefsl==1.0.0->paddlenlp) (4.27.0) Requirement already satisfied, skipping upgrade: requests~=2.24.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlefsl==1.0.0->paddlenlp) (2.24.0) Requirement already satisfied, skipping upgrade: pillow==8.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlefsl==1.0.0->paddlenlp) (8.2.0) Requirement already satisfied, skipping upgrade: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.15.0) Requirement already satisfied, skipping upgrade: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (2.1.0) Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1) Requirement already satisfied, skipping upgrade: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.6.3) Requirement already satisfied, skipping upgrade: chardet<4,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests~=2.24.0->paddlefsl==1.0.0->paddlenlp) (3.0.4) Requirement already satisfied, skipping upgrade: idna<3,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests~=2.24.0->paddlefsl==1.0.0->paddlenlp) (2.8) Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests~=2.24.0->paddlefsl==1.0.0->paddlenlp) (1.25.6) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests~=2.24.0->paddlefsl==1.0.0->paddlenlp) (2019.9.11) Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: attrdict==2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 1)) (2.0.1) Requirement already satisfied: PyYAML==5.4.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 2)) (5.4.1) Requirement already satisfied: subword_nmt==0.3.7 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 3)) (0.3.7) Requirement already satisfied: jieba==0.42.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 4)) (0.42.1) Requirement already satisfied: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from attrdict==2.0.1->-r requirements.txt (line 1)) (1.15.0)
Pipeline

Figure 2: Pipeline
import os import time import yaml import logging import argparse import numpy as np from pprint import pprint from attrdict import AttrDict import jieba import numpy as np from functools import partial import paddle import paddle.distributed as dist from paddle.io import DataLoader,BatchSampler from paddlenlp.data import Vocab, Pad from paddlenlp.datasets import load_dataset from paddlenlp.transformers import TransformerModel, InferTransformerModel, CrossEntropyCriterion, position_encoding_init from paddlenlp.utils.log import logger from utils import post_process_seq
1. Data preprocessing
This tutorial uses CWMT The Chinese and English data in the data set are used as training corpus,
CWMT dataset is 9 million + and of high quality, which is very suitable for training Transformer machine translation.
Jieba+BPE is required for Chinese and BPE is required for English
