Regular season: Chinese News Text Title Classification
I Scheme introduction
1.1 introduction to the competition:
Text classification is to automatically classify and mark the text set (or other entities or objects) according to a certain classification system or standard with the help of computer. This competition is for news title text classification. Players need to train a news classification model according to the news title text and category label provided, and then classify the news title text of the test set. Accuracy = the correct number of classification / the total number of classification required is used in the evaluation index. At the same time, the contestants need to use the propeller frame and paddelnlp, the core development library in the field of propeller text. Paddelnlp has a concise and easy-to-use whole process API in the field of text, multi scene application examples, very rich pre training models, and is deeply suitable for the propeller frame 2 X version.
Game portal: Regular season: Chinese News Text Title Classification
1.2 data introduction:
THUCNews is generated based on the historical data of Sina News RSS subscription channel from 2005 to 2011. It contains 740000 news documents (2.19 GB), all in UTF-8 plain text format. Based on the original Sina News classification system, the competition data set is re integrated and divided into 14 candidate classification categories: finance, lottery, real estate, stock, home, education, science and technology, society, fashion, current politics, sports, constellation, game and entertainment. A total of 832471 training data were provided.
Format of data set provided by the competition: training set and verification set format: original title + \ t + label, test set format: original title.
1.3 model idea:
The competition question is a relatively conventional short text classification task. Under the paddelnlp framework, firstly, nine pre training models are fine tuned to train and optimize the 14 classification model of news headlines, and then the processing results of different models are integrated through integrated learning (relative voting method, maximum score method, etc.), and finally the result file is analyzed to generate pseudo tags and iteratively expand the scale of the training set.
Since the pre training model consumes a lot of memory resources, you need to choose the supreme version of GPU environment when running! If the video memory is insufficient, please reduce the batchsize appropriately!
BERT pre knowledge supplement: [principle] classic pre training model - BERT
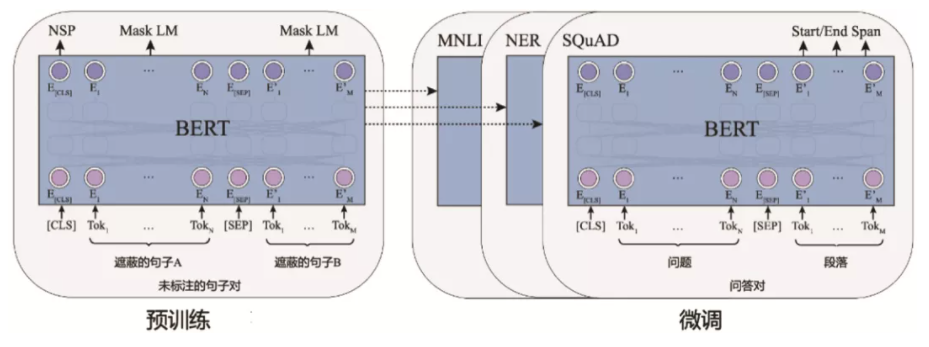
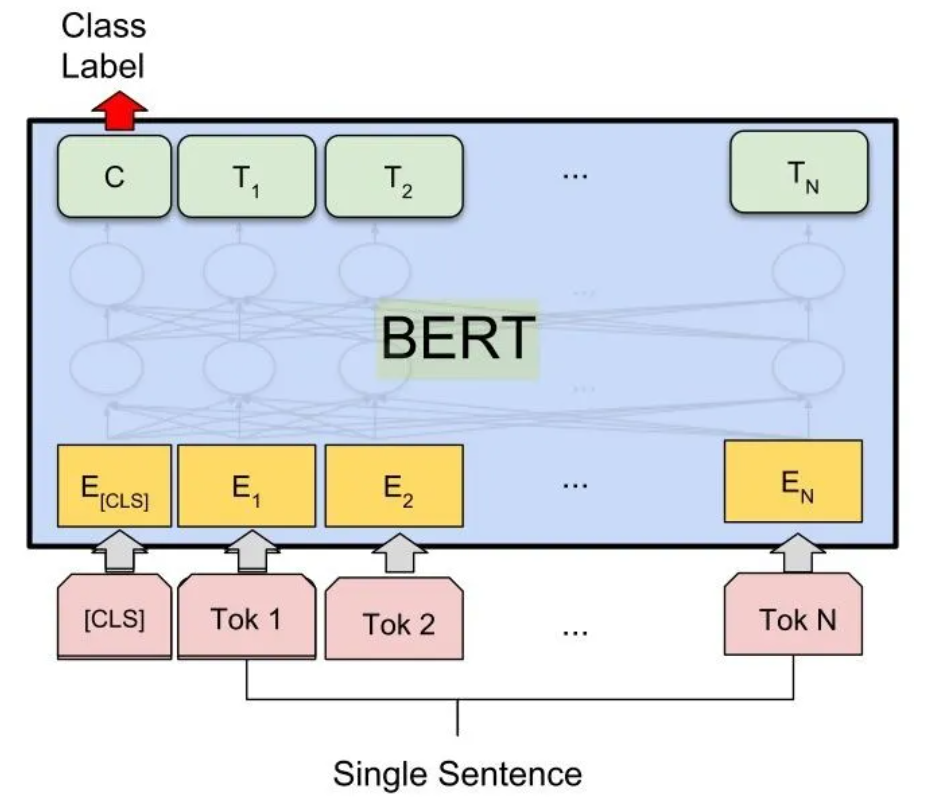
II Data reading and analysis
# Enter the game data set storage directory %cd /home/aistudio/dataset/
/home/aistudio/dataset
# Reading datasets using pandas
import pandas as pd
train = pd.read_table('train.txt', sep='\t',header=None) # Training set
dev = pd.read_table('dev.txt', sep='\t',header=None) # Verification set (officially divided)
test = pd.read_table('test.txt', sep='\t',header=None) # Test set
# Manually add column names to the dataset train.columns = ["text_a",'label'] dev.columns = ["text_a",'label'] test.columns = ["text_a"]
# Splice training and validation sets for statistical analysis total = pd.concat([train,dev],axis=0) print(total.label.unique()) print(total.label.unique().tolist())
['science and technology' 'Sports' 'Current politics' 'shares' 'entertainment' 'education' 'Home Furnishing' 'Finance and Economics' 'house property' 'Sociology' 'game' 'lottery' 'constellation' 'fashion'] ['science and technology', 'Sports', 'Current politics', 'shares', 'entertainment', 'education', 'Home Furnishing', 'Finance and Economics', 'house property', 'Sociology', 'game', 'lottery', 'constellation', 'fashion']
# Splice training and validation sets for statistical analysis
total = pd.concat([train,dev],axis=0)
print("The number and proportion of labels in different categories are as follows:")
# Get the number and proportion of labels of different categories, which are arranged in descending order. The data type is "pandas.core.series.Series"
series_Count_desc = total['label'].value_counts()
series_Ratio_desc = (train['label'].value_counts())/sum(train['label'].value_counts())
# The number and proportion of labels in different categories are merged, and they are still arranged in descending order
series_Info_desc = pd.concat([series_Count_desc,series_Ratio_desc],axis=1)
# print(series_Info_desc)
# print(series_Info_desc.keys())
# Define categories to classify
label_list = total.label.unique().tolist()
# Establish a mapping table from classification label to ID
Label_ID_map = {Val:ID for ID,Val in enumerate(label_list)}
series_Info_data = pd.Series(Label_ID_map)
# print(series_Info_data.keys())
# Rearrange the number and proportion of labels in different categories according to the order of ID
df_Info_data = pd.concat([series_Info_data,series_Info_desc],axis=1)
# Set column name
df_Info_data.columns=['ID','Count','Ratio']
print(df_Info_data)
# print(type(df_Info_data))
The number and proportion of labels in different categories are as follows:
ID Count Ratio
Technology 0 162245 0.194874
Physical education 1 130982 0.157401
Current politics 2 62867 0.075455
Stock 3 153949 0.184670
Entertainment 4 92228 0.110792
Education 5 41680 0.050159
Home 6 32363 0.038976
Caijing 7 36963 0.044372
Property 8 19922 0.023981
Social 9 50541 0.060820
Game 10 24283 0.029152
Lottery 11 7598 0.009077
Constellation 12 3515 0.004281
Fashion 13 13335 0.015990
#Calculate the weights of different types of loss function: the reciprocal of the proportion, which needs to be normalized series_Recip_desc = 1/series_Ratio_desc#reciprocal series_Weight_desc = series_Recip_desc series_WeightNorm_desc = series_Recip_desc/sum(series_Recip_desc)#normalization # print(series_Recip_desc) # print(series_Weight_desc) #Number and proportion of labels merged into different categories df_Info_data = pd.concat([df_Info_data,series_Weight_desc],axis=1) df_Info_data = pd.concat([df_Info_data,series_WeightNorm_desc],axis=1) # Set column name df_Info_data.columns=['ID','Count','Ratio','Weight','Weight Norm'] print(df_Info_data)
