
Basic concepts of composite data types
The most commonly used combined data types in Python are set type, sequence type and mapping type.
Overview of collection types
A collection type is a collection of elements, which is an unordered combination. It is represented by braces {}. The elements in the collection can be dynamically increased or decreased. The elements in the collection cannot be repeated. The element type can only be immutable data types, such as integers, floating-point numbers, strings, tuples, etc. in contrast, the list, dictionary and collection types themselves are variable data types and cannot be used as elements of the collection.
The output order of a collection can be different from the definition order. Because the collection elements are unique, the collection type can be used to filter out duplicate elements.
T={"1010",12.3,1010}
print(T)
result
{12.3, 1010, '1010'}
T={"1010",12.3,1010,1010,1010}
print(T)
result
{'1010', 12.3, 1010}
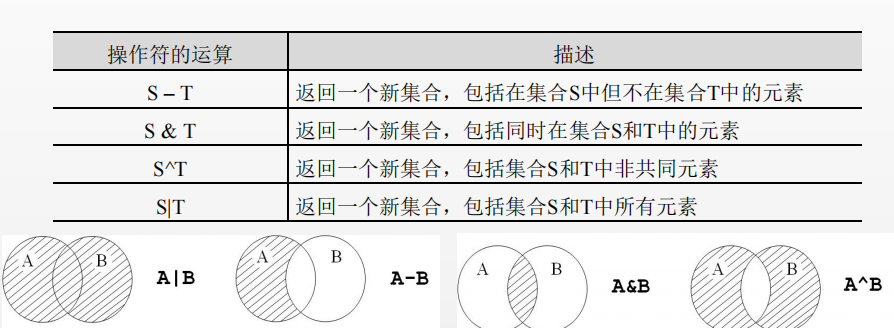
The set type has four operators, intersection (&), Union (|), difference (-), complement (^), as shown in the following table
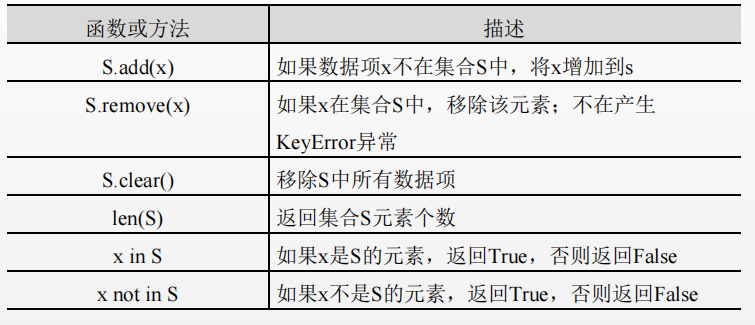
Set types have some common operation functions or methods, as shown in the following table
The set() function can generate an empty set of variables of type X.
S=set('Knowing is knowing, not knowing is not knowing')
print(S)
for i in S:
print(i,end="")
result
{'no', 'of', 'by', 'know'}
Don't know
Sequence type overview
Sequence type is a one-dimensional element vector. There is a sequence relationship between elements, which can be accessed through sequence number. Many data types in this language are sequence types, and the more important are string types, list types and tuple types.
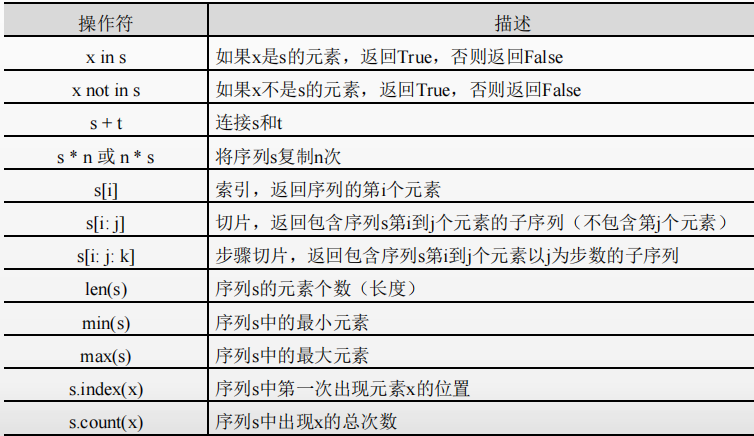
Sequence types are generic operators and functions. See the table below
Tuple type is one of the important components of sequence type.
