1, Create DataFrames from Data Sources
1. Data source for DataFrame
- DataFrames reads data from the data source and writes data to the data source
- Spark SQL supports a wide range of data source types and formats
- Text files
- CSV, JSON, plain text
- Binary format files
- Apache Parquet, Apache ORC, Apache Avro data format
- Tables
- Hive metastore, JDBC
- Cloud
- Such as Amazon S3 and Microsoft ADLS
- Text files
- You can also use custom or third-party data source types
2,DataFrames and Apache Parquet Files
- Parquet is a very common file format for DataFrame data
- Characteristics of Parquet
- Optimized binary storage of structured data
- Schema metadata is embedded in the file
- Efficient performance and large amount of data
- Many Hadoop ecosystem tools support
- Spark, Hadoop, MapReduce, Hive, etc
- Viewing Parquet file schema and data using Parquet tools
(1) Use head to display the first few records
$ parquet-tools head mydatafile.parquet
(2) View schema using schema
$ parquet-tools schema mydatafile.parquet
3. Create DataFrame from data source
- spark.read returns a DataFrameReader object
- Use DataFrameReader settings to specify how to load data sources from data
- format: indicates the data source type, such as csv, json, parquet, etc. (the default is parquet)
- option: Specifies the key / value settings for the underlying data source
- Schema: Specifies the schema to use instead of inferring a schema from the data source
- Create DataFrame based on data source
- Load data from one or more files
4. Example: creating a DataFrame from a data source
- Read CSV text file
- Treat the first line in the file as a title, not data
python:
myDF = spark.read.format("csv").option("header","true").load("/loudacre/myFile.csv")
- Read Avro file
python:
myDF = spark.read.format("avro").load("/loudacre/myData.avro")
5. DataFrameReader convenience function
- You can call load functions for certain formats
- Instead of formatting and using loaded shortcuts
- The following two code examples are the same, conventional and concise
spark.read.format("csv").load("/loudacre/myFile.csv")
spark.read.csv("/loudacre/myFile.csv")
6. Specify the data source file location
- When reading from a file data source, you must specify a location
- The location can be a single file, a file list, a directory, or a wildcard
- for example
- spark.read.json("myfile.json")
- spark.read.json("mydata/")
- spark.read.json("mydata/*.json")
- spark.read.json("myfile1.json","myfile2.json")
- Files and directories are referenced by absolute or relative URI s
- Relative URI (using default file system)
- myfile.json
- Absolute URI
- hdfs://nnhost/loudacre/myfile.json
- file:/home/training/myfile.json
- Relative URI (using default file system)
7. Create DataFrames from Hive Tables
- Apache Hive provides access to data similar databases in HDFS
- Apply Schemas to HDFS files
- Metadata is stored in Hive metastore
- Spark can read and write Hive tables
- Inferring DataFrame schema from Hive metastore
- Spark Hive support must be enabled and Hive location configured
- warehouse in HDFS
python:
usersDF = spark.read.table("users")
8. Create a DataFrame from data in memory
- You can create a DataFrame from a collection of data in memory
- Useful for testing and integration
val mydata = List(("Josiah","Bartlet"),("Harry","Potter"))
val myDF = spark.createDataFrame(mydata)
myDF.show
+------+-------+
| _1| _2|
+------+-------+
|Josiah|Bartlet|
| Harry| Potter|
+------+-------+
2, Save DataFrames to Data Sources
1. Key DataFrameWriter Functions
- DataFrame write function returns a DataFrameWriter
- Save data to a data source, such as a table or a set of files
- The working principle is similar to DataFrameReader
- DataFrameWriter method
- format specifies the data source type
- mode determines whether a directory or table already exists
- Error, overwrite, append, or ignore (error by default)
- partitionBy stores data in the partition directory as a form
Column = value (same as Hive partition) - option specifies the properties of the target data source
- save saves the data as a file in the specified directory
- Or use json, csv, parquet, and so on
- saveAsTable saves data to the Hive metastore table
- Default data location based on Hive warehouse
- Set the path option to override the location
2. Example: save a dataframe to Data Sources
- To a named my_ Write data to Hive metastore table of table
- If the table already exists, append data
- Change position
myDF.write.mode("append").option("path","/loudacre/mydata").saveAsTable("my_table")
- Write data in the form of Parquet file in mydata directory
myDF.write.save("mydata")
3. Save data to file
- When saving data from a DataFrame, you must specify a directory
- Spark saves the data to one or more assembly files in this directory
devDF.write.csv("devices")
$ hdfs dfs -ls devices Found 4 items -rw-r--r-- 3 training training 0 ... devices/_SUCCESS -rw-r--r-- 3 training training 2119 ... devices/part-00000-e0fa6381-....csv -rw-r--r-- 3 training training 2202 ... devices/part-00001-e0fa6381-....csv -rw-r--r-- 3 training training 2333 ... devices/part-00002-e0fa6381-....csv
3, DataFrame Schemas
1,DataFrame Schemas
- Each DataFrame has an associated schema
- A schema is used to define the name and type of a column
- The schema is immutable and is defined when the DataFrame is created
myDF.printSchema() root |-- lastName: string (nullable = true) |-- firstName: string (nullable = true) |-- age: integer (nullable = true)
- When creating a new DataFrame from a data source, the schema can:
- Automatically infer from data source
- Specify programmatically
- When the DataFrame is created by transformation, Spark will calculate the new schema based on the query.
2. Inferred Schemas
- Spark can load patterns from structured data, such as:
- Parquet, ORC, and Avro data files - schema is embedded in the file
- Hive table -- schema is defined in Hive metastore
- Parent DataFrames
- Spark can also try to infer patterns from semi-structured data sources
- For example, JSON and CSV
3. Example: infer the schema of a CSV file (no header)

