FileOutputStream fileOutputStream =
new FileOutputStream("module-11\\data\\out.txt");
fileOutputStream.write(100);
fileOutputStream.write(35);
FileInputStream fileInputStream =
new FileInputStream("module-11\\data\\out.txt");
System.out.println(fileInputStream.read());// 100
System.out.println(fileInputStream.read());// 35First created an out Txt file, write two bytes of content. Because the most basic format of the file is 01 binary, this is out Txt, which stores binary data of 100 and 35. Open k'k with binary viewer

Open out with binaryViewer Txt, view the binary data inside. You can see:
64 is a hexadecimal number, accounting for one byte. It is converted to binary: 01100100 is exactly 100,
23 is a hexadecimal number, accounting for one byte. It is converted to binary: 00100011 is exactly 35,
It also verifies that I was really out Txt is stored in binary.
It is often said that UTF-8 is used, Open file with GBK encoding (Note: open the file) what does it mean? They just read the basic binary data and will not change the data itself. According to their coding rules, they will read byte data and convert it into characters. Here, ASCII coding reads 01100100, and then according to ASCII coding, the binary corresponding character is d, similarly, 001000 11 corresponding characters #.
When you open a text file, you must select an encoding format. Different encoding formats sometimes lead to different characters
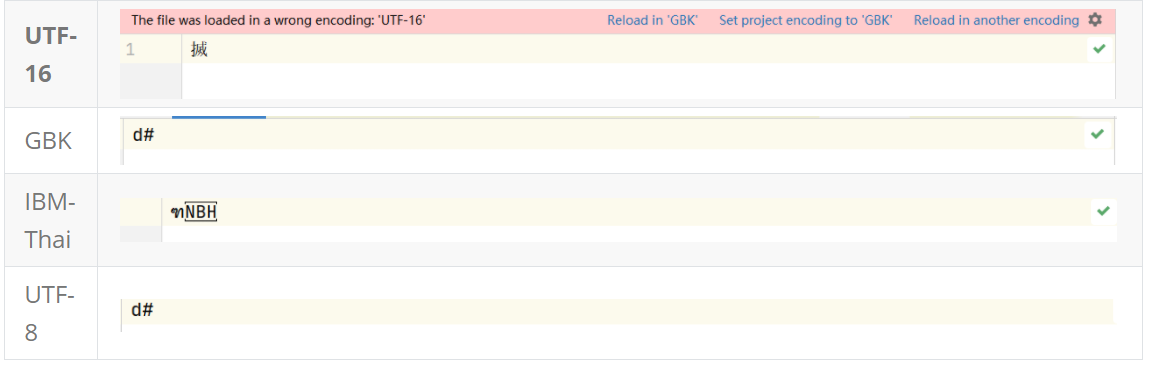
But no matter what code we open out Txt source file, the binary data obtained must still be 100, 35 we just saved
FileInputStream fileInputStream =
new FileInputStream("module-11\\data\\out.txt");
System.out.println(fileInputStream.read());//100
System.out.println(fileInputStream.read());//35
When we reread the file, we can see that the data source has not changed
Conversely, we create A txt file and write it into the Chinese character "Zhong". When we save it, You can choose different codes to save (note that here is the saved file). Different codes basically lead to different saved file results (different file results here refer to different binary data of the file), so this forms our common garbled code (save the file with A code and open the file with B code). Therefore, if we save the file with what code, the open file must also be opened in the corresponding coding format, otherwise it will form garbled code.
Explanation of the relationship between Unicode and GBK, UTF-8 and UTF-16:
Unicode is a mapping table used to store languages all over the world. All characters in the world are encoded by Unicode. GBK, UTF-8 and UTF-16 are one of the implementation methods of Unicode.

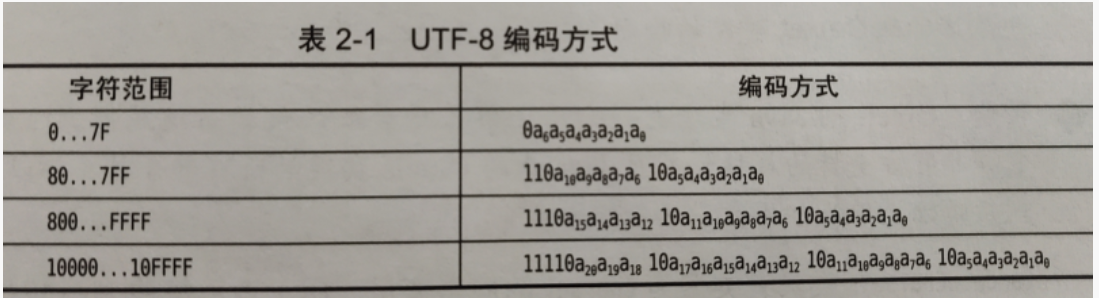
Look at the encoding method of UTF-8. (UTF-8 encodes Unicode. See the following relationship)
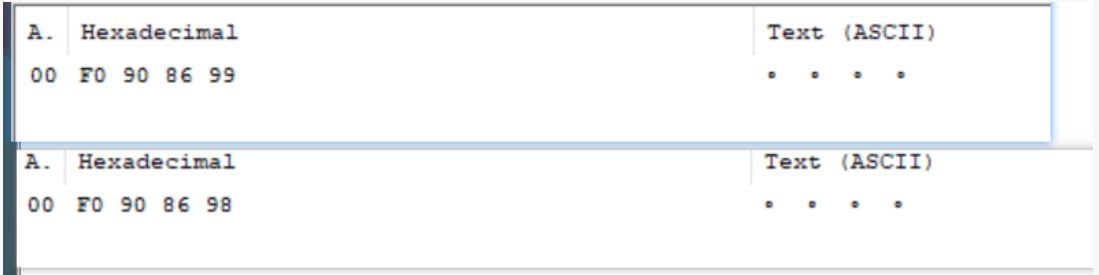
Two Unicode characters are found, but it seems that they are not supported in many places, showing that they are garbled after copying (special attention should be paid here. Although these two characters are garbled, it is only because the software does not support the visualization of these two Unicode characters), they are saved in text in UTF-8 format respectively.
-
𐆙 U+10199
-
𐆘 U+10198
Just copy it and save it as UTF-8, and then view the binary file.

