Reprinted from Analyze PL0 lexical analyzer Some of the original blog is not easy to read, and some contents have been supplemented without deletion. 🥰 The code can be found in Yuanbo, which is implemented in PL/0 language.
PL/0 language is a subset of Pascal language. The compiler of PL/0 analyzed here includes Analyze and process the PL/0 language source program, compile and generate the class PCODE code, and explain the function of running the generated class PCODE code on the virtual machine.
PL/0 language compiler adopts A compilation method with syntax analysis as the core and one-time scanning. Lexical analysis and code generation are independent subroutines for the parser to call.
At the same time of syntax analysis, it provides the functions of error report and error recovery. When the source program is compiled without error, call the class PCODE interpreter to interpret and execute the generated class PCODE code.
Lexical analysis subroutine:
The lexical analysis subroutine is called getsym. Its function is to read a word symbol from the source program and put its information into the global variables sym, id and num. when the parser needs words, it can be obtained directly from these three variables.
🐷 be careful! Every time the parser runs out of the values of these three variables, it immediately calls the getsym subroutine to get a new word for the next use. Instead of calling the getsym procedure when a new word is needed.
getsym() gets characters from the source program by repeatedly calling the getch subprocess and spells them into words.
Row buffer technology is used in getch() to improve the running efficiency of the program.
Lexical analyzer analysis process: when calling getsym, it obtains a character from the source program through the getch process.
-
If the character is a letter, continue to obtain characters or numbers, and finally spell a word. Check the reserved word list. If it is found to be a reserved word, assign the sym variable to the corresponding reserved word type value; If it is not found, the word should be a user-defined identifier (possibly variable name, constant name or process name). Set sym as ident and store the word in the id variable. Dichotomy is used to look up the reserved word table to improve efficiency.
-
If the characters obtained by getch are numbers, continue to use getch to obtain numbers and spell them into an integer, then set sym to number and put the spell into the num variable.
-
If other legal symbols (such as assignment number, greater than sign, less than or equal to sign, etc.) are recognized, sym is assigned to the corresponding type.
-
If you encounter illegal characters, set sym to null.
Parsing subroutine:
The syntax analysis subroutine adopts the top-down recursive subroutine method. At the same time, the syntax analysis also generates the corresponding code according to the semantics of the program, and provides an error handling mechanism. Mainly by
| Function name | |
|---|---|
| block | Subprogram analysis process |
| constdeclaration | Constant definition analysis process |
| vardeclaration | Variable definition analysis process |
| statement | Statement analysis process |
| expression | Expression processing procedure |
| term | Item processing |
| factor | Factor processing process |
| condition | Conditional processing |
Composition. These processes form a nested hierarchy in structure.
In addition, there are
| Function name | Auxiliary process |
|---|---|
| error | Error reporting process |
| gen | Code generation process |
| test | Test word validity and error recovery process |
| enter | Login name table process |
| position | Query name table function |
| listcode | List class PCODE code procedures |
As an auxiliary process of grammar analysis.
Semantic analysis is also dealt with

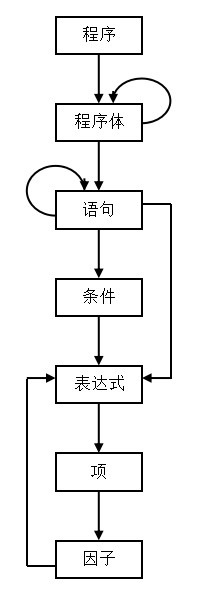
Syntax diagram by PL/0 Syntax description of PL/0 language It can be seen that a complete PL/0 program is composed of sub programs and periods. Therefore, when the compiler is running, it can analyze the part of the program by calling the block in the main program, which can also be called the block process recursively, and then determine whether the last read symbol is a full stop. If it is a period and there is no error in the sub program analysis, it is a legal PL/0 program and the generated code can be run. Otherwise, it indicates that the source PL/0 program is illegal and the error prompt can be output.
The operation mechanism of PL/0 compiler is analyzed according to each syntax unit:
🐟 After parsing starts, first call the block process to process the subprogram.
The process entry parameters are set to: 0 layer, symbol table position 0, error recovery word set to period, declarator or statement start.
After entering the block process, first set the local data segment allocation pointer dx to 3, and prepare to allocate 3 units for storing static chain SL, dynamic chain DL and return address RA during operation.
Then use tx0 to record the current symbol table position and generate a JMP instruction to jump to the start position of the main program. Since it is not known where the main program starts, the target of JMP is temporarily filled as 0 and will be changed later.
At the same time, record the position of the JMP instruction in the code segment at the current position of the symbol table. After judging that the number of nesting layers does not exceed the specified number of layers, start analyzing the source program.
Declaration part
First, judge whether the constant declaration is encountered. If so, start the constant definition and store the constant in the symbol table.
Next, analyze the variable declaration in the same way. During the variable definition process, dx variables will be used to record the number of spaces allocated by local data segments.
Then, if the procedure reserved word is encountered, the procedure declaration and definition are made:
The method of declaration is to record the name and level of the process in the symbol table;
The defined method is to call the block procedure recursively, because each procedure is a subprogram. Because this is a subprogram in the subprogram, when calling block, you need to add one to the current level number lev and pass it to the block process.
After the subprogram declaration part is completed, it will enter the statement processing. At this time, the value of the code allocation pointer cx just points to the beginning of the statement, which is the position to which the previous jmp instruction needs to jump.
Therefore, the jump position of the JMP instruction is changed to the current cx position through the previously recorded address value. And record the current code segment allocation address and the size of the local data segment to be allocated (the value of dx) in the symbol table. Generate an int instruction and allocate dx space as the first instruction of this sub program segment.
The corresponding code is as follows, and the second half of block() is intercepted
Statement part
Next, call the statement processing procedure statement to analyze the statement.
After the analysis is completed, the opr instruction with operand 0 is generated to return from the subprogram (for the main program of layer 0, it means that the program runs and exits).
Statement processing is a nested subroutine, which realizes the analysis of statements by calling expression processing, item processing, factor processing and recursive calling itself.
The statements that can be recognized during statement processing include assignment statement, read statement, write statement, call statement, if statement and while statement.
When a begin/end statement is encountered, it recursively calls itself for analysis. The corresponding PCODE like instructions are generated at the same time.
- Processing of assignment statement:
First, get the identifier on the left of the assignment number, find its information from the symbol table, and confirm that this identifier is indeed a variable name. Then, by calling the expression processing process, calculate the value of the expression on the right of the assignment number, and generate corresponding instructions to ensure that this value is placed on the top of the data stack during the run-time. Finally, the corresponding STO instruction is generated through the position information of the left variable, and the stack top value is stored in the specified variable space to realize the assignment operation. - Processing of read statement:
On the premise that the syntax of the read statement is reasonable (otherwise, an error is reported), generate the corresponding instruction:
The first is the OPR instruction of operation No. 16, which reads an integer value from the standard input and puts it on the top of the data stack.
The second is the STO instruction, which stores the value at the top of the stack in the unit of the variable in the parenthesis of the read statement. - Processing of write statement:
Similar to the read statement. On the premise of correct syntax, generate instructions: analyze each expression in the parenthesis of the write statement through the circular call expression processing process, generate corresponding instructions, ensure that the value of the expression is calculated and placed on the top of the data stack, generate the OPR instruction of operation 14, and output the value of the expression.
Finally, the OPR instruction of operation 15 is generated and a line feed is output. - Processing of call statement:
Find the identifier at the right of the call statement from the symbol table, and obtain its hierarchy and offset address. Then generate the corresponding CAL instruction.
As for the protection of the scene required for calling the sub process, it is automatically completed by the PCODE like interpreter when interpreting and executing the CAL instruction. - if statement processing:
According to the syntax of the if statement, first call the logical expression processing procedure to process the conditions of the if statement, and put the corresponding Boolean value on the top of the data stack.
Then, record the code segment allocation position (i.e. the position of the JPC instruction generated later), and then generate the conditional transfer JPC instruction (transfer when the top of the stack is false). If the transfer address is unknown, fill in 0 temporarily.
Call the statement processing procedure to process the statement or statement block after the then statement. After the statement after then is processed, the position of the current code segment allocation pointer should be the transfer position of the JPC instruction above.
Change its jump position to the current code segment pointer position through the previously recorded position of the JPC instruction. - Processing of begin/end statement:
Loop through each statement in the begin/end statement block, and recursively call the statement analysis process to analyze and generate the corresponding code. - Processing of while statement:
First, use the cx1 variable to record the allocation position of the current code segment as the starting position of the loop.
Then process the conditional expression in the while statement, generate the corresponding code, put the result on the top of the data stack, and then write down the current position with cx2 variable to generate conditional transfer instructions. If the transfer position is unknown, fill in 0.
By recursively calling the statement analysis process, the statement or statement block after the do statement is analyzed and the corresponding code is generated.
Finally, generate an unconditional jump instruction JMP, jump to the position indicated by cx1, and change the jump position of the conditional jump instruction indicated by cx2 to the current code segment allocation position. - Expression, item and factor processing:
According to PL/0 syntax, an expression should start with a sign or no sign and be connected by several items with plus and minus signs.
The term is composed of several factors connected by multiplication and division signs. The factor may be an identifier or a number, or a subexpression enclosed in parentheses.
According to this structure, the corresponding process is constructed, and the recursive call completes the processing of the expression.
The priority problem of addition and subtraction sign and multiplication and division sign is solved by separating items and factors.
In the repeated calls of these processes, the value of fsys variable is always passed to ensure that the wrong symbol can be skipped in case of error, so that the analysis process can continue. - Processing of logical expressions:
First, judge whether it is an unary operator - odd (parity).
If yes, analyze and calculate the value of the expression by calling the expression processing procedure, and then generate an odd judgment instruction.
If not, it must be a binary operator. By calling the expression processing process, analyze the left and right values of the operator in turn and put them in the two spaces at the top of the stack, and then generate corresponding logical judgment instructions according to different logical operators and put them into the code segment.
Analysis of the process of judging word validity and error recovery (test function):
This process has three parameters, s1 and s2 are two symbol sets, and n is the error code.
The function of this procedure is to test whether the current symbol (i.e. the value in the sym variable) is in the s1 set
If not, call the error report process to output the error code n, abandon the current symbol, and obtain the word through the lexical analysis process until the word appears in the s1 or s2 set.
When an error occurs in the source program, you can skip the wrong part in time to ensure that the syntax analysis can continue.
This process is very flexible in practical use. There are two main uses:
1. When entering a syntax unit, call this procedure to check whether the current symbol belongs to the starting symbol set of the syntax unit. If not, all symbols except the start symbol and subsequent symbol set are filtered out.
2. At the end of syntax unit analysis, call this procedure to check whether the current symbol belongs to the set of subsequent symbols that should be called when the syntax unit is called. If not, all symbols except the subsequent symbols and the start symbol set are filtered out.
Class PCODE code interpretation execution process analysis:

This process simulates a stack computer that can run PCODE like instructions.
It has a stack data segment for storing runtime data and a code segment for storing PCODE like program code. At the same time, it also has registers such as data segment allocation pointer, instruction pointer, instruction register and local segment base address pointer.
Explain that when executing PCODE like code, the data segment storage allocation method is as follows:
For each process of the source program (including the main program), when called, first open up three spaces in the data segment to store the static chain SL, dynamic chain DL and return address RA.
Static chain SL: records the base address of the latest data segment when the direct external process (or main program) defining the process runs.
When a child process wants to reference the variables of its direct or indirect parent process (the parent process here is determined according to the nesting situation when defining the process, rather than the calling order when executing), it can skip the data segments with a number of layers through the static chain, find the base address of the data segment containing the variable to be referenced, and then access it through the offset address.
Dynamic chain DL: records the data segment base address of the process running before calling the process.
Return address RA: records the breakpoint position of the program when the procedure is called.
For the main program, the values of SL, DL and RA are set to 0.
The function of static chain is that when a child process wants to reference the variables of its direct or indirect parent process (the parent process here is determined according to the nesting situation when defining the process, rather than the calling order when executing), it can skip the data segments with a number of layers through the static chain and find the base address of the data segment containing the variables to be referenced, It is then accessed through an offset address.
When the process returns, the interpreter restores the value of the instruction pointer to the address before the call by returning the address, restores the data segment allocation pointer through the current segment base address, and restores the local segment base address pointer through the dynamic chain. Implement the return of the subprocess.
For the main program, the interpreter will encounter the case that the return address is 0. At this time, it is considered that the program is finished.
The function of the base function in the interpreter process is to find the base address of the local data segment with a specified number of layers forward along the static chain. This is often used in instructions that use STO, LOD, etc. to access local variables.
Class PCODE code explains the execution part, judges different instructions and makes corresponding actions through loops and simple case s.
When encountering the return instruction in the main program, the instruction pointer will point to the position of 0. Take such a condition as the condition of the final loop to ensure that the program operation can end normally.
supplement 🧡
- Compiler: translate source code into object code.
Broadly speaking, any translation from one language to another is called a compiler - Early compilers: the processing language was relatively simple, and the memory was not rich at that time, so the abstract syntax tree was not used. just like me
Modern compilers generally use abstract syntax tree as the output of parser. Because there is better system support, abundant memory, and the language has become complex, the syntax tree can well simplify the design - Context free grammar: the meaning of one statement is not affected by other statements. For example, chestnuts:
Chinese is context sensitive: "I'm a good man. I sing very well. What I just said is false."
Assembly language and machine language are context independent. The CPU executes directly in sequence.
Context free languages are simpler to parse, and programming languages are basically context free. - How to get a lexical analyzer:
method1 handwriting:
Complex and error prone, but at present, the very popular GCC/LLVM is handwritten, because it can manually control all details, such as which algorithms and data structures to use, which will have high time and space efficiency. List details:
1) Using hash table to store keywords, the time efficiency can reach O(1)
2) Another way to distinguish keywords and identifiers: transforming DFA
3) If the matrix is used to realize DFA, the column order can be arranged according to ASCII, and the dichotomy is used when looking up the column
method2 automatic generation tool:
1) The amount of code is small, which liberates programmers, but it is difficult to control details, and the general efficiency is not very high
2) Just input the description of the normal expression of the word you want to recognize, and then convert it into DFA, which is implemented at the bottom of the program
3) Because it can be generated automatically and has universality, the gap between it and handwriting is not too large and can be ignored, so the macro efficiency of matrix is higher, because automatic generation tools can be used
What's your feeling?
- You must first understand BNF (symbolic expression describing language syntax) or state transition diagram. In short, you must understand syntax
- Only by understanding the class Pcode code can we understand why code at that place at that time is generated in the compiler code
- There are so many things. I still have a complete understanding of them
code
program pl0(input,output)); (* PL/0 Compiler and code generation interpreter *)
(* PL/0 compiler with code generation *)
label 99; (* Declaration error jump flag *)
const (* Constant definition *)
norw = 11; (* of reserved words *) (* Number of reserved words *)
txmax = 100; (* length of identifier table *) (* Length (capacity) of identifier table *)
nmax = 14; (* max number of digits in numbers *) (* Maximum number of digits allowed for a number *)
al = 10; (* length of identifiers *) (* Maximum length of identifier *)
amax = 2047; (* maximum address *) (* Addressing space *)
levmax = 3; (* max depth of block nesting *) (* Maximum allowed nesting levels of blocks *)
cxmax = 200; (* size of code array *) (* class PCODE Length of object code array (number of lines of code that can be accommodated) *)
type (* type definition *)
symbol = (nul, ident, number, plus, minus, times, slash, oddsym,
eql, neq, lss, leq, gtr, geq, lparen, rparen, comma,
semicolon, period, becomes, beginsym, endsym, ifsym,
thensym, whilesym, writesym, readsym, dosym, callsym,
constsym, varsym, procsym); (* symobl Types identify different types of words *)
alfa = packed array[1..al] of char; (* alfa Type for identifier *)
object1 = (constant, variable, procedur); (* object1 There are three types of identifiers *)
symset = set of symbol; (* symset yes symbol Type is a collection type that can be used to store a set of symbol *)
fct = (lit, opr, lod, sto, cal, int, jmp, jpc); (* fct The type identifies the class separately PCODE Instructions for *)
instruction = packed record
f: fct; (* function code *)
l: 0..levmax; (* level *)
a: 0..amax; (* displacement addr *)
end; (* class PCODE Instruction type, including three fields: instruction f,Layer difference l And another operand a *)
(*
lit 0, a load constant a
opr 0, a execute opr a
lod l, a load variable l, a
sto l, a store variable l, a
cal l, a call procedure a at level l
int 0, a increment t-register by a
jmp 0, a jump to a
jpc 0, a jump conditional to a
*)
var (* Global variable definition *)
ch: char; (* last char read *) (* It is mainly used for lexical analyzer to store the last characters read from the file *)
sym: symbol; (* last symbol read *) (* Lexical analyzer output results used to store the most recently recognized token Type of *)
id: alfa; (* last identifier read *) (* The lexical analyzer is used to output the result and store the name of the last recognized identifier *)
num: integer; (* last number read *) (* The lexical analyzer is used to output the result and store the value of the last recognized number *)
cc: integer; (* character count *) (* Row buffer pointer *)
ll: integer; (* line length *) (* Row buffer length *)
kk: integer; (* This variable is introduced for program performance, see getsym Process notes *)
cx: integer; (* code allocation index *) (* Code allocation pointer, code generation module is always in cx Generate new code at the indicated location *)
line: array[1..81] of char; (* Line buffer, which is used to read a line from the file and obtain words through confession analysis *)
a: alfa; (* Lexical analyzer is used to temporarily store the words being analyzed *)
code: array[0..cxmax] of instruction; (* Generated class PCODE The code table stores the compiled classes PCODE code *)
word: array[1..norw] of alfa; (* Reserved word list *)
wsym: array[1..norw] of symbol; (* Corresponding to each reserved word in the reserved word list symbol type *)
ssym: array[' '..'^'] of symbol; (* Some symbols correspond to symbol Type table *)
(* wirth uses "array[char]" here *)
mnemonic: array[fct] of packed array[1..5] of char;(* class PCODE Instruction mnemonic table *)
declbegsys, statbegsys, facbegsys: symset; (* Collection of declaration start, expression start, and item start symbols *)
table: array[0..txmax] of record (* Symbol table *)
name: alfa; (* Name of symbol *)
case kind: object1 of (* Type of symbol *)
constant: (* If it is a constant name *)
(val: integer); (* val Middle constant value *)
variable, procedur: (* If it is a variable name or procedure name *)
(level, adr, size: integer) (* Storage layer difference, offset address and size *)
(* "size" lacking in orginal. I think it belons here *)
end;
fin, fout: text; (* fin The text file is used to point to the input source program file, fout Not used in the program *)
sfile: string; (* deposit PL/0 The file name of the source file *)
<analysis PL0 Lexical analysis program
(* Error handling procedure error *)
(* Parameters: n:Error code *)
procedure error(n: integer);
begin
writeln('****', ' ': cc-1, '!', n:2); (* On screen cc-1 Position display!And error code prompt, due to cc
Is a line buffer pointer, so!The location indicated is the error location *)
writeln(fa1, '****', ' ': cc-1, '!', n:2); (* In file cc-1 Position output!And error code prompt *)
err := err + 1 (* Total number of errors plus one *)
end (* error *);
(* Lexical analysis process getsym *)
procedure getsym;
var
i, j, k: integer;
(* The process of reading the next character in the original program getch *)
procedure getch;
begin
if cc = ll then (* If the line buffer pointer points to the last character of the line buffer, a line is read from the file to the line buffer *)
begin
if eof(fin) then (* If you reach the end of the file *)
begin
write('Program incomplete'); (* Error, exit the program *)
close(fin);
exit;
end;
ll := 0; (* Row buffer length set to 0 *)
cc := 0; (* Line buffer pointer at the beginning of the line *)
write(cx: 4, ' '); (* output cx Value, width 4 *)
write(fa1, cx: 4, ' '); (* output cx Value, width 4 to file *)
while not eoln(fin) do (* When the end of the line is not reached *)
begin
ll := ll + 1; (* Line buffer length plus one *)
read(fin, ch); (* Read a character from the file to ch *)
write(ch); (* Output on screen ch *)
write(fa1, ch); (* hold ch output to a file *)
line[ll] := ch; (* Store the read characters in the corresponding position of the line buffer *)
end;
(* so PL/0 The source program requires that the length of each line is less than 81 characters *)
writeln;
ll := ll + 1; (* The length of the line buffer plus one is used to hold the carriage return to be read in CR *)
read(fin, line[ll]);(* hold#13(CR) read in line buffer tail *)
read(fin, ch); (* The code I added. because PC Wrap text file on#13#10(CR+LF),
So take the extra LF Read from the file and put it here ch Variable is due to ch Variable
The value will be changed below. Put this extra value in ch There is no problem in the *)
writeln(fa1);
end;
cc := cc + 1; (* The line buffer pointer plus one points to the character to be read *)
ch := line[cc] (* Read out the characters and put them into the global variable ch *)
end (* getch *);
begin (* getsym *)
while (ch = ' ') do getch;
if ch in ['a'..'z'] then (* If the read character is a letter, it indicates that it is a reserved word or identifier *)
begin
k := 0; (* Identifier buffer pointer set to 0 *)
repeat (* This loop is used to read out the characters in the source file in turn to form the identifier *)
if k < al then (* If the identifier length does not exceed the maximum identifier length(If it exceeds, take the front part and discard the excess) *)
begin
k := k + 1;
a[k] := ch;
end;
getch (* Read next character *)
until not (ch in ['a'..'z','0′..'9′]); (* Until you don't read letters or numbers PL/0 The identifier composition rule is:
Start with a letter followed by several letters or numbers *)
if k >= kk then (* If the length of the currently obtained identifier is greater than or equal to kk *)
kk := k (* order kk Is the length of the current identifier *)
else
repeat (* This loop is used to fill the space at the back of the identifier buffer without corresponding letters or spaces with spaces *)
a[kk] := ' ';
kk := kk – 1
until kk = k;
(* When you first run this process, kk The value of is al,That is, the maximum identifier length. If the read identifier length is less than kk,
Just put a The space without letters at the back of the array is filled with spaces.
