1, Introduction
Speaking of multiple data sources, they are generally used in the following two scenarios:
- First, the business is special, and multiple libraries need to be connected. Class representatives once migrated new and old systems from SQL server to MySQL, involving some business operations. Common data extraction tools can not meet business needs, so they can only do it with their bare hands.
- The second is the separation of database reading and writing. Under the database master-slave architecture, the write operation falls to the master database, and the read operation is handed over to the slave database to share the pressure of the master database.
There are many schemes for the implementation of multiple data sources, from simple to complex.
This article will take SpringBoot(2.5.X)+Mybatis+H2 as an example to demonstrate a simple and reliable implementation of multiple data sources.
After reading this article, you will gain:
- How does SpringBoot automatically configure data sources
- How is Mybatis automatically configured in SpringBoot
- How to use transactions under multiple data sources
- Get a reliable multi data source sample project
2, Automatically configured data sources
The automatic configuration of SpringBoot helps us do almost all the work. We only need to introduce relevant dependencies to complete all the work
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.0</version>
</dependency>When H2 database is introduced into dependency, datasourceautoconfiguration Java will automatically configure a default data source: HikariDataSource. Paste the source code first:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ DataSource.class, EmbeddedDatabaseType.class })
@ConditionalOnMissingBean(type = "io.r2dbc.spi.ConnectionFactory")
// 1. Load data source configuration
@EnableConfigurationProperties(DataSourceProperties.class)
@Import({ DataSourcePoolMetadataProvidersConfiguration.class,
DataSourceInitializationConfiguration.InitializationSpecificCredentialsDataSourceInitializationConfiguration.class,
DataSourceInitializationConfiguration.SharedCredentialsDataSourceInitializationConfiguration.class })
public class DataSourceAutoConfiguration {
@Configuration(proxyBeanMethods = false)
// Embedded database dependency conditions exist by default, so HikariDataSource will not take effect. See below for details
@Conditional(EmbeddedDatabaseCondition.class)
@ConditionalOnMissingBean({ DataSource.class, XADataSource.class })
@Import(EmbeddedDataSourceConfiguration.class)
protected static class EmbeddedDatabaseConfiguration {
}
@Configuration(proxyBeanMethods = false)
@Conditional(PooledDataSourceCondition.class)
@ConditionalOnMissingBean({ DataSource.class, XADataSource.class })
@Import({ DataSourceConfiguration.Hikari.class, DataSourceConfiguration.Tomcat.class,
DataSourceConfiguration.Dbcp2.class, DataSourceConfiguration.OracleUcp.class,
DataSourceConfiguration.Generic.class, DataSourceJmxConfiguration.class })
protected static class PooledDataSourceConfiguration {
//2. Initialize data sources with pooling: Hikari, Tomcat, Dbcp2, etc
}
// Omit others
}Its principle is as follows:
1. Load data source configuration
Load the configuration information through @ EnableConfigurationProperties(DataSourceProperties.class) and observe the class definition of DataSourceProperties:
@ConfigurationProperties(prefix = "spring.datasource") public class DataSourceProperties implements BeanClassLoaderAware, InitializingBean
Two messages can be obtained:
- The configured prefix is spring datasource;
- The InitializingBean interface is implemented with initialization operation.
In fact, the default embedded database connection is initialized according to the user configuration:
@Override
public void afterPropertiesSet() throws Exception {
if (this.embeddedDatabaseConnection == null) {
this.embeddedDatabaseConnection = EmbeddedDatabaseConnection.get(this.classLoader);
}
}Via embeddeddatabaseconnection The get method traverses the built-in database enumeration to find the embedded database connection most suitable for the current environment. Since H2 is introduced, the return value is also the enumeration information of H2 database:
public static EmbeddedDatabaseConnection get(ClassLoader classLoader) {
for (EmbeddedDatabaseConnection candidate : EmbeddedDatabaseConnection.values()) {
if (candidate != NONE && ClassUtils.isPresent(candidate.getDriverClassName(), classLoader)) {
return candidate;
}
}
return NONE;
}This is the idea of SpringBoot's convention over configuration. SpringBoot found that we introduced H2 database and immediately prepared the default connection information.
