1, Introduction
1.1 what is a clickhouse
ClickHouse is a columnar database management system (DBMS) for on-line analysis (OLAP).
In the traditional line database system, data is stored in the following order: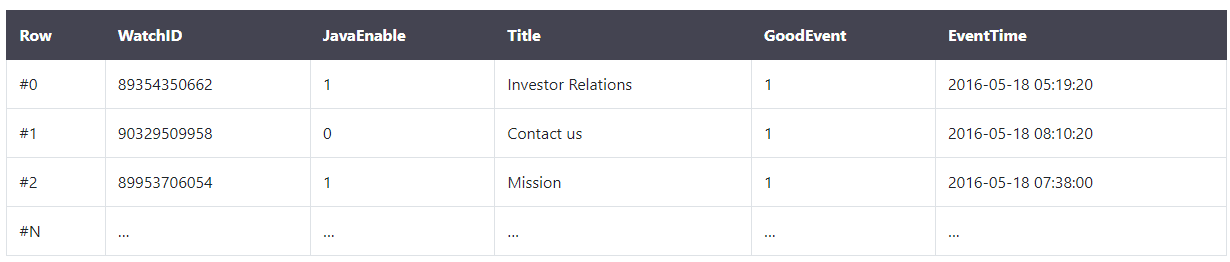
Data in the same row is always physically stored together.
Common line database systems include MySQL, Postgres and MS SQL Server.
In the column database system, data is stored in the following order:
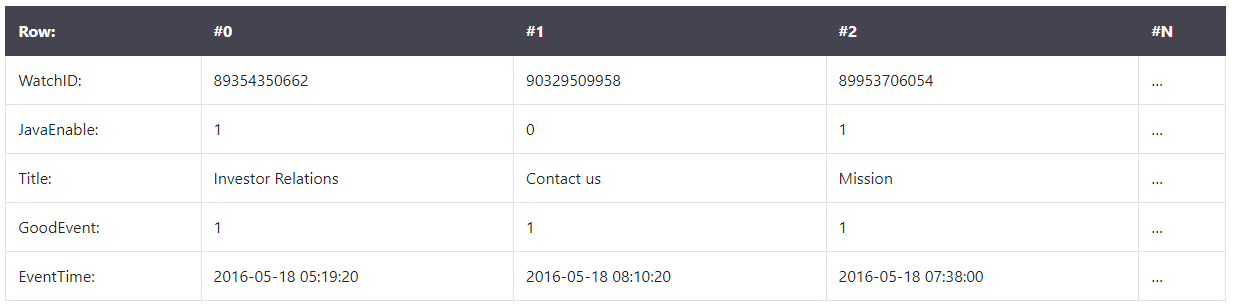
These examples show only the order in which the data is arranged. Values from different columns are stored separately, and data from the same column is stored together.
Different data storage methods are applicable to different business scenarios. Data access scenarios include: what kind of query is performed, how often and the proportion of various queries; How much data is read by each type of query (row, column and byte); The relationship between reading data and updating; The size of the dataset used and how to use the local dataset; Whether transactions are used and how they are isolated; Data replication mechanism and data integrity requirements; Each type of query requires latency and throughput, etc.
The higher the system load, the more important it is to customize according to the use scenario, and the more refined the customization will become. No system can apply to all different business scenarios at the same time. If the system is suitable for a wide range of scenarios and takes into account all scenarios under high load, you will have to make a choice. Balance or efficiency?
2, Key features of OLAP scenarios
- Most are read requests
- The data is updated in large batches (> 1000 rows) rather than single lines; Or no updates at all.
- Data that has been added to the database cannot be modified.
- For reads, a considerable number of rows are extracted from the database, but only a small portion of the columns are extracted.
- Wide table, that is, each table contains a large number of columns
- Relatively few queries (typically hundreds or fewer queries per second per server)
- For simple queries, a delay of about 50 milliseconds is allowed
- The data in the column is relatively small: numbers and short strings (for example, 60 bytes per URL)
- Processing a single query requires high throughput (billions of rows per second per server)
- Transactions are not required
- Low requirements for data consistency
- Each query has a large table. Except him, the others are very small.