ID Count Ratio Weight Weight Norm Technology 0 162245 0.194874 5.131522 0.008467 Physical education 1 130982 0.157401 6.353183 0.010482 Current politics 2 62867 0.075455 13.252862 0.021867 Stock 3 153949 0.184670 5.415058 0.008935 Entertainment 4 92228 0.110792 9.025897 0.014892 Education 5 41680 0.050159 19.936703 0.032895 Home 6 32363 0.038976 25.657085 0.042333 Caijing 7 36963 0.044372 22.536494 0.037184 Property 8 19922 0.023981 41.699695 0.068802 Social 9 50541 0.060820 16.442063 0.027129 Game 10 24283 0.029152 34.303018 0.056598 Lottery 11 7598 0.009077 110.171449 0.181778 Constellation 12 3515 0.004281 233.614095 0.385452 Fashion 13 13335 0.015990 62.539146 0.103187
# Global settings to solve the problem of Chinese display errors in matplotlib. Refer to: https://aistudio.baidu.com/aistudio/projectdetail/1658980 %matplotlib inline import matplotlib import matplotlib.pyplot as plt import matplotlib.font_manager as font_manager # Set display Chinese matplotlib.rcParams['font.sans-serif'] = ['FZSongYi-Z13S'] # Specifies the default font matplotlib.rcParams['axes.unicode_minus'] = False # Solve the problem that the negative sign '-' is displayed as a square in the saved image # Set font size matplotlib.rcParams['font.size'] = 16 # Draw the distribution of different types of labels (in ascending order of ID) plt.subplot2grid((2,2),(0,0),colspan=2) df_Info_data['Count'].plot(kind='bar'); # Draw the distribution of different types of labels (in descending order according to the number of samples) plt.subplot2grid((2,2),(1,0),colspan=2) series_Count_desc.plot(kind='bar');
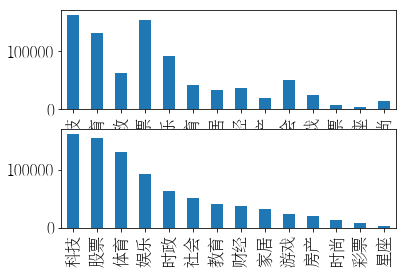
# Statistics the length information of "training set + verification set"
print("The length information of Train&&Dev is as follows:/n")
print(total['text_a'].map(len).describe())
# Statistics the length information of "test set"
print("The length information of Test is as follows:/n")
print(test['text_a'].map(len).describe())
The length information of Train&&Dev is as follows:/n count 832471.000000 mean 19.388112 std 4.097139 min 2.000000 25% 17.000000 50% 20.000000 75% 23.000000 max 48.000000 Name: text_a, dtype: float64 The length information of Test is as follows:/n count 83599.000000 mean 19.815022 std 3.883845 min 3.000000 25% 17.000000 50% 20.000000 75% 23.000000 max 84.000000 Name: text_a, dtype: float64
# Whether to use all data sets (training set + verification set) for training
useTotalData = False
# Whether to use pseudo tags for training
useFakeData = False
# Whether to use only pseudo tags for training (incremental learning)
useFakeOnly = False
if useTotalData == True:
#All data sets (training set + verification set) are used for training
train = pd.concat([train,dev],axis=0)
if useFakeData == True:
#Training with pseudo Tags
train = pd.concat([train,fakeData1],axis=0)
if useFakeOnly == True:
#Training with pseudo tags only (incremental learning)
train = fakeData1
# Save the processed dataset file
train.to_csv('train.csv', sep='\t', index=False) # Save the training set in the format of text_ a. Label, separated by \ t
dev.to_csv('dev.csv', sep='\t', index=False) # Save the validation set in the format text_ a. Label, separated by \ t
test.to_csv('test.csv', sep='\t', index=False) # Save the test set in the format of text_a. Separated by \ t
III Build a baseline model based on PaddleNLP

3.1 setting the operating environment
# Import the required third-party libraries import math import numpy as np import os import collections from functools import partial import random import time import inspect import importlib from tqdm import tqdm import paddle import paddle.nn as nn import paddle.nn.functional as F from paddle.io import IterableDataset from paddle.utils.download import get_path_from_url
# Download paddlenlp2 1. The latest version is 2.2. There will be problems in the following steps !pip install --upgrade paddlenlp==2.1 # Import related packages required by paddlenlp import paddlenlp as ppnlp from paddlenlp.data import JiebaTokenizer, Pad, Stack, Tuple, Vocab from paddlenlp.datasets import MapDataset from paddle.dataset.common import md5file from paddlenlp.datasets import DatasetBuilder
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already up-to-date: paddlenlp==2.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (2.1.0) Requirement already satisfied, skipping upgrade: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.1) (0.70.11.1) Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.1) (2.9.0) Requirement already satisfied, skipping upgrade: paddlefsl==1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.1) (1.0.0) Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.1) (4.1.0) Requirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.1) (1.2.2) Requirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.1) (0.42.1) Requirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.1) (0.4.4) Requirement already satisfied, skipping upgrade: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->paddlenlp==2.1) (0.3.3) Requirement already satisfied, skipping upgrade: numpy>=1.7 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp==2.1) (1.20.3) Requirement already satisfied, skipping upgrade: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp==2.1) (1.16.0) Requirement already satisfied, skipping upgrade: tqdm~=4.27.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlefsl==1.0.0->paddlenlp==2.1) (4.27.0) Requirement already satisfied, skipping upgrade: pillow==8.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlefsl==1.0.0->paddlenlp==2.1) (8.2.0) Requirement already satisfied, skipping upgrade: requests~=2.24.