Class description
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, Serializable
This class implements a hash table that maps keys to values. Any non empty object can be used as a key or value.
To successfully store and retrieve objects from the hash table, the objects used as keys must implement the hashCode method and the equals method.
The instance of hash table has two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table. The initial capacity is only the capacity when the hash table is created. Note that the hash table is open: in the case of "hash conflict", a single bucket stores multiple entries, which must be searched in order. The load factor is a measure of the fullness of the hash table that is allowed to be expressed before automatically increasing the hash table capacity. The initial capacity and load factor parameters are only hints for implementation. The exact details of when and whether to call the rehash method depend on the implementation.
In general, the default load factor (0.75) provides a good compromise between time and space costs. Higher values reduce the space overhead, but increase the time overhead of finding entries (this is reflected in most hash table operations, including get and put).
Initial capacity controls the tradeoff between wasted space and the need for re ashing operations, which is very time-consuming. If the initial capacity is greater than the maximum number of entries contained in the hash table divided by its load factor, no re caching operation will occur. However, setting the initial capacity too high may waste space.
If you want to create multiple entries in a hash table, creating a hash table with sufficient capacity may insert entries more effectively than having the hash table automatically expand as needed to grow the table.
This example creates a numeric hash table. It uses the name of the number as the key: hashtable < string, integer > numbers
Hashtable<String, Integer> numbers = new Hashtable<String, Integer>();
numbers.put("one", 1);
numbers.put("two", 2);
numbers.put("three", 3);
To retrieve numbers, use the following code:
Integer n = numbers.get("two");
if (n != null) {
System.out.println("two = " + n);
}
The iterators returned by the iterator methods of all collections returned by the "collection view methods" of this class are fail fast: if the structure of the hash table is modified in any way other than the iterator's own remove method at any time after the iterator is created, the iterator will throw a ConcurrentModificationException. Therefore, in the face of concurrent modifications, the iterator will fail quickly and cleanly, rather than risking arbitrary and uncertain behavior at an uncertain time in the future. The enumeration returned by the key and element methods of the hash table is not a quick failure.
Note that the fast failure behavior of iterators cannot be guaranteed, because in general, no hard guarantee can be made in the presence of asynchronous concurrent modifications. The fast failure iterator will try its best to throw a ConcurrentModificationException. Therefore, it is wrong to write a program that depends on the correctness of this exception: the fast failure behavior of the iterator should only be used to detect bug s.
Start with the Java 2 platform v1. 2. This class is transformed to implement the Map interface and make it a member of the Java collection framework. Unlike the new collection implementation, the hash table is synchronized. If thread safe implementation is not required, it is recommended to use HashMap instead of Hashtable. Java is recommended if a thread safe high concurrency implementation is required. util. Concurrent HashMap replaces Hashtable.
Constants, variables, inner classes
/**
* The hash table data.
*/
private transient Entry<?,?>[] table;
/**
* The total number of nodes in the hash table
*/
private transient int count;
/**
* Capacity * expansion factor (boundary of expansion)
*
* @serial
*/
private int threshold;
/**
* Expansion factor
*
* @serial
*/
private float loadFactor;
//Node object
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
@SuppressWarnings("unchecked")
protected Object clone() {
return new Entry<>(hash, key, value,
(next==null ? null : (Entry<K,V>) next.clone()));
}
// Map.Entry Ops
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
}
public int hashCode() {
return hash ^ Objects.hashCode(value);
}
public String toString() {
return key.toString()+"="+value.toString();
}
}Construction method
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t); //put
}As can be seen from the above, the default capacity of Hashtable is 11, and the default expansion factor is not 0.75
put
public synchronized V put(K key, V value) {
//value cannot be empty
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
//Loop down the table from the position of the index corresponding to the hash value of the key
for(; entry != null ; entry = entry.next) {
//Match, replace value, and return oldValue
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
//Add entru
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
//If the current number of nodes is greater than or equal to the capacity expansion boundary value (because when count=threshold, + 1 ratio is greater than threshold), the capacity will be expanded
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
//Set the element of the current index position to e.next, and then set the current position to e, header insertion
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1; // Capacity expansion 2x + 1
if (newCapacity - MAX_ARRAY_SIZE > 0) { //And integer MAX_ Value - 8 for comparison
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
//Set boundary
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
//Put the elements in the old table into the new table by calculating the index
for (int i = oldCapacity ; i-- > 0 ;) {
//Traversal linked list
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
//Set the element of the current index position to e.next, and then set the current position to e, header insertion
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
public synchronized void putAll(Map<? extends K, ? extends V> t) {
for (Map.Entry<? extends K, ? extends V> e : t.entrySet())
//Called put method
put(e.getKey(), e.getValue());
}Through put, we find that the data structure of HashTable is in the form of array + linked list
copy the picture to: HashTable of java - Xia you - blog Park (cnblogs.com)
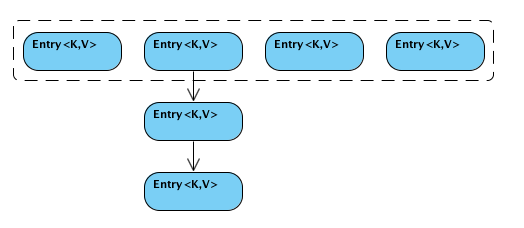
Then hashtable's linked list uses header insertion
get
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}remove
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
//Traverse the linked list at position index to find the position
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) { //e is not a header node
prev.next = e.next;
} else {
//E is the head node, so e.next is the head node
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}Conclusion:
1. The data structure is array + linked list, which uses header insertion
2. The related methods use synchronized modification, so they are thread safe