Code Intelligence: Problems and Solutions
Today, the natural language processing revolution is triggered by the large model based on pre training, and the code intelligence technology is also developing rapidly.
So, what is code intelligence doing? Maybe many students will have more science fiction ideas, such as programmers going to lose their jobs.
However, in fact, many jobs are not so mysterious and very basic. So what problems do we use code intelligence to solve?
- Determine whether the two pieces of code implement similar functions
- Search for the code most similar to the current snippet
- Check the code for bug s
- Automatically fix bug s in code
- Automatically write comments for a piece of code
- Recommend the most similar code snippet based on the text
- Generate code from text
Do you think it's more mysterious after watching it? How can such a difficult problem be solved?
To be honest, each of these sub problems is very difficult, even for human beings.
However, just as human beings have learned step by step, machines are constantly improving. What we need is not necessarily a universal robot God, but also ordinary robots like us. They have great limitations, but they can help us reduce a lot of workload.
Moreover, in the last section, we will reveal that the method to deal with so many and so complex problems is very simple. We can do it with only one model.
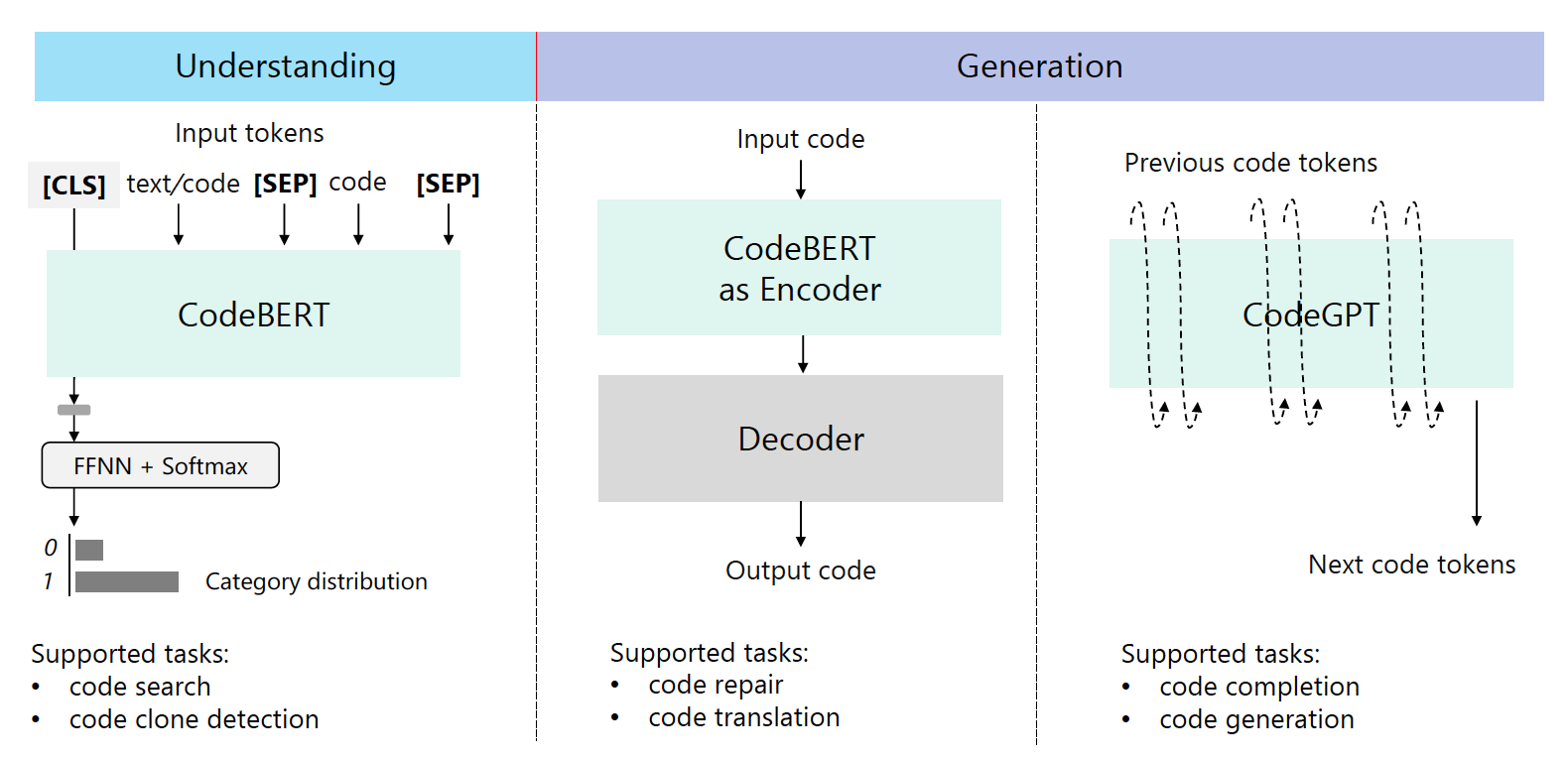
Let's take a detailed look at the details of these problems.
Problem: Clone Detection
Starting from the ground, the code intelligence task starts with clone detection.
The so-called clone detection is to find code similar in writing and function.
Don't underestimate code repetition, which will significantly reduce the effectiveness of code intelligence training.
