scene
Imagine that there is a requirement: design a comment system that requires users to comment on articles and reply to each other, without the limit of level.
(the adjacency list most commonly used by programmers will not be discussed here. Partners can baidu by themselves.)
Path Enumeration
Path enumeration is a complete path composed of continuous direct hierarchical relationships. For example, the UNIX path of / usr/local/lib is a path enumeration of the file system, where usr is the father of local, which means that usr is the ancestor of lib.
In the comments table, we use the path field of VARCHAR type to store the sequence from the topmost ancestor of the current node to itself. Just like the UNIX path, you can even use '/' as the delimiter in the path.
Table structure:
CREATE TABLE `comments` ( `comment_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `path` varchar(100) DEFAULT NULL, `bug_id` bigint(20) unsigned NOT NULL, `author` varchar(60) NOT NULL, `comment_date` datetime NOT NULL, `comment` text NOT NULL, PRIMARY KEY (`comment_id`), KEY `bug_id` (`bug_id`) ); INSERT INTO `comments` VALUES (1, '1/', 1, 'Fran', '2021-05-23 10:27:22', 'this Bug What are the causes of'); INSERT INTO `comments` VALUES (2, '1/2/', 1, 'Ollie', '2021-05-23 10:29:26', 'I think it's a null pointer'); INSERT INTO `comments` VALUES (3, '1/2/3/', 1, 'Fran', '2021-05-23 10:30:00', 'No, I checked'); INSERT INTO `comments` VALUES (4, '1/4/', 1, 'Kukla', '2021-05-23 10:30:34', 'We need to check the invalid input'); INSERT INTO `comments` VALUES (5, '1/4/5/', 1, 'Ollie', '2021-05-23 10:31:01', 'Yes, that's a problem'); INSERT INTO `comments` VALUES (6, '1/4/6/', 1, 'Fran', '2021-05-23 10:31:19', 'OK, check it out'); INSERT INTO `comments` VALUES (7, '1/4/6/7', 1, 'Kukla', '2021-05-23 10:31:41', 'Solved');
| comment_id | path | author | comment |
|---|---|---|---|
| 1 | 1/ | Fran | What is the cause of this Bug |
| 2 | 1/2/ | Ollie | I think it's a null pointer |
| 3 | 1/2/3/ | Fran | No, I checked |
| 4 | 1/4/ | Kukla | We need to check the invalid input |
| 5 | 1/4/5/ | Ollie | Yes, that's a problem |
| 6 | 1/4/6/ | Fran | OK, check it out |
| 7 | 1/4/6/7/ | Kukla | Solved |
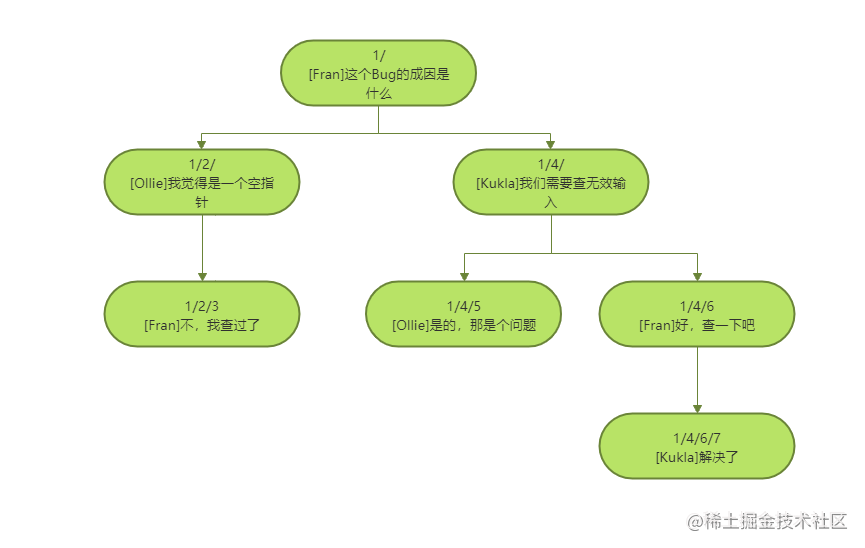
You can query the ancestors of a node by comparing the paths of each node. For example, to find a comment #7 (the path is 1 / 4 / 6 / 7) and its ancestors, you can do this:
SELECT * from comments AS c where '1/4/6/7/' like CONCAT(c.path,'%');
For example, to find a comment #4 (the path is 1 / 4) and all its descendants, you can use the following statement:
SELECT * from comments AS c where c.path like CONCAT('1/4/','%');If you want to calculate the number of comments per user in all comments #4 extended from comments, you can do this:
SELECT author,count(*) from comments AS c where c.path like CONCAT('1/4/','%') GROUP BY c.author;To insert a node, all you need to do is copy the path of the logical parent node of the node to be inserted, and append the ID of the new node to the end of the path.