spark.read.option("inferSchema","true").csv("people.csv").printSchema()
root
|-- _c0: integer (nullable = true)
|-- _c1: string (nullable = true)
|-- _c2: string (nullable = true)
|-- _c3: integer (nullable = true)
4. Example: infer the schema of CSV file (with header)
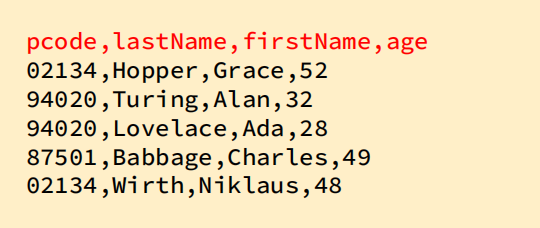
spark.read.option("inferSchema","true").option("header","true").csv("people.csv").printSchema()
root
|-- pcode: integer (nullable = true)
|-- lastName: string (nullable = true)
|-- firstName: string (nullable = true)
|-- age: integer (nullable = true)
5. Inferred Schemas and Manual Schemas
- Disadvantages of automatic inference mode relying on Spark
- Initial file scanning is required for inference, which may take a long time
- The inferred pattern may not be correct for your use case
- Manually define mode
- Schema Schemas is a StructType object that contains a list of structfields
- Each StructField represents a column in the schema, specifying:
- The name of the column
- The data type of the column
- Whether the data can be empty (optional - the default is true)