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlefsl==1.0.0->paddlenlp==2.1) (2.24.0) Requirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp==2.1) (0.24.2) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests~=2.24.0->paddlefsl==1.0.0->paddlenlp==2.1) (2019.9.11) Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests~=2.24.0->paddlefsl==1.0.0->paddlenlp==2.1) (1.25.6) Requirement already satisfied, skipping upgrade: chardet<4,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests~=2.24.0->paddlefsl==1.0.0->paddlenlp==2.1) (3.0.4) Requirement already satisfied, skipping upgrade: idna<3,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests~=2.24.0->paddlefsl==1.0.0->paddlenlp==2.1) (2.8) Requirement already satisfied, skipping upgrade: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp==2.1) (1.6.3) Requirement already satisfied, skipping upgrade: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp==2.1) (2.1.0) Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp==2.1) (0.14.1)
3.2 define the pre training model to be fine tuned
In the selection of pre training models, 7 pre training models with better effects in different Chinese fields are selected. After training with the training set, the scores submitted are as follows:
roberta-wwm-ext-large: 89.08
nezha-large-wwm-chinese: 88.96
skep_ernie_1.0_large_ch: 88.82
bert-wwm-ext-chinese: 88.62
macbert-large-chinese: 88.75
huhuiwen/mengzi-bert-base: 88.64
junnyu/hfl-chinese-electra-180g-base-discriminator: 88.28
# Using the Roberta WwM ext large model MODEL_NAME = "roberta-wwm-ext-large" # Just specify the name of the model you want to use and the number of categories of text classification to complete the fine tune network definition, which is classified by splicing a Full Connected network after pre training the model model = ppnlp.transformers.RobertaForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=14) # The classification task is 14, so num_classes is set to 14 # Define the tokenizer corresponding to the model. The tokenizer can convert the original input text into the input data format acceptable to the model. It should be noted that the tokenizer class should correspond to the selected model. For details, see the relevant documents of PaddleNLP tokenizer = ppnlp.transformers.RobertaTokenizer.from_pretrained(MODEL_NAME)
[2022-01-20 11:12:00,457] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/roberta-wwm-ext-large/roberta_chn_large.pdparams [2022-01-20 11:12:05,655] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/roberta-wwm-ext-large/vocab.txt
# Using the Nezha large WwM Chinese model
# Specify the model name and load the model with one click
#model = ppnlp.transformers.NeZhaForSequenceClassification.from_pretrained('nezha-large-wwm-chinese', num_classes=14)
# Similarly, the corresponding Tokenizer is loaded with one click by specifying the model name, which is used to process text data, such as segmentation token and conversion token_id, etc
#tokenizer = ppnlp.transformers.NeZhaTokenizer.from_pretrained('nezha-large-wwm-chinese')
# skep_ernie_1.0_large_ch model # Model name, one click loading #model = ppnlp.transformers.SkepForSequenceClassification.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch", num_classes=14) # Similarly, the corresponding Tokenizer is loaded with one click by specifying the model name, which is used to process text data, such as segmentation token and conversion token_id, etc #tokenizer = ppnlp.transformers.SkepTokenizer.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch")
# Using Bert WwM ext Chinese model MODEL_NAME = "bert-wwm-ext-chinese" # Just specify the name of the model you want to use and the number of categories of text classification to complete the fine tune network definition, which is classified by splicing a Full Connected network after pre training the model model = ppnlp.transformers.BertForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=14) # The classification task is 14, so num_classes is set to 14 # Define the tokenizer corresponding to the model. The tokenizer can convert the original input text into the input data format acceptable to the model. It should be noted that the tokenizer class should correspond to the selected model. For details, see the relevant documents of PaddleNLP tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained(MODEL_NAME)
# Using macbert large Chinese model #MODEL_NAME = "macbert-large-chinese" # Just specify the name of the model you want to use and the number of categories of text classification to complete the fine tune network definition, which is classified by splicing a Full Connected network after pre training the model #model = ppnlp.transformers.BertForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=14) # The classification task is 14, so num_classes is set to 14 # Define the tokenizer corresponding to the model. The tokenizer can convert the original input text into the input data format acceptable to the model. It should be noted that the tokenizer class should correspond to the selected model. For details, see the relevant documents of PaddleNLP #tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained(MODEL_NAME)
# Using the huhuiwen / Mengzi Bert base model #MODEL_NAME = "huhuiwen/mengzi-bert-base" # Just specify the name of the model you want to use and the number of categories of text classification to complete the fine tune network definition, which is classified by splicing a Full Connected network after pre training the model #model = ppnlp.transformers.BertForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=14) # The classification task is 14, so num_classes is set to 14 # Define the tokenizer corresponding to the model. The tokenizer can convert the original input text into the input data format acceptable to the model. It should be noted that the tokenizer class should correspond to the selected model. For details, see the relevant documents of PaddleNLP #tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained(MODEL_NAME)
# Junnyu / HFL Chinese Electra 180g base discriminator model was used
# Specify the model name and load the model with one click
#model = ppnlp.transformers.ElectraForSequenceClassification.from_pretrained('junnyu/hfl-chinese-electra-180g-base-discriminator', num_classes=14)
# Similarly, the corresponding Tokenizer is loaded with one click by specifying the model name, which is used to process text data, such as segmentation token and conversion token_id, etc
#tokenizer = ppnlp.transformers.ElectraTokenizer.from_pretrained('junnyu/hfl-chinese-electra-180g-base-discriminator')
PaddleNLP supports not only RoBERTa pre training model, but also ERNIE, BERT, Electra and other pre training models. For details: PaddleNLP model
The following table summarizes the various pre training models currently supported by PaddleNLP. Users can use the model provided by PaddleNLP to complete questions and answers, sequence classification, token classification and other tasks. At the same time, 22 kinds of pre training parameter weights are provided for users, including the pre training weights of 11 Chinese language models.
| Model | Tokenizer | Supported Task | Model Name |
|---|---|---|---|
| BERT | BertTokenizer | BertModel BertForQuestionAnswering BertForSequenceClassification BertForTokenClassification | bert-base-uncased bert-large-uncased bert-base-multilingual-uncased bert-base-cased bert-base-chinese bert-base-multilingual-cased bert-large-cased bert-wwm-chinese bert-wwm-ext-chinese |
| ERNIE | ErnieTokenizer ErnieTinyTokenizer | ErnieModel ErnieForQuestionAnswering ErnieForSequenceClassification ErnieForTokenClassification | ernie-1.0 ernie-tiny ernie-2.0-en ernie-2.0-large-en |
| RoBERTa | RobertaTokenizer | RobertaModel RobertaForQuestionAnswering RobertaForSequenceClassification RobertaForTokenClassification | roberta-wwm-ext roberta-wwm-ext-large rbt3 rbtl3 |
| ELECTRA | ElectraTokenizer | ElectraModel ElectraForSequenceClassification ElectraForTokenClassification | electra-small electra-base electra-large chinese-electra-small chinese-electra-base |
Note: the Chinese pre training models include Bert base Chinese, Bert WwM Chinese, Bert WwM ext Chinese, ernie-1.0, Ernie tiny, Roberta WwM ext, Roberta WwM ext large, rbt3, rbtl3, China electric base, China Electric small, etc.
3.3 data reading and processing
# Define the file corresponding to the dataset and its file storage format
class NewsData(DatasetBuilder):
#File names corresponding to training set and verification set
SPLITS = {
'train': 'train.csv', # Training set
'dev': 'dev.csv', # Validation set
}
#Get the file names of training set and verification set
def _get_data(self, mode, **kwargs):
filename = self.SPLITS[mode]
return filename
#Read data from file
def _read(self, filename):
with open(filename, 'r', encoding='utf-8') as f:
head = None
for line in f:
data = line.strip().split("\t") # Separate columns with '\ t'
if not head:
head = data
else:
text_a, label = data
yield {"text_a": text_a, "label": label} # The format of this setting data is: text_ a. Label, which can be modified according to the specific situation
#Get category label
def get_labels(self):
return label_list # Category label
# Define dataset loading function
def load_dataset(name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = NewsData # Load defined dataset format
print(reader_cls)
#Dataset load instance
if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs)
else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
#Load dataset by instance
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)
return datasets
# Load training and validation sets train_ds, dev_ds = load_dataset(splits=["train", "dev"])
<class '__main__.NewsData'>
# Define data loading and processing functions
def convert_example(example, tokenizer, max_seq_length=128, is_test=False):
qtconcat = example["text_a"]
encoded_inputs = tokenizer(text=qtconcat, max_seq_len=max_seq_length) # tokenizer is processed into a format acceptable to the model
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
#If it is not a test set, you need to return the label
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:#The test set does not need to return a label
return input_ids, token_type_ids
# Define the data loading function dataloader
def create_dataloader(dataset,
mode='train',
batch_size=1,
batchify_fn=None,
trans_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False
# The training data set is randomly disrupted, and the test data set is not disrupted
if mode == 'train':
batch_sampler = paddle.io.DistributedBatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
else:
batch_sampler = paddle.io.BatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
return paddle.io.DataLoader(
dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
# Parameter setting: # Batch processing size. If the video memory is insufficient, this value can be appropriately reduced # Note that in this scenario, if you use Nezha large WwM Chinese, you need to set batch_size is modified to 256, Chinese xlnet large to 128, and other models to 300. Otherwise, it is easy to cause the problem of explosive display memory batch_size = 256 # The maximum truncation length of the text sequence shall be determined according to the specific length of the text, and the maximum length shall not exceed 512. Through the text length analysis, it can be seen that the maximum text length is 48, so it is set to 48 here max_seq_length = 48
# Process the data into a data format that the model can read in
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack() # labels
): [data for data in fn(samples)]
# Training set iterator
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# Validation set iterator
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
3.4 set fine tune optimization strategy and access evaluation index
The data distribution is uneven, and Focal Loss is used to calculate the loss function.
