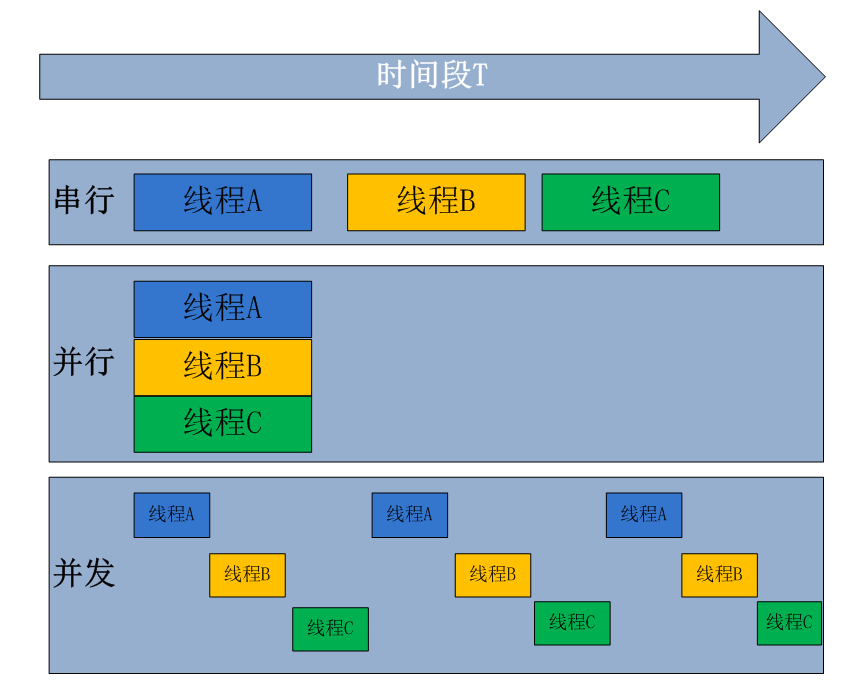
Parallelism and concurrency
- parallel processing
It is an execution method of executing more than two tasks at the same time in a computer system. Parallel processing can work on different aspects of the same program at the same time. The main purpose of parallel processing is to save time for solving large and complex problems - Concurrent processing
It means that multiple programs in the same time period are between running and running, and these programs are running on the same processor (CPU), but only one program runs on the CPU at any time point
Synchronous and asynchronous
- synchronization
When a process executes a request, if the request encounters IO time-consuming, other processes will wait until the time-consuming process returns the result after execution - asynchronous
It refers to the time-consuming process. Other processes do not need to wait all the time, but perform their own tasks.
Single process
from random import randint
from time import time, sleep
def download_task(filename):
print('Start downloading%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s Download complete! Consumed%d second' % (filename, time_to_download))
def main():
start = time()
download_task('Python introduction.pdf')
download_task('av.avi')
end = time()
print('Total cost%.2f second.' % (end - start))
if __name__ == '__main__':
main()
result
Start downloading Python introduction.pdf...
Python introduction.pdf Download complete! It took eight seconds
Start downloading av.avi...
av.avi Download complete! It took seven seconds
It took a total of 15 minutes.03 second.
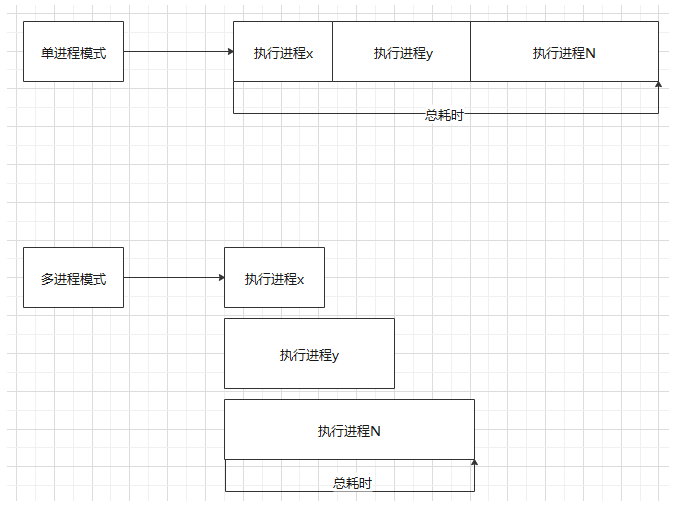
The run is executed sequentially, so the time consumption is the sum of the time of multiple processes
Because it is a single process task, all tasks are queued, so the execution efficiency is very low. Let's add the multi process mode to execute multiple processes at the same time. In this way, when one process executes, the other process does not need to wait, and the execution time will be greatly shortened.
Multi process
from random import randint
from time import time, sleep
from multiprocessing import Process
from os import getpid
def download_task(filename):
print('Start the download process, process number:[%d]'%getpid())
print('Start downloading%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s Download complete! Consumed%d second' % (filename, time_to_download))
def main():
start = time()
p1 = Process(target=download_task,args=('python introduction.pdf',))
p2 = Process(target=download_task,args=('av.avi',))
p1.start()
p2.start()
p1.join()
p2.join()
# download_ Task ('getting started with Python. pdf ')
# download_task('av.avi')
end = time()
print('Total cost%.2f second.' % (end - start))
if __name__ == '__main__':
main()
Multiple processes are executed side by side. The total time is the time of the longest process.
The characteristic of multi process is that they are independent of each other and will not share global variables, that is, after modifying the global variables in one process, they will not affect the global variables in another process.
Queue queue implements interprocess communication
from random import randint
from time import time,sleep
from multiprocessing import Process
import multiprocessing
from os import getpid
time_to_download = 3
def write(q):
for i in ['python introduction','av.avi','java introduction']:
q.put(i)
print('Start writing process, process number:[%d]'%getpid())
print('Start writing%s...' % i)
sleep(time_to_download)
def read(q):
while True:
if not q.empty():
print('Start reading process, process number:[%d]'%getpid())
print('Start reading%s...' % q.get())
sleep(time_to_download)
else:
break
def main():
q = multiprocessing.Queue()
p1 = Process(target=write,args=(q,))
p2 = Process(target=read,args=(q,))
p1.start()
p1.join()
p2.start()
p2.join()
if __name__ == '__main__':
main()