Author: Li Xin
In recent ten years, Internet technology has developed rapidly. More and more industries have joined the matrix of the Internet, which has brought more rich and complex business scenario requirements, which is undoubtedly a great challenge to the performance of data application system.
Relational database mysql is the most widely used database product in the application system, with strong data query and transaction processing capabilities. In today's cloud era, the application system has gradually evolved to be built based on the cloud native Serverless architecture, because it has the advantages of low cost and high elasticity. However, there are still some obvious deficiencies in MySQL based data storage under Serverless architecture:
- Poor elastic expansion ability. An important feature of Serverless scenario is that the application load has significant peaks and troughs. When facing the peak flow, DBA needs to manually expand the cluster to avoid the cluster being exploded; When the traffic is low, the cluster needs to be shrunk to save cost.
- High complexity of operation and maintenance. MySQL construction requires cluster purchase, installation service and management connection. After the business goes online, we should also pay attention to data security, service availability, response time, etc. the proportion of time used for cluster operation and maintenance will become higher, so we can't focus more on business R & D.
- High cost. Usually, DBA s need to estimate the business scale to set the initial database capacity in advance. When the business requests do not reach the estimated value, the resources in the cluster will always be idle, resulting in a waste of resources.
Serverless DataBase
MySQL supports the relational model and its strong transaction characteristics, which makes it a very important position in the application system. It is one of the storage components that can not be completely replaced at present. However, blindly relying on MySQL will make the application system unable to be fully Serverless and cannot enjoy the extreme elasticity brought by Serverless.
We have some new architecture practices in Alibaba. The data requiring strong transaction processing still uses relational table storage, while for non strong transaction table data storage, we have designed a Serverless table storage with extreme flexibility.
As for Serverless database products, our design requirements are as follows:
- Completely elastic. It can automatically expand and shrink the capacity elastically according to the application load, which can bring users a more economical billing mode and a smoother experience.
- Pay by volume. The use cost of Serverless database mainly comes from the calculation cost and storage cost. Users only need to pay for the storage units and response units actually generated by the business to save costs.
- Zero operation and maintenance. It is ready to use and does not need to manage operation and maintenance matters such as capacity, water level, software upgrade and kernel optimization, so that R & D can really focus on business development.
Serverless architecture is widely used in many business scenarios. For example, in its core e-commerce business, Century Lianhua Group comprehensively launched its business into the cloud and gradually transformed it into a medium platform model with full serverless architecture in view of the pain points such as difficult resource budget and system deployment encountered in the self built IDC room.
Century Lianhua Group has adopted the scheme of function computing + API gateway + Tablestore to easily support the promotion activities such as 6.18 and double 11. Among them, as the core storage in the cloud serverless architecture of Century Lianhua e-commerce system, Tablestore has the advantages of extreme flexibility, operation and maintenance free and low cost.
Introduction to table store
Table storage Tablestore was developed at the beginning of Alibaba cloud's establishment in 2009. It is built from scratch based on the underlying flying platform. It is a multi model, multi engine Serverless table storage. It has exported more than 30 regions at home and abroad on the public cloud, with 15000 servers and 200PB storage. It is the underlying core storage of many commercial products of Alibaba cloud.
At the same time, offline has been exported to finance, energy, power, logistics, medical treatment, government and enterprises, serving 1000 + enterprise customers and 500 + offline projects of public cloud.
Table storage Tablestore has the integration function of HBase and ElasticSearch, has the characteristics of extreme elastic experience, operation and maintenance free and ready to use, and supports GB to PB elastic storage and non perceptual expansion of 100000 TPS service capabilities. While supporting massive table data, it provides rich data retrieval and analysis capabilities. It is a one-stop structured data storage platform integrating storage, search and analysis.
The overall architecture of the table store is shown in the following figure:


Tablestore architecture diagram
Table storage provides a variety of data models, mainly including wide column model, message model (Timeline) and time series model.
- The wide table model mainly carries table structure data storage, such as e-commerce order data.
- The message model mainly hosts message data storage, such as IM/Feeds messages.
- The timing model mainly carries the timing data storage, such as the timing data of Internet of things devices.
Next, we will take the e-commerce order scenario as an example to show you how to build a Serverless order storage system based on the Tablestore wide table model.
