Introduction: This article is translated from Altinity's series of technical articles on ClickHouse. ClickHouse, an open source analysis engine for online analytical processing (OLAP), is widely used by companies at home and abroad because of its excellent query performance, PB level data scale and simple architecture. This series of technical articles will introduce ClickHouse in detail.
preface
This article is translated from Altinity's series of technical articles on ClickHouse. ClickHouse, an open source analysis engine for online analytical processing (OLAP), is widely used by companies at home and abroad because of its excellent query performance, PB level data scale and simple architecture.
The Alibaba cloud EMR-OLAP team has made a series of optimizations based on the open source ClickHouse and provided the cloud hosting service of the open source OLAP analysis engine ClickHouse. EMR ClickHouse is fully compatible with the product features of the open source version. At the same time, it provides cloud product functions such as cluster rapid deployment, cluster management, capacity expansion, capacity reduction and monitoring alarm. On the basis of open source, it optimizes the read-write performance of ClickHouse and improves the ability of rapid integration between ClickHouse and other components of EMR. visit https://help.aliyun.com/docum... Learn more.
Translator: He Yuan (Jinghang), senior product expert of Alibaba cloud computing platform Division

(source Altinity, invasion and deletion)
Handle real-time updates in ClickHouse
catalogue
- A short history of ClickHouse updates
- Use case
- Implementation update
- conclusion
- follow-up
In OLAP databases, variable data is usually not popular. ClickHouse also does not welcome variable data. Like some other OLAP products, ClickHouse initially did not even support updates. Later, the update function was added, but like many other functions, it was added in the "ClickHouse mode".
Even now, ClickHouse updates are asynchronous, making them difficult to use in interactive applications. Nevertheless, in many use cases, users need to modify existing data and expect to see the effect immediately. Can ClickHouse do it? Certainly.
A short history of ClickHouse updates
As early as 2016, the ClickHouse team published an article entitled "how to update data in ClickHouse". At that time, ClickHouse did not support data modification. It could only use a special insertion structure to simulate updates, and the data must be discarded by partition.
To meet the requirements of GDPR, the ClickHouse team provided UPDATE and DELETE in 2018. The updates and deletions in subsequent articles ClickHouse are still one of the most read articles in Altinity blog. This asynchronous and non atomic UPDATE is implemented in the form of ALTER TABLE UPDATE statement, and may disrupt a large amount of data. This is useful for batch operations and infrequent updates because they do not require immediate results. Although "normal" SQL updates appear properly in the roadmap every year, they are still not implemented in ClickHouse. If we need to UPDATE behavior in real time, we must use other methods. Let's consider an actual use case and compare the different implementations in ClickHouse.
Use case
Consider a system that generates various alarms. The user or machine learning algorithm will query the database from time to time to view and acknowledge new alarms. The confirmation operation needs to modify the alarm record in the database. Once acknowledged, the alarm will disappear from the user's view. This looks like an OLTP operation, which is incompatible with ClickHouse.
Since we cannot use the update, we can only insert the modified record instead. Once there are two records in the database, we need an effective method to obtain the latest records. To do this, we will try three different methods:
- ReplacingMergeTree
- Aggregate function
- AggregatingMergeTree
ReplacingMergeTree
We first create a table to store alarms.
CREATE TABLE alerts( tenant_id UInt32, alert_id String, timestamp DateTime Codec(Delta, LZ4), alert_data String, acked UInt8 DEFAULT 0, ack_time DateTime DEFAULT toDateTime(0), ack_user LowCardinality(String) DEFAULT '' ) ENGINE = ReplacingMergeTree(ack_time) PARTITION BY tuple() ORDER BY (tenant_id, timestamp, alert_id);
For simplicity, all alarm specific columns are packaged into a common "alert_data" column. However, it is conceivable that the alarm may contain dozens or even hundreds of columns. In addition, in our example, "alert_id" is a random string.
Notice the replaceingmergetree engine. Replaceingmergetee is a special table engine that replaces data by primary key with ORDER BY statement -- new rows with the same key value will replace old rows. In our use case, the "age of row data" is determined by the "ack_time" column. The replacement is performed in the background merge operation. It will not happen immediately or can not be guaranteed. Therefore, the consistency of query results is a problem. However, ClickHouse has a special syntax to handle such tables, which we will use in the following query.