- The query result is significantly smaller than the source data. In other words, the data is filtered or aggregated, so the results are suitable for the RAM of a single server
It is easy to see that OLAP scenarios are very different from other common business scenarios (for example, OLTP or K/V). Therefore, it is not a perfect solution to use OLTP or key value databases to efficiently process and analyze query scenarios. For example, using OLAP database to process analysis requests is usually better than using MongoDB or Redis to process analysis requests.
Why column database is more suitable for OLAP scenario
The columnar database is more suitable for OLAP scenarios (for most queries, the processing speed is increased by at least 100 times). The reasons are explained in detail below (pictures are more conducive to intuitive understanding):
line
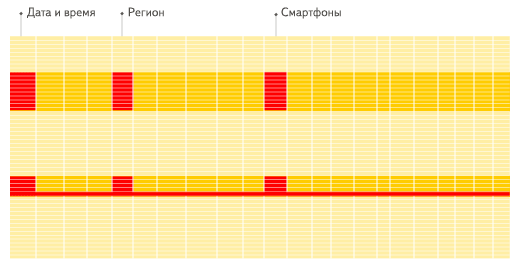
Scan all rows to find corresponding columns
Determinant
Find the corresponding column
- Input / output
For analysis queries, you usually only need to read a small part of the table columns. In a column database, you can read only the data you need. For example, if you only need to read 5 out of 100 columns, this will help you reduce I/O consumption by at least 20 times. - Since data is always packaged for batch reading, compression is very easy. At the same time, the data is stored separately by column, which is easier to compress. This further reduces the volume of I/O.
- Due to the reduction of I/O, this will help more data to be cached by the system.
For example, to query « count the number of records of each advertising platform » you need to read the column « advertising platform ID », which needs 1 byte to store without compression. If most of the traffic is not from the advertising platform, this column can be compressed at least ten times the compression rate. When using fast compression algorithm, its decompression speed is at least one billion bytes (uncompressed data) per second. In other words, this query can be processed on a single server at a rate of about billions of rows per second. This is actually the speed of the current implementation.
3, MergeTree collection
The table engine of MergeTree series is the core of ClickHouse data storage function. They provide most functions for elastic and high-performance data retrieval: columnar storage, custom partition, sparse primary index, auxiliary data skipping index, etc.
The basic MergeTree table engine can be considered as the default table engine for a single node ClickHouse instance because it is common and practical in various use cases.
ReplicatedMergeTree is a must for production use because it adds high availability to all the functions of the regular MergeTree engine. An additional benefit is automatic data deduplication during data extraction, so the software can safely retry if there is a network problem during insertion.
All other engines in the MergeTree family add additional functionality for certain use cases. Usually, it is implemented as other data operations in the background.
The main disadvantage of MergeTree engines is that they are heavy. Therefore, the typical pattern is not too much. If you need many small tables (for example, for temporary data)
3.1 MergeTree
3.1.1 basic grammar
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2)
ENGINE = MergeTree()ORDER BY expr[PARTITION BY expr][PRIMARY KEY expr][SAMPLE BY expr][TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...][SETTINGS name=value, ...]
3.1.2 parameter interpretation
Engine - name and parameters of the engine. ENGINE = MergeTree(). The mergetree engine has no parameters.
ORDER BY - sort key
Column name or tuple of any expression. Example: ORDER BY (CounterID, EventDate).
If the PRIMARY KEY clause does not explicitly define a PRIMARY KEY, ClickHouse uses the sort key as the PRIMARY KEY.
ORDER BY tuple() use syntax if sorting is not required.
PARTITION BY - partition key. Optional.
To partition by month, use the toyymm (date_column) expression, where Date_ Column is a column of Date type. The partition name here has the format "YYYYMM".
PRIMARY KEY - PRIMARY KEY (different from sort key). Optional.
By default, the PRIMARY KEY is the same as the sort key (specified by the ORDER BY clause). Therefore, in most cases, you do not need to specify a separate PRIMARY KEY clause.
SAMPLE BY - expression for sampling. Optional.
If you use a sampling expression, the primary key must contain it. Example: SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID)).
TTL - a list of rules that specify the storage duration of rows and define the logic for automatic movement of parts between disks and volumes. Optional.
The result must have a Date or DateTime column. Example:
TTL date + INTERVAL 1 DAY
The type of rule DELETE|TO DISK 'xxx' |TO VOLUME 'xxx' specifies the action to be performed on the part when the expression (reaching the current time) is satisfied: DELETE the expired lines, move the part (if the expression is satisfied for all lines in the part) to the specified disk (TO DISK 'xxx') or TO VOLUME (TO VOLUME 'xxx'). The default type of rule is DELETE. You can specify a list of multiple rules, but there can be at most one DELETE rule.