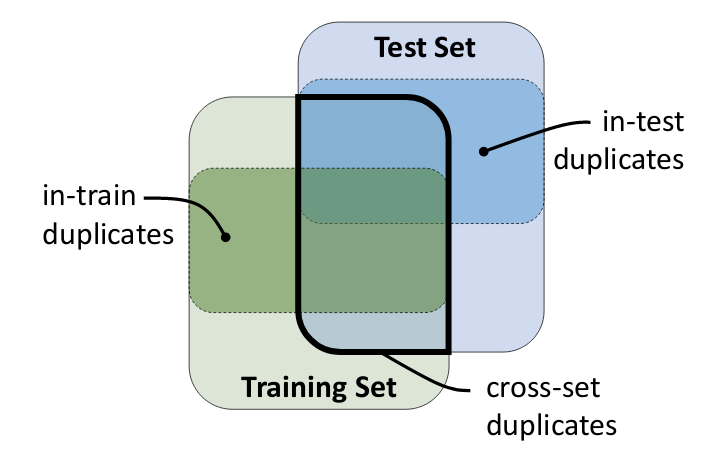
Let's look at the following figure. There are repetitions in the training set and in the test set, but there are still repetitions in their intersection. A detailed analysis is given in the paper the advantage effects of code duplication in machine learning models of code.
Predict whether the two pieces of code are similar
The following example is from BigCloneBench dataset The address of the thesis is: https://arxiv.org/pdf/2002.08653.pdf
Let's give a few examples to see what is similar:
Code 1:
private StringBuffer encoder(String arg) {
if (arg == null) {
arg = "";
}
MessageDigest md5 = null;
try {
md5 = MessageDigest.getInstance("MD5");
md5.update(arg.getBytes(SysConstant.charset));
} catch (Exception e) {
e.printStackTrace();
}
return toHex(md5.digest());
}
Code 2:
public String kodetu(String testusoila) {
MessageDigest md = null;
try {
md = MessageDigest.getInstance("SHA");
md.update(testusoila.getBytes("UTF-8"));
} catch (NoSuchAlgorithmException e) {
new MezuLeiho("Ez da zifraketa algoritmoa aurkitu", "Ados", "Zifraketa Arazoa", JOptionPane.ERROR_MESSAGE);
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
new MezuLeiho("Errorea kodetzerakoan", "Ados", "Kodeketa Errorea", JOptionPane.ERROR_MESSAGE);
e.printStackTrace();
}
byte raw[] = md.digest();
String hash = (new BASE64Encoder()).encode(raw);
return hash;
}
The string for code 2 is written in Basque. The algorithms they use are also different, and there are also differences in space judgment and exception handling, but we think they are very similar and belong to the same or highly similar clone recognition.
Let's take another pair of examples:
Code 1:
public static void test(String args[]) {
int trace;
int bytes_read = 0;
int last_contentLenght = 0;
try {
BufferedReader reader;
URL url;
url = new URL(args[0]);
URLConnection istream = url.openConnection();
last_contentLenght = istream.getContentLength();
reader = new BufferedReader(new InputStreamReader(istream.getInputStream()));
System.out.println(url.toString());
String line;
trace = t2pNewTrace();
while ((line = reader.readLine()) != null) {
bytes_read = bytes_read + line.length() + 1;
t2pProcessLine(trace, line);
}
t2pHandleEventPairs(trace);
t2pSort(trace, 0);
t2pExportTrace(trace, new String("pngtest2.png"), 1000, 700, (float) 0, (float) 33);
t2pExportTrace(trace, new String("pngtest3.png"), 1000, 700, (float) 2.3, (float) 2.44);
System.out.println("Press any key to contiune read from stream !!!");
System.out.println(t2pGetProcessName(trace, 0));
System.in.read();
istream = url.openConnection();
if (last_contentLenght != istream.getContentLength()) {
istream = url.openConnection();
istream.setRequestProperty("Range", "bytes=" + Integer.toString(bytes_read) + "-");
System.out.println(Integer.toString(istream.getContentLength()));
reader = new BufferedReader(new InputStreamReader(istream.getInputStream()));
while ((line = reader.readLine()) != null) {
System.out.println(line);
t2pProcessLine(trace, line);
}
} else System.out.println("File not changed !");
t2pDeleteTrace(trace);
} catch (MalformedURLException e) {
System.out.println("MalformedURLException !!!");
} catch (IOException e) {
System.out.println("File not found " + args[0]);
}
;
}
Code 2:
private static String loadUrlToString(String a_url) throws IOException {
URL l_url1 = new URL(a_url);
BufferedReader br = new BufferedReader(new InputStreamReader(l_url1.openStream()));
String l_content = "";
String l_ligne = null;
l_content = br.readLine();
while ((l_ligne = br.readLine()) != null) {
l_content += AA.SL + l_ligne;
}
return l_content;
}
Although this does not involve small languages, it is obvious that the code length varies greatly. However, we still think they are similar.
Let's look at a pair of dissimilar:
Code 1:
private void setNodekeyInJsonResponse(String service) throws Exception {
String filename = this.baseDirectory + service + ".json";
Scanner s = new Scanner(new File(filename));
PrintWriter fw = new PrintWriter(new File(filename + ".new"));
while (s.hasNextLine()) {
fw.println(s.nextLine().replaceAll("NODEKEY", this.key));
}
s.close();
fw.close();
(new File(filename + ".new")).renameTo(new File(filename));
}
Code 2:
public void transform(String style, String spec, OutputStream out) throws IOException {
URL url = new URL(rootURL, spec);
InputStream in = new PatchXMLSymbolsStream(new StripDoctypeStream(url.openStream()));
transform(style, in, out);
in.close();
}
If it is not similar, it will not be explained.
BigCloneBench data set provides two pieces of code and whether they are similar to the results of manual marking.
The data is divided into train txt, valid. txt, test. Txt three sets, all of which have the same format:
idx1 idx2 0/1
idx1 and idx2 are two pieces of code in data The index value in jsonl, and the last one is whether they are similar to the manually marked value.