Before running the query, we fill the table with some data. We generated 10 million alerts for 1000 Tenants:
INSERT INTO alerts(tenant_id, alert_id, timestamp, alert_data)
SELECT
toUInt32(rand(1)%1000+1) AS tenant_id,
randomPrintableASCII(64) as alert_id,
toDateTime('2020-01-01 00:00:00') + rand(2)%(3600*24*30) as timestamp,
randomPrintableASCII(1024) as alert_data
FROM numbers(10000000);Next, we acknowledge 99% of the alarms and provide new values for the "acked", "ack_user" and "ack_time" columns. We just insert a new line, not an update.
INSERT INTO alerts (tenant_id, alert_id, timestamp, alert_data, acked, ack_user, ack_time)
SELECT tenant_id, alert_id, timestamp, alert_data,
1 as acked,
concat('user', toString(rand()%1000)) as ack_user, now() as ack_time
FROM alerts WHERE cityHash64(alert_id) % 99 != 0;If we query this table now, we will see the following results:
SELECT count() FROM alerts ┌──count()─┐ │ 19898060 │ └──────────┘ 1 rows in set. Elapsed: 0.008 sec.
There are obviously both confirmed and unconfirmed rows in the table. So the replacement hasn't happened yet. In order to view "real" data, we must add the FINAL keyword.
SELECT count() FROM alerts FINAL ┌──count()─┐ │ 10000000 │ └──────────┘ 1 rows in set. Elapsed: 3.693 sec. Processed 19.90 million rows, 1.71 GB (5.39 million rows/s., 463.39 MB/s.)
Now the count is correct, but look at how much the query time has increased! After using FINAL, ClickHouse must scan all rows when executing the query and merge them by primary key. This can get the right answer, but it costs a lot of money. Let's see if it would be better to filter only unconfirmed rows.
SELECT count() FROM alerts FINAL WHERE NOT acked ┌─count()─┐ │ 101940 │ └─────────┘ 1 rows in set. Elapsed: 3.570 sec. Processed 19.07 million rows, 1.64 GB (5.34 million rows/s., 459.38 MB/s.)
Although the count is significantly reduced, the query time and the amount of data processed are the same. Filtering does not help speed up queries. As the table increases, the cost may be greater. It cannot be extended.
Note: to improve readability, all queries and query times are displayed as if they were run in "Clickhouse client". In fact, we tried several queries to ensure consistent results and confirmed them using the "Clickhouse benchmark" utility.
Well, looking up the whole table doesn't help. Can we still use replaceingmergetree for our use cases? Let's choose a tenant at random_ ID, and then select all unconfirmed records -- imagine that the user is viewing the monitoring view. I like Ray Bradbury, so choose 451. Since the value of "alert_data" is only randomly generated, we will calculate a checksum to confirm that the results of multiple methods are the same:
SELECT count(), sum(cityHash64(*)) AS data FROM alerts FINAL WHERE (tenant_id = 451) AND (NOT acked) ┌─count()─┬─────────────────data─┐ │ 90 │ 18441617166277032220 │ └─────────┴──────────────────────┘ 1 rows in set. Elapsed: 0.278 sec. Processed 106.50 thousand rows, 119.52 MB (383.45 thousand rows/s., 430.33 MB/s.)
It's too fast! We queried all unconfirmed data in only 278 milliseconds. Why is it so fast this time? The difference lies in the screening criteria. "tenant_id" is a part of a primary key, so ClickHouse can filter data before FINAL. In this case, replacing mergetree becomes efficient.
We also try the user filter and query the number of alarms acknowledged by a specific user. The cardinality of the columns is the same -- we have 1000 users, so you can try user451.
SELECT count() FROM alerts FINAL WHERE (ack_user = 'user451') AND acked ┌─count()─┐ │ 9725 │ └─────────┘ 1 rows in set. Elapsed: 4.778 sec. Processed 19.04 million rows, 1.69 GB (3.98 million rows/s., 353.21 MB/s.)
This is very slow because indexes are not used. ClickHouse scanned all 19.04 million lines. Note that we cannot add "ack_user" to the index because it will break the replacing mergetree semantics. However, we can make a clever treatment with PREWHERE:
SELECT count() FROM alerts FINAL PREWHERE (ack_user = 'user451') AND acked ┌─count()─┐ │ 9725 │ └─────────┘ 1 rows in set. Elapsed: 0.639 sec. Processed 19.04 million rows, 942.40 MB (29.80 million rows/s., 1.48 GB/s.)
Preview is a special trick that allows ClickHouse to apply filters in different ways. In general, ClickHouse is smart enough to automatically move conditions to preview, so users don't have to care. It didn't happen this time. Fortunately, we checked it.