SETTINGS - additional parameters that control the behavior of MergeTree (optional):
1. index_granularity—Maximum number of data rows between index tags. Default: 8192. See data store. 2. index_granularity_bytes—The maximum size (in bytes) of the data granularity. Default: 10 Mb. To limit the particle size by the number of rows only, set to 0 (not recommended). See data storage. 3. enable_mixed_granularity_parts—Enable or disable transitions to pass through index_granularity_bytes Setting controls particle size. In version 19.11 Before, only index_granularity Settings to limit particle size. index_granularity_bytes From having large lines (tens and hundreds) MB)This setting improves when data is selected in the table ClickHouse Performance. If your table has large rows, you can enable this setting for the table to improve performance SELECT Query efficiency. 4. use_minimalistic_part_header_in_zookeeper— ZooKeeper Storage method of data part header in. If use_minimalistic_part_header_in_zookeeper=1,be ZooKeeper Less data is stored. For more information, see the setting instructions in server configuration parameters. 5. min_merge_bytes_to_use_direct_io—Use direct access to storage disks I / O The minimum amount of merge operation data required to access. When merging data parts, ClickHouse Calculate the total storage of all data to be consolidated. If the volume exceeds 6. min_merge_bytes_to_use_direct_io Bytes, ClickHouse Will use direct I / O Interface( O_DIRECT Option) reads the data and writes the data to the storage disk. If yes min_merge_bytes_to_use_direct_io = 0,Then directly I / O Disabled. Default: 10 * 1024 * 1024 * 1024 Bytes. 6. merge_with_ttl_timeout—Repetition and TTL Minimum delay (in seconds) before merging. Default: 86400 (1 day). 7. write_final_mark—Enables or disables writing the final index mark at the end of the data section (after the last byte). Default: 1.Don't close it. 8. merge_max_bloCK_size—The maximum number of rows in a block for a merge operation. Default: 8192 9. storage_policy—Storage policy. See using multiple block devices for data storage. 10. min_bytes_for_wide_part,min_rows_for_wide_part—Can be Wide The smallest byte in the data portion stored in the format/Number of rows. You can set one of these settings, all or all. See data store.
3.1.3 construction example
Build table create table tb_merge_tree( id Int8 , name String , ctime Date ) engine=MergeTree() order by id partition by name ; insert data insert into tb_merge_tree values (1,'hng','2020-08-07'),(4,'hng','2020-08-07'),(3,'ada','2020-08-07'),(2,'ada','2020-08-07') ;
The specified partition field is name
The specified sort field is id
The inserted data of each batch is partitioned as a basic unit, and the data in the area is sorted according to the specified fields
Enter a partition directory
4, clickhouse optimization logic
4.1 zoning during table creation
The partition granularity is determined according to the business characteristics and should not be too coarse or too fine. Generally, partition by day can also be specified as tuple(); taking 100 million data in a single table as an example, it is best to control the partition size at 10-30.
4.2 when creating a table, use the fields with high query frequency to create an index
The index column in the clickhouse is a sort column, which is specified by order by. Generally, the attributes often used as filter conditions in query criteria are included; it can be a single dimension or a combined dimension index; it usually needs to meet the principle of high base column first and high query frequency first; and the index column with a particularly large base is not suitable for index columns, such as the userid word of the user table Segment; generally, it is the best if the filtered data is within one million.
4.3 multi table Association
-
When multi table association is needed, filter the data of the associated table before de associating
-
When multiple tables are associated queried and the queried data is only from one table, consider using the IN operation instead of the JOIN.
select a.* from a where a.uid in (select uid from b) # Don't write select a.* from a left join b on a.uid=b.uid
-
When joining multiple tables, the principle of small tables on the right should be met. When the right table is associated, it is loaded into memory and compared with the left table.
-
clickhouse will not actively initiate predicate push down during join query, and each sub query needs to complete the filtering operation in advance. It should be noted that whether to actively execute predicate push down has a great impact on performance [this problem no longer exists in the new version, but it should be noted that there are still performance differences due to different predicate positions].