6. Example: incorrect pattern inference
- The CSV file pattern inferred below is incorrect
- The pcode column should be a string
spark.read.option("inferSchema","true").option("header","true").csv("people.csv").printSchema()
root
|-- pcode: integer (nullable = true)
|-- lastName: string (nullable = true)
|-- firstName: string (nullable = true)
|-- age: integer (nullable = true)
7. Example: manually defining patterns programmatically (Python)
from pyspark.sql.types import *
columnsList = [
StructField("pcode", StringType()),
StructField("lastName", StringType()),
StructField("firstName", StringType()),
StructField("age", IntegerType())]
peopleSchema = StructType(columnsList)
8. Example: manually defining patterns programmatically (Scala)
import org.apache.spark.sql.types._
val columnsList = List(
StructField("pcode", StringType),
StructField("lastName", StringType),
StructField("firstName", StringType),
StructField("age", IntegerType))
val peopleSchema = StructType(columnsList)
9. Example: apply manual mode
spark.read.option("header","true").schema(peopleSchema).csv("people.csv").printSchema()
root
|-- pcode: string (nullable = true)
|-- lastName: string (nullable = true)
|-- firstName: string (nullable = true)
|-- age: integer (nullable = true)
4, Eagle and lazy execution
1. Eager execution and lazy execution
- Once a statement appears in the code, the operation is executed immediately
- When an operation is performed only when the result is referenced, the operation is lazy
- Spark queries are slow and eager to execute
- The DataFrame pattern is eagerly determined
- Data conversion is delayed
- When an action is invoked in a series of transformations, inert execution is triggered.
2,Eager and Lazy Execution(1)
python:
> usersDF = spark.read.json("users.json")
3,Eager and Lazy Execution(2)
python:
> usersDF = spark.read.json("users.json")
> nameAgeDF = usersDF.select("name","age")
4,Eager and Lazy Execution(3)
python:
> usersDF = spark.read.json("users.json")
> nameAgeDF = usersDF.select("name","age")
> nameAgeDF.show()
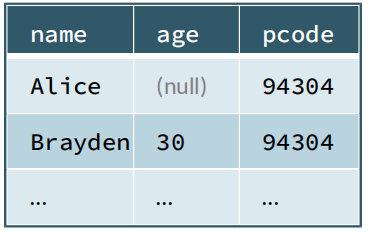
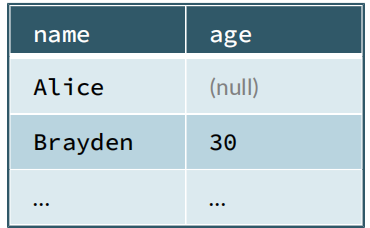
5,Eager and Lazy Execution(4)
python:
> usersDF = spark.read.json("users.json")
> nameAgeDF = usersDF.select("name","age")
> nameAgeDF.show()
+-------+----+
| name| age|
+-------+----+
| Alice|null|
|Brayden| 30|
| Carla| 19|
...
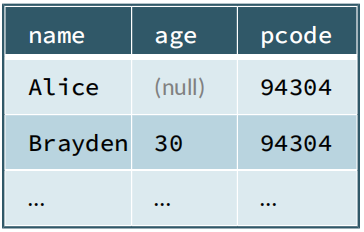
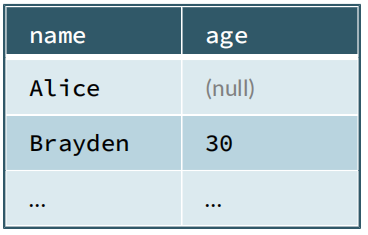
5, Basic points
- DataFrames can be loaded and saved from several different types of data sources
- Semi structured text files such as CSV and JSON
- Structured binary formats such as Parquet, Avro and ORC
- Hive and JDBC tables
- DataFrames can infer a schema from the data source or manually define a schema
- The DataFrame schema is determined at creation time, but the query is delayed (when an action is called)
6, Practical exercise: using DataFrames and schema s
1. Create DataFrame based on Hive Table
1. This exercise uses a DataFrame based on the accounts table in the devsh Hive database. You can use the Beeline SQL command line to access Hive to view the schema
$ beeline -u jdbc:hive2://localhost:10000 -e "DESCRIBE devsh.accounts"
2. If it is not already running, start the spark shell (you can choose Scala or Python).
spark-shell
3. Create a new DataFrame using the Hive table devsh.accounts.
pyspark> accountsDF = spark.read.table("devsh.accounts")
scala> val accountsDF = spark.read.table("devsh.accounts")

4. Print the mode and the first few rows of the DataFrame. Note that the mode is consistent with that of the Hive table.
5. Create a new DataFrame using the account data row with zip code 94913 and save the results to the HDFS directory / devsh_ loudacre/ accounts_ In the CSV file in zip94913. You can do this in a single command, as shown below, or you can use multiple commands.
pyspark> accountsDF.where("zipcode = 94913").write.option("header","true").csv("/devsh_loudacre/accounts_zip94913")
scala> accountsDF.where("zipcode = '94913'").write.option("header","true").csv("/devsh_loudacre/accounts_zip94913")
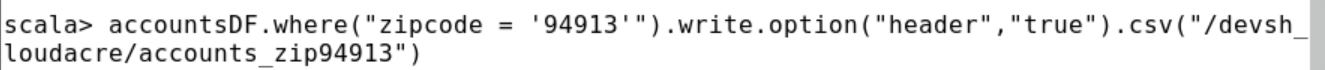
6. Use hdfs to view / devsh in hdfs in a separate terminal window_ loudacre/accounts_ Zip94913 directory and one of them saves the data in the file. Verify that the CSV file contains header lines and only records for the selected zip code.
7. Optional: try to create a new DataFrame based on the CSV file created above. Compare the schema of the original accountsDF and the new DataFrame. What's the difference? Try again, this time setting the inforschema option to true and compare again.
2. Define the schema of the DataFrame
8. If you haven't already done so, check the HDFS file / devsh_ Data in loudacre / devices.json.
9. Create a new DataFrame based on the device. json file. (this command may take several seconds to infer the mode.)
pyspark> devDF = spark.read.json("/devsh_loudacre/devices.json")
scala> val devDF = spark.read.json("/devsh_loudacre/devices.json")