BPE(Byte Pair Encoding)
BPE benefits:
- Compressed thesaurus;
- Alleviate the OOV(out of vocabulary) problem to a certain extent
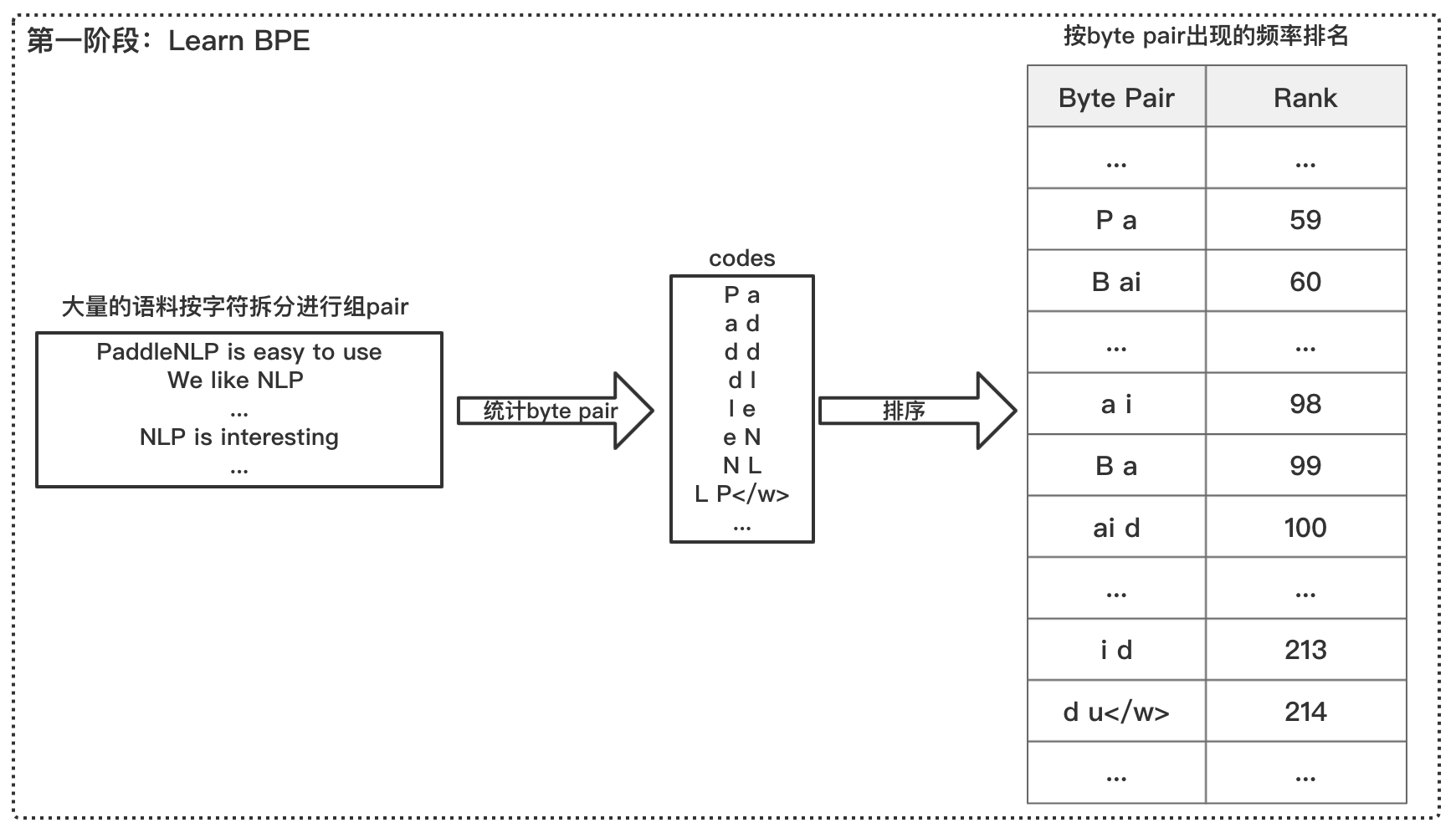
Figure 3: learn BPE
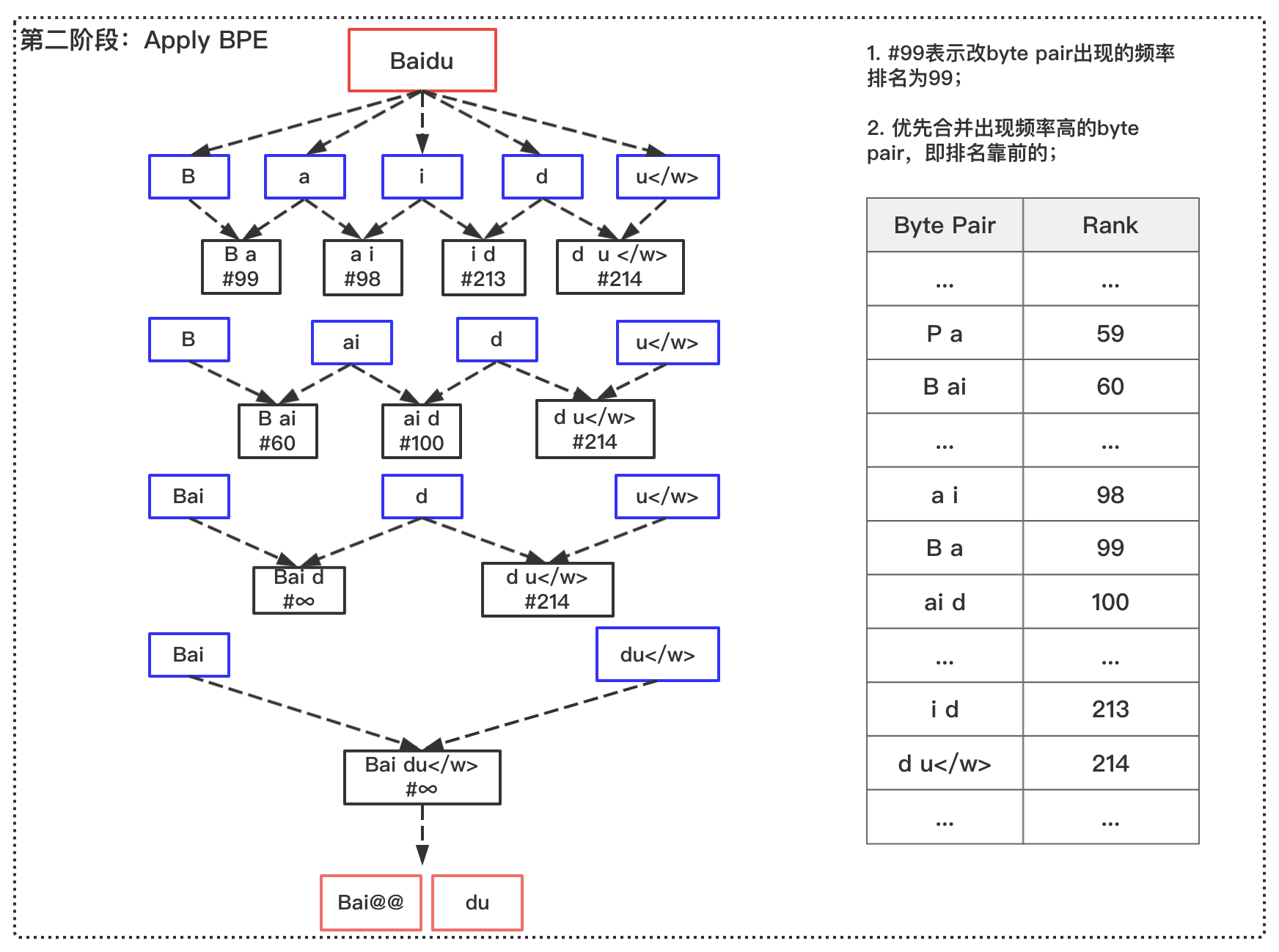

Figure 5: Jieba+BPE
# Data preprocessing process, including jieba word segmentation, bpe word segmentation and thesaurus. !bash preprocess.sh
jieba tokenize... Building prefix dict from the default dictionary ... Loading model from cache /tmp/jieba.cache Loading model cost 0.705 seconds. Prefix dict has been built successfully. source learn-bpe and apply-bpe... no pair has frequency >= 2. Stopping target learn-bpe and apply-bpe... no pair has frequency >= 2. Stopping source get-vocab. if loading pretrained model, use its vocab. target get-vocab. if loading pretrained model, use its vocab. Over.
# Download pre training model !bash get_data_and_model.sh
Over.
2. Construct Dataloader
Create below_ data_ The loader function is used to create DataLoader objects required for training sets and validation sets,
create_ infer_ The loader function is used to create the DataLoader object required by the prediction set,
The DataLoader object is used to generate batch by batch data. The following is a brief description of the paddlenlp built-in function invoked in the function:
- paddlenlp.data.Vocab.load_vocabulary: vocab thesaurus class, which collects a series of methods for mapping between text token and ids, and supports the construction of thesaurus from files, dictionaries, json and other methods
- paddlenlp.datasets.load_dataset: when creating a dataset from a local file, it is recommended to give a read function according to the format of the local dataset and pass it in to load_ Create a dataset in dataset()
- paddlenlp.data.Pad: padding operation
For details, please refer to PaddleNLP documentation
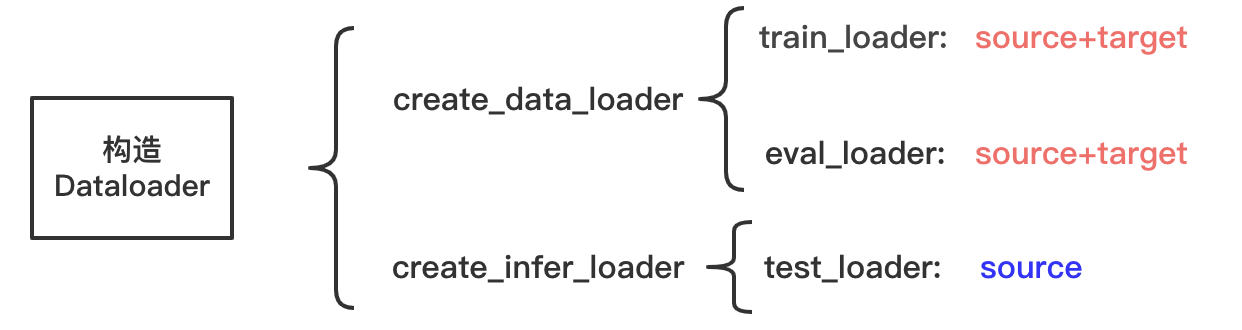
Figure 6: process of constructing Dataloader
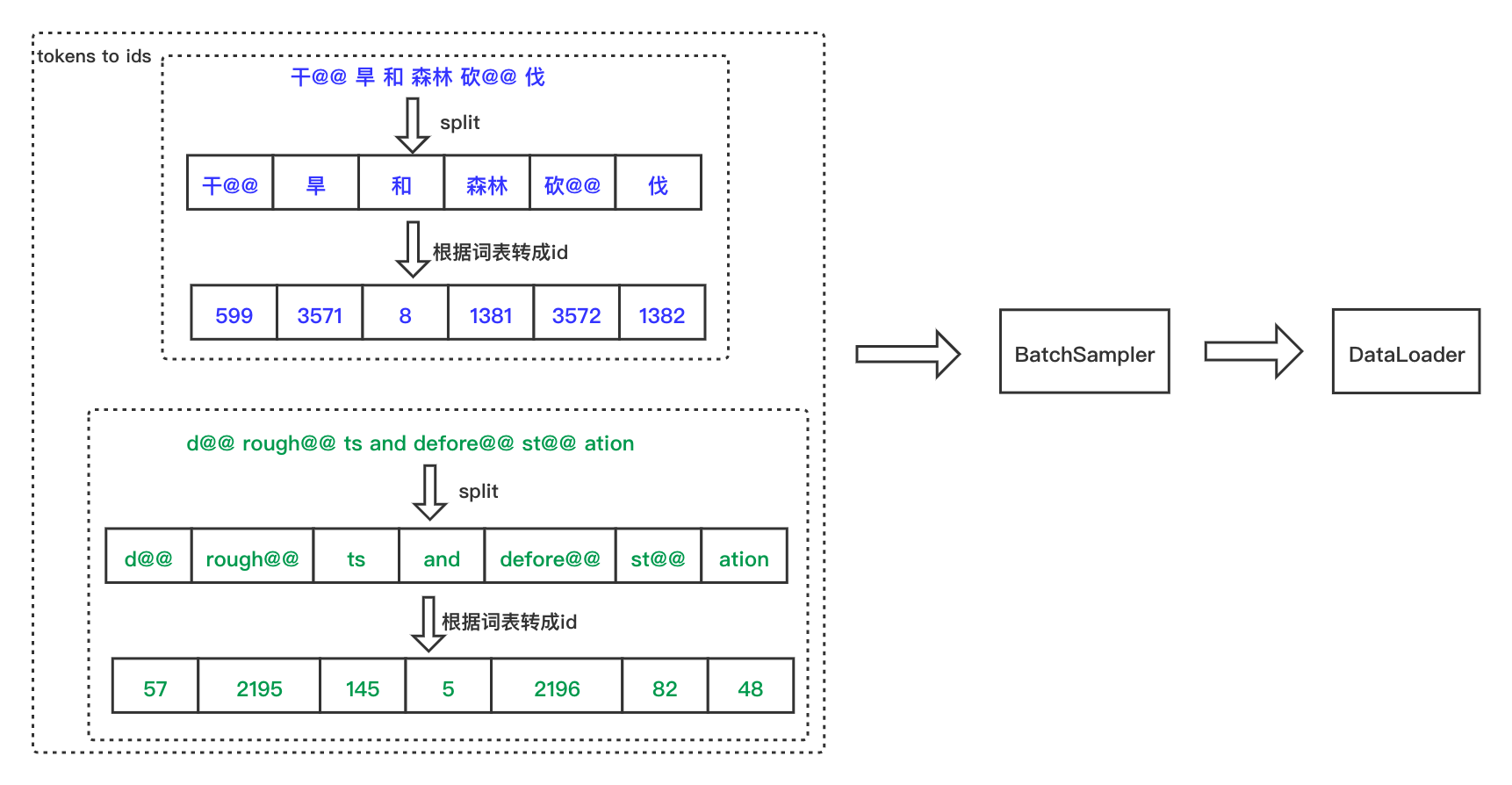
Figure 7: Dataloader details
# Customize the method of reading local data
def read(src_path, tgt_path, is_predict=False):
if is_predict:
with open(src_path, 'r', encoding='utf8') as src_f:
for src_line in src_f.readlines():
src_line = src_line.strip()
if not src_line:
continue
yield {'src':src_line, 'tgt':''}
else:
with open(src_path, 'r', encoding='utf8') as src_f, open(tgt_path, 'r', encoding='utf8') as tgt_f:
for src_line, tgt_line in zip(src_f.readlines(), tgt_f.readlines()):
src_line = src_line.strip()
if not src_line:
continue
tgt_line = tgt_line.strip()
if not tgt_line:
continue
yield {'src':src_line, 'tgt':tgt_line}
# Filtering length ≤ min_len or ≥ max_len's data
def min_max_filer(data, max_len, min_len=0):