t=(1,2,3) print(type(t))
result
<class 'tuple'>
Tuples cannot be modified once defined. Therefore, in some programming, list type is usually used instead of tuple type. Tuple types are mainly used in Python syntax related scenarios. For example, when a function returns multiple values, multiple return values are returned in tuple type, which is actually a data type.
def f(x):
return x,x+1,x+2
print(f(1))
print(type(f(1)))
result
(1, 2, 3) <class 'tuple'>
Overview of mapping types
The mapping type is a combination of "key value" data items, that is, elements (key,value). Elements are unordered.
List type
Definition of list
The list is an ordered sequence and belongs to the sequence type. The list can add, delete, replace and find elements. Element types can be different. You can convert a collection or string type to a list type through the list(x) function.
The list() function generates an empty list.
print(list('Lists can be generated from strings'))
result
['column', 'surface', 'can', 'from', 'word', 'symbol', 'strand', 'living', 'become']
Index of the list
The index number cannot exceed the element range of the list. Otherwise, an IndexError error error will be generated.
>>> ls=[1010,"1010",[1010,"1010"],1010]
>>> ls[3]
1010
>>> ls[-2]
[1010, '1010']
>>> ls[5]
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
ls[5]
IndexError: list index out of range
You can use the traversal loop to traverse elements of list type. The basic usage is as follows:
For < loop variable > in < list variable >
< statement block >
ls=[1010,"1010",[1010,"1010"],1010]
for i in ls:
print(i*2)
result
2020 10101010 [1010, '1010', 1010, '1010'] 2020
Slice of list
< list or list variable > [n: M: k]
Slice gets the list of elements corresponding to the list type from N to M (excluding M) in K steps.
>>> ls=[1010,"1010",[1010,"1010"],1010] >>> ls[1:4] ['1010', [1010, '1010'], 1010] >>> ls[-1:-3] [] >>> ls[-3:-1] ['1010', [1010, '1010']] >>> ls[0:4:2] [1010, [1010, '1010']]
List type actions
List operator
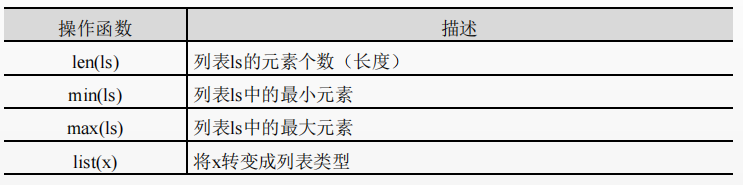
min(ls) and max(ls). The premise of using these two functions is that the element types in the list can be compared. If the list elements cannot be compared, using these two functions will report an error.
list(x) converts the variable x into a list type, where x can be a string type or a dictionary type.
>>> list({"Xiao Ming","Xiao Hong","Xiaobai","Xiaoxin"})
['Xiao Hong', 'Xiao Ming', 'Xiaoxin', 'Xiaobai']
>>> list({"201801":"Xiao Ming","201802":"Xiao Hong","201803":"Xiaobai"})
['201801', '201802', '201803']
Operation method of list
Its operation method and syntax form:
< list variables >< Method name > (< method parameter >)
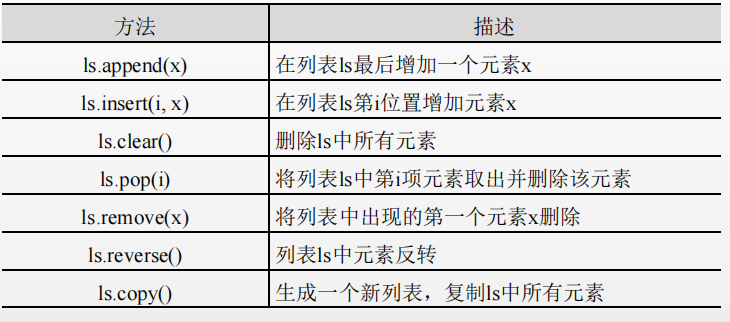
ls.copy() copies all elements in LS to generate a new list.