At this time, kk The value of becomes a The number of non whitespace characters in the front of the array. Run later getsym If the length of the read identifier is greater than or equal to kk,
Just put kk The value of becomes the length of the current identifier.
At this time, you don't have to fill in the blank space behind it, because it must be full of spaces. Conversely, if the length of the recently read identifier is less than kk,Then you need to start kk Position forward,
Fill the space that exceeds the length of the current logo with spaces.
The above logic is entirely based on the consideration of program performance. In fact, you can simply a In array a[k]The space after the element is filled in no matter three, seven, twenty-one.
*)
(* Let's start the binary search to see if the read identifier is one of the reserved words *)
id := a; (* The last read identifier is equal to a *)
i := 1; (* i Point to the first reserved word *)
j := norw; (* j Point to the last reserved word *)
repeat
k := (i + j) div 2; (* k Point to the middle reserved word *)
if id <= word[k] then (* If the current identifier is less than k Reserved word referred to *)
j := k – 1; (* move j Pointer *)
if id >= word[k] then (* If the current identifier is greater than k Reserved word referred to *)
i := k + 1 (* move i Pointer *)
until i > j; (* Cycle until the reserved word table is found *)
if i – 1 > j then (* If i – 1 > j Indicates that the corresponding item is found in the reserved word table, id There are reserved words in the *)
sym := wsym[k] (* Find the reserved word and put it sym Set to the corresponding reserved word value *)
else
sym := ident (* Reserved word not found, put sym Set as ident Type, indicating that it is an identifier *)
end(* At this point, the read character is a letter, that is, the processing of the reserved word or identifier ends *)
else (* If the read character is not a letter *)
if ch in ['0'..'9′] then (* If the read character is a number *)
begin (* number *) (* Start processing numbers *)
k := 0; (* Number of digits *)
num := 0; (* The number is set to 0 *)
sym := number; (* Set sym by number,It means that what you read this time is a number *)
repeat (* This loop reads characters from the source file in turn to form numbers *)
num := 10 * num + (ord(ch) – ord('0')); (* num * 10 Add the most recently read characters ASCII reduce'0'of ASCII Get the corresponding value *)
k := k + 1; (* Number of digits plus one *)
getch
until not (ch in ['0'..'9′]); (* Until the read character is not a number *)
if k > nmax then (* If the number of digits of the composition is greater than the maximum number of digits allowed *)
error(30) (* Issue error number 30 *)
end(* At this point, the recognition processing of numbers is completed *)
else
if ch = ':' then (* If you don't read letters or numbers, but colons *)
begin
getch; (* Read another character *)
if ch = '=' then (* If you read an equal sign, it can form an assignment sign with a colon *)
begin
sym := becomes; (* sym The type of is set as the assignment number becomes *)
getch (* Read the next word *)
end
else
sym := nul; (* If you don't read the equal sign, a single colon is nothing *)
end(* The above completes the processing of the assignment number *)
else (* If you read neither letters nor numbers nor colons *)
if ch = '<' then (* If you read the less than sign *)
begin
getch; (* Read another character *)
if ch = '=' then (* If you read the equal sign *)
begin
sym := leq; (* Purchase a less than or equal sign *)
getch (* Read a character *)
end
else (* If the less than sign is not followed by an equal sign *)
sym := lss (* That's a separate less than sign *)
end
else (* If you read neither letters nor numbers, nor colons nor less than signs *)
if ch = '>' then (* If the greater than sign is read, the process is similar to the less than sign *)
begin
getch; (* Read another character *)
if ch = '=' then (* If you read the equal sign *)
begin
sym := geq; (* Purchase a sign greater than or equal to *)
getch (* Read a character *)
end
else (* If the greater than sign is not followed by the equal sign *)
sym := gtr (* That's a separate greater than sign *)
end
else(* If you read that it is neither a letter nor a number, nor a colon, nor a less than sign, nor a greater than sign *)
begin (* That means it's not an identifier/Reserved word is not a complex double byte operator. It should be an ordinary symbol *)
sym := ssym[ch]; (* Directly find its type in the symbol table and assign it to sym *)
getch (* Read next character *)
end
(* whole if End of statement judgment *)
end (* getsym *);
(* Lexical analysis process getsym Summary: read several valid characters from the source file to form a token String to identify its type
Reserved word/identifier /Numbers or other symbols. If it's a reserved word, put sym Set to the corresponding reserved word type, if yes
Identifier, put sym Set into ident Indicates that it is an identifier. At the same time, id Variables are reserved word strings or identifiers
Character name. If it's a number, put it sym Set as number,meanwhile num Variable to store the value of the number. If it's another operator,
Then directly sym Set to the corresponding type. After this process ch The next character to be recognized is stored in the variable *)
(* Object code generation process gen *)
(* Parameters: x:Mnemonic of a line of code to be generated *)
(* y, z:Two operands of the code *)
(* This procedure is used to write the generated object code into the object code array for interpretation and execution by the subsequent interpreter *)
procedure gen(x: fct; y, z: integer);
begin
if cx > cxmax then (* If cx>cxmax Indicates that the currently generated code line number is greater than the maximum number of allowed code lines *)
begin
write('program too long'); {goto 99}(* Output program is too long, exit *)
end;
with code[cx] do
begin f := x; l := y; a := z
end;
cx := cx + 1
end {gen};
(* The process of testing whether the current word is legal test *)
(* Parameters: s1:When parsing enters or exits a grammar unit, the current word matches the set to which it belongs *)
(* s2:In a certain error state, the supplementary word set that can restore the normal operation of grammar analysis *)
(* n:Error message number, when the current symbol is not legal s1 Error message from collection *)
procedure test(s1, s2: symset; n: integer);
begin
if not (sym in s1) then (* If the current symbol is not s1 in *)
begin
error(n); (* issue n Number error *)
s1 := s1 + s2; (* hold s2 Set replenishment s1 aggregate *)
while not (sym in s1) do (* Find the next legal symbol through the loop to resume parsing *)
getsym
end
end (* test *);
(* Parsing process block *)
(* Parameters: lev:The level of parsing this time *)
(* tx:Symbol table pointer *)
(* fsys:Set of words for error recovery *)
procedure block(lev, tx: integer; fsys: symset);
var
dx: integer; (* data allocation index *) (* Data segment memory allocation pointer, pointing to the offset position of the next allocated space in the data segment *)
tx0: integer; (* initial table index *) (* Record the position of the symbol table at the beginning of this layer *)
cx0: integer; (* initial code index *) (* Record the code segment allocation position at the beginning of this layer *)
(* Login symbol table process enter *)
(* Parameters: k:The symbol type to log in to the symbol table *)
procedure enter(k: object1);
begin (* enter object into table *)
tx := tx + 1; (* The symbol table pointer points to a new empty bit *)
with table[tx] do (* Start login *)
begin
name := id; (* name Is the name of the symbol. For identifiers, this is the name of the identifier *)
kind := k; (* Symbol type, which can be a constant, variable, or procedure name *)
case k of (* Perform different operations according to different types *)
constant: (* If it is a constant name *)
begin
if num > amax then (* When the value of the constant is greater than the maximum allowed *)
begin
error(31); (* Error 31 thrown *)
num := 0; (* The actual login number is replaced by 0 *)
end;
val := num (* If it is a legal value, log in to the symbol table *)
end;
variable: (* If it is a variable name *)
begin
level := lev; (* Write down the level number to which it belongs *)
adr := dx; (* Note its offset in the current layer *)
dx := dx+1; (* The offset increases by one to prepare for the next time *)
end;
procedur: (* If you want to log in to the process name *)
level := lev (* Record the level of the process *)
end
end
end (* enter *);
(* The login symbol process does not take into account the problem of duplicate definitions. In case of duplicate definitions, the last definition shall prevail. *)
(* Finds the function that specifies the location of the symbol in the symbol table position *)
(* Parameters: id:Symbol to find *)
(* Return value: the position of the symbol to be found in the symbol table. If it is not found, it returns 0 *)
function position (id: alfa): integer;
var
i: integer;
begin (* find identifier in table *)
table[0].name := id; (* First id Put it in position 0 of the symbol table *)
i := tx; (* Start from the current position in the symbol table, that is, the last symbol *)
while table[i].name <> id do (* If the current symbol is inconsistent with the one you are looking for *)
i := i – 1; (* Find the front one *)
position := i (* Returns the location number found. If it is not found, it must be exactly 0 *)
end(* position *);
(* Constant declaration process constdeclaration *)
procedure constdeclaration;
begin
if sym = ident then (* The first symbol encountered at the beginning of the constant declaration process must be an identifier *)
begin
getsym; (* Get next token *)
if sym in [eql, becomes] then (* If it is an equal sign or assignment sign *)
begin
if sym = becomes then (* In case of assignment number(Constant Shengming should be an equal sign) *)
error(1); (* Throw error 1 *)
(* In fact, error correction is automatically performed here to continue the compilation, and the assignment number is treated as an equal sign *)
getsym; (* Get next token,The equal sign or assignment sign shall be followed by a number *)
if sym = number then (* If it's a number *)
begin
enter(constant); (* Log this constant into the symbol table *)
getsym (* Get next token,Prepare for the back *)
end
else
error(2) (* If the equal sign is not followed by a number, error No. 2 is thrown *)
end
else
error(3) (* If the constant identifier is not followed by an equal sign or assignment number, error No. 3 is thrown *)
end
else
error(4) (* If the first symbol encountered in the constant declaration process is not an identifier, error No. 4 is thrown *)
end(* constdeclaration *);
(* Variable declaration procedure vardeclaration *)
procedure vardeclaration;
begin
if sym = ident then (* The first symbol encountered at the beginning of the variable declaration process must be an identifier *)
begin
enter(variable); (* Log the identifier into the symbol table *)
getsym (* Get next token,Prepare for the back *)
end
else
error(4) (* If the first symbol encountered in the variable declaration process is not an identifier, error No. 4 is thrown *)
end(* vardeclaration *);
(* Lists the current level of classes PCODE Object code process listcode *)
procedure listcode;
var
i: integer;
begin (* list code generated for this block *)
if listswitch then (* If the user chooses to list codes, the codes are listed only *)
begin
for i := cx0 to cx – 1 do (* From the current layer code start position to the current code position-1 This is the subprogram block *)
with code[i] do
begin
writeln(i: 4, mnemonic[f]: 5, l: 3, a: 5); (* The second page is displayed i Mnemonic and of line code L And A Operand *)
(* I modified the code: the original program is output here i The width of 4 characters is not specified, which is not beautiful and does not match the following sentence. *)
writeln(fa, i: 4, mnemonic[f]: 5, l: 3, a: 5) (* Print the screen display to the file at the same time *)
end;
end
end(* listcode *);
(* Statement processing procedure statement *)
(* Parameter Description: fsys: A collection of symbols that can be used to recover parsing if an error occurs *)
procedure statement(fsys: symset);
var
i, cx1, cx2: integer;
(* Expression processing procedure expression *)
(* Parameter Description: fsys: A collection of symbols that can be used to recover parsing if an error occurs *)
procedure expression(fsys: symset);
var
addop: symbol;
(* Item processing term *)
(* Parameter Description: fsys: A collection of symbols that can be used to recover parsing if an error occurs *)
procedure term(fsys: symset);
var
mulop: symbol;
(* Factor processing process factor *)
(* Parameter Description: fsys: A collection of symbols that can be used to recover parsing if an error occurs *)
procedure factor(fsys: symset);
var
i: integer;
begin
test(facbegsys, fsys, 24); (* Check the current before starting factor processing token Is it facbegsys In the collection. *)
(* If it's not legal token,Throw error 24 and pass fsys Set recovery allows syntax processing to continue *)
while sym in facbegsys do (* Cyclic processing factor *)
begin
if sym = ident then (* If an identifier is encountered *)
begin
i := position(id); (* Check the symbol table to find the position of the current identifier in the symbol table *)
if i = 0 then (* If the symbol table lookup returns 0, the identifier is not found *)
error(11) (* Throw error 11 *)
else
with table[i] do (* If the location of the current identifier is found in the symbol table, start generating the corresponding code *)
case kind of
constant: gen(lit, 0, val); (* If this identifier corresponds to a constant, the value is val,generate lit Command, put val Put it on the top of the stack *)
variable: gen(lod, lev – level, adr); (* If the identifier is a variable name, generate lod Instructions, *)
(* Place at a distance from the current layer level The offset address of the layer is adr Put the variable at the top of the stack *)
procedur: error(21) (* If the identifier encountered in factor processing is the process name, an error occurs, throw error No. 21 *)
end;
getsym (* Get next token,Continue cycle processing *)
end
else
if sym = number then (* If a number is encountered during factor processing *)
begin
if num > amax then (* If the size of the number exceeds the maximum allowed value amax *)
begin
error(31); (* Throw error 31 *)
num := 0 (* Process the number as 0 *)
end;
gen(lit, 0, num); (* generate lit Instruction to put this numeric literal constant at the top of the stack *)
getsym (* Get next token *)
end
else
if sym = lparen then (* If the left parenthesis is encountered *)
begin
getsym; (* Get a token *)
expression( [rparen] + fsys ); (* Recursive call expression The subroutine analyzes a subexpression *)
if sym = rparen then (* A closing parenthesis should be encountered after the subexpression has been parsed *)
getsym (* If you do encounter a closing bracket, read the next one token *)
else
error(22) (* Otherwise, error 22 will be thrown *)
end;
test(fsys, facbegsys, 23) (* After a factor is processed, the problem is encountered token Should be fsys In collection *)
(* If not, throw error 23 and find the beginning of the next factor so that the parsing can continue *)
end
end(* factor *);
begin (* term *)
factor([times, slash] + fsys); (* Each item should start with a factor, so call factor Subroutine Analysis Factor *)
while sym in [times, slash] do (* A multiplication or division sign should be encountered after a factor *)
begin
mulop := sym; (* Save current operator *)
getsym; (* Get next token *)
factor(fsys + [times, slash]); (* Operator should be followed by a factor, so it is called factor Subroutine Analysis Factor *)
if mulop = times then (* If you just met the multiplier *)
gen(opr, 0, 4) (* Generate multiplication instruction *)
else
gen(opr, 0, 5) (* Not a multiplication sign, it must be a division sign. Generate a division instruction *)
end
end (* term *);
begin (* expression *)
if sym in [plus, minus] then (* An expression may begin with a plus or minus sign, indicating a plus or minus sign *)
begin
addop := sym; (* Save the current plus or minus sign so that the corresponding code can be generated below *)
getsym; (* Get a token *)
term(fsys + [plus, minus]); (* The sign should be followed by an item, key term Subroutine Analysis *)
if addop = minus then (* If the saved symbol is a minus sign *)
gen(opr, 0, 1) (* Generate an operation instruction No. 1: inverse operation *)
(* If it is not a negative sign or a positive sign, there is no need to generate the corresponding instruction *)
end
else (* If it does not start with a sign, it should start with an item *)
term(fsys + [plus, minus]); (* call term Subprogram analysis item *)
while sym in [plus, minus] do (* Item should be followed by addition or subtraction *)
begin
addop := sym; (* Save the operator *)
getsym; (* Get next token,The addition and subtraction operator should be followed by an item *)
term(fsys + [plus, minus]); (* transfer term Subprogram analysis item *)
if addop = plus then (* If the operator between items is a plus sign *)
gen(opr, 0, 2) (* Generate operation instruction No. 2: addition *)
else (* Otherwise it's subtraction *)
gen(opr, 0, 3) (* Generate operation instruction 3: subtraction *)
end
end (* expression *);
(* Conditional processing condition *)
(* Parameter Description: fsys: A collection of symbols that can be used to recover parsing if an error occurs *)
procedure condition(fsys: symset);
var
relop: symbol; (* For temporary records token(This must be a binary logical operator)Content of *)
begin
if sym = oddsym then (* If it is odd operator(one yuan) *)
begin
getsym; (* Get next token *)
expression(fsys); (* yes odd Process and evaluate the expression of *)
gen(opr, 0, 6); (* Generate operation instruction No. 6: parity judgment operation *)
end
else (* If not odd operator(It must be a binary logical operator) *)
begin
expression([eql, neq, lss, leq, gtr, geq] + fsys); (* Process and evaluate the left part of the expression *)
if not (sym in [eql, neq, lss, leq, gtr, geq]) then (* If token Is not one of the logical operators *)
error(20) (* Throw error 20 *)
else
begin
relop := sym; (* Record the current logical operator *)
getsym; (* Get next token *)
expression(fsys); (* Process and calculate the right part of the expression *)
case relop of (* If the operator is one of the following *)
eql: gen(opr, 0, 8); (* Equal sign: generate No. 8 judgment order *)
neq: gen(opr, 0, 9); (* Unequal sign: generate unequal Order No. 9 *)
lss: gen(opr, 0, 10); (* Less than sign: generate No. 10 small judgment instruction *)
geq: gen(opr, 0, 11); (* Greater than equal sign: generate No. 11 judgment not less than instruction *)
gtr: gen(opr, 0, 12); (* Greater than sign: generate No. 12 greater than command *)
leq: gen(opr, 0, 13); (* Less than or equal to: generate No. 13 judgment no greater than instruction *)
end
end
end
end (* condition *);
begin (* statement *)
if sym = ident then (* The so-called "statement" may be an assignment statement, starting with an identifier *)
begin
i := position(id); (* Find the location of the identifier in the symbol table *)
if i = 0 then (* If you don't find it *)
error(11) (* Throw error 11 *)
else
if table[i].kind <> variable then (* If the identifier is found in the symbol table, but the identifier is not a variable name *)
begin
error(12); (* Throw error 12 *)
i := 0 (* i Set 0 as error flag *)
end;
getsym; (* Get next token,Normal should be assignment number *)
if sym = becomes then (* If it is an assignment number *)
getsym (* Get next token,Normal should be an expression *)
else
error(13); (* If the left identifier of the assignment statement is not followed by the assignment number, error 13 is thrown *)
expression(fsys); (* Processing expression *)
if i <> 0 then (* If you don't make mistakes, i Will not be 0, i Refers to the position of the left identifier of the current language name in the symbol table *)
with table[i] do
gen(sto, lev – level, adr) (* Generates a line that writes the value of the expression to the specified memory sto Object code *)
end
else
if sym = readsym then (* If not an assignment statement, but an read sentence *)
begin
getsym; (* Get next token,Normally, it should be left parenthesis *)
if sym <> lparen then (* If read Statement is not followed by an open parenthesis *)
error(34) (* Throw error 34 *)
else
repeat (* Loop get read The parameter table in the parentheses of the statement generates the corresponding "read from the keyboard" object code in turn *)
getsym; (* Get one token,Normal should be a variable name *)
if sym = ident then (* If it is an identifier *)
(* There is a slight problem here. You should also judge whether this identifier is a variable name. If it is a constant name or a procedure name, there should be an error *)
i := position(id) (* Look up the symbol table and find its location i,Can't find it i Will be 0 *)
else
i := 0; (* If it is not an identifier, there is a problem, i Set 0 as error flag *)
if i = 0 then (* If there is an error *)
error(35) (* Throw error 35 *)
else (* Otherwise, the corresponding object code is generated *)
with table[i] do
begin
gen(opr, 0, 16); (* Generate operation instruction No. 16:Read in numbers from the keyboard *)
gen(sto, lev – level, adr) (* generate sto Instruction to store the read value in the space where the specified variable is located *)
end;
getsym (* Get next token,If comma, then read The sentence is not finished, otherwise it should be a right parenthesis *)
until sym <> comma; (* Keep generating code until read The variables in the parameter table of the statement are traversed. Instead of commas, they should be right parentheses *)
if sym <> rparen then (* If it wasn't the right parenthesis we expected *)
begin
error(33); (* Throw error 33 *)
while not (sym in fsys) do (* rely on fsys Set, find the next legal token,Resume parsing *)
getsym
end
else
getsym (* If read The statement ends normally to get the next token,Generally semicolon or end *)
end
else
if sym = writesym then (* If you encounter write sentence *)
begin
getsym; (* Get next token,Expected left parenthesis *)
if sym = lparen then (* If it is the left bracket *)
begin
repeat (* Obtain each value in parentheses in turn for output *)
getsym; (* Get one token,Expected an identifier here *)
expression([rparen, comma] + fsys); (* call expression Process analysis expression, which is used to add closing parentheses and commas to the collection of error recovery *)
gen(opr, 0, 14) (* Generate instruction 14: output to screen *)
until sym <> comma; (* Loop until you no longer encounter a comma, which should be a right parenthesis *)
if sym <> rparen then (* If it's not a right parenthesis *)
error(33) (* Error 33 thrown *)
else
getsym (* Normally, you want to get the next token,Get ready for the back *)
end;
gen(opr, 0, 15) (* Generate an object code for operation No. 15. Its function is to output a line feed *)
(* It can be seen from this that PL/0 Medium write Statement and Pascal Medium writeln Statements are similar, with output line breaks *)
end
else
if sym = callsym then (* If it is call sentence *)
begin
getsym; (* obtain token,Expected process name type identifier *)
if sym <> ident then (* If call Not followed by an identifier *)
error(14) (* Error 14 thrown *)
else
begin
i := position(id); (* Find the corresponding identifier from the symbol table *)
if i = 0 then (* If you don't find it *)
error(11) (* Throw error 11 *)
else
with table[i] do (* If an identifier is found, it is located on the third page of the symbol table i position *)
if kind = procedur then (* If this identifier is a procedure name *)
gen(cal,lev-level,adr) (* generate cal Object code, call this process *)
else
error(15); (* If call The procedure name is not followed, and error No. 15 is thrown *)
getsym (* Get next token,Prepare for the back *)
end
end
else
if sym = ifsym then (* If it is if sentence *)
begin
getsym; (* Get one token Expected a logical expression *)
condition([thensym, dosym] + fsys); (* Analyze and calculate the logical expression, and add it into the error recovery set then and do sentence *)
if sym = thensym then (* Expected after expression then sentence *)
getsym (* obtain then Posterior token,Expected a statement *)
else
error(16); (* If if Not after then,Throw error number 16 *)
cx1 := cx; (* Note the current code assignment pointer position *)
gen(jpc, 0, 0); (* Generate conditional jump instructions, fill in 0 for the jump position temporarily, and fill in after analyzing the statement *)
statement(fsys); (* analysis then Statement after *)
code[cx1].a:=cx (* Previous line instruction(cx1 Referred to)The jump position of should be current cx Indicated position *)
end
else
if sym = beginsym then (* If encountered begin *)
begin
getsym; (* Get next token *)
statement([semicolon, endsym] + fsys);(* yes begin And end Analysis and processing of statements between *)
while sym in [semicolon] + statbegsys do (* If a semicolon or statement start character is encountered after analyzing a sentence, cycle to analyze the next sentence *)
begin
if sym = semicolon then (* If the statement is a semicolon (possibly an empty statement) *)
getsym (* Get next token Continue analysis *)
else
error(10); (* If there is no semicolon between statements, error number 10 will appear *)
statement([semicolon, endsym] + fsys) (* Analyze a statement *)
end;
if sym = endsym then (* If all the statements are analyzed, you should encounter end *)
getsym (* Indeed end,Read next token *)
else
error(17) (* If not end,Throw error 17 *)
end
else
if sym = whilesym then (* If encountered while sentence *)
begin
cx1 := cx; (* Note the current code assignment location, which is while Start position of cycle *)
getsym; (* Get next token,Expected a logical expression *)
condition([dosym] + fsys); (* Analyze and evaluate this logical expression *)
cx2 := cx; (* Note the current code assignment location, which is while of do Start position of the statement in *)
gen(jpc, 0, 0); (* Generate conditional jump instruction, and fill 0 in the jump position temporarily *)
if sym = dosym then (* Expected after logical expression do sentence *)
getsym (* Get next token *)
else
error(18); (* if Post missing then,Error 18 thrown *)
statement(fsys); (* analysis do Statement block after *)
gen(jmp, 0, cx1); (* Loop jump to cx1 Position, i.e. make logical judgment again *)
code[cx2].a := cx (* Change the jump position just filled in 0 to the current position. Complete while Statement processing *)
end;
test(fsys, [], 19) (* At this point, the processing of a statement is completed, and there will be problems fsys If you don't encounter the symbols in the set, throw error No. 19 *)
end(* statement *);
begin (* block *)
dx := 3; (* The address indicator gives the relative position to which the local quantity of each layer has been currently allocated.
The reason for setting the initial value to 3 is that there are three spaces at the beginning of each layer for storing static chains SL,Dynamic chain DL And return address RA *)
tx0 := tx; (* The initial symbol table pointer points to the starting position of the symbol of the current layer in the symbol table *)
table[tx].adr := cx; (* The current position of the symbol table records the starting position of the current layer code *)
gen(jmp, 0, 0); (* Generate a line of jump instruction, and the jump position is temporarily unknown. Fill in 0 *)
if lev > levmax then (* If the number of nesting layers of the current procedure is greater than the maximum number of nesting layers allowed *)
error(32); (* Issue error 32 *)
repeat (* Start looping through all the declared parts of the source program *)
if sym = constsym then (* If current token yes const Reserved word, start constant declaration *)
begin
getsym; (* Get next token,Normal should be an identifier used as a constant name *)
repeat (* Constant declaration repeated *)
constdeclaration; (* Declare to current token Constant for identifier *)
while sym = comma do (* If a comma is encountered, the next constant is declared repeatedly *)
begin
getsym; (* Get next token,This should be exactly the identifier *)
constdeclaration (* Declare to current token Constant for identifier *)
end;
if sym = semicolon then (* Semicolon expected if constant declaration ends *)
getsym (* Get next token,Prepare for the next cycle *)
else
error(5) (* If a semicolon is not encountered after the constant declaration statement ends, an error number 5 is issued *)
until sym <> ident (* If a non identifier is encountered, the constant declaration ends *)
end;
(* The syntax of the constant declaration here is the same as that in the textbook EBNF Paradigms differ:
It can accept declaration methods like the following, and according to the textbook EBNF The following syntax cannot be derived from the paradigm:
const a = 3, b = 3; c = 6; d = 7, e = 8;
That is, it can accept constant declarations separated by semicolons or commas EBNF The paradigm can only accept declarations separated by commas *)
if sym = varsym then (* If current token yes var Reserved word, start variable declaration,Similar to constant declarations *)
begin
getsym; (* Get next token,Normal here should be an identifier used as a variable name *)
repeat (* Repeat variable declaration *)
vardeclaration; (* With current token Declare a variable for the identifier *)
while sym = comma do (* If a comma is encountered, the next variable is declared repeatedly *)
begin
getsym; (* Get next token,This should be exactly the identifier *)
vardeclaration; (* Declare with current token Variable with identifier *)
end;
if sym = semicolon then (* A semicolon should be encountered if the variable declaration ends *)
getsym (* Get next token,Prepare for the next cycle *)
else
error(5) (* If a semicolon is not encountered after the variable declaration statement, an error number 5 is issued *)
until sym <> ident; (* If a non identifier is encountered, the variable declaration ends *)
(* There is also the same problem as the constant declaration above: and PL/0 There is a conflict with the syntax specification of. *)
end;
while sym = procsym do (* Circular declaration of subprocesses *)
begin
getsym; (* Get next token,The normal here should be an identifier as a procedure name *)
if sym = ident then (* If token Really an identifier *)
begin
enter(procedur); (* Log this process into the name table *)
getsym (* Get next token,Normally it should be a semicolon *)
end
else
error(4); (* Otherwise, error No. 4 will be thrown *)
if sym = semicolon then (* If current token Semicolon *)
getsym (* Get next token,Recursive call ready for parsing *)
else
error(5); (* Otherwise, error No. 5 will be thrown *)
block(lev + 1, tx, [semicolon] + fsys); (* Recursively call the syntax analysis process, add one to the current level, and pass the header index and legal word symbols at the same time *)
if sym = semicolon then (* Current after recursive return token Last expected in recursive call end Semicolon after *)
begin
getsym; (* Get next token *)
test(statbegsys + [ident, procsym], fsys, 6); (* Check current token Whether it is legal or not fsys Resume parsing and throw error 6 at the same time *)
end
else
error(5) (* If the symbol after the procedure declaration is not a semicolon, error No. 5 is thrown *)
end;
test(statbegsys + [ident], declbegsys, 7) (* Check whether the current state is legal. If not, use the declaration start symbol for error recovery and throw No. 7 error *)
until not (sym in declbegsys); (* Until the declarative source program analysis is completed, continue to execute downward to analyze the main program *)
code[table[tx0].adr].a := cx; (* Change the jump position of the previously generated jump statement to the current position *)
with table[tx0] do (* Record in symbol table *)
begin
adr := cx; (* Address assigns an address to the current code *)
size := dx; (* The length assigns a location for the current data generation *)
end;
cx0 := cx; (* Note the current code assignment location *)
gen(int, 0, dx); (* Generate space allocation instruction dx Space *)