Tablestore experience
preparation
Before experiencing the extreme flexibility brought by the Tablestore, you need to prepare the following steps:
(1) Create an alicloud account and obtain the AK of the alicloud account. (the cloud account AK is the key to access all cloud services, including the Tablestore. You need to access the Tablestore service through the AK later).
(2) Download and start the command line tool Tablestore CLI provided by Tablestore. The command line tool provides some simple instructions to manage the table storage service.
First, configure the connection key through the config command and enable_ The service command enables the Tablestore service:
config --id accessKeyID --key accessKeySecret enable_service
(3) Create an instance with the create_instance command:
create_instance -d "order storage" -n serverless-db -r cn-hangzhou
An instance is equivalent to the concept of MySQL database. After an instance is created, you do not need to consider the water level of the physical machine cluster where the instance is located, but just focus on developing business logic. At the same time, the reading, writing and storage on the instance are billed by volume. If there is no reading, writing and storage, there will be no actual cost.
So far, a Serverless DataBase that can support GB to PB storage, has no concurrency limit, zero operation and maintenance, and is fully elastic has been created.
Create table
Widecolumn model is a schema free data table. Different from relational database MySQL, the data table of Widecolumn model only needs to define the primary key structure rather than the attribute column structure to create a table.
For example, the table structure of an order table order is shown in the table below:
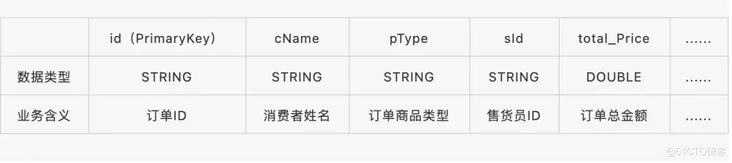
To create an order table of a wide table model, the attribute column information does not need to be defined, only the order table primary key id needs to be defined. The command is as follows:
create_instance -d "order storage" -n serverless-db -r cn-hangzhou
After executing the create command, an order wide table is successfully created. The newly created order wide table will be initialized with a data partition.
With the increase of order data volume or access volume, The wide table model will be split and expanded into multiple data partitions according to the distribution range of the first primary key (order ID in the above data model) and evenly distributed to multiple physical machines to support larger data scale (TB or even PB) and read-write throughput (more than 100000 TPS). The whole expansion process is completed automatically by the server without manual intervention.
Data import
The simulation generates 1 million sample order data, which are imported into the order table in batch through the import command. The write speed of a single data partition can reach tens of thousands of lines / s. with the expansion of the partition, the write throughput can be further improved.
import -i orderDataFile -l 1000000
Current speed is: 10000 rows/s. Total succeed count 10000, failed count 0. Current speed is: 12600 rows/s. Total succeed count 22600, failed count 0. ...... Current speed is: 9200 rows/s. Total succeed count 1000000, failed count 0. Import finished, total count is 1000000, failed 0 rows.
Order query
Use the get command to query the wide table model in a single line according to the order number (id) to get an order data. The get command can only query in a single line based on rowKey.
Example of querying an order:
id = "0000005be2b43dd134eae18ebe079774"
get --pk '["0000005be2b43dd134eae18ebe079774"]
+----------------------------------+-------+--------+---------+-------------+---------------+--------+--------+----------+--------+---------+-------+-------+--------+------------+ | order_id | cId | cName | hasPaid | oId | orderTime | pBrand | pCount | pId | pName | pPrice | pType | sId | sName | totalPrice | +----------------------------------+-------+--------+---------+-------------+---------------+--------+--------+----------+--------+---------+-------+-------+--------+------------+ | 0000005be2b43dd134eae18ebe079774 | c0015 | Cancel Friday | false | o0035062633 | 1507519847532 | millet | 3 | p0005003 | Millet 6 | 2299.21 | mobile phone | s0017 | Sell Zheng Qi | 6897.63 | +----------------------------------+-------+--------+---------+-------------+---------------+--------+--------+----------+--------+---------+-------+-------+--------+------------+
Order retrieval and statistics
Multi condition combination filtering often occurs in the order scenario. In this case, it needs to rely on the multi index feature of the Tablestore. Multivariate index is a table data index similar to Elasticsearch provided by Tablestore. It supports rich query methods and data aggregation capabilities, and can establish indexes on multiple columns respectively. Unlike federated indexes in MySQL, multiple indexes can be queried according to any combination of fields and will not be matched according to the leftmost prefix of multiple columns.
