
1, Foreword
By Jack Cui
After the learning of the last two articles, Python crawler takes three steps: request initiation, data parsing and data saving. Have you mastered them? Are they entry-level crawlers?
No, it's not enough! Only mastering these skills can only be regarded as layman level.
Today, let's continue to learn how to climb more gracefully!
According to the Convention, let's start from the actual combat. Today, let's take a picture and check the problems and elegant solutions.
This article is suitable for both men and women, old and young. I learned the method of this article and collected everything in my pocket!
Many people study python and don't know where to start.
Many people learn python, master the basic syntax, do not know where to find cases to start.
Many people who have already done cases do not know how to learn more advanced knowledge.
Then for these three types of people, I will provide you with a good learning platform, free access to video tutorials, e-books, and the source code of the course!
QQ group: 1097524789
2, Actual combat background
Let's not go for the eye-catching pictures. Let's have some light home cooking.
Cartoon home comics download!
In this actual battle, you will encounter dynamic loading and primary anti climbing. If you know the method of this article, are you afraid that you will not be able to climb the "beauty map" of your mind?

3, Comics Download
I do not download the whole site resources, just choose a download, do not give the server too much pressure.
Pick to pick, looking for the animation home ranking top of a "demon God", to tell the truth, read the first chapter of the comic content, thick fire and shadow atmosphere.
URL: https://www.dmzj.com/info/yaoshenji.html
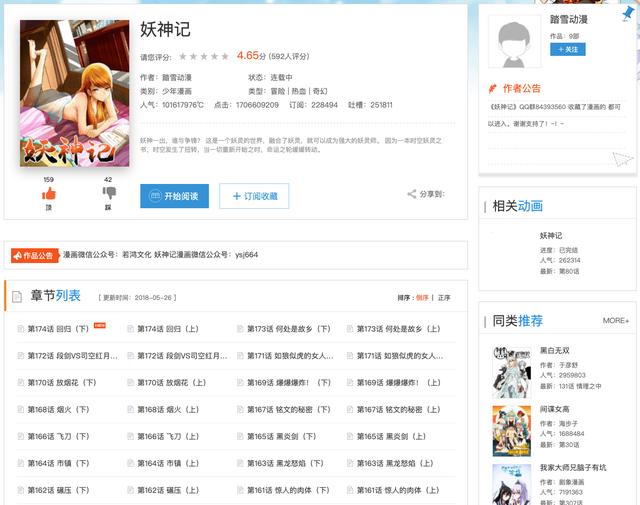
In order to download this cartoon, we need to save the pictures of all chapters to the local. Let's start with the following ideas:
- Get all chapter names and chapter links
- Link all comic pictures in the chapter according to the chapter
- Save the comics by category according to the chapter name
It seems simple, but in practice, we may encounter various problems. Let's solve these problems gracefully!
1. Get chapter name and chapter link
A web page is composed of many div elements
Different divs store different contents, as shown in the figure above. There are divs for storing the title Jack Cui, menu, text and copyright information.
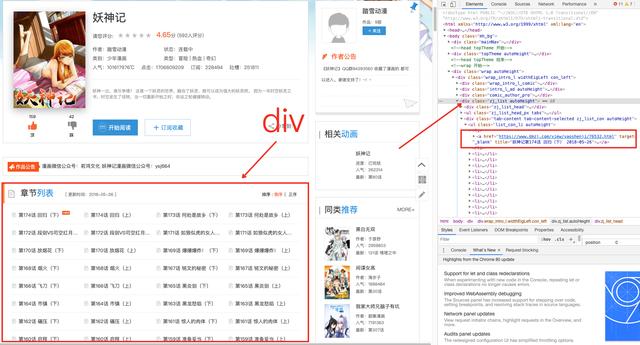
Look, it's not hard to find that as long as you get the class attribute of ZJ_ The div tag of list can get the chapter name and chapter link, which are stored in the a tag under the div tag.
If you take a closer look, you will find that there is also a ul tag under the div tag. The ul tag is the closest tag to the a tag.