-
Create some businesses requiring association analysis into a dictionary table for join operation. The premise is that the dictionary table is not easy to be too large because the dictionary table will reside in memory.
4.4 query optimization
- Use the where keyword instead of the where keyword; when the query columns are significantly more than the filter columns, using the where keyword can ten times improve the query performance
# Where will automatically optimize the data reading method in the filtering phase and reduce io operations select * from work_basic_model where product='tracker_view' and ( id='eDf8fZky' or code='eDf8fZky' ) #Replace where keyword select * from work_basic_model prewhere product='tracker_view' and ( id='eDf8fZky' or code='eDf8fZky' )
- Data sampling can greatly improve the performance of data analysis by using operation
SELECT
Title,
count() * 10 AS PageViews
FROM hits_distributed
SAMPLE 0.1 #Represents 10% of the sampled data, or the specific number of pieces
WHERE
CounterID = 34
GROUP BY Title
ORDER BY PageViews DESC LIMIT 1000
-
The sampling modifier is valid only in the mergetree engine table, and the sampling policy needs to be specified when creating the table;
-
When the amount of data is too large, the select * operation should be avoided. The query performance will change linearly with the size and number of fields; the fewer fields, the less io resources will be consumed and the higher the performance will be.
-
For order by queries on more than ten million datasets, the where condition and limit statement should be used together
-
If it is not necessary, do not build virtual columns on the result set. Virtual columns consume resources and waste performance. You can consider processing at the front end or constructing actual fields in the table for additional storage.
-
Using uniqCombined instead of distinct can improve the performance by more than 10 times. The underlying layer of uniqCombined is implemented by a hyperlog algorithm. If it can receive about 2% of the data error, it can directly use this de duplication method to improve the query performance.
-
For some determined data models, the statistical indicators can be constructed through materialized view, which can avoid repeated calculation during data query; the materialized view will be updated when new data is inserted.
# Pre calculate the user download volume in advance through the materialized view
CREATE MATERIALIZED VIEW download_hour_mv
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(hour) ORDER BY (userid, hour)
AS SELECT
toStartOfHour(when) AS hour,
userid,
count() as downloads,
sum(bytes) AS bytes
FROM download WHERE when >= toDateTime('2020-10-01 00:00:00') #Set the update point. The data before this time point can be inserted by inserting into select
GROUP BY userid, hour
## perhaps
CREATE MATERIALIZED VIEW db.table_MV TO db.table_new ## table_new can be a mergetree table
AS SELECT * FROM db.table_old;
# It is not recommended to add the populate keyword for full update
- It is not recommended to perform distinct de duplication query on the high base column, but to perform approximate de duplication uniqCombined instead
5, Data synchronization
The new version of clickhouse provides an experimental function, that is, we can disguise the clickhouse as a backup database of mysql to align the data in mysql in real time. When the mysql database table data changes, it will be synchronized to the clickhouse in real time. In this way, the link of maintaining the real-time spark / flick task alone, reading kafka data and storing it in the clickhouse is omitted, which greatly reduces the operation and maintenance cost Improved efficiency.
CREATE DATABASE ckdb ENGINE = MaterializeMySQL('172.17.0.2:3306', 'ckdb', 'root', '123');
6, Inquiry fuse
In order to avoid the service avalanche caused by individual slow queries, in addition to setting the timeout for a single query, you can also configure the cycle; In a query cycle, if users frequently perform slow query operations, they will not be able to continue the query operations after exceeding the specified threshold
Monopoly strategy:
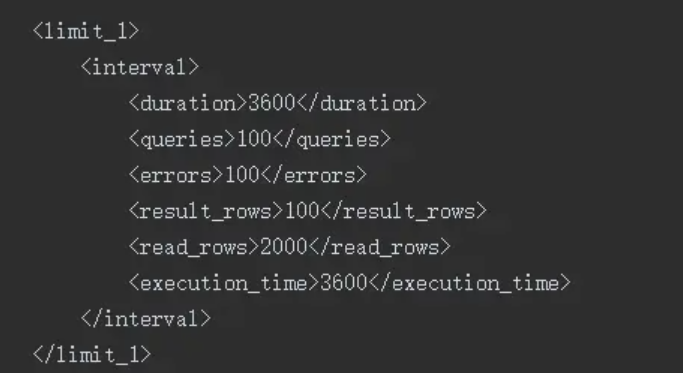
Bind user: