"Everything is a document" is the basic design philosophy of UNIX. Files are organized into tree directories according to hierarchical relationships, which constitute the basic form of the file system. When using the file system to save data, users do not need to care about the underlying storage mode of data, and can access it according to the agreed interface specification.
Concept article
POSIX is the most widely used interface specification for file system, which comes from the relevant standards prepared by IEEE Committee, and some chapters are about file and directory operation. The standard itself is rather lengthy and obscure, so it will not be discussed in depth here. We can refer to a Q & A on Quora“ What does POSIX conformance/compliance mean in the distributed systems world? ”, the summary is relatively comprehensive.
POSIX compatibility requires file systems to have the following characteristics:
- Hierarchical directory structure, supporting any depth
- Files are created through open(O_CREAT), directories are created through mkdir, and so on
- Directories can be traversed through opendir/readdir
- The path / namespace can be modified through rename, link / unlink, symlink / readlink, etc
- The data is written through write or writev. It is required to be persistent during fsync and read through read or readv
- Other interfaces such as stat, chmod / chown, etc
- Contrary to some popular claims, extended attributes do not seem to be part of POSIX, see The Open Group Base Specifications Issue 7, 2018 edition List of functions in
Test article
Whether a file system really meets POSIX compatibility can be verified by testing tools. A popular test case set is pjdfstest, which comes from FreeBSD and is also applicable to Linux and other systems. The test case of pjdfstest needs to be run as root, and Perl and TAP::Harness (Perl package) are required to be installed in the system. The test process is as follows:
cd /path/to/filesystem/under/test sudo prove --recurse --verbose /path/to/pjdfstest/tests
We selected several shared file systems in the cloud environment for testing, and the failure cases in the statistical test results are as follows:
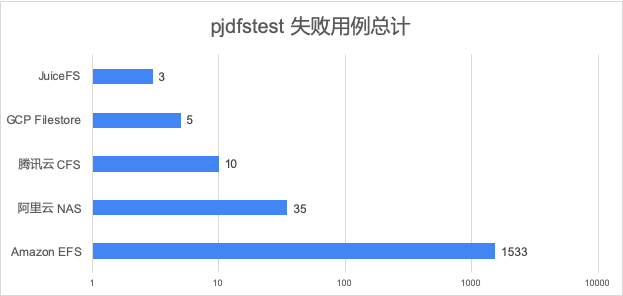
Because the test cases failed by Amazon EFS are several orders of magnitude larger than other products, the abscissa in the figure above uses logarithmic coordinates for comparison.
We also tested S3FS and Goofys at the same time, and the number of failed use cases was hundreds or even thousands. The fundamental reason is that these two projects are not designed in strict accordance with the file system:
- Goofys can mount S3 as a file system, but it is only a "Filey" system with a "POSIX ish" interface (these two descriptions come from the official project introduction and are translated into Chinese, that is, "specious" or "seemingly divorced"). In terms of design concept, goofys sacrifices POSIX compatibility for performance, and the supported file operations are greatly limited by the object storage itself such as S3. The test results also verify this. It is recommended to comprehensively review the data access mode of the application before production and use, so as to avoid falling into a trap.
- Although S3FS is called file system, it is actually closer to a method of managing objects in S3 bucket with file system view. Although S3FS supports a large subset of POSIX, it only maps system calls to object storage requests one by one, and does not support the semantics and consistency of conventional file systems (such as atomic renaming of directories, mutual exclusion when exclusive mode is turned on, overwriting the entire file by attaching file contents, and hard connection is not supported). Even if the performance of the file system used to replace S3FS is far from meeting the expected performance of the file system, which should not be considered when the file system used to replace S3FS does not meet the specification.
Analysis
Next, we will classify and count the failed test cases, and select several representative ones to analyze the restrictions on the application.
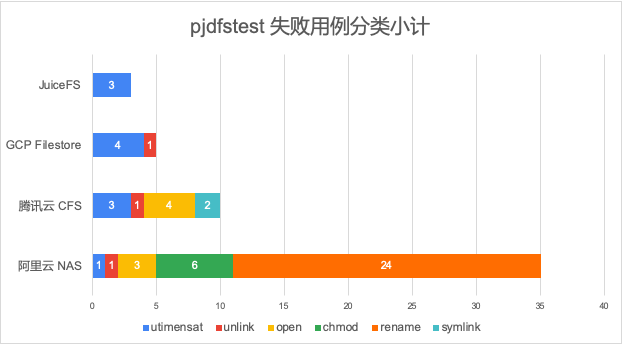
In general, JuiceFS has fewer failure cases and better compatibility in terms of quantity and category. The failure cases of Amazon EFS greatly exceed other file systems in terms of total number and category, and cannot be put into the same chart for comparison, which will be analyzed separately later.
JuiceFS
JuiceFS passed the vast majority of 8811 use cases in this test, and only 3 failed in the utimensat test set. The corresponding logs are as follows:
... /root/pjdfstest/tests/utimensat/08.t ........ not ok 5 - tried 'lstat pjdfstest_bfaee1fc7f2c1f80768e30f203f41627 atime_ns', expected 100000000, got 0 not ok 6 - tried 'lstat pjdfstest_bfaee1fc7f2c1f80768e30f203f41627 mtime_ns', expected 200000000, got 0 Failed 2/9 subtests /root/pjdfstest/tests/utimensat/09.t ........ not ok 5 - tried 'lstat pjdfstest_7911595d91adcf915009f551ac48e1f2 mtime', expected 4294967296, got 0
These test cases are from utimensat/08.t and utimensat/09.t . Of which 08 T is to test the accuracy of sub second file access time and modification time, 09 T is required to support 64 bit timestamp.
At present, JuiceFS only supports seconds, and the timestamp is saved as a 32-bit integer, so it cannot pass these three tests (in fact, all file systems involved in this test cannot pass 100% of this test set). If your application scenario requires a time accuracy of less than seconds or a larger range, please contact us to discuss the solution.
GCP Filestore
In addition to several failure results on the utimesat test set like JuiceFS, GCP Filestore also failed one item in the unlink test set. This one also fails in all other file systems.
/root/pjdfstest/tests/unlink/14.t ........... not ok 4 - tried 'open pjdfstest_b03f52249a0c653a3f382dfe1237caa1 O_RDONLY : unlink pjdfstest_b03f52249a0c653a3f382dfe1237caa1 : fstat 0 nlink', expected 0, got 1
This test set( unlink/14.t )Used to verify the behavior of a file when it is deleted in the open state:
desc="An open file will not be immediately freed by unlink"
At the system level, the operation of deleting a file actually corresponds to unlink, that is, remove the link from the file name to the corresponding inode, and the value of the corresponding nlink minus 1. This test case is to verify this.
# A deleted file's link count should be 0
expect 0 open ${n0} O_RDONLY : unlink ${n0} : fstat 0 nlinkThe contents of the file will be deleted only when the number of links (nlink) is reduced to 0 and there is no open file descriptor (fd) pointing to the file. If nlink is not updated correctly, the files that should be deleted may still remain in the system.
CFS
Compared with Google Filestore, CFS has not passed several tests of open and symlink.
open failure case
Select some of the failure logs as follows:
/root/pjdfstest/tests/open/07.t ............. not ok 5 - tried '-u 65534 -g 65534 open pjdfstest_f24a42815d59c16a4bde54e6559d0390 O_RDONLY,O_TRUNC', expected EACCES, got 0 not ok 7 - tried '-u 65533 -g 65534 open pjdfstest_f24a42815d59c16a4bde54e6559d0390 O_RDONLY,O_TRUNC', expected EACCES, got 0 not ok 9 - tried '-u 65533 -g 65533 open pjdfstest_f24a42815d59c16a4bde54e6559d0390 O_RDONLY,O_TRUNC', expected EACCES, got 0 Failed 3/23 subtests
This test set is open / 07 T is used to verify that o should be checked when you do not have write permission_ TRUNC mode returns the behavior of EACCES error.
desc="open returns EACCES when O_TRUNC is specified and write permission is denied"
The above three failure logs need to be analyzed in combination with the test code, corresponding to owner, group and other respectively. Without losing generality, we only analyze the owner:
expect 0 -u 65534 -g 65534 chmod ${n1} 0477
expect EACCES -u 65534 -g 65534 open ${n1} O_RDONLY,O_TRUNCFirst set the file owner permission to 4, that is, r-- read-only, and then try to use o_ RDONLY,O_ When a file is opened in TRUNC mode, EACCES is expected to be returned, but 0 is actually returned.
according to The Single UNIX ® Specification, Version 2 Middle to o_ Description of TRUNC
O_TRUNC
If the file exists and is a regular file, and the file is successfully opened O_RDWR or O_WRONLY, its length is truncated to 0 and the mode and owner are unchanged. It will have no effect on FIFO special files or terminal device files. Its effect on other file types is implementation-dependent. The result of using O_TRUNC with O_RDONLY is undefined.
O_TRUNC and o_ The result of rdonly combination is unknown, and the tested file of this use case itself is an empty file, O_TRUNC has no effect.
symlink failure case
The corresponding test logs are as follows:
/root/pjdfstest/tests/symlink/03.t .......... not ok 1 - tried 'symlink 7ea12171c487d234bef89d9d77ac8dc2929ea8ce264150140f02a77fc6dcad7c3b2b36b5ed19666f8b57ad861861c69cb63a7b23bcc58ad68e132a94c0939d5/.../... pjdfstest_57517a47d0388e0c84fa1915bf11fe4a', expected 0, got EINVAL not ok 2 - tried 'unlink pjdfstest_57517a47d0388e0c84fa1915bf11fe4a', expected 0, got ENOENT Failed 2/6 subtests
This test set( symlink/03.t )Path exceeded for test_ Behavior of symblink at max length
desc="symlink returns ENAMETOOLONG if an entire length of either path name exceeded {PATH_MAX} characters"The corresponding code of the failed case is as follows:
n0=`namegen`
nx=`dirgen_max`
nxx="${nx}x"
mkdir -p "${nx%/*}"
expect 0 symlink ${nx} ${n0}
expect 0 unlink ${n0}The test case is to create a path of length_ The symbolic link of max (including 0 at the end) does not pass, indicating that the path cannot be created on Tencent cloud NAS_ Symbolic link of max.
Alibaba cloud NAS
Compared with Tencent cloud NAS, Alibaba cloud NAS performs normally on symlink, but fails to pass several test cases on chmod and rename.
chmod failure case
In this test set, Alibaba cloud NAS failed the following projects
/root/pjdfstest/tests/chmod/12.t ............ not ok 3 - tried '-u 65534 -g 65534 open pjdfstest_db85e6a66130518db172a8b6ce6d53da O_WRONLY : write 0 x : fstat 0 mode', expected 0777, got 04777 not ok 4 - tried 'stat pjdfstest_db85e6a66130518db172a8b6ce6d53da mode', expected 0777, got 04777 not ok 7 - tried '-u 65534 -g 65534 open pjdfstest_db85e6a66130518db172a8b6ce6d53da O_RDWR : write 0 x : fstat 0 mode', expected 0777, got 02777 not ok 8 - tried 'stat pjdfstest_db85e6a66130518db172a8b6ce6d53da mode', expected 0777, got 02777 not ok 11 - tried '-u 65534 -g 65534 open pjdfstest_db85e6a66130518db172a8b6ce6d53da O_RDWR : write 0 x : fstat 0 mode', expected 0777, got 06777 not ok 12 - tried 'stat pjdfstest_db85e6a66130518db172a8b6ce6d53da mode', expected 0777, got 06777 Failed 6/14 subtests
This test set( chmod/12.t )Used to test the behavior of SUID/SGID bits
desc="verify SUID/SGID bit behaviour"
We select the 11th and 12th test cases to explain in detail, and cover these two permission bits at the same time
# Check whether writing to the file by non-owner clears the SUID+SGID.
expect 0 create ${n0} 06777
expect 0777 -u 65534 -g 65534 open ${n0} O_RDWR : write 0 x : fstat 0 mode
expect 0777 stat ${n0} mode
expect 0 unlink ${n0}Here, we first create the target file with the permission of 06777, then modify the file content and check whether the SUID and SGID are cleared correctly. 777 in file permissions will be familiar to you. It corresponds to rwx of owner, group and other, which can be read, written and executed. The first 0 represents an octal number.
The second bit 6 needs to be explained emphatically. This octet represents special permission bits. The first two bits correspond to setuid/setgid (or SUID/SGID) respectively, which can be applied to executable files and public directories. When this permission bit is set, any user will run the file as owner (or group). This special attribute allows users to gain access to files and directories that are usually only open to the owner. For example, the passwd command sets the setuid permission, which allows ordinary users to modify the password, because the file that stores the password is only allowed to be accessed by root, and users cannot modify it directly.
The starting point of setuid/setgid design is to provide a method for users to access restricted files (not owned by the current user) in a limited way (specify executable files). Therefore, when the file is modified by non owner, this permission bit should be cleared automatically to prevent users from obtaining other permissions through this way.
From the test results, we can see that in Alibaba cloud NAS, setuid/setgid are not cleared when the file is modified by a non owner. In fact, users can operate arbitrarily as the owner by modifying the file content, which will be a security risk.
Reference reading: Special File Permissions (setuid, setgid and Sticky Bit) (System Administration Guide: Security Services)
rename failure case
Alibaba cloud NAS has a large number of failures in this test set, reaching 24, all of which appear in rename/09.t Medium:
desc="rename returns EACCES or EPERM if the directory containing 'from' is marked sticky, and neither the containing directory nor 'from' are owned by the effective user ID"
This test set is used to check the behavior of rename when the sticky bit is set: when the sticky permission bit is set in the directory containing the source object, and the owner of the source object and the directory is different from the effective user ID, rename should return EACCES or EPERM. (such complex logic is reminiscent of the skill setting of generals killed by the Three Kingdoms...).
The typical application of sticky bit is the / tmp directory, which allows everyone to create content, but only the owner can delete files. The public upload directory in FTP is usually set in this way.
Several failed test cases show that Alibaba cloud NAS's support for sticky bit is not perfect. The rename operation of non owner is not rejected, and the actual effect - the source file is renamed. This behavior goes beyond the access control of file system and poses a threat to the security of user files.
Failure cases in Amazon EFS
Amazon Elastic File System (EFS) not only has a very high failure rate in pjdfstest (1533 of 8811 test cases failed), but also covers almost all categories, which is surprising.
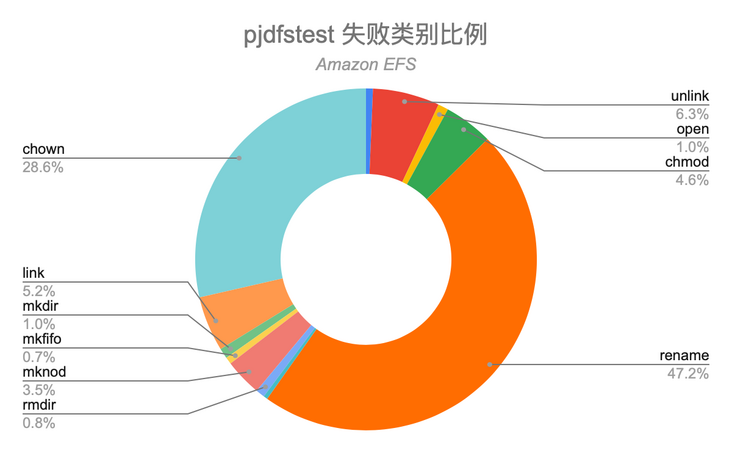
EFS supports NFS mounting, but the support for NFS features is incomplete. For example, EFS does not support block devices and character devices, which directly leads to the failure of a large number of test cases in pjdfstest. After excluding these two types of files, there are still hundreds of different types of failures, so we must be careful when applying EFS in complex scenes.
Conclusion
Through the above comparative analysis, JuiceFS performs best in terms of compatibility. Like most network file systems, it sacrifices time accuracy and range of less than seconds for performance (1970 - 2106). Google Filestore and Tencent cloud CFS came second, and several failed to pass. Alibaba cloud NAS and Amazon EFS have the worst compatibility, and a large number of compatibility tests fail, including several test cases with serious security risks. It is recommended to conduct security assessment before use.
JuiceFS has always attached great importance to the high compatibility of POSIX standards. We take pjdfstest and other compatibility testing tools together with other random and concurrent testing tools (such as fsracer, fstool, etc.) as integration testing tools. While continuously improving functions and improving performance, we try our best to maintain the maximum POSIX compatibility and avoid users falling into various traps in the process of use, So as to focus more on the development of their own business.
If you are helpful, please pay attention to our project Juicedata/JuiceFS Yo! (0ᴗ0✿)