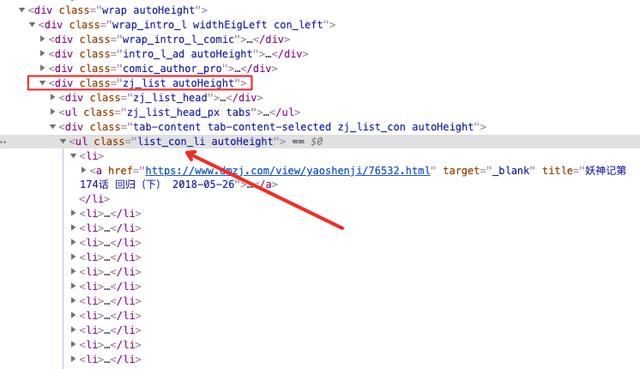
Use the beautiful soup explained in the previous article to directly match the latest class attribute to list_con_li's ul label is enough. Write the following code:
Python
import requests
from bs4 import BeautifulSoup
target_url = "https://www.dmzj.com/info/yaoshenji.html"
r = requests.get(url=target_url)
bs = BeautifulSoup(r.text, 'lxml')
list_con_li = bs.find('ul', class_="list_con_li")
comic_list = list_con_li.find_all('a')
chapter_names = []
chapter_urls = []
for comic in comic_list:
href = comic.get('href')
name = comic.text
chapter_names.insert(0, name)
chapter_urls.insert(0, href)
print(chapter_names)
print(chapter_urls)Look, chapter name and chapter link are done!
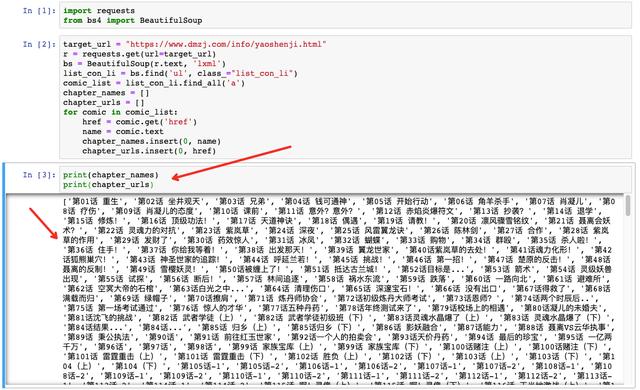
No difficulty? Don't worry. It's hard at the back.
2. Get comic image address
As long as we analyze how to get pictures in one chapter, we can get cartoon pictures in batches in each chapter.
Let's look at the first chapter.
URL: https://www.dmzj.com/view/yaoshenji/41917.html
Open the link in the first chapter, and you will find that "× @ page=1" is automatically added after the link.
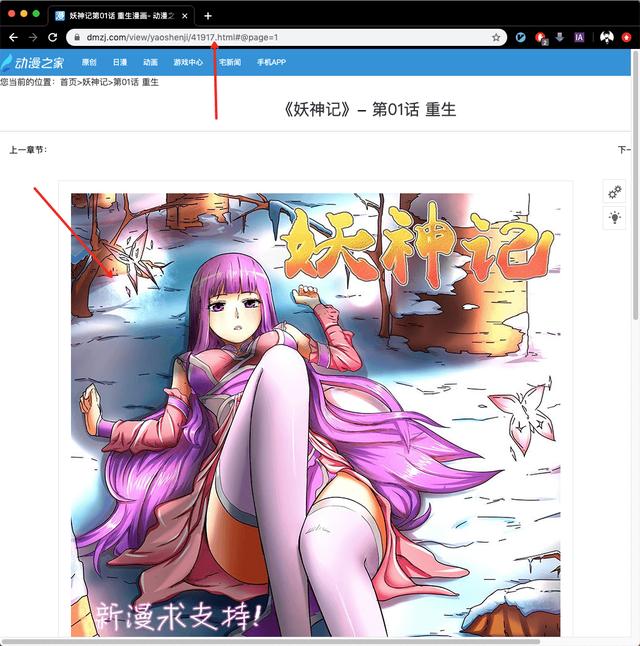
When you turn the page, you will find that the links on the second page are followed by # @ page=2, the links on the third page are followed by # @ page=3, and so on.
However, these are not the address of the image, but the address of the display page. To download the image, first get the real address of the image.
Review the element to find the image address, you will find that this page can not right-click!
This is the lowest anti crawler method. At this time, we can call up the review element window through F12 of the keyboard.
Some websites even ban F12, which is also a very low-level anti crawler means to cheat the novice.
In the face of this kind of primary means to prohibit viewing the page source code, an elegant general solution is to add a view source: before connecting.
Shell
view-source:https://www.dmzj.com/view/yaoshenji/41917.html
With this link, you can directly see the source code of the page.
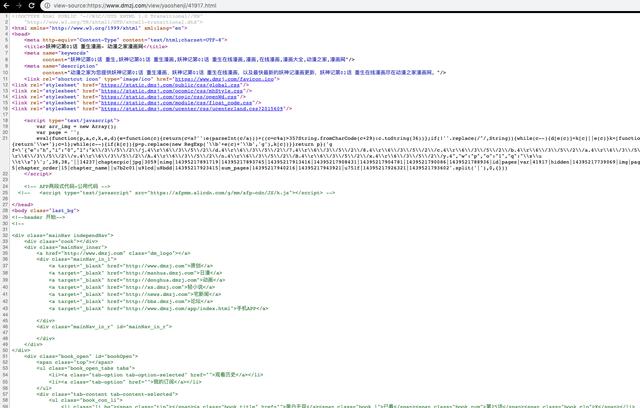
A simpler way is to focus your mouse on the browser address bar and press F12 to still bring up the debug window.
This cartoon website, or through F12 review elements, call up the debugging window.
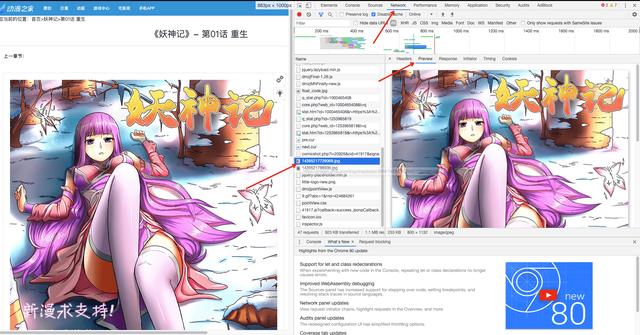
We can find the content loaded on this page in the Network of browser debugging window, such as some css files, js files, pictures, etc.
If you want to find the address of the picture, you can directly find it here. Don't look in the html page. There are so many html information. You can find the year of the monkey and the moon one by one.
We can easily find the real address of the image we want in the Network. The debugging tool is very powerful. Headers can see some request header information, and Preview can browse the return information.
Search function, filter function and so on, have everything, how to use concretely, do it by yourself, you will know!
OK, I got the real address of the picture. Let's see the following link:
https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg
This is the real address of the image. Take this link to search the html page, and see which img tag it is stored in. After searching, you will find that the html page in the browser has this image link.
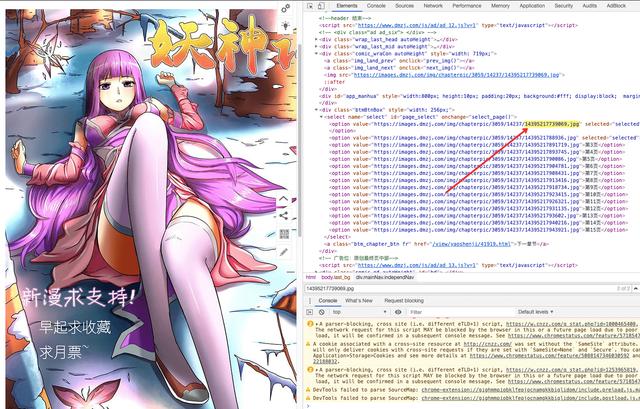
But if you use view source: to open this page, you will find that you can't search the image link.
Shell
view-source:https://www.dmzj.com/view/yaoshenji/41917.html
Remember, this shows that the image is dynamically loaded!

Using the view source: method is to view the page source code, regardless of the dynamically loaded content. There is no image link in it, which means that the image is dynamically loaded.
Is it easy to judge?
Don't panic when it comes to dynamic loading. There are two ways to use JavaScript for dynamic loading:
- External load
- Internal load
External loading is to load a js in the form of reference in the html page, for example:
XHTML
<script type="text/javascript" src="https://cuijiahua.com/call.js"></script>
This code means, quote cuijiahua.com Under domain name call.js Documents.
Internal loading means that the content of Javascript script is written in html, such as this cartoon website.