2. Create data source
By default, @ Import(EmbeddedDataSourceConfiguration.class) will not be loaded because SpringBoot has built-in pooled data source HikariDataSource. Only one HikariDataSource will be initialized because @ Conditional(EmbeddedDatabaseCondition.class) is not valid in the current environment. The comments in the source code have explained this:
/**
* {@link Condition} to detect when an embedded {@link DataSource} type can be used.
* If a pooled {@link DataSource} is available, it will always be preferred to an
* {@code EmbeddedDatabase}.
* If a pooled DataSource exists, it will take precedence over the EmbeddedDatabase
*/
static class EmbeddedDatabaseCondition extends SpringBootCondition {
// Omit source code
}Therefore, the initialization of the default data source is realized by: @ import ({datasourceconfiguration. Hikari. Class, / / omitting other}. The code is also relatively simple:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(HikariDataSource.class)
@ConditionalOnMissingBean(DataSource.class)
@ConditionalOnProperty(name = "spring.datasource.type", havingValue = "com.zaxxer.hikari.HikariDataSource",
matchIfMissing = true)
static class Hikari {
@Bean
@ConfigurationProperties(prefix = "spring.datasource.hikari")
HikariDataSource dataSource(DataSourceProperties properties) {
//Create a HikariDataSource instance
HikariDataSource dataSource = createDataSource(properties, HikariDataSource.class);
if (StringUtils.hasText(properties.getName())) {
dataSource.setPoolName(properties.getName());
}
return dataSource;
}
}protected static <T> T createDataSource(DataSourceProperties properties, Class<? extends DataSource> type) {
// The default connection information will be used in initializedata sourcebuilder
return (T) properties.initializeDataSourceBuilder().type(type).build();
}public DataSourceBuilder<?> initializeDataSourceBuilder() {
return DataSourceBuilder.create(getClassLoader()).type(getType()).driverClassName(determineDriverClassName())
.url(determineUrl()).username(determineUsername()).password(determinePassword());
}The use of default connection information is the same idea: give priority to the configuration specified by the user. If the user does not write, use the default. Take determineDriverClassName() as an example:
public String determineDriverClassName() {
// Returns if driverClassName is configured
if (StringUtils.hasText(this.driverClassName)) {
Assert.state(driverClassIsLoadable(), () -> "Cannot load driver class: " + this.driverClassName);
return this.driverClassName;
}
String driverClassName = null;
// If the url is configured, the driverClassName is derived from the url
if (StringUtils.hasText(this.url)) {
driverClassName = DatabaseDriver.fromJdbcUrl(this.url).getDriverClassName();
}
// If not, fill it with the enumeration information obtained during the initialization of the data source configuration class
if (!StringUtils.hasText(driverClassName)) {
driverClassName = this.embeddedDatabaseConnection.getDriverClassName();
}
if (!StringUtils.hasText(driverClassName)) {
throw new DataSourceBeanCreationException("Failed to determine a suitable driver class", this,
this.embeddedDatabaseConnection);
}
return driverClassName;
}Other principles such as determineUrl(), determineUsername(), determinePassword() are the same and will not be repeated.
At this point, the default HikariDataSource is automatically configured!