# 1 for special tokens.
data_min_len = min(len(data[0]), len(data[1])) + 1
data_max_len = max(len(data[0]), len(data[1])) + 1
return (data_min_len >= min_len) and (data_max_len <= max_len)
# Create dataloader for training set and verification set
def create_data_loader(args):
train_dataset = load_dataset(read, src_path=args.training_file.split(',')[0], tgt_path=args.training_file.split(',')[1], lazy=False)
dev_dataset = load_dataset(read, src_path=args.validation_file.split(',')[0], tgt_path=args.validation_file.split(',')[1], lazy=False)
src_vocab = Vocab.load_vocabulary(
args.src_vocab_fpath,
bos_token=args.special_token[0],
eos_token=args.special_token[1],
unk_token=args.special_token[2])
trg_vocab = Vocab.load_vocabulary(
args.trg_vocab_fpath,
bos_token=args.special_token[0],
eos_token=args.special_token[1],
unk_token=args.special_token[2])
padding_vocab = (
lambda x: (x + args.pad_factor - 1) // args.pad_factor * args.pad_factor
)
args.src_vocab_size = padding_vocab(len(src_vocab))
args.trg_vocab_size = padding_vocab(len(trg_vocab))
def convert_samples(sample):
source = sample['src'].split()
target = sample['tgt'].split()
source = src_vocab.to_indices(source)
target = trg_vocab.to_indices(target)
return source, target
# Training set dataloader and verification set dataloader
data_loaders = []
for i, dataset in enumerate([train_dataset, dev_dataset]):
dataset = dataset.map(convert_samples, lazy=False).filter(
partial(min_max_filer, max_len=args.max_length))
# BatchSampler: https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/io/BatchSampler_cn.html
batch_sampler = BatchSampler(dataset,batch_size=args.batch_size, shuffle=True,drop_last=False)
# DataLoader: https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/io/DataLoader_cn.html
data_loader = DataLoader(
dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=partial(
prepare_train_input,
bos_idx=args.bos_idx,
eos_idx=args.eos_idx,
pad_idx=args.bos_idx),
num_workers=0,
return_list=True)
data_loaders.append(data_loader)
return data_loaders
def prepare_train_input(insts, bos_idx, eos_idx, pad_idx):
"""
Put all padded data needed by training into a list.
"""
word_pad = Pad(pad_idx)
src_word = word_pad([inst[0] + [eos_idx] for inst in insts])
trg_word = word_pad([[bos_idx] + inst[1] for inst in insts])
lbl_word = np.expand_dims(
word_pad([inst[1] + [eos_idx] for inst in insts]), axis=2)
data_inputs = [src_word, trg_word, lbl_word]
return data_inputs
# Create the dataloader of the test set. The principle and steps are the same as above (create the dataloader of the training set and the verification set)
def create_infer_loader(args):
dataset = load_dataset(read, src_path=args.predict_file, tgt_path=None, is_predict=True, lazy=False)
src_vocab = Vocab.load_vocabulary(
args.src_vocab_fpath,
bos_token=args.special_token[0],
eos_token=args.special_token[1],
unk_token=args.special_token[2])
trg_vocab = Vocab.load_vocabulary(
args.trg_vocab_fpath,
bos_token=args.special_token[0],
eos_token=args.special_token[1],
unk_token=args.special_token[2])
padding_vocab = (
lambda x: (x + args.pad_factor - 1) // args.pad_factor * args.pad_factor
)
args.src_vocab_size = padding_vocab(len(src_vocab))
args.trg_vocab_size = padding_vocab(len(trg_vocab))
def convert_samples(sample):
source = sample['src'].split()
target = sample['tgt'].split()
source = src_vocab.to_indices(source)
target = trg_vocab.to_indices(target)
return source, target
dataset = dataset.map(convert_samples, lazy=False)
# BatchSampler: https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/io/BatchSampler_cn.html
batch_sampler = BatchSampler(dataset,batch_size=args.infer_batch_size,drop_last=False)
# DataLoader: https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/io/DataLoader_cn.html
data_loader = DataLoader(
dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=partial(
prepare_infer_input,
bos_idx=args.bos_idx,
eos_idx=args.eos_idx,
pad_idx=args.bos_idx),
num_workers=0,
return_list=True)
return data_loader, trg_vocab.to_tokens
def prepare_infer_input(insts, bos_idx, eos_idx, pad_idx):
"""
Put all padded data needed by beam search decoder into a list.