The code is saved in data In jsonl, the format is:
{"func":"code","idx":"idx value"}
We take the training set train Txt as an example, the first two lines are as follows:
13988825 8660836 0 80378 18548122 1
13988825 in data The corresponding structure in jsonl is as follows:
{"func": " private void setNodekeyInJsonResponse(String service) throws Exception {\n String filename = this.baseDirectory + service + \".json\";\n Scanner s = new Scanner(new File(filename));\n PrintWriter fw = new PrintWriter(new File(filename + \".new\"));\n while (s.hasNextLine()) {\n fw.println(s.nextLine().replaceAll(\"NODEKEY\", this.key));\n }\n s.close();\n fw.close();\n (new File(filename + \".new\")).renameTo(new File(filename));\n }\n", "idx": "13988825"}
8660836 corresponds to:
{"func": " public void transform(String style, String spec, OutputStream out) throws IOException {\n URL url = new URL(rootURL, spec);\n InputStream in = new PatchXMLSymbolsStream(new StripDoctypeStream(url.openStream()));\n transform(style, in, out);\n in.close();\n }\n", "idx": "8660836"}
And their results are not similar. As you can see, this example is the third example we just wrote above.
Search for the code segment with the most similar semantics to the current code segment
We use the POJ-104 data set of Li Ge and Li Shi's team of Peking University.
This dataset needs to be https://drive.google.com/uc?id=0B2i-vWnOu7MxVlJwQXN6eVNONUU to download.
Each code segment is described by an index, and then the code field is the complete code. Let's take an example:
{
"label":"1",
"index":"0",
"code":"
int f(int a,int x)
{
int count=1,i;
for(i=x;i<a;i++)
if(a%i==0)
count+=f(a/i,i);
if(i==a)
return count;
else
return 0;
}
void main()
{
int n,a;
scanf(\"%d\",&n);
for(;n>0;n--)
{
scanf(\"%d\",&a);
if(a==1||a==2)
printf(\"1\
\");
else
printf(\"%d\
\",f(a,2));
}
}
"
}
Then, the purpose of this task is to find the most similar code segment for a piece of code. Take top 2 as an example: the output example is as follows:
{"index": "0", "answers": ["3", "2"]}
{"index": "1", "answers": ["0", "4"]}
{"index": "2", "answers": ["0", "1"]}
{"index": "4", "answers": ["1", "5"]}
{"index": "3", "answers": ["4", "2"]}
{"index": "5", "answers": ["4", "3"]}
That is to say, for the code index 0, the most similar code segments are index 3 and 2
index 3 is as follows:
void qut(int a,int b); //????
int num=0; //?????????
int main()
{
int i,n,g[1000]; //?????????
cin>>n;
for(i=0;i<n;i++) //??????
cin>>g[i];
for(i=0;i<n;i++)
{
qut(g[i],1); //????
cout<<num<<endl;
num=0;
}
return 0;
}
void qut(int a,int b)
{
int i;
if (a>=b)
{
num++;
if (b==1)
b++;
for (i=b;i<=a;i++)
{
if (a%i==0)
{
qut(a/i,i); //??a%i==0,??
}
}
}
}
Problem: defect detection
The data set of defect detection is very simple and rough. It is a piece of marked code to identify whether there is a vulnerability.
Let's look at an example of loopholes:
{
"project":"FFmpeg",
"commit_id":"aba232cfa9b193604ed98f3fa505378d006b1b3b",
"target":1,
"func":"static int r3d_read_rdvo(AVFormatContext *s, Atom *atom)
{
R3DContext *r3d = s->priv_data;
AVStream *st = s->streams[0];
int i;
r3d->video_offsets_count = (atom->size - 8) / 4;
r3d->video_offsets = av_malloc(atom->size);
if (!r3d->video_offsets)
return AVERROR(ENOMEM);
for (i = 0; i < r3d->video_offsets_count; i++) {
r3d->video_offsets[i] = avio_rb32(s->pb);
if (!r3d->video_offsets[i]) {
r3d->video_offsets_count = i;
break;
}
av_dlog(s, \"video offset %d: %#x\
\", i, r3d->video_offsets[i]);
}
if (st->r_frame_rate.num)
st->duration = av_rescale_q(r3d->video_offsets_count,
(AVRational){st->r_frame_rate.den,
st->r_frame_rate.num},
st->time_base);
av_dlog(s, \"duration %\"PRId64\"\
\", st->duration);
return 0;
}
",
"idx":5
}
There is so much information. As for what line is what problem, there is no training concentration.
Of course, most of the data sets are still free of vulnerabilities, such as the first:
{"project": "FFmpeg", "commit_id": "973b1a6b9070e2bf17d17568cbaf4043ce931f51", "target": 0, "func": "static av_cold int vdadec_init(AVCodecContext *avctx)\n\n{\n\n VDADecoderContext *ctx = avctx->priv_data;\n\n struct vda_context *vda_ctx = &ctx->vda_ctx;\n\n OSStatus status;\n\n int ret;\n\n\n\n ctx->h264_initialized = 0;\n\n\n\n /* init pix_fmts of codec */\n\n if (!ff_h264_vda_decoder.pix_fmts) {\n\n if (kCFCoreFoundationVersionNumber < kCFCoreFoundationVersionNumber10_7)\n\n ff_h264_vda_decoder.pix_fmts = vda_pixfmts_prior_10_7;\n\n else\n\n ff_h264_vda_decoder.pix_fmts = vda_pixfmts;\n\n }\n\n\n\n /* init vda */\n\n memset(vda_ctx, 0, sizeof(struct vda_context));\n\n vda_ctx->width = avctx->width;\n\n vda_ctx->height = avctx->height;\n\n vda_ctx->format = 'avc1';\n\n vda_ctx->use_sync_decoding = 1;\n\n vda_ctx->use_ref_buffer = 1;\n\n ctx->pix_fmt = avctx->get_format(avctx, avctx->codec->pix_fmts);\n\n switch (ctx->pix_fmt) {\n\n case AV_PIX_FMT_UYVY422:\n\n vda_ctx->cv_pix_fmt_type = '2vuy';\n\n break;\n\n case AV_PIX_FMT_YUYV422:\n\n vda_ctx->cv_pix_fmt_type = 'yuvs';\n\n break;\n\n case AV_PIX_FMT_NV12:\n\n vda_ctx->cv_pix_fmt_type = '420v';\n\n break;\n\n case AV_PIX_FMT_YUV420P:\n\n vda_ctx->cv_pix_fmt_type = 'y420';\n\n break;\n\n default:\n\n av_log(avctx, AV_LOG_ERROR, \"Unsupported pixel format: %d\\n\", avctx->pix_fmt);\n\n goto failed;\n\n }\n\n status = ff_vda_create_decoder(vda_ctx,\n\n avctx->extradata, avctx->extradata_size);\n\n if (status != kVDADecoderNoErr) {\n\n av_log(avctx, AV_LOG_ERROR,\n\n \"Failed to init VDA decoder: %d.\\n\", status);\n\n goto failed;\n\n }\n\n avctx->hwaccel_context = vda_ctx;\n\n\n\n /* changes callback functions */\n\n avctx->get_format = get_format;\n\n avctx->get_buffer2 = get_buffer2;\n\n#if FF_API_GET_BUFFER\n\n // force the old get_buffer to be empty\n\n avctx->get_buffer = NULL;\n\n#endif\n\n\n\n /* init H.264 decoder */\n\n ret = ff_h264_decoder.init(avctx);\n\n if (ret < 0) {\n\n av_log(avctx, AV_LOG_ERROR, \"Failed to open H.264 decoder.\\n\");\n\n goto failed;\n\n }\n\n ctx->h264_initialized = 1;\n\n\n\n return 0;\n\n\n\nfailed:\n\n vdadec_close(avctx);\n\n return -1;\n\n}\n", "idx": 0}
Reasoning is also very easy. It is the result of giving 0 or 1 to each index:
0 0 1 1 2 1 3 0 4 0
Problem: Code auto repair
With the identification of code vulnerabilities, the further step is to learn to automatically repair the code.
The problem of automatic code repair is also very simple. One is the bug code, and the other is the repaired code.
Let's take an example:
The bug gy code is as follows:
public java.lang.String METHOD_1 ( ) { return new TYPE_1 ( STRING_1 ) . format ( VAR_1 [ ( ( VAR_1 . length ) - 1 ) ] . getTime ( ) ) ; }
After repair, it looks like this:
public java.lang.String METHOD_1 ( ) { return new TYPE_1 ( STRING_1 ) . format ( VAR_1 [ ( ( type ) - 1 ) ] . getTime ( ) ) ; }
It's really difficult to solve the algorithm. People seem to have a little trouble.
Question: Code Translation
For example, realize the translation between C# language and Java language. As long as we have a series of code written in C# and Java, we can learn and translate each other.
Let's look at a pair of examples.
Look at the C# code first:
public virtual ListSpeechSynthesisTasksResponse ListSpeechSynthesisTasks(ListSpeechSynthesisTasksRequest request){
var options = new InvokeOptions();
options.RequestMarshaller = ListSpeechSynthesisTasksRequestMarshaller.Instance;
options.ResponseUnmarshaller = ListSpeechSynthesisTasksResponseUnmarshaller.Instance;
return Invoke<ListSpeechSynthesisTasksResponse>(request, options);
}
Corresponding Java
public ListSpeechSynthesisTasksResult listSpeechSynthesisTasks(ListSpeechSynthesisTasksRequest request) {
request = beforeClientExecution(request);
return executeListSpeechSynthesisTasks(request);
}

Problem: write comments to the code
In the training material, there are codes and comments. The purpose of this task is to write comments for new codes. The evaluation index is the language accuracy of the generated annotation.
For this, we use the CodeSearchNet dataset.
The format of each record in this dataset is as follows:
- repo: warehouse name
- path: file name
- func_name: function or method name
- original_string: unprocessed source string
- Language: programming language
- code/function: code information
- code_tokens/function_tokens: Code result after word segmentation
- docstring: comment string information
- docstring_ Tokens: results after docstring word segmentation
- url: the unique identification number of the natural language
- idx: unique identification number of the code snippet
Let's take an example:
{"repo": "ciena-blueplanet/bunsen-core", "path": "src/reducer.js", "func_name": "", "original_string": "function
(state, action) {\n return _.defaults({\n isValidating: action.isValidating,\n lastAction: IS_VALIDA
TING\n }, state)\n }", "language": "javascript", "code": "function (state, action) {\n return _.defaults({
\n isValidating: action.isValidating,\n lastAction: IS_VALIDATING\n }, state)\n }", "code_tokens":
["function", "(", "state", ",", "action", ")", "{", "return", "_", ".", "defaults", "(", "{", "isValidating", ":"
, "action", ".", "isValidating", ",", "lastAction", ":", "IS_VALIDATING", "}", ",", "state", ")", "}"], "docstrin
g": "Update is validating result\n@param {State} state - state to update\n@param {Action} action - action\n@retur
ns {State} - updated state", "docstring_tokens": ["Update", "is", "validating", "result"], "sha": "993c67e314e2b7
5003a1ff4c2f0cb667715562b2", "url": "https://github.com/ciena-blueplanet/bunsen-core/blob/993c67e314e2b75003a1ff4
c2f0cb667715562b2/src/reducer.js#L394-L399", "partition": "train"}
For the generated natural language, we use the method of ORANGE: a Method for Evaluating Automatic Evaluation Metrics for Machine Translation.
Problem: match the most appropriate code segment for natural language text
We still use the CodeSearchNet dataset in the previous section.
The results of this search are similar to the following:
{"url": "url0", "answers": [10,11,12,13,14]}
{"url": "url1", "answers": [10,12,11,13,14]}
{"url": "url2", "answers": [13,11,12,10,14]}
{"url": "url3", "answers": [10,14,12,13,11]}
{"url": "url4", "answers": [10,11,12,13,14]}
With UI, the general effect is as follows:

Or this:

Problem: generate code from natural language
This is the ultimate task, which is to generate a piece of code according to a text description.
The format is very simple, just a piece of code and a piece of text.
Let's take an example of a training sample:
{"code": "void function ( Binder arg0 ) { EventBus loc0 = new EventBus ( ) ; AmbariEventPublisher loc1 = new AmbariEventPublisher ( ) ; repla
ceEventBus ( AmbariEventPublisher . class , loc1 , loc0 ) ; arg0 . bind ( AmbariEventPublisher . class ) . toInstance ( loc1 ) ; }", "nl": "force the eventb us from ambarievent publisher to be serialand synchronous . concode_field_sep PlaceHolder placeHolder concode_field_sep void registerAlertListeners concode_elem_sep EventBus synchronizeAlertEventPublisher concode_elem_sep void replaceEventBus concode_elem_sep void registerAmbariListeners"}
This NL part is a little messy. There is no way. In order to increase the amount of data, there are not so many people to make accurate marks.
Let's take another look:
{"code": "byte [ ] function ( Class < ? > arg0 , Configuration arg1 ) { return AuthenticationTokenSerializer . serialize ( org . apache . acc
umulo . core . client . mapreduce . lib . impl . ConfiguratorBase . getAuthenticationToken ( arg0 , arg1 ) ) ; }", "nl": "do n't use this . n
o , really , do n't use this . you already have an authenticationtoken with org.apache.accumulo.core.client.mapreduce.lib.impl.configuratorba
se #getauthenticationtoken class , configuration . you do n't need to construct it yourself . gets the password from the configuration . warn
ing : the password is stored in the configuration and shared with all mapreduce tasks ; it is base64 encoded to provide a charset safe conver
sion to a string , and is not intended to be secure . concode_field_sep PlaceHolder placeHolder concode_field_sep String getPrincipal concode
_elem_sep void setLogLevel concode_elem_sep Level getLogLevel concode_elem_sep Boolean isConnectorInfoSet concode_elem_sep String getTokenCla
ss concode_elem_sep void setZooKeeperInstance concode_elem_sep void setMockInstance concode_elem_sep Instance getInstance concode_elem_sep St
ring enumToConfKey concode_elem_sep void setConnectorInfo"}
Isn't the quality any better? This is what a CONCODE dataset looks like.
Solution: multi task learning based on large-scale pre training model
402 years ago, when Nurhachi was besieged by multiple armies of the Ming Dynasty, he adopted the tactics of "depending on how many routes you come, I only go all the way" and won the war of Sarhu.
We also learn from the wisdom of the ancients. As your data set is ever-changing, our tool only uses one - large-scale pre training model.
The following is a brief history of the pre training model:
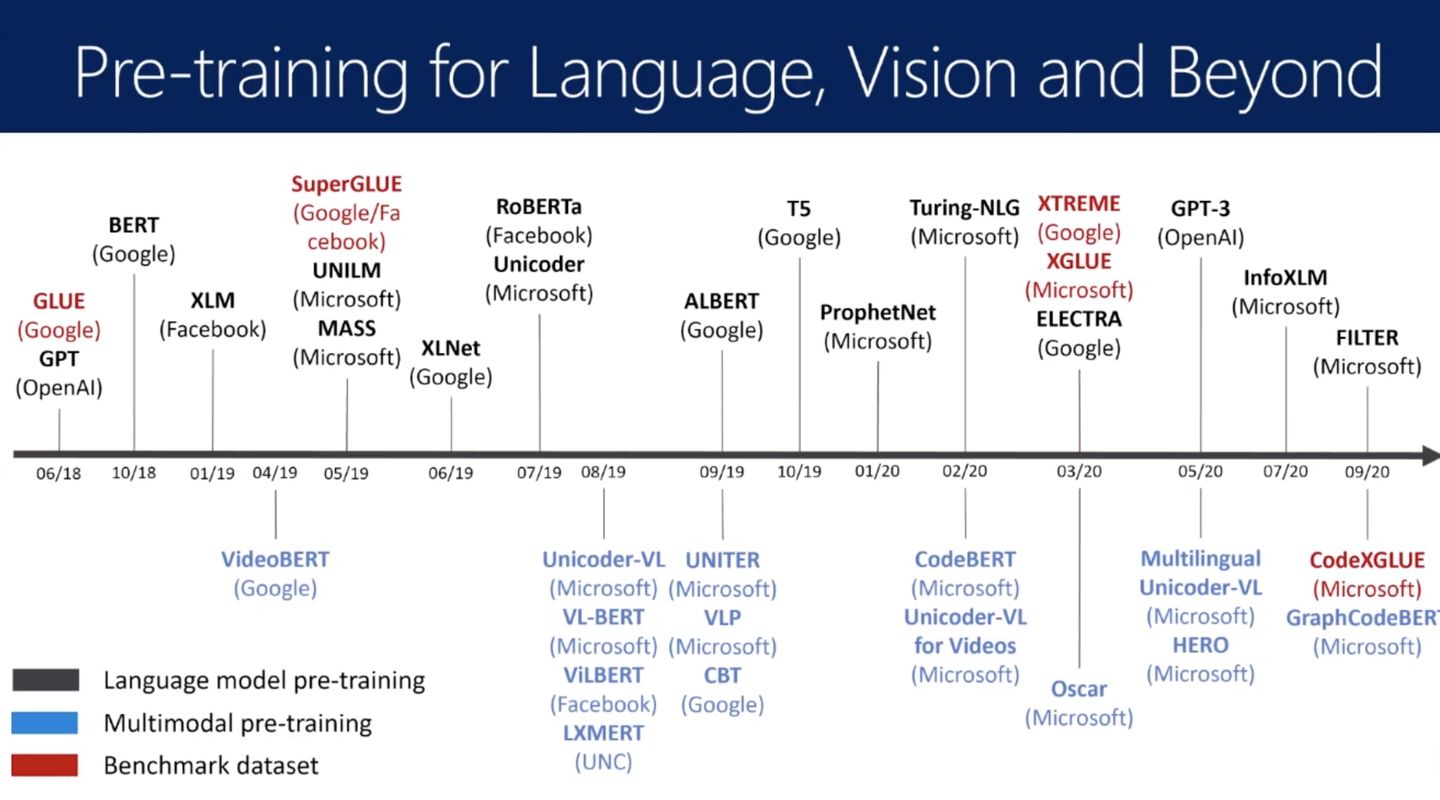
Take Microsoft's codebert model shown at the beginning as an example. We need to deal with the most complex code generation task above. We can do it with one command:
python -m torch.distributed.launch --nproc_per_node=$PER_NODE_GPU run.py \
--data_dir=$DATADIR \
--langs=$LANG \
--output_dir=$OUTPUTDIR \
--pretrain_dir=$PRETRAINDIR \
--log_file=$LOGFILE \
--model_type=gpt2 \
--block_size=512 \
--do_train \
--node_index 0 \
--gpu_per_node $PER_NODE_GPU \
--learning_rate=5e-5 \
--weight_decay=0.01 \
--evaluate_during_training \
--per_gpu_train_batch_size=6 \
--per_gpu_eval_batch_size=12 \
--gradient_accumulation_steps=2 \
--num_train_epochs=30 \
--logging_steps=100 \
--save_steps=5000 \
--overwrite_output_dir \
--seed=42
If you use two NVIDIA P100 GPU cards, you can finish training in about 22 hours.
Reasoning is also done in one sentence:
python -u run.py \
--data_dir=$DATADIR \
--langs=$LANG \
--output_dir=$OUTPUTDIR \
--pretrain_dir=$PRETRAINDIR \
--log_file=$LOGFILE \
--model_type=gpt2 \
--block_size=512 \
--do_infer \
--logging_steps=100 \
--seed=42
It can be done in about 40 minutes with only one P100 card.
With the above foundation, we can play games. The data sets described above are all the questions of the competition:
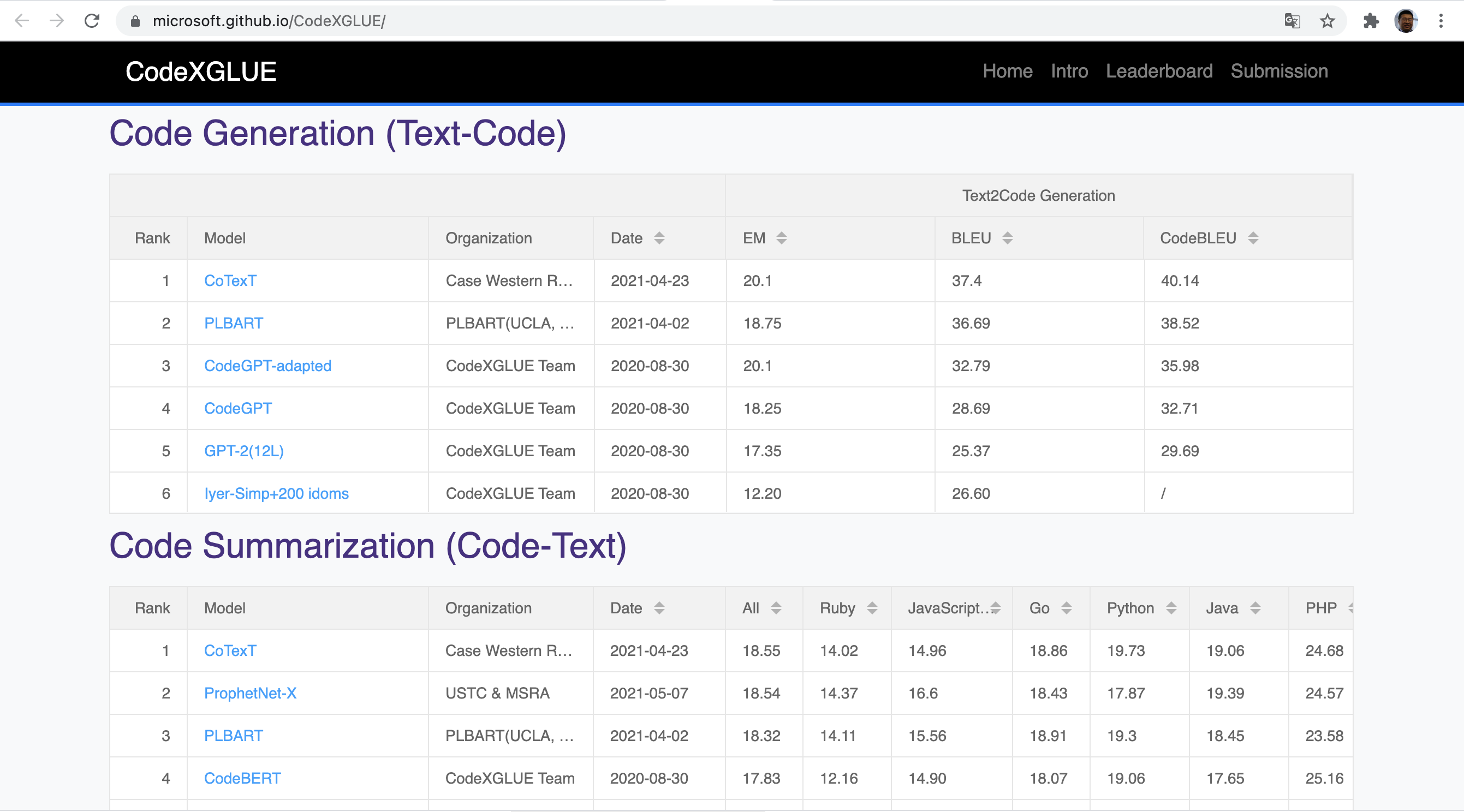
The data sets mentioned above can be found in https://github.com/microsoft/CodeXGLUE Download to.
Welcome to the world of code intelligence!
Appendix: Quick Start Guide
Fang Weng said: you'll never know what you're going to do on paper.
Let's go to the ground and run the training and reasoning of code intelligent model ~ ~
- Step 1: install the transformers framework, because codebert is based on this framework:
pip install transformers --user
- Step 2: install PyTorch or Tensorflow as the back end of Transformers. At the time point of July 5, 2021, the required PyTorch version is at least 1.5.0. If the driver can handle it, simply install the latest one:
pip install torch torchvision torchtext torchaudio --user
- The third step is to download Microsoft's data set
git clone https://github.com/microsoft/CodeXGLUE
- Step 4, let's play BigCloneBench first
Go to the code code / clone detection bigclonebench / code directory and run:
python run.py --output_dir=./saved_models --model_type=roberta --config_name=microsoft/codebert-base --model_name_or_path=microsoft/codebert-base --tokenizer_name=roberta-base --do_train --train_data_file=../dataset/train.txt --eval_data_file=../dataset/valid.txt --test_data_file=../dataset/test.txt --epoch 2 --block_size 400 --train_batch_size 16 --eval_batch_size 32 --learning_rate 5e-5 --max_grad_norm 1.0 --evaluate_during_training --seed 123456 2>&1| tee train.log
Then the training runs:
07/05/2021 16:29:24 - INFO - __main__ - ***** Running training ***** 07/05/2021 16:29:24 - INFO - __main__ - Num examples = 90102 07/05/2021 16:29:24 - INFO - __main__ - Num Epochs = 2 07/05/2021 16:29:24 - INFO - __main__ - Instantaneous batch size per GPU = 8 07/05/2021 16:29:24 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 16 07/05/2021 16:29:24 - INFO - __main__ - Gradient Accumulation steps = 1 07/05/2021 16:29:24 - INFO - __main__ - Total optimization steps = 11264
It takes about 40 minutes to train on two V100 cards.
The training is followed by verification, and the best results will be saved in the checkpoint for reasoning
07/05/2021 17:10:04 - INFO - __main__ - ***** Running evaluation ***** 40950/41541 [00:10<00:00, 2785.61it/s] 07/05/2021 17:10:04 - INFO - __main__ - Num examples = 41541 07/05/2021 17:10:04 - INFO - __main__ - Batch size = 32 07/05/2021 17:16:05 - INFO - __main__ - ***** Eval results ***** 07/05/2021 17:16:05 - INFO - __main__ - eval_f1 = 0.9531 07/05/2021 17:16:05 - INFO - __main__ - eval_precision = 0.9579 07/05/2021 17:16:05 - INFO - __main__ - eval_recall = 0.9484 07/05/2021 17:16:05 - INFO - __main__ - eval_threshold = 0.97 07/05/2021 17:16:06 - INFO - __main__ - ******************** 07/05/2021 17:16:06 - INFO - __main__ - Best f1:0.9531 07/05/2021 17:16:06 - INFO - __main__ - ******************** 07/05/2021 17:16:08 - INFO - __main__ - Saving model checkpoint to ./saved_models/checkpoint-best-f1/model.bin
After two rounds of training at a time, the effect of the second round is increased to more than 0.97:
07/05/2021 17:56:43 - INFO - __main__ - ***** Running evaluation ***** 40950/41541 [00:12<00:00, 3535.62it/s] 07/05/2021 17:56:43 - INFO - __main__ - Num examples = 41541 07/05/2021 17:56:43 - INFO - __main__ - Batch size = 32 [W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool) [W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool) [W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool) [W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool) 07/05/2021 18:02:44 - INFO - __main__ - ***** Eval results ***** 07/05/2021 18:02:44 - INFO - __main__ - eval_f1 = 0.9701 07/05/2021 18:02:44 - INFO - __main__ - eval_precision = 0.9772 07/05/2021 18:02:44 - INFO - __main__ - eval_recall = 0.9633 07/05/2021 18:02:44 - INFO - __main__ - eval_threshold = 0.97 07/05/2021 18:02:45 - INFO - __main__ - ******************** 07/05/2021 18:02:45 - INFO - __main__ - Best f1:0.9701 07/05/2021 18:02:45 - INFO - __main__ - ******************** 07/05/2021 18:02:47 - INFO - __main__ - Saving model checkpoint to ./saved_models/checkpoint-best-f1/model.bin