At this time, you can use the search function to teach a search tips.
https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg
This is the picture link. Then use the picture name to remove the suffix, that is, 14395217739069 to search on the debugging page of the browser. Because the general dynamic loading, the link is the combination of programs. It's right to search it!
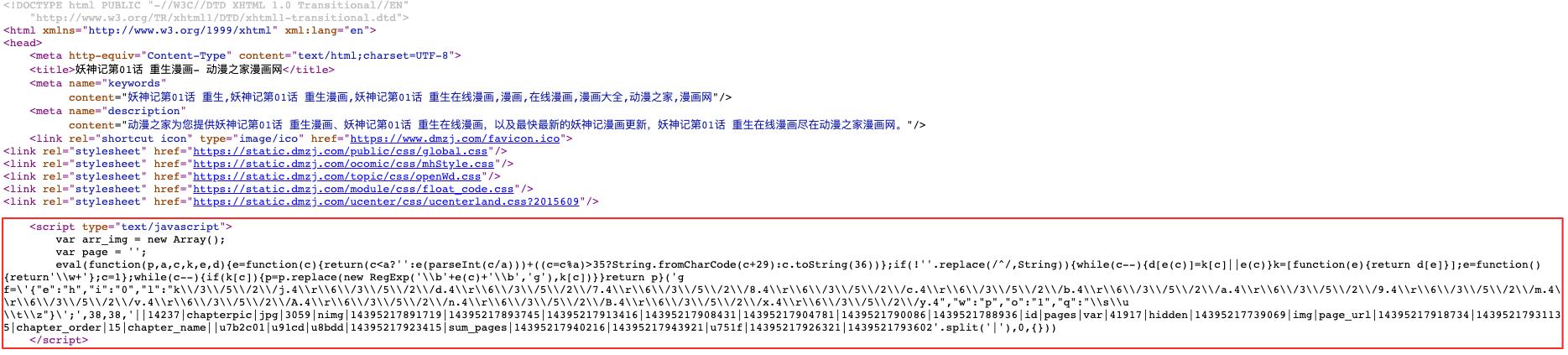
XHTML
<script type="text/javascript">
var arr_img = new Array();
var page = '';
eval(function(p,a,c,k,e,d){e=function(c){return(c<a?'':e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--){d[e(c)]=k[c]||e(c)}k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1};while(c--){if(k[c]){p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c])}}return p}('g f=\'{"e":"h","i":"0","l":"k\\/3\\/5\\/2\\/j.4\\r\\6\\/3\\/5\\/2\\/d.4\\r\\6\\/3\\/5\\/2\\/7.4\\r\\6\\/3\\/5\\/2\\/8.4\\r\\6\\/3\\/5\\/2\\/c.4\\r\\6\\/3\\/5\\/2\\/b.4\\r\\6\\/3\\/5\\/2\\/a.4\\r\\6\\/3\\/5\\/2\\/9.4\\r\\6\\/3\\/5\\/2\\/m.4\\r\\6\\/3\\/5\\/2\\/v.4\\r\\6\\/3\\/5\\/2\\/A.4\\r\\6\\/3\\/5\\/2\\/n.4\\r\\6\\/3\\/5\\/2\\/B.4\\r\\6\\/3\\/5\\/2\\/x.4\\r\\6\\/3\\/5\\/2\\/y.4","w":"p","o":"1","q":"\\s\\u \\t\\z"}\';',38,38,'||14237|chapterpic|jpg|3059|nimg|14395217891719|14395217893745|14395217913416|14395217908431|14395217904781|1439521790086|1439521788936|id|pages|var|41917|hidden|14395217739069|img|page_url|14395217918734|14395217931135|chapter_order|15|chapter_name||u7b2c01|u91cd|u8bdd|14395217923415|sum_pages|14395217940216|14395217943921|u751f|14395217926321|1439521793602'.split('|'),0,{}))
</script>No surprise, you can see this code, 1439521739069 mixed in!
I can't understand Javascript. What can I do?
It doesn't matter. To be honest, I have trouble watching it.
Let's find out the rules, analyze and analyze to see if we can solve this dynamic loading problem gracefully. Let's look at the picture link again:
https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg
Are the numbers in the link familiar?