INSERT INTO comments (author,comment_date,bug_id, comment) VALUES ('Ollie','2021-01-11', 1,'Good job!');
UPDATE comments
SET path = ( SELECT b.path FROM ( SELECT CONCAT( path, '/8' ) AS path FROM comments WHERE comment_id = 7 ) AS b )
WHERE
comment_id = 8;Disadvantages of path enumeration: the database cannot ensure that the format of the path is always correct or that the nodes in the path do exist. It depends on the logical code of the application to maintain the string of the path, and it is expensive to verify the correctness of the string. No matter how long the VARCHAR is set, there is still a length limit, so it can not support the infinite expansion of the tree structure.
Nested set
Nested set solution is to store the relevant information of descendant nodes, not the direct ancestors of nodes. We use two numbers to encode each node to represent this information, which can be called nsleft and nsright.
Table structure:
CREATE TABLE `comments` ( `comment_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `nsleft` int(11) NOT NULL, `nsright` int(11) NOT NULL, `bug_id` bigint(20) unsigned NOT NULL, `author` varchar(200) NOT NULL, `comment_date` datetime NOT NULL, `comment` text NOT NULL, PRIMARY KEY (`comment_id`), KEY `bug_id` (`bug_id`) ); INSERT INTO `comments` VALUES (1, 1, 14, 1, 'Fran', '2021-06-16 18:50:51', 'this Bug What are the causes of'); INSERT INTO `comments` VALUES (2, 2, 5, 1, 'Ollie', '2021-06-16 18:53:07', 'I think it's a null pointer'); INSERT INTO `comments` VALUES (3, 3, 4, 1, 'Fran', '2021-06-16 18:53:36', 'No, I checked'); INSERT INTO `comments` VALUES (4, 6, 13, 1, 'Kukla', '2021-06-16 18:53:58', 'We need to check the invalid input'); INSERT INTO `comments` VALUES (5, 7, 8, 1, 'Ollie', '2021-06-16 18:54:19', 'Yes, that's a problem'); INSERT INTO `comments` VALUES (6, 9, 12, 1, 'Fran', '2021-06-16 18:54:47', 'OK, check it out'); INSERT INTO `comments` VALUES (7, 10, 11, 1, 'Kukla', '2021-06-16 18:55:06', ' Solved');
Each node determines the values of nsleft and nsright in the following way: the value of nsleft is less than the ID of all descendants of the node, and the value of nsright is greater than the ID of all descendants of the node. These numbers and comments_ The value of ID has no association.
The simple method to determine these three values (nsleft, comment_id, nsrigh) is to perform a depth first traversal of the tree, allocate nsleft values incrementally in the process of layer by layer, and allocate nsright values incrementally in return.
| comment_id | nsleft | nsright | author | comment |
|---|---|---|---|---|
| 1 | 1 | 14 | Fran | What is the cause of this Bug |
| 2 | 2 | 5 | Ollie | I think it's a null pointer |
| 3 | 3 | 4 | Fran | No, I checked |
| 4 | 6 | 13 | Kukla | We need to check the invalid input |
| 5 | 7 | 8 | Ollie | Yes, that's a problem |
| 6 | 9 | 12 | Fran | OK, check it out |
| 7 | 10 | 11 | Kukla | Solved |
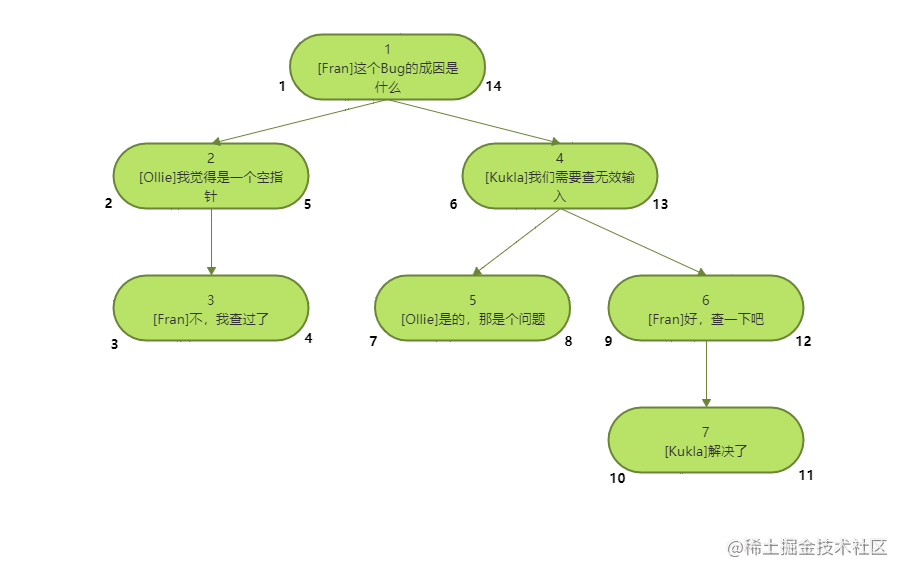
Once you assign these numbers to each node, you can use them to find the ancestors and descendants of a given node. For example, you can search which node's ID is between the nsleft and nsright range of the comment #4 to get the comment #4 and all its descendants
SELECT
c2.*
FROM
comments AS c1
LEFT JOIN comments AS c2 ON c2.nsleft BETWEEN c1.nsleft
AND c1.nsright
WHERE
c1.comment_id = 4;The comment #6 and all its ancestors can be obtained by searching which nodes have the ID within the nsleft and nsright ranges of the comment:
SELECT
c2.*
FROM
comments AS c1
JOIN comments AS c2 ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright
WHERE
c1.comment_id = 6;Operations on trees, such as inserting and moving nodes, using nested assemblies is much more complex than other designs. When inserting a new node, you need to recalculate the adjacent siblings, ancestors and brothers of its ancestors of the newly inserted node to ensure that their left and right values are greater than the left value of the new node. At the same time, if the new node is a non leaf node, you also need to check its descendant nodes. Assuming that the newly inserted node is a leaf node, the following statement can update each place to be updated:
Suppose the newly inserted node is a leaf node (inserted under the fifth node, the left and right values are 8 and 9):
UPDATE comments
SET nsleft =
CASE
WHEN nsleft >= 8 THEN
nsleft + 2 ELSE nsleft
END,
nsright = nsright + 2
WHERE
nsright >= 7;
INSERT INTO comments ( nsleft, nsright, bug_id, author, comment_date, COMMENT )
VALUES
( 8, 9, 1, 'Fran', '2021-06-16 19:55:06', 'Me too!' );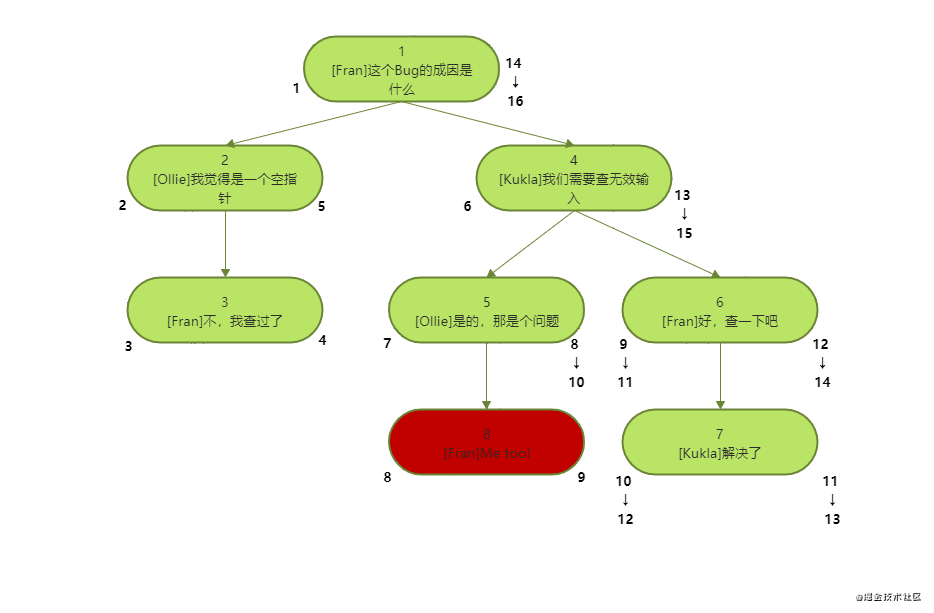
If a simple and fast query is the most important part of the whole program, nested sets are the best choice - much easier and faster than operating on individual nodes. However, inserting and moving nodes in a nested set is complicated because the left and right values need to be reassigned. If your application needs to insert and delete nodes frequently, the nested set may not be suitable, and the SQL statement will be very long and complex to query the direct parent node or direct child node of a node in the nested set.