"""
word_pad = Pad(pad_idx)
src_word = word_pad([inst[0] + [eos_idx] for inst in insts])
return [src_word, ]
3. Build model
PaddleNLP provides Transformer API for calling:
- paddlenlp.transformers.TransformerModel : implementation of Transformer model
- paddlenlp.transformers.InferTransformerModel : Transformer models are used to generate
- paddlenlp.transformers.CrossEntropyCriterion : calculate cross entropy loss
- paddlenlp.transformers.position_encoding_init : initialization of Transformer location code
Figure 8: Model Construction
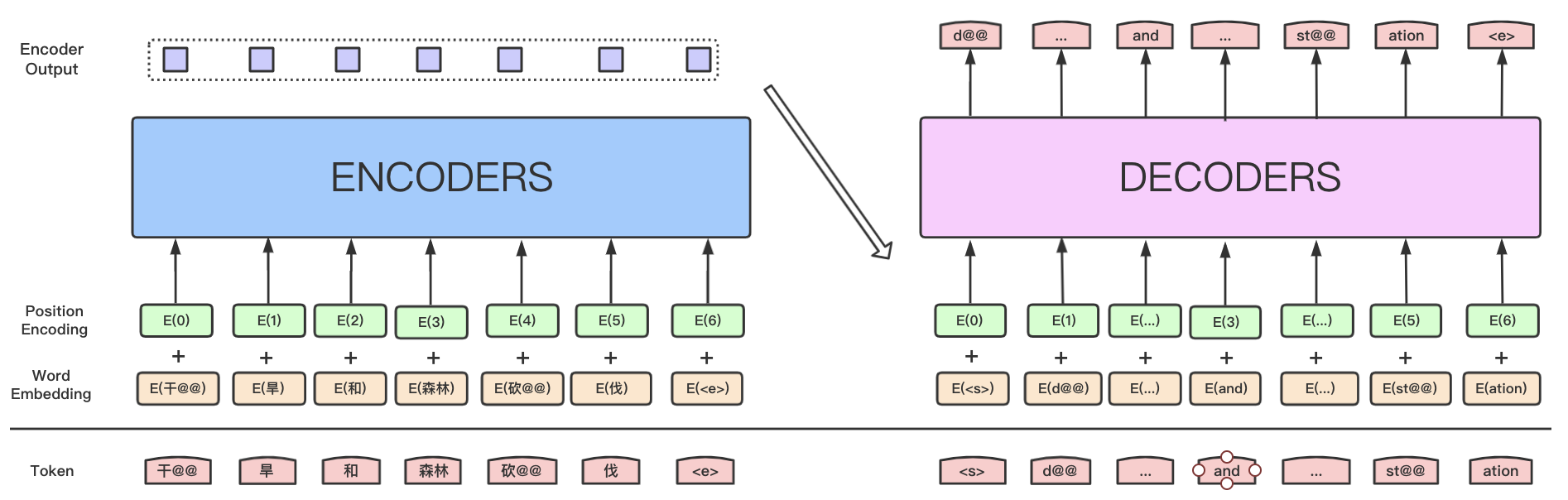
Figure 9: Example
4. Training model
Run do_train function,
In do_ In the train function, configure the optimizer, loss function, and evaluation index perflexity;
Perplexity, or confusion, is often used to measure the pros and cons of language models, that is, the smoothness of sentences. It is generally used in the fields of machine translation and text generation. The smaller the perflexity, the smoother the sentence, and the better the language model.