Aggregate function
ClickHouse is famous for supporting various aggregate functions, and the latest version can support more than 100. Combine 9 aggregate function combinators (see https://clickhouse.tech/docs/... ), this provides high flexibility for experienced users. For this use case, we don't need any advanced functions. We only use the following three functions: "argMax", "max" and "any".
You can use the "argMax" aggregate function to execute the same query for tenant 451, as follows:
SELECT count(), sum(cityHash64(*)) data FROM (
SELECT tenant_id, alert_id, timestamp,
argMax(alert_data, ack_time) alert_data,
argMax(acked, ack_time) acked,
max(ack_time) ack_time_,
argMax(ack_user, ack_time) ack_user
FROM alerts
GROUP BY tenant_id, alert_id, timestamp
)
WHERE tenant_id=451 AND NOT acked;
┌─count()─┬─────────────────data─┐
│ 90 │ 18441617166277032220 │
└─────────┴──────────────────────┘
1 rows in set. Elapsed: 0.059 sec. Processed 73.73 thousand rows, 82.74 MB (1.25 million rows/s., 1.40 GB/s.)The same result, the same number of rows, but the performance is 4 times higher than before! This is the efficiency of ClickHouse aggregation. The disadvantage is that queries become more complex. But we can make it easier.
Please note that when the alarm is acknowledged, we only update the following 3 columns:
- acked: 0 => 1
- ack_time: 0 => now()
- ack_user: '' => 'user1'
In all 3 cases, the column value will increase! Therefore, we can use "max" instead of the slightly bloated "argMax". Since we do not change "alert_data", we do not need to do any actual aggregation for this column. ClickHouse has an easy-to-use "any" aggregation function to achieve this. It can pick any value without additional overhead:
SELECT count(), sum(cityHash64(*)) data FROM (
SELECT tenant_id, alert_id, timestamp,
any(alert_data) alert_data,
max(acked) acked,
max(ack_time) ack_time,
max(ack_user) ack_user
FROM alerts
GROUP BY tenant_id, alert_id, timestamp
)
WHERE tenant_id=451 AND NOT acked;
┌─count()─┬─────────────────data─┐
│ 90 │ 18441617166277032220 │
└─────────┴──────────────────────┘
1 rows in set. Elapsed: 0.055 sec. Processed 73.73 thousand rows, 82.74 MB (1.34 million rows/s., 1.50 GB/s.)The query is simpler and faster! The reason is that after using the "any" function, ClickHouse does not need to calculate "max" for the "alert_data" column!
AggregatingMergeTree
AggregatingMergeTree is one of the most powerful features of ClickHouse. When combined with materialized view, it can realize real-time data aggregation. Since we used the aggregation function in the previous method, can we use AggregatingMergeTree to make it more perfect? In fact, this has not improved.
We only update one row at a time, so a group has only two rows to aggregate. AggregatingMergeTree is not the best choice for this situation. But we have a trick. As we know, alarms are always inserted in the unacknowledged state first, and then become the acknowledged state. After the user confirms the alarm, only 3 columns need to be modified. Can we save disk space and improve performance if we don't duplicate the data of other columns?
Let's create a table that implements aggregation using the "max" aggregation function. We can also use "any" instead of "max", but the column must be empty - "any" will select a non empty value.
DROP TABLE alerts_amt_max; CREATE TABLE alerts_amt_max ( tenant_id UInt32, alert_id String, timestamp DateTime Codec(Delta, LZ4), alert_data SimpleAggregateFunction(max, String), acked SimpleAggregateFunction(max, UInt8), ack_time SimpleAggregateFunction(max, DateTime), ack_user SimpleAggregateFunction(max, LowCardinality(String)) ) Engine = AggregatingMergeTree() ORDER BY (tenant_id, timestamp, alert_id);
Since the original data is random, we will populate the new table with the existing data in "alerts". As before, we will insert it in two times, one is unacknowledged alarm and the other is acknowledged alarm:
INSERT INTO alerts_amt_max SELECT * FROM alerts WHERE NOT acked; INSERT INTO alerts_amt_max SELECT tenant_id, alert_id, timestamp, '' as alert_data, acked, ack_time, ack_user FROM alerts WHERE acked;
Note that for confirmed events, we insert an empty string instead of "alert_data". We know that the data will not change, we can only store it once! The aggregate function fills the gap. In practice, we can skip all invariant columns and let them get the default value.