Next, let's take a look at how Mybatis is automatically configured in spring boot
3, Auto configure Mybatis
To use Mybatis in Spring, you need at least a SqlSessionFactory and a mapper interface. Therefore, Mybatis Spring boot starter does these things for us:
- Automatically discover existing DataSource
- Pass DataSource to SqlSessionFactoryBean to create and register a SqlSessionFactory instance
- Use sqlSessionFactory to create and register SqlSessionTemplate instances
- Automatically scan mapper s, link them with SqlSessionTemplate and register them in the Spring container for injection by other beans
Combined with the source code to deepen the impression:
public class MybatisAutoConfiguration implements InitializingBean {
@Bean
@ConditionalOnMissingBean
//1. Auto discover existing ` DataSource`
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean factory = new SqlSessionFactoryBean();
//2. Pass DataSource to SqlSessionFactoryBean to create and register a SqlSessionFactory instance
factory.setDataSource(dataSource);
// Omit other
return factory.getObject();
}
@Bean
@ConditionalOnMissingBean
//3. Use sqlSessionFactory to create and register SqlSessionTemplate instances
public SqlSessionTemplate sqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
ExecutorType executorType = this.properties.getExecutorType();
if (executorType != null) {
return new SqlSessionTemplate(sqlSessionFactory, executorType);
} else {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
/**
* This will just scan the same base package as Spring Boot does. If you want more power, you can explicitly use
* {@link org.mybatis.spring.annotation.MapperScan} but this will get typed mappers working correctly, out-of-the-box,
* similar to using Spring Data JPA repositories.
*/
//4. Automatically scan 'mapper s', link them with' SqlSessionTemplate 'and register them in the' Spring 'container for injection by other' beans'
public static class AutoConfiguredMapperScannerRegistrar implements BeanFactoryAware, ImportBeanDefinitionRegistrar {
// Omit other
}
}One picture is better than a thousand words. Its essence is to inject layer by layer:
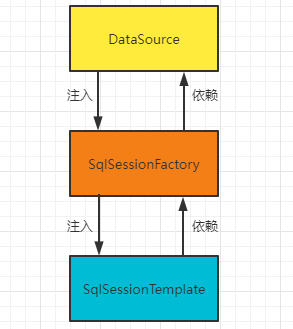
4, From single to many
With the knowledge reserve of the second and third summaries, there is the theoretical basis for creating multiple data sources: two sets of DataSource and two sets of layer by layer injection, as shown in the figure: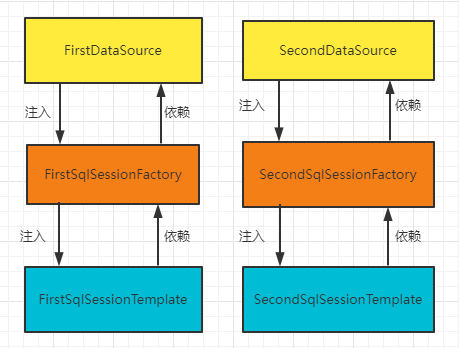
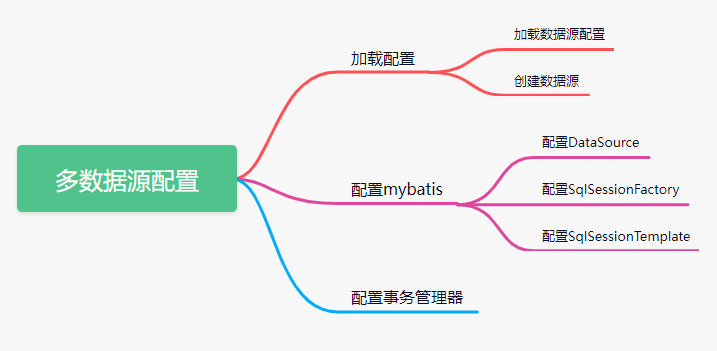
Next, we will copy the routine of automatic configuration of single data source and configure multiple data sources in the following order:
First, design the configuration information. For a single data source, the configuration prefix is spring In order to support multiple datasources, we add another layer later, yml as follows:
spring:
datasource:
first:
driver-class-name: org.h2.Driver
jdbc-url: jdbc:h2:mem:db1
username: sa
password:
second:
driver-class-name: org.h2.Driver
jdbc-url: jdbc:h2:mem:db2
username: sa
password:Configuration of first data source
/**
* @description:
* @author:Java Class representative
* @createTime:2021/11/3 23:13
*/
@Configuration
//Configure the scanning location of the mapper and specify the corresponding sqlSessionTemplate
@MapperScan(basePackages = "top.javahelper.multidatasources.mapper.first", sqlSessionTemplateRef = "firstSqlSessionTemplate")
public class FirstDataSourceConfig {
@Bean
@Primary
// Read configuration and create data source
@ConfigurationProperties(prefix = "spring.datasource.first")
public DataSource firstDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
@Primary
// Create SqlSessionFactory
public SqlSessionFactory firstSqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
// Set scan path for xml
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mybatis/first/*.xml"));
bean.setTypeAliasesPackage("top.javahelper.multidatasources.entity");
org.apache.ibatis.session.Configuration config = new org.apache.ibatis.session.Configuration();