In order to avoid model instability (oscillation), the "warm-up" strategy (WarmUp) of network training is realized by gradually increasing the learning rate from low to high, as follows:
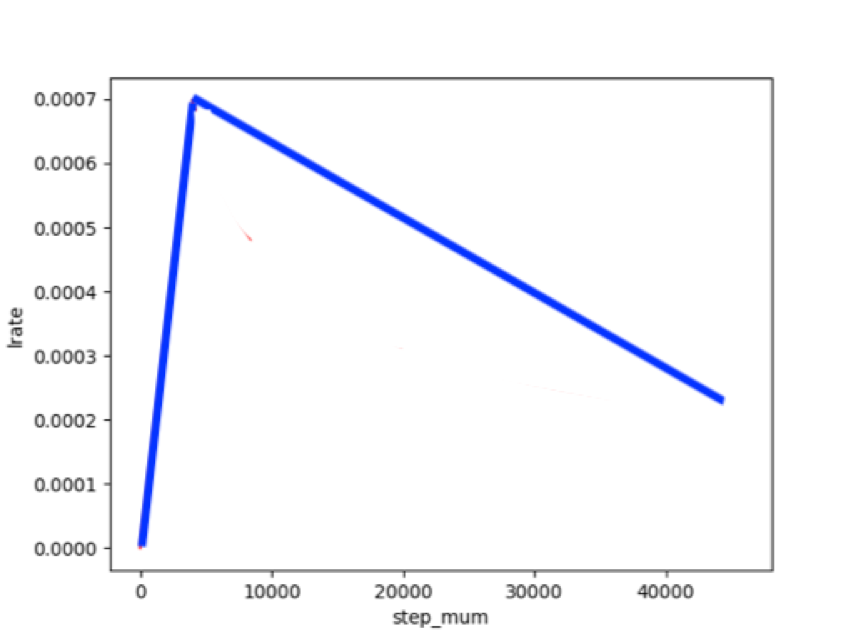
#According to the definition of Focal Loss loss function, it is found that the effect is not as good as Paddle's cross entropy
import paddle.nn.functional as F
class MultiCEFocalLoss(nn.Layer):
#class_num: type quantity, reduction: how to deal with different types of loss function contributions. You can choose: mean, sum, and mean by default.
#use_softmax: whether to softmax the input data
def __init__(self, class_num, gamma=2, alpha=None, reduction='mean',use_softmax=True):
super(MultiCEFocalLoss, self).__init__()
if alpha is None:
self.alpha = paddle.ones((class_num, 1))
elif isinstance(alpha,list):
self.alpha = paddle.to_tensor(alpha,dtype=paddle.float32)
elif isinstance(alpha,[float,int]):
self.alpha = paddle.to_tensor([alpha])
self.gamma = gamma
self.reduction = reduction
self.class_num = class_num
self.use_softmax = use_softmax
def forward(self, preds, labels):
#print("predict",preds)
#print("label",labels)
labels = labels.cast(paddle.int64)
# print("The dimension of preds is:",preds.ndim)
# print("The dimension of labels is:",labels.ndim)
if labels.ndim > 1:#Remove the dimension of single value array in labels
labels = labels.squeeze(1)
#List of predicted values of each type in the sample
if self.use_softmax:#Prediction probability based on softmax
pt = F.softmax(preds,axis=-1)
else:
pt = preds
# print("Processed predict",pt)
#One Hot code of sample label
class_mask = F.one_hot(labels, self.class_num)
# print("One hot of each Label ID",class_mask)
#Convert to 1 column, and the element is the ID of the sample label
ids = labels.reshape((-1, 1))
# print("Label's ID",ids)
# print("Label's alpha",self.alpha)
#The sample label type corresponds to the List composed of weights, and the length is equal to the number of samples
alpha = self.alpha[ids.reshape((-1,1))].reshape((-1,1))
# print("Label's alpha of each sample",alpha)
#The sample label type corresponds to the List composed of predicted values (from pt), and the length is equal to the number of samples
probs = (pt * class_mask).sum(1).reshape((-1, 1)) # Using onehot as mask, the corresponding pt is extracted
# print("Label's predict of each sample",probs)
log_p = probs.log()
# print("Label's log predict of each sample",log_p)
#Weight alpha and log of predicted value of fusion sample label type_ p. Dynamic attenuation factor pow[(1-predicted value), gama], calculate loss function
loss = -alpha * (paddle.pow((1 - probs), self.gamma)) * log_p
# print(loss)
#Fusion of different types of loss function contributions
if self.reduction == 'mean':#average value
loss = loss.mean()
elif self.reduction == 'sum':#the sum
loss = loss.sum()
return loss
# Define hyperparameters, loss, optimizers, etc
from paddlenlp.transformers import LinearDecayWithWarmup, CosineDecayWithWarmup
# Define training configuration parameters:
# Define the maximum learning rate during training
learning_rate = 4e-5
# Training rounds
epochs = 4
# The preheating ratio of learning rate is used to control the Step position of the peak point in the "learning rate Step times" curve. Here, the peak value is reached at 10% of the whole Step and then attenuated.