10. View the mode of devDF DataFrame. Notice the column names and types that Spark infers from the JSON file. In particular, release_ The type of the DT column is string, and the data in the column actually represents a timestamp.
11. Define the schema that correctly specifies this DataFrame column type. First, import the package that contains the necessary class and type definitions.
Note: "" stands for all, which is consistent with "*" in JAVA
pyspark> from pyspark.sql.types import *
scala> import org.apache.spark.sql.types._

12. Next, create a collection of StructField objects that represent column definitions. release_ The DT column should be a timestamp.
pyspark> devColumns = [StructField("devnum",LongType()),
StructField("make",StringType()),
StructField("model",StringType()),
StructField("release_dt",TimestampType()),
StructField("dev_type",StringType())]
scala> val devColumns = List(
StructField("devnum",LongType),
StructField("make",StringType),
StructField("model",StringType),
StructField("release_dt",TimestampType),
StructField("dev_type",StringType))
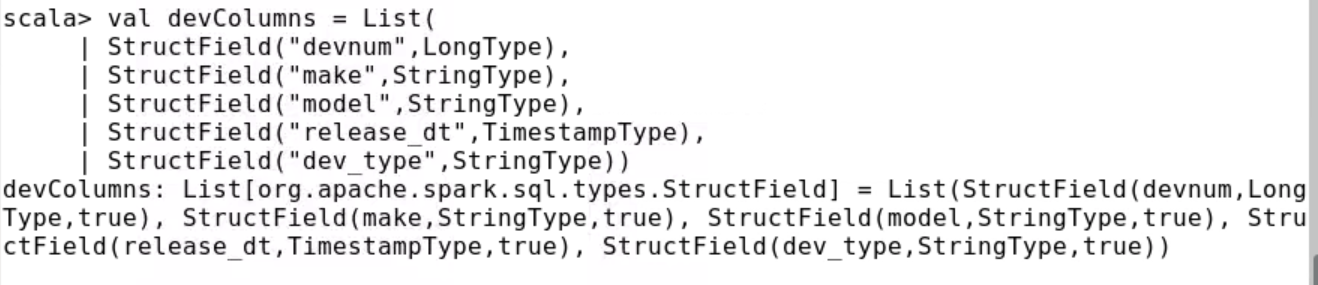
13. Create a schema (StructType object) using the column definition list.
pyspark> devSchema = StructType(devColumns)
scala> val devSchema = StructType(devColumns)

14. Recreate the devDF DataFrame, this time using the new schema.
pyspark> devDF = spark.read.schema(devSchema).json("/devsh_loudacre/devices.json")
scala> val devDF = spark.read.schema(devSchema).json("/devsh_loudacre/devices.json")

15. View the schema and data of the new DataFrame and confirm the release_ The DT column type is now a timestamp.
16. Since the device data uses the correct mode, the data is written in Parquet format, which will automatically embed the mode. Save the Parquet data file to the "/ devsh_loudacre/devices_parquet" directory of HDFS.
17. Optional: in a separate terminal window, use parquet tools to view the mode of saved files. Please download the HDFS directory (or a single file) before executing the command.
$ hdfs dfs -get /devsh_loudacre/devices_parquet /tmp/
$ parquet-tools schema /tmp/devices_parquet/
Note: release_ The type of the DT column is labeled int96; This is how Spark represents the timestamp type in Parquet. For more information about the jigsaw puzzle, run the jigsaw puzzle -- help.
18. Use save on devices_ Create a new DataFrame from the Parquet file in Parquet and view its schema. Note that Spark can correctly infer release from Parquet's embedded mode_ The timestamp type of the DT column.