One of the main tasks of working with text data is to create many text-based features.
People may want to find content in a specific format in the text, such as e-mail existing in the text, or telephone numbers in large text.
Although it sounds cumbersome to implement the above functions, it can be made easier by using the Python regular expression module.
Suppose you want to find the number of punctuation marks in a specific article. Take Dickens' works as an example.
What do you usually do?
The simplest method is as follows:
target = [';','.',',','–'] string = "It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way – in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only."num _ points = 0num_puncts = 0for punct in target: if punct in string: num_puncts+=string.count(punct)print(num_puncts)------------------------------------------------------------------19
If there is no disposable re module, you need to use the above code. However, if there is a re module, only two lines of code are required:
import repattern = r"[;.,–]"print(len(re.findall(pattern,string)))------------------------------------------------------------------19
This paper discusses the most commonly used regular expression patterns and some regular expression functions that are often used.

What is a regular expression?
In short, regular expressions (regex) are used to explore fixed patterns in a given string.
The pattern we want to find can be anything.
You can create a pattern similar to finding email or mobile phone numbers. You can also create patterns that start with a and end with z.
In the above example:
import re pattern = r'[,;.,–]'print(len(re.findall(pattern,string)))
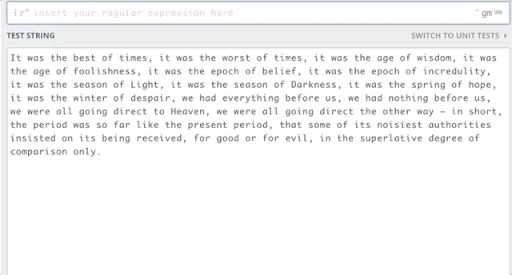
The pattern we want to find is r '[,;, –]'. This pattern can find any of the four characters you want. regex101 is a tool for testing patterns. When you apply a pattern to the target string, the following interface appears.
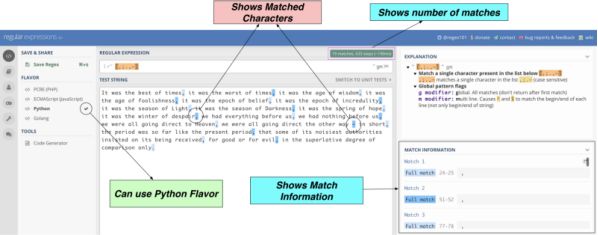
As shown in the figure,;., –, can be found in the target string as needed.
The above tools are used whenever you need to test regular expressions. This is much faster and much easier to debug than running python over and over again.
Now that we can find these patterns in the target string, how can we really create these patterns?

Create mode

When using regular expressions, the first thing you need to learn is how to create patterns.
Next, we will introduce some of the most commonly used modes one by one.
The simplest pattern you can think of is a simple string.
pattern = r'times' string = "It was the best of times, it was the worst of times." print(len(re.findall(pattern,string)))
But it's not very useful. To help create complex patterns, regular expressions provide special characters / operators. Let's look at these operators one by one. Please wait for gif to load.
1. [] operator
This is used in the first example to find a character that meets the conditions in these square brackets.
[abc] - will find all a, b, or c that appear in the text
[a-z] - will find all letters from a to z that appear in the text
[a-z0 – 9A-Z] - finds all uppercase letters from a to Z, lowercase letters from a to Z, and numbers from 0 to 9 that appear in the text.

You can easily run the following code in Python:
pattern = r'[a-zA-Z]' string = "It was the best of times, it was the worst of times." print(len(re.findall(pattern,string)))
Except findall, regular expressions have many other functions, which will be covered later.
2. Point operator
Dot operator (.) Used to match any character except the newline character.
The biggest advantage of operators is that they can be used together.
For example, you want to find a six letter substring in a string that starts with a small D or an uppercase D and ends with the letter e.
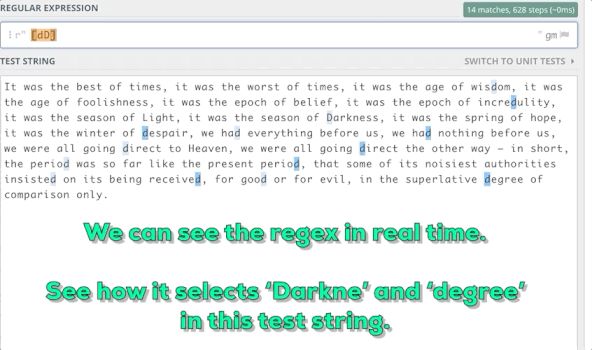
3. Some meta sequences
When using regular expressions, some patterns are often used. Therefore, regular expressions create some shortcuts for these patterns. The most common shortcuts are as follows:
\w. Match any letters, numbers, or underscores. Equivalent to [a-zA-Z0 – 9_]
\W. Match anything except letters, numbers, or underscores.
\d. Match any decimal number. Equivalent to [0 – 9].
\D. Matches any number except decimal.
4. Plus sign and star operator