For example, we build indexes on fields such as id, pName and totalPrice respectively, and use data structures such as inverted index, word segmentation and BKDTree to provide query capabilities such as accurate query, full-text retrieval and range query. In addition, multiple indexes also support grouping by field, sorting by multiple fields, and statistical aggregation.
Using create_ search_ The index command creates multiple indexes on a wide table to speed up queries.
create_search_index -t order -n order_index
{
"IndexSetting": null,
"FieldSchemas": [{
"FieldName": "id",
"FieldType": "KEYWORD",
"Index": true,
"EnableSortAndAgg": true,
"Store": true
},{
"FieldName": "pName",
"FieldType": "TEXT",
"Index": true,
"EnableSortAndAgg": false,
"Store": true
},{
"FieldName": "totalPrice",
"FieldType": "DOUBLE",
"Index": true,
"EnableSortAndAgg": true,
"Store": true
}
...//Other fields
]
}The Tablestore supports SQL query capability, is compatible with MySQL query syntax, and retains the usage habit of relational database as much as possible. SQL can automatically select the index and accelerate the query. Through the query acceleration of multiple indexes, SQL also has the ability of millisecond delay query in the scale of 10 billion data.
Order retrieval is performed according to the three field conditions of sName, pBrand and pName:
select * from `order` where sName = "Sell Friday" and pBrand = "millet" and pName like "Red rice%" limit 3;
+----------------------------------+-------+--------+---------+-------------+---------------+--------+--------+----------+---------+--------+-------+---------------+-------+--------+------------+ | id | cId | cName | hasPaid | oId | orderTime | pBrand | pCount | pId | pName | pPrice | pType | payTime | sId | sName | totalPrice | +----------------------------------+-------+--------+---------+-------------+---------------+--------+--------+----------+---------+--------+-------+---------------+-------+--------+------------+ | 00001c760c04126da067e90409467c4e | c0022 | Xiao Zhaoyi | true | o0009999792 | 1494976931954 | millet | 3 | p0005004 | Red rice 5 s | 499.01 | mobile phone | 1494977189780 | s0005 | Sell Friday | 1497.03 | +----------------------------------+-------+--------+---------+-------------+---------------+--------+--------+----------+---------+--------+-------+---------------+-------+--------+------------+ | 0000d89f46952ac03da71a33c8e83eef | c0012 | Xiaoqian II | false | o0024862442 | 1502415559707 | millet | 2 | p0005004 | Red rice 5 s | 499.01 | mobile phone | null | s0015 | Sell Friday | 998.02 | +----------------------------------+-------+--------+---------+-------------+---------------+--------+--------+----------+---------+--------+-------+---------------+-------+--------+------------+ | 0000f560b62779285e86947f8e8d0e4c | c0008 | Xiao fengba | false | o0000826505 | 1490386088808 | millet | 1 | p0005004 | Red rice 5 s | 499.01 | mobile phone | null | s0015 | Sell Friday | 499.01 | +----------------------------------+-------+--------+---------+-------------+---------------+--------+--------+----------+---------+--------+-------+---------------+-------+--------+------------+
Count the number of orders of each commodity brand in all orders:
select pBrand,count(*) from `order` group bypBrand;
+--------+----------+ | pBrand | count(*) | +--------+----------+ | vivo | 162539 | +--------+----------+ | association | 304252 | +--------+----------+ | oppo | 242513 | +--------+----------+ | Apple | 96153 | +--------+----------+ | millet | 194543 | +--------+----------+
summary
As a widely used Serverless DataBase, Tablestore provides an economic billing model and can greatly reduce business costs. Taking the above order scenario as an example, under the data level of 100 million orders and the average reading and writing capacity of 2000TPS, the use cost of using tables to store Tablestore is less than 400 yuan / month. At the same time, Tablestore has the ultimate elastic service capability and zero operation and maintenance features, which can bring users a smoother experience.
If you have questions or want to know more about table storage, you can search the group number: "23307953". Free online expert services are provided in the group. Welcome to join us.
Click here , you can view the table storage details!