lt=[1010,"1010",[1010,"1010"],1010] ls=lt.copy() lt.clear() #Empty lt print(ls)
result
[1010, '1010', [1010, '1010'], 1010]
A new list cannot be generated by direct assignment. Only an alias can be added to the list.
lt=[1010,"1010",[1010,"1010"],1010] ls=lt #Use equal sign only lt.clear() #Empty lt print(ls)
result
[]
You can modify the list fragment by using slice and equal sign (=), and the modified content can be unequal in length. When using one list to change the value of another list, Python does not require the length of the two lists to be the same, but follows the principle of "more increase and less decrease".
lt=[1010,"10,10","python"] lt[1:2]=[1010,10.10,0x1010] print(lt) lt[1:4]=[1010] print(lt) [1010, 1010, 10.1, 4112, 'python'] [1010, 1010, 'python']
Dictionary type
Each element is a key value pair, which is used as follows
{< key 1 >: < value 1 >, < key 2 >: < value 2 >,..., < key n >: < value n >}
Dictionary index
The index pattern of key value pairs in the dictionary is as follows
< value > = < dictionary variable > [< key >]
d={"201801":"Xiao Ming","201802":"Xiao Hong","201803":"Xiaobai"}
print(d["201802"])
Xiao Hong
A dictionary is a data structure that stores a variable number of key value pairs. The value can be any data type, and the key can only be an immutable data type. The value can be indexed through the key, and the value can be modified through the key.
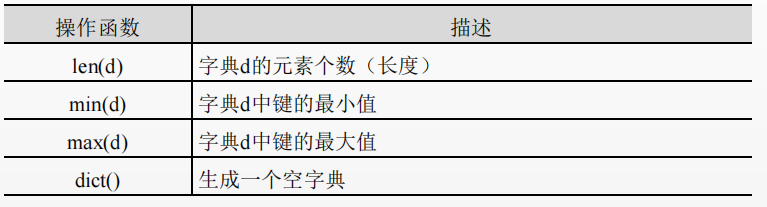
Dictionary type operation
Dictionary operation function
Operation method of dictionary
Use grammatical forms
< dictionary variables >< Method name > (< method parameter >)
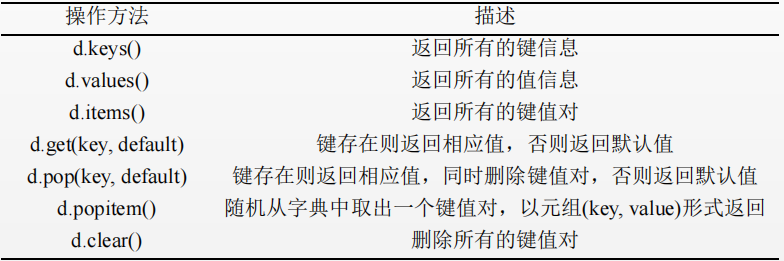
d.get(key.default) the second element default can be omitted. If omitted, the default value is empty.
d={"201801":"Xiao Ming","201802":"Xiao Hong","201803":"Xiaobai"}
>>> d.get('201801')
'Xiao Ming'
>>> d.get('201804')
>>> d.get('201804','non-existent')
'non-existent'
The dictionary can traverse other elements in a loop. The basic syntax structure is as follows:
For < variable name > in < dictionary name >:
statement block
The variable name returned by the for loop is the index value of the dictionary. If you need to get the value corresponding to the key, you can get it through the get() method in the statement block.
d={"201801":"Xiao Ming","201802":"Xiao Hong","201803":"Xiaobai"}
for k in d:
print("The keys and values of the dictionary are:{}and{}".format(k,d.get(k)))
result
The keys and values of the dictionary are 201801 and Xiaoming respectively The keys and values of the dictionary are 201802 and Xiaohong respectively The keys and values of the dictionary are 201803 and Xiaobai respectively
After class exercises
- English character frequency statistics. Write a program to analyze the frequency of a ~ z letters in a given string, ignore case and output in descending order.