warmup_proportion = 0.1
# The layer by layer weight attenuation coefficient is similar to the regular term strategy of the model to avoid over fitting of the model
weight_decay = 0.0
#Total number of steps experienced during training
num_training_steps = len(train_data_loader) * epochs
print(num_training_steps)
#Linear preheating learning rate. In the first "warm up_contribution * num_training_steps", the learning rate increases linearly from 0 to learning_rate, and then the cosine decays to 0.
lr_scheduler = CosineDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
# AdamW optimizer
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
#Custom Focal Loss function
#criterion = MultiCEFocalLoss(class_num=14, alpha=(df_Info_data['Weight'].values.tolist()))
#Cross entropy loss function
criterion = paddle.nn.CrossEntropyLoss(weight=paddle.to_tensor(df_Info_data['Weight'].values.astype("float32")))
#criterion = paddle.nn.CrossEntropyLoss()
metric = paddle.metric.Accuracy() # accuracy evaluation index
11760
3.5 model training and evaluation
ps: during model training, judge whether the training parameters are appropriate and whether there is over fitting by observing the changes of parameters such as loss function and accuracy.
Input NVIDIA SMI command in the terminal or click the "performance monitoring" option at the bottom to check the occupation of video memory, and properly adjust the batch size to prevent suspension caused by insufficient video memory.
# Define model training verification evaluation function
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval loss: %.5f, accu: %.5f" % (np.mean(losses), accu)) # Evaluation effect on output validation set
model.train()
metric.reset()
return accu # Return accuracy
# Fixed random seeds facilitate the reproduction of results seed = 1024 random.seed(seed) np.random.seed(seed) paddle.seed(seed)
<paddle.fluid.core_avx.Generator at 0x7f02da321fb0>
# Model training:
import paddle.nn.functional as F
import matplotlib.pyplot as plt
#Save path of the model with the highest accuracy on the validation set
save_dir = "checkpoint"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
#Save path of the model after the end of the last Epoch
save_final_dir = "checkpoint_final"
if not os.path.exists(save_final_dir):
os.makedirs(save_final_dir)
pre_accu=0
accu=0
global_step = 0
#Record the Step and Epoch values when the effect is better
best_global_step = 0
best_epoch = 0
#Handle Epoch one by one
for epoch in range(1, epochs + 1):
losses = []
#Process Step by Step
for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
# print(len(logits[0]))
# print(len(labels[0]))
# print(logits)
# print(labels)
loss = criterion(logits, labels)
losses.append(loss.numpy())
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
#Count and output the results every 10 steps
if global_step % 10 == 0:
print("global step %d, epoch: %d, batch: %d, loss: %.5f, avgLoss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, np.mean(losses), acc))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if useTotalData == False:
#If all data sets (training set + verification set) are not used for training, the evaluation shall be carried out after a certain number of batches to avoid missing the best model in the middle
if global_step % 300 == 0:
accu = evaluate(model, criterion, metric, dev_data_loader)
if accu > pre_accu:
# Save better model parameters
save_param_path = os.path.join(save_dir, 'model_state.pdparams') # Save model parameters
paddle.save(model.state_dict(), save_param_path)
pre_accu=accu
#Record the Step and Epoch values when the effect is better
best_global_step = global_step
best_epoch = epoch
print("The best model is found in epoch: %d, batch: %d" % (best_epoch, best_global_step))
if useTotalData == False:
#If all data sets (training set + verification set) are not used for training, the verification set is evaluated at the end of each round
accu = evaluate(model, criterion, metric, dev_data_loader)
print(accu)
if accu > pre_accu:
#Save the model parameters with better effect than the previous round
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
pre_accu=accu
#Record the Step and Epoch values when the effect is better
best_global_step = global_step
best_epoch = epoch
print("The best model is found in epoch: %d, batch: %d" % (best_epoch, best_global_step))
else:#Save the model parameters of this round to avoid intermediate downtime
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_dir)
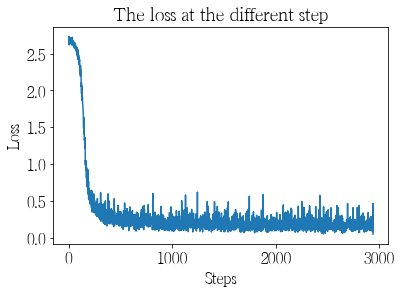
#Draw loss function curve
plt.figure()
#Curve title
plt.title("The loss at the different step")
#Curve X-axis and Y-axis names
plt.xlabel("Steps")
plt.ylabel("Loss")
plt.plot(losses)
plt.figure()
#Save the model after the last Epoch
save_final_param_path = os.path.join(save_final_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_final_param_path)
tokenizer.save_pretrained(save_final_dir)
The best model is found in epoch: 3, batch: 8400
<Figure size 432x288 with 0 Axes>
<Figure size 432x288 with 0 Axes>
<Figure size 432x288 with 0 Axes>
<Figure size 432x288 with 0 Axes>
# Load the model parameters of the round with the best effect on the verification set
import os
import paddle
params_path = 'checkpoint_final/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# Load model parameters
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
Loaded parameters from checkpoint_final/model_state.pdparams
# Test the score of the optimal model parameters on the verification set evaluate(model, criterion, metric, dev_data_loader)
eval loss: 0.06091, accu: 0.96970 0.9697
3.6 model prediction
# Define categories to classify
label_list = train.label.unique().tolist()
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}
print(label_map)
{0: 'science and technology', 1: 'Sports', 2: 'Current politics', 3: 'shares', 4: 'entertainment', 5: 'education', 6: 'Home Furnishing', 7: 'Finance and Economics', 8: 'house property', 9: 'Sociology', 10: 'game', 11: 'lottery', 12: 'constellation', 13: 'fashion'}
# Prediction function definition
def predict(model, data, tokenizer, label_map, batch_size=1):
examples = []
# Process the input data (list format) into a format acceptable to the model
for text in data:
input_ids, segment_ids = convert_example(
text,
tokenizer,
max_seq_length=128,
is_test=True)
examples.append((input_ids, segment_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input id
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment id
): fn(samples)
# Divide the dataset into multiple batches and save them in batches
batches = []
one_batch = []
#Process samples one by one
for example in examples:
#Add each sample to one_ In batch, if the number increases to batch size, it will be added to batches as one batch
one_batch.append(example)
if len(one_batch) == batch_size:
batches.append(one_batch)
one_batch = []
if one_batch:
#Process last one_ Special case where the number of elements in batch is less than batch size
batches.append(one_batch)
results = []
model.eval()
#Process data batch by batch
for batch in batches:
input_ids, segment_ids = batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
segment_ids = paddle.to_tensor(segment_ids)
logits = model(input_ids, segment_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results # Return forecast results
# Define the preprocessing function for data, and specify the list format for model input
def preprocess_prediction_data(data):
examples = []
for text_a in data:
examples.append({"text_a": text_a})
return examples
# Store the prediction results in list format as txt file, and submit the format requirements: one category per line
def write_results(labels, file_path):
with open(file_path, "w", encoding="utf8") as f:
f.writelines("\n".join(labels))
# Read the test set file to predict
test = pd.read_csv('./test.csv',sep='\t')
# Format the test set data
test_data = list(test.text_a)
test_example = preprocess_prediction_data(test_data)
# Predict the test set results = predict(model, test_example, tokenizer, label_map, batch_size=16)
#Save the prediction results as txt files that meet the format requirements write_results(results, "./result.txt") #zip file !zip 'submission.zip' 'result.txt' !cp -r submission.zip /home/aistudio/
IV Integrated learning
The voting method is used to fuse the results of multiple models into a single result to eliminate inconsistency
According to the results of the seven models fused with equal weight, the score of the submitted results is 0.89494
The results of 7 models are fused with weights 158, 146, 132, 112, 125, 114 and 78, and the score of the submitted results is 0.89527
#When calculating the result correlation, the label column can only be ID, so you need to convert the original name to ID
#Establish a mapping table from classification label to ID
label_ID_map = {Val:ID for ID,Val in enumerate(label_list)}
print(label_ID_map)
{'science and technology': 0, 'Sports': 1, 'Current politics': 2, 'shares': 3, 'entertainment': 4, 'education': 5, 'Home Furnishing': 6, 'Finance and Economics': 7, 'house property': 8, 'Sociology': 9, 'game': 10, 'lottery': 11, 'constellation': 12, 'fashion': 13}
#Since each line of the prediction result file has only label, it needs to be preprocessed to generate several files
#predfile: save the file generated by the model prediction results, with only label column
#label_ID_map: the mapping table from classification label to ID, weight: the weight of the result file
#resultfile: the result file after adding the predfile to the column ('id','label ')
#resultIDfile: the result file after converting the classification label of resultfile into ID
def preprocess_prediction_file(predfile, label_ID_map, weight, resultfile, resultIDfile):
dftab = pd.read_table(predfile,header=None)
dftab.columns = ['label']
#Add id index to data
lst_ID = []
for i in range(1,len(dftab) + 1):
lst_ID.append(i)
id = pd.DataFrame(lst_ID)
dftab['id'] = id
#DataFrame consisting of ID and Label
dftab = dftab[['id','label']]
#Save results
dftab.to_csv(resultfile, index=False)
#Result file with weighted name
resultWeightfile = "_w" + str(int(weight)) + "_" + resultfile
dftab.to_csv(resultWeightfile, index=False)
#Add tag ID to data
lst_LabelID = []
for i in range(1,len(dftab) + 1):
lst_LabelID.append(label_ID_map[dftab['label'][i-1]])
labelID = pd.DataFrame(lst_LabelID)
dftab['labelID'] = labelID
#DataFrame consisting of ID and LabelID
dfIDtab = dftab[['id','labelID']]
#Save results
dfIDtab.to_csv(resultIDfile, index=False)
%cd /home/aistudio/merge_result/ #Clear existing csv files !rm *.csv
/home/aistudio/merge_result rm: cannot remove '*.csv': No such file or directory
#Preprocess the model prediction result file
preprocess_prediction_file("./result89.08.txt", label_ID_map, 158, "method1.csv", "method1_ID.csv")
preprocess_prediction_file("./result88.96.txt", label_ID_map, 146, "method2.csv", "method2_ID.csv")
preprocess_prediction_file("./result88.82.txt", label_ID_map, 132, "method3.csv", "method3_ID.csv")
preprocess_prediction_file("./result88.62.txt", label_ID_map, 112, "method4.csv", "method4_ID.csv")
preprocess_prediction_file("./result88.75.txt", label_ID_map, 125, "method5.csv", "method5_ID.csv")
preprocess_prediction_file("./result88.64.txt", label_ID_map, 114, "method6.csv", "method6_ID.csv")
preprocess_prediction_file("./result88.28.txt", label_ID_map, 78, "method7.csv", "method7_ID.csv")
# Correlation of calculation results !python correlations.py "./method1_ID.csv" "./method2_ID.csv"
Finding correlation between: ./method1_ID.csv and ./method2_ID.csv Column to be measured: labelID Pearson's correlation score: 0.9269307860693886 Kendall's correlation score: 0.9219420409220379 Spearman's correlation score: 0.9367103330656568
# Equal weight Voting Fusion !python kaggle_vote.py "./method?.csv" "./merge.csv" # Weighted voting fusion !python kaggle_vote.py "./_w*.csv" "./merge_weight.csv" "weighted"
parsing: ./method3.csv parsing: ./method2.csv parsing: ./method1.csv parsing: ./method5.csv parsing: ./method7.csv parsing: ./method4.csv parsing: ./method6.csv wrote to ./merge.csv parsing: ./_w78_method7.csv Using weight: 78 parsing: ./_w146_method2.csv Using weight: 146 parsing: ./_w112_method4.csv Using weight: 112 parsing: ./_w158_method1.csv Using weight: 158 parsing: ./_w125_method5.csv Using weight: 125 parsing: ./_w132_method3.csv Using weight: 132 parsing: ./_w114_method6.csv Using weight: 114 wrote to ./merge_weight.csv
# Because the result of fusion does not meet the format requirements, the following simple format processing is also required
# df1 = pd.read_csv('./_w4_method1.csv')
# df2 = pd.read_csv('./merge_weight.csv')
df1 = pd.read_csv('./method1.csv')
df2 = pd.read_csv('./merge.csv')
# Filling the filtered data into the new table mainly solves the problem of id disorder
df1['label'] = df1['id'].map(df2.set_index('id')['label'])
df1 = df1['label']
# Save forecast result file
df1.to_csv('result.txt',index=False,header=None)
# Compress the result file into a zip file
!zip 'result.zip' 'result.txt'
adding: result.txt (deflated 89%)
V Direct push learning
Using direct push learning, the high-quality test set is transformed into training set to improve the number of effective samples
According to the pseudo tags generated by direct push learning, after two training, the scores of the submitted results are 90.01 and 90.06447.