Figure 10: Training Model
def do_train(args):
if args.use_gpu:
place = "gpu"
else:
place = "cpu"
paddle.set_device(place)
# Set seed for CE
random_seed = eval(str(args.random_seed))
if random_seed is not None:
paddle.seed(random_seed)
# Define data loader
(train_loader), (eval_loader) = create_data_loader(args)
# Define model
transformer = TransformerModel(
src_vocab_size=args.src_vocab_size,
trg_vocab_size=args.trg_vocab_size,
max_length=args.max_length + 1,
num_encoder_layers=args.n_layer,
num_decoder_layers=args.n_layer,
n_head=args.n_head,
d_model=args.d_model,
d_inner_hid=args.d_inner_hid,
dropout=args.dropout,
weight_sharing=args.weight_sharing,
bos_id=args.bos_idx,
eos_id=args.eos_idx)
# Define loss
criterion = CrossEntropyCriterion(args.label_smooth_eps, args.bos_idx)
scheduler = paddle.optimizer.lr.NoamDecay(
args.d_model, args.warmup_steps, args.learning_rate, last_epoch=0)
# Define optimizer
optimizer = paddle.optimizer.Adam(
learning_rate=scheduler,
beta1=args.beta1,
beta2=args.beta2,
epsilon=float(args.eps),
parameters=transformer.parameters())
step_idx = 0
# Train loop
for pass_id in range(args.epoch):
batch_id = 0
for input_data in train_loader:
(src_word, trg_word, lbl_word) = input_data
logits = transformer(src_word=src_word, trg_word=trg_word)
sum_cost, avg_cost, token_num = criterion(logits, lbl_word)
# Calculated gradient
avg_cost.backward()
# Update parameters
optimizer.step()
# Gradient clearing
optimizer.clear_grad()
if (step_idx + 1) % args.print_step == 0 or step_idx == 0:
total_avg_cost = avg_cost.numpy()
logger.info(
"step_idx: %d, epoch: %d, batch: %d, avg loss: %f, "
" ppl: %f " %
(step_idx, pass_id, batch_id, total_avg_cost,
np.exp([min(total_avg_cost, 100)])))
if (step_idx + 1) % args.save_step == 0:
# Validation
transformer.eval()
total_sum_cost = 0
total_token_num = 0
with paddle.no_grad():
for input_data in eval_loader:
(src_word, trg_word, lbl_word) = input_data
logits = transformer(
src_word=src_word, trg_word=trg_word)
sum_cost, avg_cost, token_num = criterion(logits,
lbl_word)
total_sum_cost += sum_cost.numpy()
total_token_num += token_num.numpy()
total_avg_cost = total_sum_cost / total_token_num
logger.info("validation, step_idx: %d, avg loss: %f, "
" ppl: %f" %
(step_idx, total_avg_cost,
np.exp([min(total_avg_cost, 100)])))
transformer.train()
if args.save_model:
model_dir = os.path.join(args.save_model,
"step_" + str(step_idx))
if not os.path.exists(model_dir):
os.makedirs(model_dir)
paddle.save(transformer.state_dict(),
os.path.join(model_dir, "transformer.pdparams"))
paddle.save(optimizer.state_dict(),
os.path.join(model_dir, "transformer.pdopt"))
batch_id += 1
step_idx += 1
scheduler.step()
if args.save_model:
model_dir = os.path.join(args.save_model, "step_final")
if not os.path.exists(model_dir):
os.makedirs(model_dir)
paddle.save(transformer.state_dict(),
os.path.join(model_dir, "transformer.pdparams"))
paddle.save(optimizer.state_dict(),
os.path.join(model_dir, "transformer.pdopt"))
# Read in parameters
yaml_file = 'transformer.base.yaml'
with open(yaml_file, 'rt') as f:
args = AttrDict(yaml.safe_load(f))
pprint(args)
{'batch_size': 50,
'beam_size': 5,
'beta1': 0.9,
'beta2': 0.997,
'bos_idx': 0,
'd_inner_hid': 2048,
'd_model': 512,
'dropout': 0.1,
'eos_idx': 1,
'epoch': 1,
'eps': '1e-9',
'infer_batch_size': 50,
'init_from_params': 'trained_models/CWMT2021_step_345000/',
'label_smooth_eps': 0.1,
'learning_rate': 2.0,
'max_length': 256,
'max_out_len': 256,
'n_best': 1,
'n_head': 8,
'n_layer': 6,
'output_file': 'train_dev_test/predict.txt',
'pad_factor': 8,
'predict_file': 'train_dev_test/ccmt2019-news.zh2en.source_bpe',
'print_step': 10,
'random_seed': 'None',
'save_model': 'trained_models',
'save_step': 20,
'special_token': ['<s>', '<e>', '<unk>'],
'src_vocab_fpath': 'train_dev_test/vocab.ch.src',
'src_vocab_size': 10000,
'training_file': 'train_dev_test/train.ch.bpe,train_dev_test/train.en.bpe',
'trg_vocab_fpath': 'train_dev_test/vocab.en.tgt',
'trg_vocab_size': 10000,
'unk_idx': 2,
'use_gpu': True,
'validation_file': 'train_dev_test/dev.ch.bpe,train_dev_test/dev.en.bpe',
'warmup_steps': 8000,
'weight_sharing': False}
do_train(args)
[2021-10-20 18:45:23,800] [ INFO] - step_idx: 0, epoch: 0, batch: 0, avg loss: 10.526473, ppl: 37289.726562 [2021-10-20 18:45:24,991] [ INFO] - step_idx: 9, epoch: 0, batch: 9, avg loss: 10.517828, ppl: 36968.742188 [2021-10-20 18:45:26,296] [ INFO] - step_idx: 19, epoch: 0, batch: 19, avg loss: 10.475711, ppl: 35444.054688 [2021-10-20 18:45:26,404] [ INFO] - validation, step_idx: 19, avg loss: 10.480215, ppl: 35604.062500
5. Forecasting and evaluation
The final training effect of the model can generally be tested through the test set, and the BLEU value is generally calculated in the field of machine translation.