txt=input("Please enter an English string:")
txt=txt.lower() #Make letters lowercase
d={}
for i in txt:
if i in "abcdefghigklmnopqrstuvwxyz":
d[i]=d.get(i,0)+1 #The value in the dictionary. If i is in d, the value corresponding to i is returned; If i is not in d, return 0
ls=list(d.items()) #Convert dictionary to record list
ls.sort(key=lambda x:x[1],reverse=True) #For sorting
for i in range(len(d)):
word,count=ls[i]
print("{:<10}{:<5}".format(word,count))
result
Please enter an English string: dhnesammxmopwedjqmsdqdssaaq d 4 s 4 m 4 a 3 q 3 e 2 h 1 n 1 x 1 o 1 p 1 w 1
- Chinese character frequency statistics. Write a program to analyze the frequency of all characters (including Chinese characters) in a given string and output them in descending order.
txt=input("Please enter a Chinese string:")
d={}
for ch in ',. "";!?':
txt=txt.replace(ch," ") #Convert special characters to spaces
for i in txt:
d[i]=d.get(i,0)+1 #The value in the dictionary. If i is in d, the value corresponding to i is returned; If i is not in d, return 0
ls=list(d.items()) #Convert dictionary to record list
ls.sort(key=lambda x:x[1],reverse=True) #For sorting
for i in range(len(d)):
word,count=ls[i]
print("{:<10}{:<5}".format(word,count))
result
Please enter a Chinese string: I'm Chinese. I'm proud to be Chinese.
I 2
yes 2
in 2
country 2
people 2
2
since 2
very 1
Haughty 1
Oneself 1
- Random password generation. Write a program to randomly generate 10 8-bit passwords in a list composed of 26 letters and 9 numbers.
import random
s = ["a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z",
"A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z",
"0","1","2","3","4","5","6","7","8","9"] #Define the range of list elements according to requirements. It is more convenient to define strings when there are no requirements
for i in range(10): #Cycle 10 times to generate 10 groups of passwords
for i in range(8):
print (random.choice(s),end="") #random.choice(seq) implements random selection of an element from a sequence or set
print("\n") #After each group is output, the next group is output by line feed
result
lcr4ld2M OpWGJZDT GwiaGaqB 15JOlPEI MN5abIXi qugDm2fY H6BH2tzN 1WyViiw6 5dWOwU6a 0fb7xqmv
- Duplicate element determination. Write a function that receives a list as a parameter. If an element appears in the list more than once, it returns True, but do not change the value of the original list. At the same time, write a program to call this function and output the test results. (this has to end with Ctrl+C)
def Lbpd(a): #Define function Lbpd(a)
a =a.split(" ") #Perform word segmentation for parameter a according to spaces
if len(a)==len(set(a)): #Using the non repeatability of the set, compare the length of list a and set a
return "False,This is a non repetitive sequence" #If not, the same sequence is returned
else:
return "True,This is a repeat sequence" #If different, repeat sequence is returned
t = f = 0 #Initial assignment of the number of repeat sequences and non repeat sequences
while True: #Let the program cycle
a =input("Please enter a set of sequences separated by spaces:")
print(Lbpd(a)) #Call the function to print the return value when the function parameter is a
if Lbpd(a)=="True,This is a repeat sequence": #Count the number of repeats
t +=1
if Lbpd(a)=="False,This is a non repetitive sequence": #Count the number of non repetitive sequences
f +=1
print("Repeat sequence{}Times, non repetitive sequence{}second".format(t,f)) #Print out statistics result statement
result
Please enter a set of sequences separated by spaces:[10,20,10] [10,20,10] True,This is a repeat sequence Repeat sequence 1 times, non repeat sequence 0 times Please enter a set of sequences separated by spaces:[11,12,14] [11,12,14] True,This is a repeat sequence Repeat sequence 2 times, non repeat sequence 0 times Please enter a set of sequences separated by spaces:[11,12,13] [14,15,16] False,This is a non repetitive sequence Repeat sequence 2 times and non repeat sequence 1 time Please enter a set of sequences separated by spaces:
- Repeat element determination continued. Use the non repeatability of the set to adapt the previous program to obtain a faster and more concise version.
ls = eval(input("Please enter a list:"))
if ls != list(set(ls)):
print(True)
else:
print(False)
result
Please enter a list:[10,20,10] True >>> =================== RESTART: C:/Users/lenovo/Desktop/Program running.py =================== Please enter a list:[10,20,30] False