Then let's use the trained model for reasoning:
python run.py \
--output_dir=./saved_models \
--model_type=roberta \
--config_name=microsoft/codebert-base \
--model_name_or_path=microsoft/codebert-base \
--tokenizer_name=roberta-base \
--do_eval \
--do_test \
--train_data_file=../dataset/train.txt \
--eval_data_file=../dataset/valid.txt \
--test_data_file=../dataset/test.txt \
--epoch 2 \
--block_size 400 \
--train_batch_size 16 \
--eval_batch_size 32 \
--learning_rate 5e-5 \
--max_grad_norm 1.0 \
--evaluate_during_training \
--seed 123456 2>&1| tee test.log
Finally, we run evaluator Py to view the test results:
python ../evaluator/evaluator.py -a ../dataset/test.txt -p saved_models/predictions.txt
The output is as follows:
{'Recall': 0.9677421599288263, 'Prediction': 0.9557057904236594, 'F1': 0.9616080550111168}
The accuracy rate was 0.956 and the recall rate was 0.968, which was pretty good ~
Compare with the leaderboard of CodeXGLUE:
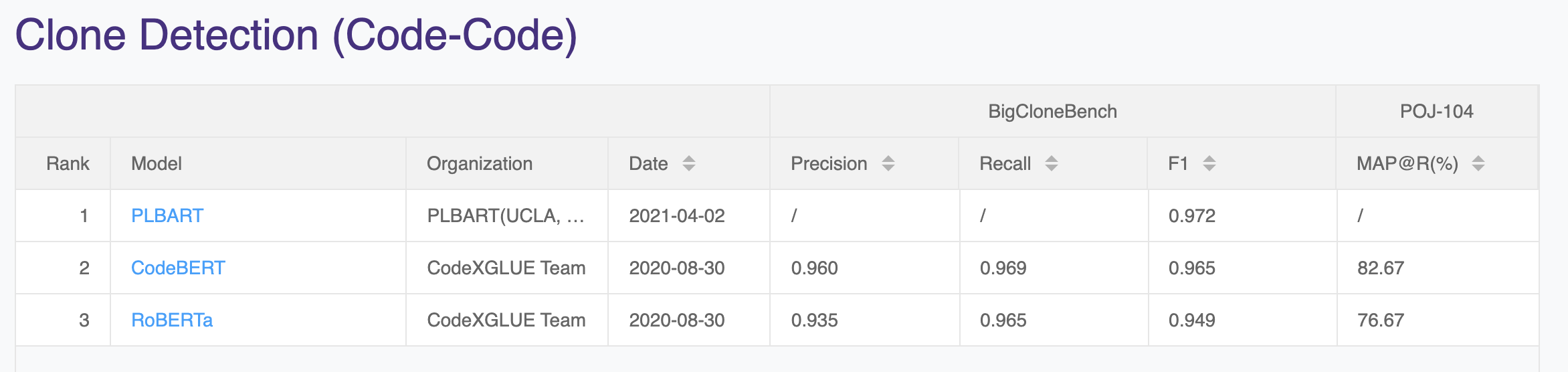
It is basically consistent with the results of CodeBert on the list
GraphCodeBert
To improve performance, we can replace CodeBert with GraphCodeBert
Let's download the code of GraphCodeBert first:
git clone https://github.com/microsoft/CodeBERT
Then go to the GraphCodeBERT/clonedetection directory and unzip the dataset zip:
unzip dataset.zip
Then you can train graphcodebert as you train codebert:
mkdir saved_models
python run.py \
--output_dir=saved_models \
--config_name=microsoft/graphcodebert-base \
--model_name_or_path=microsoft/graphcodebert-base \
--tokenizer_name=microsoft/graphcodebert-base \
--do_train \
--train_data_file=dataset/train.txt \
--eval_data_file=dataset/valid.txt \
--test_data_file=dataset/test.txt \
--epoch 1 \
--code_length 512 \
--data_flow_length 128 \
--train_batch_size 16 \
--eval_batch_size 32 \
--learning_rate 2e-5 \
--max_grad_norm 1.0 \
--evaluate_during_training \
--seed 123456 2>&1| tee saved_models/train.log
The above parameters are adjusted according to four V100 GPU s. If there are only two V100, you can set the – code_ Change length to 256
Codebert takes about 40 minutes and GraphCodeBert takes about six and a half hours.
Then we reasoned:
python run.py --output_dir=saved_models --config_name=microsoft/graphcodebert-base --model_name_or_path=microsoft/graphcodebert-base --tokenizer_name=microsoft/graphcodebert-base --do_eval --do_test --train_data_file=dataset/train.txt --eval_data_file=dataset/valid.txt --test_data_file=dataset/test.txt --epoch 1 --code_length 256 --data_flow_length 128 --train_batch_size 16 --eval_batch_size 32 --learning_rate 2e-5 --max_grad_norm 1.0 --evaluate_during_training --seed 123456 2>&1| tee saved_models/test.log
Finally, let's interpret the results:
python evaluator/evaluator.py -a dataset/test.txt -p saved_models/predictions.txt 2>&1| tee saved_models/score.log
The results are as follows:
{'Recall': 0.9589415798936043, 'Prediction': 0.962620653900429, 'F1': 0.9607703728051462}