After having the data, we first check the data size:
SELECT
table,
sum(rows) AS r,
sum(data_compressed_bytes) AS c,
sum(data_uncompressed_bytes) AS uc,
uc / c AS ratio
FROM system.parts
WHERE active AND (database = 'last_state')
GROUP BY table
┌─table──────────┬────────r─┬───────────c─┬──────────uc─┬──────────────ratio─┐
│ alerts │ 19039439 │ 20926009562 │ 21049307710 │ 1.0058921003373666 │
│ alerts_amt_max │ 19039439 │ 10723636061 │ 10902048178 │ 1.0166372782501314 │
└────────────────┴──────────┴─────────────┴─────────────┴────────────────────┘Well, with random strings, we have little compression. However, since we do not have to store "alerts_data" twice, the size of aggregated data can be reduced by half compared with non aggregation.
Now let's try to query the aggregation table:
SELECT count(), sum(cityHash64(*)) data FROM (
SELECT tenant_id, alert_id, timestamp,
max(alert_data) alert_data,
max(acked) acked,
max(ack_time) ack_time,
max(ack_user) ack_user
FROM alerts_amt_max
GROUP BY tenant_id, alert_id, timestamp
)
WHERE tenant_id=451 AND NOT acked;
┌─count()─┬─────────────────data─┐
│ 90 │ 18441617166277032220 │
└─────────┴──────────────────────┘
1 rows in set. Elapsed: 0.036 sec. Processed 73.73 thousand rows, 40.75 MB (2.04 million rows/s., 1.13 GB/s.)Thanks to aggregating merge tree, we process less data (previously 82MB, now 40MB) and are more efficient.
Implementation update
ClickHouse will do its best to merge data in the background, so as to delete duplicate rows and perform aggregation. However, sometimes it makes sense to force a merge, for example, to free up disk space. This can be achieved through the OPTIMIZE FINAL statement. The OPTIMIZE operation is slow and expensive, so it cannot be executed frequently. Let's see how it affects query performance.
OPTIMIZE TABLE alerts FINAL Ok. 0 rows in set. Elapsed: 105.675 sec. OPTIMIZE TABLE alerts_amt_max FINAL Ok. 0 rows in set. Elapsed: 70.121 sec.
After optimizing final is executed, the number of rows and data of the two tables are the same.
┌─table──────────┬────────r─┬───────────c─┬──────────uc─┬────────────ratio─┐ │ alerts │ 10000000 │ 10616223201 │ 10859490300 │ 1.02291465565429 │ │ alerts_amt_max │ 10000000 │ 10616223201 │ 10859490300 │ 1.02291465565429 │ └────────────────┴──────────┴─────────────┴─────────────┴──────────────────┘
The performance differences between different methods become less obvious. The summary table is as follows:
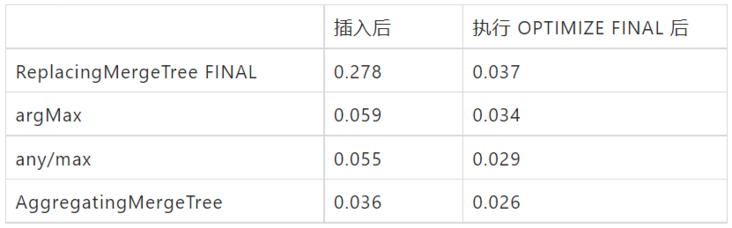
conclusion
ClickHouse provides a rich set of tools to handle real-time updates, such as replacing mergetree, collapsing mergetree (not mentioned in this article), aggregating mergetree, and aggregation functions. All these methods have the following three commonalities:
"Modify" data by inserting a new version. The insertion speed in ClickHouse is very fast.
There are some effective methods to simulate update semantics similar to OLTP database.
However, the actual changes do not occur immediately.
The choice of specific methods depends on the use cases of the application. For users, replaceingmergetree is straightforward and the most convenient method, but it is only applicable to small and medium-sized tables or when data is always queried by primary key. Using aggregate functions can provide more flexibility and performance, but requires a lot of query rewriting. Finally, aggregating merge tree can save storage space and keep only modified columns. These are good tools for ClickHouse DB designers, which can be applied according to specific needs.
follow-up
You've learned about handling real-time updates in ClickHouse. This series also includes other content:
- Use the new TTL move to store the data in a suitable place
- Using Join in ClickHouse materialized view
- ClickHouse aggregate function and aggregate state
- Nested data structures in ClickHouse
Original link
This article is the original content of Alibaba cloud and cannot be reproduced without permission.