-
These two characters are just that the software does not support visualization, but the coding is still UTF-8, as shown in the figure below.
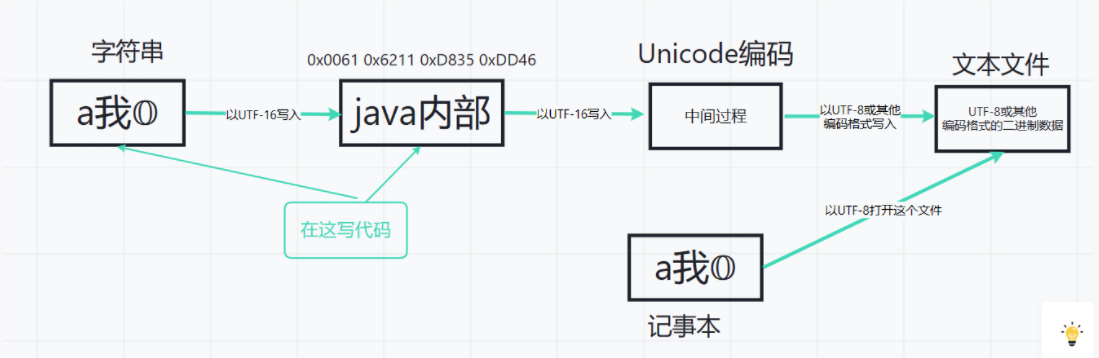
Suppose we build one on a window desktop txt file, and then write the file in it. At this time, the file can be saved in any format. According to different formats, the binary data of the file is also different, because there are certain rules for coding. We can imagine that every written character is U +????? (Unicode code points), and then convert these characters (or imagine them as Unicode code points) into 01 binary computer stored data according to different coding methods. This is easy to understand.
However, it is difficult to understand this in java. First, UTF-16 is used internally in java, such as a special string
The first character of "a I 𝕆" must be converted to UTF-16 format, which is \ u0061\u6211\uD835\uDD46 (\ u0061 represents a UTF-16 symbol). Each char can only store this \ u0061 symbol, because it is 0x0061 (hexadecimal number) with 2 bytes. The 𝕆 character is special. It can only be represented by two UTF-16 code points, so this character needs two chars to store, so the length of the whole "a I 𝕆" is 4, Because it uses four chars to store data (but it seems that after jdk1.8, the String class does not use char [] to store data, but uses byte [] as the storage container. Let's still assume that char [] is used as the String container. In fact, byte [] is used as the container, and you can also use its inner part as char [])
Insert an example
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(
new FileOutputStream("module-11\\data\\UTF_8.txt"), StandardCharsets.UTF_8); //In fact, the default is to write files in UTF-8 encoding format
String s = "\u0061\u6211\uD835\uDD46"; // a I 𝕆
char[] chars = s.toCharArray();
int i =0;
System.out.println(chars.length);//4
outputStreamWriter.write(chars[3]);
outputStreamWriter.write(chars[2]);
outputStreamWriter.write(chars[1]);
outputStreamWriter.write(chars[0]);
outputStreamWriter.flush();
// Stored results:?? I a
Second sequential storage:
// System.out.println(chars.length);//4
// outputStreamWriter.write(chars[0]);
// outputStreamWriter.write(chars[1]);
// outputStreamWriter.write(chars[2]);
// outputStreamWriter.write(chars[3]);
// outputStreamWriter.flush();
// //Stored results: a I 𝕆The write method can only read in one char at a time. Here, all text will be converted again after being read in, that is, the conversion from UTF-16 to UNicode. This is the only way to explain the difference between the two storage.
Reading files is the reverse,
You can see that binary data can be directly converted into characters when the encoding is determined. The three bytes here are the encoding rules of UTF-8
byte[] bytes1 = new byte[3];
bytes1[0] = (byte) 0b11100110;
bytes1[1] = (byte) 0b10001000;
bytes1[2] = (byte) 0b10010001;
String s = new String(bytes1, StandardCharsets.UTF_8);
System.out.println("s = " + s);// s = me
FileOutputStream fileOutputStream = new FileOutputStream("byte.txt");
fileOutputStream.write(bytes1);
fileOutputStream.flush();//The stored result is also "me"I didn't know much about csdn for the first time. I hope I can be more forgiving and give some comments