Closure table
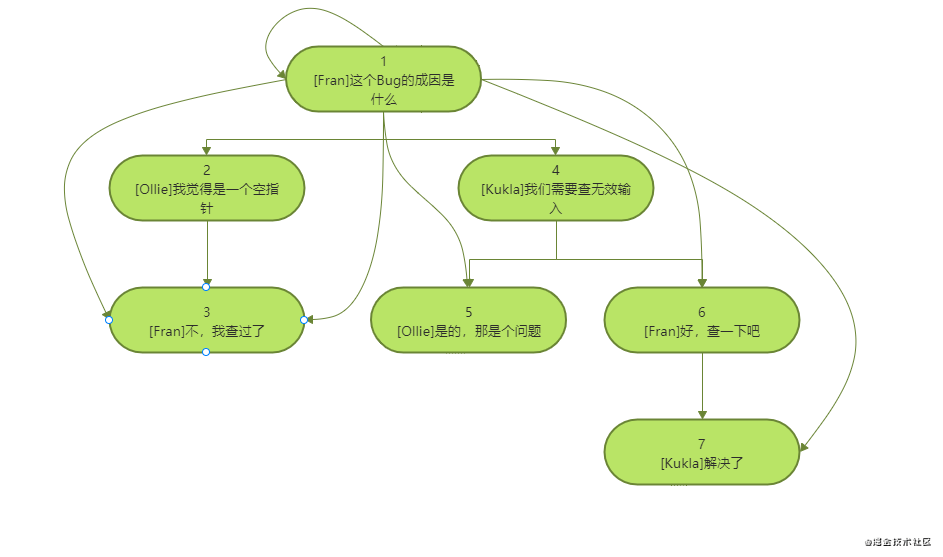
Closure table is a simple and elegant solution to hierarchical storage. It records the relationship between all nodes in the tree, not just the direct parent-child relationship.
When designing the comment system, we created an additional table called treepaths, which contains two columns, and each column is a comment pointing to the comments in the comments_ id.
Table structure:
CREATE TABLE `comments` ( `comment_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `bug_id` bigint(20) unsigned NOT NULL, `author` varchar(60) NOT NULL, `comment_date` datetime NOT NULL, `comment` text NOT NULL, PRIMARY KEY (`comment_id`), KEY `bug_id` (`bug_id`) ); CREATE TABLE `treepaths` ( `ancestor` bigint(20) unsigned NOT NULL, `descendant` bigint(20) unsigned NOT NULL, PRIMARY KEY (`ancestor`,`descendant`), KEY `descendant` (`descendant`) ); INSERT INTO `comments` VALUES (1, 1, 'Fran', '2021-06-16 19:27:22', 'this Bug What are the causes of'); INSERT INTO `comments` VALUES (2, 1, 'Ollie', '2021-06-16 19:29:26', 'I think it's a null pointer'); INSERT INTO `comments` VALUES (3, 1, 'Fran', '2021-06-16 19:30:00', 'No, I checked'); INSERT INTO `comments` VALUES (4, 1, 'Kukla', '2021-06-16 19:30:34', 'We need to check the invalid input'); INSERT INTO `comments` VALUES (5, 1, 'Ollie', '2021-06-16 19:31:01', 'Yes, that's a problem'); INSERT INTO `comments` VALUES (6, 1, 'Fran', '2021-06-16 19:31:19', 'OK, check it out'); INSERT INTO `comments` VALUES (7, 1, 'Kukla', '2021-06-16 19:31:41', 'Solved'); INSERT INTO `treepaths` VALUES (1, 1); INSERT INTO `treepaths` VALUES (1, 2); INSERT INTO `treepaths` VALUES (1, 3); INSERT INTO `treepaths` VALUES (1, 4); INSERT INTO `treepaths` VALUES (1, 5); INSERT INTO `treepaths` VALUES (1, 6); INSERT INTO `treepaths` VALUES (1, 7); INSERT INTO `treepaths` VALUES (2, 2); INSERT INTO `treepaths` VALUES (2, 3); INSERT INTO `treepaths` VALUES (3, 3); INSERT INTO `treepaths` VALUES (4, 4); INSERT INTO `treepaths` VALUES (4, 5); INSERT INTO `treepaths` VALUES (4, 6); INSERT INTO `treepaths` VALUES (4, 7); INSERT INTO `treepaths` VALUES (5, 5); INSERT INTO `treepaths` VALUES (6, 6); INSERT INTO `treepaths` VALUES (6, 7); INSERT INTO `treepaths` VALUES (7, 7);
Instead of using the comments table to store the tree structure, we store any node pair with ancestor descendant relationship in the tree in a row of the tree paths table, even if the two nodes are not directly parent-child relationship; At the same time, we also add a line pointing to the node itself.