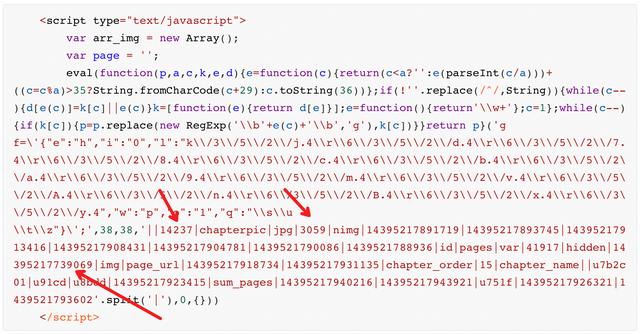
Isn't that the combination of these numbers?
Well, I have a bold idea! Make these long numbers directly, and try to synthesize the links.
Python
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.dmzj.com/view/yaoshenji/41917.html'
r = requests.get(url=url)
html = BeautifulSoup(r.text, 'lxml')
script_info = html.script
pics = re.findall('\d{13,14}', str(script_info))
chapterpic_hou = re.findall('\|(\d{5})\|', str(script_info))[0]
chapterpic_qian = re.findall('\|(\d{4})\|', str(script_info))[0]
for pic in pics:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg'
print(url)Running the code, you can get the following results:
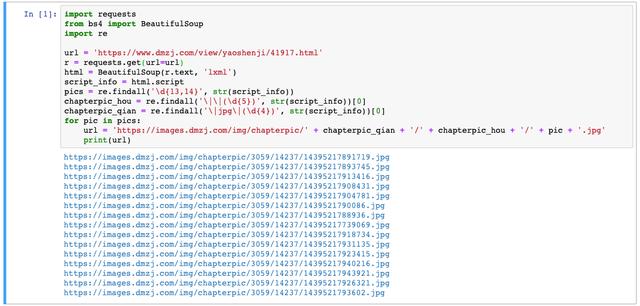
There is no place to look for. It won't take much time to come!
If you compare them, you will find that these are really the links of cartoon pictures!
But there is a problem, so the composite picture link is not in accordance with the order of comics, this download down the comics pictures are chaotic ah! Not elegant!
This website is also written by people! It's human, it's easy to do! Inertial thinking, if you, is the decimal number in front of the big number in the back? Among these long numbers, there are 13 digits, 14 digits, and they all start with 14. Then I'll bet that the result of zero filling of the last digit is the order of the pictures!
Python
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.dmzj.com/view/yaoshenji/41917.html'
r = requests.get(url=url)
html = BeautifulSoup(r.text, 'lxml')
script_info = html.script
pics = re.findall('\d{13,14}', str(script_info))
for idx, pic in enumerate(pics):
if len(pic) == 13:
pics[idx] = pic + '0'
pics = sorted(pics, key=lambda x:int(x))
chapterpic_hou = re.findall('\|(\d{5})\|', str(script_info))[0]
chapterpic_qian = re.findall('\|(\d{4})\|', str(script_info))[0]
for pic in pics:
if pic[-1] == '0':
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic[:-1] + '.jpg'
else:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg'
print(url)Program to 13 digits, the last zero, and then sort.
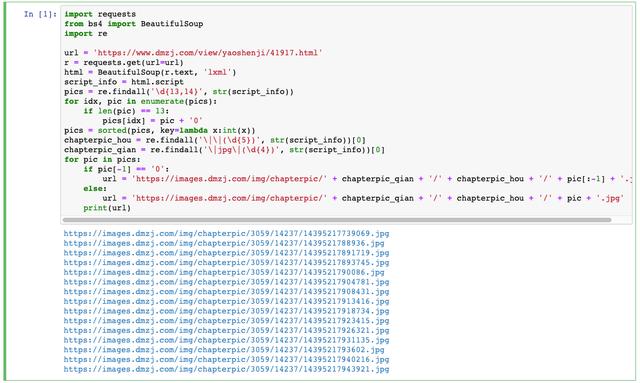
After comparing the links with the web page in order, you will find that it is right! That's the order!
Is it elegant enough to directly analyze and test without reading Javascript synthetic link code?
3. Download pictures
Everything is ready, only the east wind!
Use one of the picture links and try downloading it with code.
Python
import requests from urllib.request import urlretrieve dn_url = 'https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg' urlretrieve(dn_url,'1.jpg')
Through the urlretrieve method, you can download it. This is the simplest download method. The first parameter is the download link, and the second parameter is the save name of the downloaded file.