config.setMapUnderscoreToCamelCase(true);
bean.setConfiguration(config);
return bean.getObject();
}
@Bean
@Primary
// Create SqlSessionTemplate
public SqlSessionTemplate firstSqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
@Bean
@Primary
// Create DataSourceTransactionManager for transaction management
public DataSourceTransactionManager firstTransactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
}Here @ Primary is added to each @ Bean to make it the default Bean. When @ MapperScan is used, specify SqlSessionTemplate to associate mapper with firstSqlSessionTemplate.
Tips:
Finally, a DataSourceTransactionManager is created for the data source for transaction management. When using a transaction in a multi data source scenario, @ Transactional(transactionManager = "firstTransactionManager") is used to specify which transaction management is used for the transaction.
So far, the first data source is configured, and the second data source is also configured for these items. Because the configured beans are of the same type, you need to use @ Qualifier to limit the loaded beans, for example:
@Bean
// Create SqlSessionTemplate
public SqlSessionTemplate secondSqlSessionTemplate(@Qualifier("secondSqlSessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}For the complete code, you can view the GitHub represented by the class
5, Transactions under multiple data sources
Spring provides us with simple and easy-to-use declarative transactions, so that we can focus more on business development, but it is not easy to use them well. This article only focuses on multiple data sources. Please stamp for supplementary courses on transactions: How should Spring declarative transactions be learned?
As mentioned in the previous tips, when opening a declarative transaction, because there are multiple transaction managers, it is necessary to display the specified transaction manager, such as the following example:
// If the parameter transactionManager is not explicitly specified, the firstTransactionManager set to Primary will be used
// The following code will only roll back firstusermapper insert, secondUserMapper.insert(user2); It will be inserted normally
@Transactional(rollbackFor = Throwable.class,transactionManager = "firstTransactionManager")
public void insertTwoDBWithTX(String name) {
User user = new User();
user.setName(name);
// RollBACK
firstUserMapper.insert(user);
// No rollback
secondUserMapper.insert(user);
// Actively trigger rollback
int i = 1/0;
}By default, the transaction uses firstTransactionManager as the transaction manager and only controls the transaction of FristDataSource. Therefore, when we manually throw an exception internally to roll back the transaction, firstusermapper insert(user); Rollback, secondusermapper insert(user); No rollback.
The framework code has been uploaded, and the partners can design use case verification according to their own ideas.
6, Review
So far, the multi data source example of SpringBoot+Mybatis+H2 has been demonstrated. This should be the most basic multi data source configuration. In fact, it is rarely used online, unless it is an extremely simple one-time business.
Because the disadvantages of this method are very obvious: the code is too intrusive! The number of data sources depends on the number of components to be implemented, and the amount of code has doubled.
Writing this case is more about summarizing and reviewing the basic knowledge of SpringBoot's automatic configuration, annotated declared beans, Spring declarative transactions and so on, so as to pave the way for the advancement of multiple data sources later.
Spring officially provides us with an AbstractRoutingDataSource class to switch multiple data sources by routing the DataSource. This is also the bottom support of most lightweight multi data source implementations.
Attention class representative, the next presentation is based on AbstractRoutingDataSource+AOP multi data source implementation!