| ancestors | Offspring | ancestors | Offspring | ancestors | Offspring |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 7 | 4 | 6 |
| 1 | 2 | 2 | 2 | 4 | 7 |
| 1 | 3 | 2 | 3 | 5 | 5 |
| 1 | 4 | 3 | 3 | 6 | 6 |
| 1 | 5 | 4 | 4 | 6 | 7 |
| 1 | 6 | 4 | 5 | 7 | 7 |
Comment here_ As an example, when the ID is 1_ The structure to be stored in treepaths with ID 1 is the contents marked in red in the table
Getting ancestors and descendants through the tree paths table is more direct than using nested sets. For example, to get the descendants of comments #4, you only need to search the row whose ancestor is comments #4 in the tree paths table:
SELECT
c.*,
t.*
FROM
comments AS c
JOIN TreePaths AS t ON c.comment_id = t.descendant
WHERE
t.ancestor = 4;To get all the ancestors of comments #6, you only need to search the row whose descendants are comments #6 in the tree paths table:
SELECT
c.*
FROM
comments AS c
JOIN treepaths AS t ON c.comment_id = t.ancestor
WHERE
t.descendant = 6;
To insert a new leaf node, such as a child node of the comment #5, you should first insert a relationship between yourself and yourself, and then search the node in the tree paths table where the descendant is the comment #5, and add the "ancestor descendant" relationship between the node and the newly inserted node (including the self reference of the comment #5):
{int} is a new comment_id
INSERT INTO comments (author,comment_date,bug_id, comment) VALUES ('Ollie','2021-01-11', 1,'Good job!');
INSERT INTO treepaths ( ancestor, descendant ) SELECT
t.ancestor,
{int}
FROM
TreePaths AS t
WHERE
t.descendant = 5 UNION ALL
SELECT
{int},
{int};
To delete a leaf node, such as a comment #7, delete all rows in the tree paths table whose descendants are comments #7:
DELETE FROM treepaths WHERE descendant = 7;
To delete a complete subtree, such as comments #4 and all its descendants, delete all rows whose descendants are #4 in the trees table and those whose descendants are the descendants of comments #4:
DELETE
FROM
treepaths
WHERE
descendant IN ( SELECT descendant FROM ( SELECT descendant FROM treepaths WHERE ancestor = 4 ) AS b );The design of closure table is more direct than nested set. Both of them can quickly query the ancestors and descendants of a given node, but closure table can maintain hierarchical information more simply. Both designs make it easier to query the direct descendants and parents of a given node than path enumeration.
However, you can optimize the closure table to make it easier to query direct parent or child nodes: add a path to the tree paths table_ Length field. The self referenced path of a node_ Length is 0, and the path to its direct child node_ Length is 1, the next layer is 2, and so on. The query comment #4's child nodes become very direct:
SELECT * FROM treepaths WHERE ancestor = 4 AND path_length = 1;
summary
Path enumeration can intuitively show the path from ancestor to offspring, but at the same time, because it can not ensure referential integrity, the design is very fragile. Enumeration paths also make the storage of data redundant.
Nested sets are a smart solution -- but perhaps too smart to ensure referential integrity. It is best to use it in a situation where query performance is very high and other requirements are general
Closure table is the most common design. It requires an additional table to store relationships, and uses the scheme of space for time to reduce the consumption caused by redundant calculation in the process of operation.
reference resources
- MySQL anti pattern