No accident, you can download this picture smoothly!
But an accident happened!
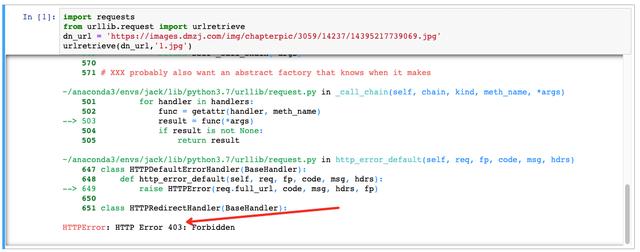
An HTTP Error occurred with error code 403.
403 indicates that resources are not available, which is another typical anti pickpocketing method.
Don't panic, let's analyze another wave!
Open this picture link:
URL: https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg
This address is the real address of the picture. If you open it in a browser, you may not be able to open it directly, or you may be able to open it, but you cannot open it once you refresh it!

If you open the chapter page again, and then open the picture link, you can see the picture again.
Chapter URL: https://www.dmzj.com/view/yaoshenji/41917.html
Remember, this is a typical anti - crawling method through Referer!
Referer can be understood as the origin. First, open the chapter URL link, and then open the picture link. When opening the picture, the chapter URL is saved in the referer's information.
The way of animation home website is that when users visit this picture, I will show it to them, and when users come from other places, I will not show it to them.
Whether it is a user in the station or not is a simple judgment based on the Referer.
This is a typical anti reptile method!
The solution is simple. We'll give it what it needs. Python
import requests
from contextlib import closing
download_header = {
'Referer': 'https://www.dmzj.com/view/yaoshenji/41917.html'
}
dn_url = 'https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg'
with closing(requests.get(dn_url, headers=download_header, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
print('file size:%0.2f KB' % (content_size / chunk_size))
with open('1.jpg', "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
else:
print('Link exception')
print('Download complete!')Using the closing method, you can set the Headers information. In this Headers information, you can save the Referer's origin, which is the URL of the first chapter. Finally, you can save this picture in the form of writing a file.
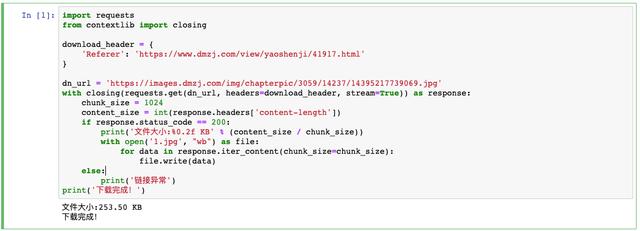
Download complete! It's that simple!
4, Comics Download
Integrate the code and download the whole cartoon. Write the code as follows: Python
import requests
import os
import re
from bs4 import BeautifulSoup
from contextlib import closing
from tqdm import tqdm
import time
"""
Author:
Jack Cui
Wechat:
https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA
"""
# Create save directory
save_dir = 'Demons and gods'
if save_dir not in os.listdir('./'):
os.mkdir(save_dir)
target_url = "https://www.dmzj.com/info/yaoshenji.html"
# Get animation chapter links and chapter names
r = requests.get(url = target_url)
bs = BeautifulSoup(r.text, 'lxml')
list_con_li = bs.find('ul', class_="list_con_li")
cartoon_list = list_con_li.find_all('a')
chapter_names = []
chapter_urls = []
for cartoon in cartoon_list:
href = cartoon.get('href')
name = cartoon.text
chapter_names.insert(0, name)
chapter_urls.insert(0, href)
# Download Comics
for i, url in enumerate(tqdm(chapter_urls)):
download_header = {
'Referer': url
}
name = chapter_names[i]
# Remove
while '.' in name:
name = name.replace('.', '')
chapter_save_dir = os.path.join(save_dir, name)
if name not in os.listdir(save_dir):
os.mkdir(chapter_save_dir)
r = requests.get(url = url)
html = BeautifulSoup(r.text, 'lxml')
script_info = html.script
pics = re.findall('\d{13,14}', str(script_info))
for j, pic in enumerate(pics):
if len(pic) == 13:
pics[j] = pic + '0'
pics = sorted(pics, key=lambda x:int(x))
chapterpic_hou = re.findall('\|(\d{5})\|', str(script_info))[0]
chapterpic_qian = re.findall('\|(\d{4})\|', str(script_info))[0]
for idx, pic in enumerate(pics):
if pic[-1] == '0':
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic[:-1] + '.jpg'
else:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg'
pic_name = '%03d.jpg' % (idx + 1)
pic_save_path = os.path.join(chapter_save_dir, pic_name)
with closing(requests.get(url, headers = download_header, stream = True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
with open(pic_save_path, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
else:
print('Link exception')
time.sleep(10)About 40 minutes, the comics can be downloaded!