#Since each line of the prediction result file has only label, you need to add ID index
#predfile: save the file generated by the model prediction results, with only label column
#resultfile: the result file after adding the predfile to the column ('id','label ')
def addIDIndex_prediction_file(predfile, resultfile):
dftab = pd.read_table(predfile,header=None)
dftab.columns = ['label']
#Add id index to data
lst_ID = []
for i in range(1,len(dftab) + 1):
lst_ID.append(i)
id = pd.DataFrame(lst_ID)
dftab['id'] = id
#DataFrame consisting of ID and Label
dftab = dftab[['id','label']]
#Save results
dftab.to_csv(resultfile, index=False)
#Convert the file composed of columns ('id','label ') into KV table ('id':'label ')
def iDLabelFile2KVTable(iDLabelFile):
result_file = open(iDLabelFile,'r',encoding='utf-8')
result_reader = csv.reader(result_file)
KVTab = {}
#Convert line by line
for rows in result_reader:
KVTab[rows[0]] = rows[1].encode('utf-8').decode('utf-8')
return KVTab
%cd /home/aistudio/fake_data/ #Clear existing csv files !rm *.csv
/home/aistudio/fake_data rm: cannot remove '*.csv': No such file or directory
#Preprocess the model prediction result file
addIDIndex_prediction_file("./result89.08.txt", "method1.csv")
addIDIndex_prediction_file("./result88.96.txt", "method2.csv")
addIDIndex_prediction_file("./result88.82.txt", "method3.csv")
addIDIndex_prediction_file("./result88.62.txt", "method4.csv")
addIDIndex_prediction_file("./result88.75.txt", "method5.csv")
addIDIndex_prediction_file("./result88.64.txt", "method6.csv")
addIDIndex_prediction_file("./result88.28.txt", "method7.csv")
import csv
import numpy as np
import pandas as pd
#Convert the file composed of columns ('id','label ') into KV table ('id':'label ')
f1 = iDLabelFile2KVTable('method1.csv')
f2 = iDLabelFile2KVTable('method2.csv')
f3 = iDLabelFile2KVTable('method3.csv')
f4 = iDLabelFile2KVTable('method1.csv')
f5 = iDLabelFile2KVTable('method2.csv')
f6 = iDLabelFile2KVTable('method3.csv')
f7 = iDLabelFile2KVTable('method3.csv')
# Select the parts with the same prediction results of multiple models
x1 = set(f1.items()).intersection(set(f2.items())).intersection(set(f3.items()))
x2 = set(f4.items()).intersection(set(f5.items())).intersection(set(f6.items()))
x3 = set(f7.items())
x = x1.intersection(x2.intersection(x3))
x = pd.DataFrame(x)
x.columns = ["id", "label"]
# print(x)
df1 = pd.read_csv('method1.csv')
# print(df1['label'])
x[~df1['label'].isin(['label'])]
# Splice text_ a. Label is label data
t1 = x
t2 = pd.read_table('./test.txt',header=None)
t2.columns = ["text_a"]
# Add id index
list = []
for i in range(1,83600):
list.append(i)
id = pd.DataFrame(list)
t2['id'] = id
t2 = t2[['id','text_a']]
t1['id'] = t1['id'].astype(str)
t1['label'] = t1['label'].astype(str)
t2['id'] = t2['id'].astype(str)
t2['text_a'] = t2['text_a'].astype(str)
t3 = pd.merge(t1, t2[['id', 'text_a']], on='id', how='left')
t3 = t3[['text_a','label']]
)
x = x1.intersection(x2.intersection(x3))
x = pd.DataFrame(x)
x.columns = ["id", "label"]
# print(x)
df1 = pd.read_csv('method1.csv')
# print(df1['label'])
x[~df1['label'].isin(['label'])]
# Splice text_ a. Label is label data
t1 = x
t2 = pd.read_table('./test.txt',header=None)
t2.columns = ["text_a"]
# Add id index
list = []
for i in range(1,83600):
list.append(i)
id = pd.DataFrame(list)
t2['id'] = id
t2 = t2[['id','text_a']]
t1['id'] = t1['id'].astype(str)
t1['label'] = t1['label'].astype(str)
t2['id'] = t2['id'].astype(str)
t2['text_a'] = t2['text_a'].astype(str)
t3 = pd.merge(t1, t2[['id', 'text_a']], on='id', how='left')
t3 = t3[['text_a','label']]
t3.to_csv('fakeData1.csv',index=False,sep=',')
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
Please click here View the basic usage of this environment
Please click here for more detailed instructions.