The dot operator is simply used to get a single instance of any character. What if you want to find more examples?
The plus sign + is used to represent one or more instances of the leftmost character.
The asterisk * is used to represent 0 or more instances of the leftmost character.
For example, if you want to find all substrings that start with d and end with E, there can be no or multiple characters between d and E. We can use: d\w*e
If we want to find all substrings that start with d and end with e, and there is at least one character between d and e, we can use: d\w+e
You can also use a more general method: use {}
\w{n} - repeat \ w exactly n times.
\w{n,} - repeat \ w at least N times, or more.
\w{n1, n2} - repeat \ w at least n1 times, but no more than n2 times.
5. ^ caret and $Dollar sign.
^The caret matches the beginning of the string, while the dollar sign matches the end of the string.
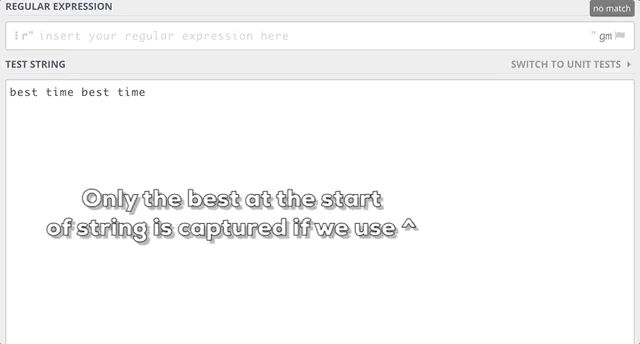
6. Word boundaries
This is an important concept.
Have you noticed that in the above example, the substring is always matched, not the word?
What if you want to find all the words that start with d?
Can I use d\w * mode? Let's try it with network tools.

Regular expression function
So far, only the findall function in the re package has been used. In fact, there are many other functions. Let's introduce them one by one.
1. findall
findall has been used above. This is the one I use most often. Let's formally understand this function.
Input: mode and test string
Output: list of strings.
#USAGE: pattern = r'[iI]t' string = "It was the best of times, it was the worst of times." matches = re.findall(pattern,string) for match in matches: print(match)------------------------------------------------------------ It it
2. Search

Input: mode and test string
Output: first matched position object.
#USAGE: pattern = r'[iI]t'string = "It was the best of times, it was the worst of times." location = re.search(pattern,string)print(location) ------------------------------------------------------------<_sre.SRE_Match object; span=(0, 2), match='It'>
The following programming can be used to obtain the data of the location object:
print(location.group())------------------------------------------------------------'It'
3. Replacement
This function is also important. When using natural language processors, sometimes you need to replace integers with X, or you may need to edit some files. Search and replace in any text editor can be done.
Input: search mode, replace mode and target string
Output: substitution strings
string = "It was the best of times, it was the worst of times."string = re.sub(r'times', r'life', string)print(string)------------------------------------------------------------It was the best of life, it was the worst of life.

case study
Regular expressions are used in many situations that require validation. We may see a hint on the website like "this is not a valid email address". Although you can use multiple if and else conditions to write such hints, regular expressions may have more advantages.
1.PAN No

In the United States, SSN (Social Security number) is used for tax identification, while in India, PAN is used for tax identification. The basic verification standard of PAN is that all letters above must be capitalized, and the order of characters is as follows:
<char><char><char><char><char><digit><digit><digit><digit><char>
So the question is:
Is "ABcDE1234L" a valid PAN number?
If there is no regular expression, how to answer this question? You might write a for loop and do a traversal search. But if you use regular expressions, it's as simple as this:
match=re.search(r'[A-Z]{5}[0–9]{4}[A-Z]','ABcDE1234L')if match: print(True)else: print(False)-----------------------------------------------------------------False2. Find the domain name