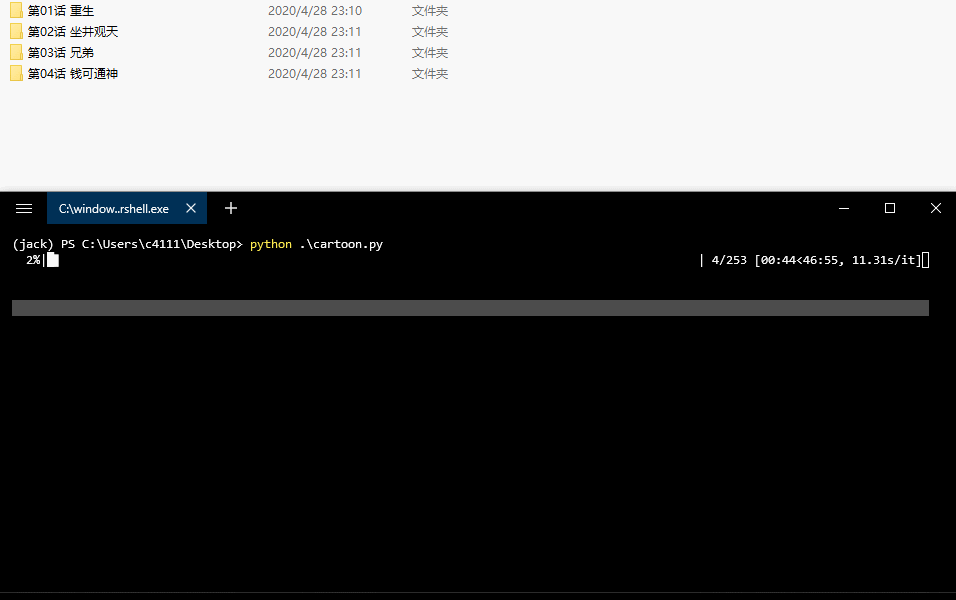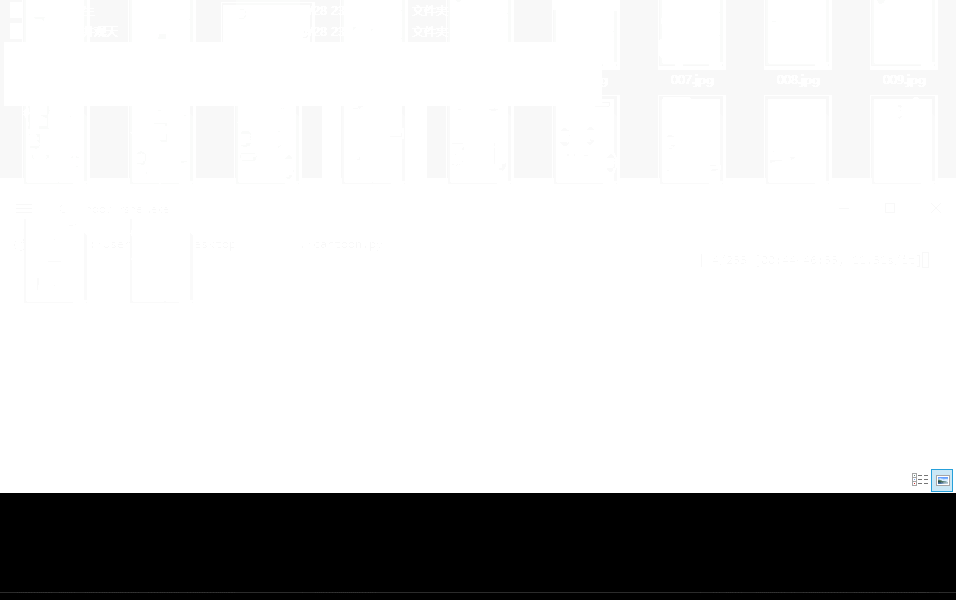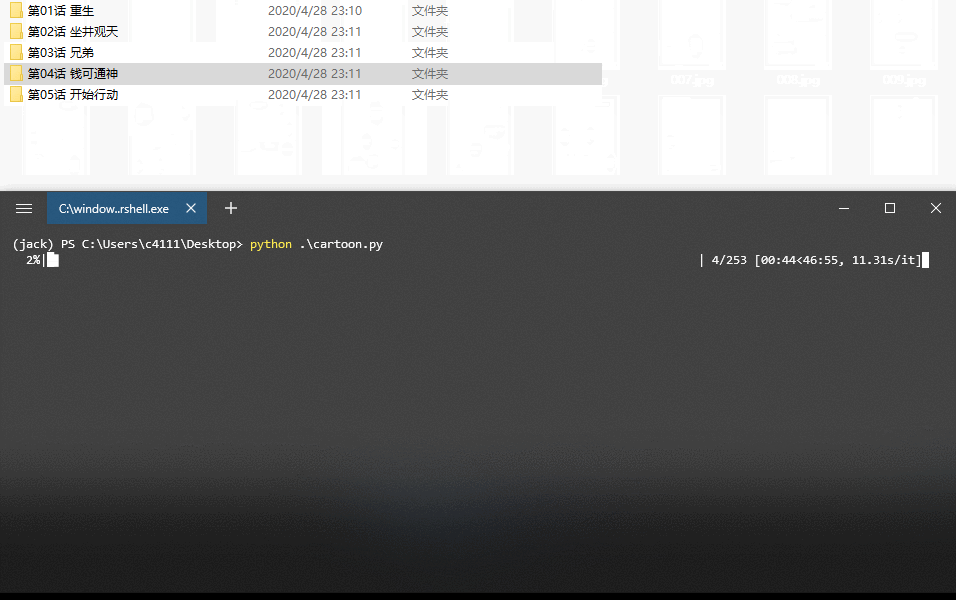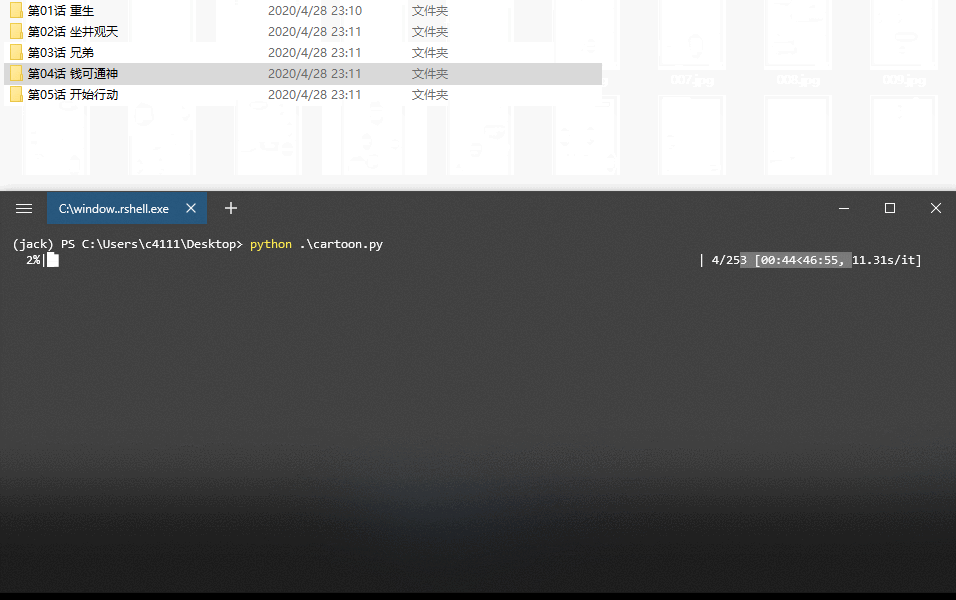
In the same words, we should be a friendly reptile. To write a crawler, be careful not to put too much pressure on the server to meet our data acquisition needs, which is enough.
Hello, I'm good, everyone is really good.
5, Summary
- This article explains how to judge whether the page information is dynamically loaded and how to solve the problem of dynamic loading.
- This article explains some common anti - Crawler strategies and solutions.