Figure 11: Forecast and evaluation
def do_predict(args):
if args.use_gpu:
place = "gpu"
else:
place = "cpu"
paddle.set_device(place)
# Define data loader
test_loader, to_tokens = create_infer_loader(args)
# Define model
transformer = InferTransformerModel(
src_vocab_size=args.src_vocab_size,
trg_vocab_size=args.trg_vocab_size,
max_length=args.max_length + 1,
num_encoder_layers=args.n_layer,
num_decoder_layers=args.n_layer,
n_head=args.n_head,
d_model=args.d_model,
d_inner_hid=args.d_inner_hid,
dropout=args.dropout,
weight_sharing=args.weight_sharing,
bos_id=args.bos_idx,
eos_id=args.eos_idx,
beam_size=args.beam_size,
max_out_len=args.max_out_len)
# Load the trained model
assert args.init_from_params, (
"Please set init_from_params to load the infer model.")
model_dict = paddle.load(
os.path.join(args.init_from_params, "transformer.pdparams"))
# To avoid a longer length than training, reset the size of position
# encoding to max_length
model_dict["encoder.pos_encoder.weight"] = position_encoding_init(
args.max_length + 1, args.d_model)
model_dict["decoder.pos_encoder.weight"] = position_encoding_init(
args.max_length + 1, args.d_model)
transformer.load_dict(model_dict)
# Set evaluate mode
transformer.eval()
f = open(args.output_file, "w")
with paddle.no_grad():
for (src_word, ) in test_loader:
finished_seq = transformer(src_word=src_word)
finished_seq = finished_seq.numpy().transpose([0, 2, 1])
for ins in finished_seq:
for beam_idx, beam in enumerate(ins):
if beam_idx >= args.n_best:
break
id_list = post_process_seq(beam, args.bos_idx, args.eos_idx)
word_list = to_tokens(id_list)
sequence = " ".join(word_list) + "\n"
f.write(sequence)
f.close()
do_predict(args)
Model evaluation
In the prediction result, the output of each row is the translation with the highest score corresponding to the input of the row. For the data using BPE, the predicted translation result will also be the data represented by BPE, which can be correctly evaluated only after being restored to the original data (here refers to the tokenize d data)
# Restore the prediction result in predict.txt to the data after tokenize ! sed -r 's/(@@ )|(@@ ?$)//g' train_dev_test/predict.txt > train_dev_test/predict.tok.txt # BLEU assessment tool comes from https://github.com/moses-smt/mosesdecoder.git ! tar -zxf mosesdecoder.tar.gz # Computing multi bleu ! perl mosesdecoder/scripts/generic/multi-bleu.perl train_dev_test/ccmt2019-news.zh2en.ref*.txt < train_dev_test/predict.tok.txt
BLEU = 38.11, 74.5/49.1/32.5/21.7 (BP=0.951, ratio=0.952, hyp_len=22252, ref_len=23371) It is not advisable to publish scores from multi-bleu.perl. The scores depend on your tokenizer, which is unlikely to be reproducible from your paper or consistent across research groups. Instead you should detokenize then use mteval-v14.pl, which has a standard tokenization. Scores from multi-bleu.perl can still be used for internal purposes when you have a consistent tokenizer.