Sometimes we have to find a phone number, e-mail address or domain name from a huge text document.
For example, suppose you have the following text:
<div class="reflist" style="list-style-type: decimal;"><ol class="references"><li id="cite_note-1"><span class="mw-cite-backlink"><b>^ ["Train (noun)"](http://www.askoxford.com/concise_oed/train?view=uk). <i>(definition – Compact OED)</i>. Oxford University Press<span class="reference-accessdate">. Retrieved 2008-03-18</span>.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.atitle=Train+%28noun%29&rft.genre=article&rft_id=http%3A%2F%2Fwww.askoxford.com%2Fconcise_oed%2Ftrain%3Fview%3Duk&rft.jtitle=%28definition+%E2%80%93+Compact+OED%29&rft.pub=Oxford+University+Press&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span></li><li id="cite_note-2"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Atchison, Topeka and Santa Fe Railway (1948). <i>Rules: Operating Department</i>. p. 7.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Atchison%2C+Topeka+and+Santa+Fe+Railway&rft.aulast=Atchison%2C+Topeka+and+Santa+Fe+Railway&rft.btitle=Rules%3A+Operating+Department&rft.date=1948&rft.genre=book&rft.pages=7&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li><li id="cite_note-3"><span class="mw-cite-backlink"><b>^ [Hydrogen trains](http://www.hydrogencarsnow.com/blog2/index.php/hydrogen-vehicles/i-hear-the-hydrogen-train-a-comin-its-rolling-round-the-bend/)</span></li><li id="cite_note-4"><span class="mw-cite-backlink"><b>^ [Vehicle Projects Inc. Fuel cell locomotive](http://www.bnsf.com/media/news/articles/2008/01/2008-01-09a.html)</span></li><li id="cite_note-5"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Central Japan Railway (2006). <i>Central Japan Railway Data Book 2006</i>. p. 16.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Central+Japan+Railway&rft.aulast=Central+Japan+Railway&rft.btitle=Central+Japan+Railway+Data+Book+2006&rft.date=2006&rft.genre=book&rft.pages=16&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li><li id="cite_note-6"><span class="mw-cite-backlink"><b>^ ["Overview Of the existing Mumbai Suburban Railway"](http://web.archive.org/web/20080620033027/http://www.mrvc.indianrail.gov.in/overview.htm). _Official webpage of Mumbai Railway Vikas Corporation_. Archived from [the original](http://www.mrvc.indianrail.gov.in/overview.htm) on 2008-06-20<span class="reference-accessdate">. Retrieved 2008-12-11</span>.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.atitle=Overview+Of+the+existing+Mumbai+Suburban+Railway&rft.genre=article&rft_id=http%3A%2F%2Fwww.mrvc.indianrail.gov.in%2Foverview.htm&rft.jtitle=Official+webpage+of+Mumbai+Railway+Vikas+Corporation&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span></li></ol></div>
You need to find all the domain names here from the text above - askoxford com; bnsf. com; hydrogencarsnow. com; mrvc. indianrail. gov.in; http://web.archive.org
What should I do?
match=re.findall(r'http(s:|:)\/\/(www.|ww2.|)([0-9a-z.A-Z-]*\.\w{2,3})',string)for elem in match: print(elem)--------------------------------------------------------------------(':', 'www.', 'askoxford.com')(':', 'www.', 'hydrogencarsnow.com')(':', 'www.', 'bnsf.com')(':', '', 'web.archive.org')(':', 'www.', 'mrvc.indianrail.gov.in')(':', 'www.', 'mrvc.indianrail.gov.in')The or operator is used here. match returns tuples and retains the pattern part in ().
3. Find email address:
The following regular expression is used to find an e-mail address in long text.
match=re.findall(r'([\w0-9-._]+@[\w0-9-.]+[\w0-9]{2,3})',string)
These are high-level examples, and the information provided is enough to help you understand these examples.

conclusion

Although regular expressions look daunting, they are highly flexible in data manipulation, creating features, and finding patterns.