statement([semicolon, endsym] + fsys); (* Process the currently encountered statement or statement block *)
gen(opr, 0, 0); (* Generate operation instructions returned from subroutines *)
test(fsys, [], 8); (* use fsys Check whether the current status is legal. If not, throw error No. 8 *)
listcode (* List the classes of this layer PCODE code *)
end(* block *);
(* PL/0 Compiler generated classes PCODE The object code explains the running process interpret *)
procedure interpret;
const
stacksize = 500; (* Constant definition, the hypothetical stack computer has 500 stack units *)
var
p, b, t: integer; (* program base topstack registers *)
(* p Is the program instruction pointer, pointing to the next code to run *)
(* b Is the base address pointer, pointing to the base address of the local variable data segment assigned to each procedure in the data area when it is called *)
(* t For stack top register, class PCODE It runs on a hypothetical stack calculation. This variable records the current top position of the computer *)
i: instruction; (* i Variable stores the currently running instructions *)
s: array[1..stacksize] of integer; (* datastore *) (* s Is the data memory area of the stack computer *)
(* The function of finding the base address of the data area through the static chain base *)
(* Parameter Description: l:The layer difference between the required data area and the current layer *)
(* Return value: the base address of the required data area *)
function base(l: integer): integer;
var
b1: integer;
begin
b1 := b; (* find base 1 level down *) (* Start with the current layer *)
while l > 0 do (* If l If it is greater than 0, the loop finds the required base address of the data area through the static chain *)
begin
b1 := s[b1]; (* Use the content in the base address of the data area of the current layer (just the static chain) SL Data, which is the base address of the previous layer, is used as the new current layer, that is, a layer is found upward *)
l := l – 1 (* Up one level, l Minus one *)
end;
base := b1 (* Returns the found base address of the requested data area *)
end(* base *);
begin
writeln('start pl0'); (* PL/0 The program starts running *)
t := 0; (* When the program starts running, the stack top register is set to 0 *)
b := 1; (* The base address of the data segment is 1 *)
p := 0; (* Execute the program from code 0 *)
s[1] := 0;
s[2] := 0;
s[3] := 0; (* Data in memory is SL,DL,RA All three units are 0, and the identification is the main program *)
repeat (* Start running the program object code in turn *)
i := code[p]; (* Get a line of object code *)
p := p + 1; (* The instruction pointer plus one points to the next code *)
with i do
case f of (* If i of f,That is, instruction mnemonics are some of the following situations that perform different functions *)
lit: (* If it is lit instructions *)
begin
t := t + 1; (* The pointer at the top of the stack moves up and a unit is allocated in the stack *)
s[t] := a (* Content storage of this unit i Directive a Operand, that is, to put the constant value on the top of the running stack *)
end;
opr: (* If it is opr instructions *)
case a of (* operator *) (* according to a Different operands perform different operations *)
0: (* 0 Operation number is a return operation from a subprocess *)
begin (* return *)
t := b – 1; (* Release the data memory space occupied by this sub process *)
p := s[t + 3]; (* Take the instruction pointer to RA Refers to the return address *)
b := s[t + 2] (* Get the data segment base address to DL Value that points to the base address of the data segment of the sub procedure before the call *)
end;
1: (* 1 No. operation is the reverse operation of stack top data *)
s[t] := -s[t]; (* Negate stack top data *)
2: (* 2 No. operation is the addition of two data at the top of the stack *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := s[t] + s[t + 1] (* Add the two units of data and store them at the top of the stack *)
end;
3: (* 3 No. operation is two data subtraction operations at the top of the stack *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := s[t] – s[t + 1] (* Subtract the two units of data and store them at the top of the stack *)
end;
4: (* 4 No. operation is two data multiplication operations at the top of the stack *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := s[t] * s[t + 1] (* Multiply the two units of data and store them at the top of the stack *)
end;
5: (* 5 No. operation is two data division operations at the top of the stack *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := s[t] div s[t + 1] (* Divide the two units of data and store them at the top of the stack *)
end;
6: (* 6 No. operation is odd judgment operation *)
s[t] := ord(odd(s[t])); (* If the value at the top of the data stack is odd, set the value at the top of the stack to 1, otherwise set to 0 *)
8: (* 8 No. operations are two data judgment operations at the top of the stack *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := ord(s[t] = s[t + 1]) (* Judge the level, set the top of the equal stack to 1, and set the unequal stack to 0 *)
end;
9: (* 9 The No. operation is the unequal operation of two data at the top of the stack *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := ord(s[t] <> s[t + 1]) (* Unequal judgment, unequal stack top setting 1, equal setting 0 *)
end;
10: (* 10 No. operation is the less than operation of two data at the top of the stack *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := ord(s[t] < s[t + 1]) (* Judge less than. If the lower value is less than the upper value, set 1 at the top of the stack, otherwise set 0 *)
end;
11: (* 11 Operation No. is the operation of determining whether the two data at the top of the stack are greater than or equal to each other *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := ord(s[t] >= s[t + 1]) (* If the lower value is greater than or equal to the upper value, set 1 at the top of the stack, otherwise set 0 *)
end;
12: (* 12 The operation No. is the operation of determining whether the two data at the top of the stack are greater than *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := ord(s[t] > s[t + 1]) (* Judge greater than. If the lower value is greater than the upper value, set 1 at the top of the stack, otherwise set 0 *)
end;
13: (* 13 The No. operation is the operation of determining less than or equal to two data at the top of the stack *)
begin
t := t – 1; (* Stack top pointer down *)
s[t] := ord(s[t] <= s[t + 1]) (* If the lower value is less than or equal to the upper value, set 1 at the top of the stack, otherwise set 0 *)
end;
14: (* 14 No. operation is the output stack top value operation *)
begin
write(s[t]); (* Output stack top value *)
write(fa2, s[t]); (* Print to file at the same time *)
t := t – 1 (* Stack top down *)
end;
15: (* 15 No. operation is output line feed operation *)
begin
writeln; (* Output wrap *)
writeln(fa2) (* Output to file at the same time *)
end;
16: (* 16 No. operation is to accept the keyboard value input to the top of the stack *)
begin
t := t + 1; (* Move the top of the stack up to allocate space *)
write('?'); (* Screen display question mark *)
write(fa2, '?'); (* Output to file at the same time *)
readln(s[t]); (* Get input *)
writeln(fa2, s[t]); (* Print user input value to file *)
end;
end; (* opr End of instruction analysis run *)
lod: (* If it is lod instructions:Put variables at the top of the stack *)
begin
t := t + 1; (* Move the top of the stack up to open up space *)
s[t] := s[base(l) + a] (* Layer difference through data area l And offset address a Find the variable data and store it in the new space opened up above (i.e. the top of the stack) *)
end;
sto: (* If it is sto instructions *)
begin
s[base(l) + a] := s[t]; (* Store the value at the top of the stack in the data area layer difference l Offset address a Variable memory *)
t := t – 1 (* Move the stack item down to free up space *)
end;
cal: (* If it is cal instructions *)
begin (* generat new block mark *)
s[t + 1] := base(l); (* Push in static chain at the top of stack SL *)
s[t + 2] := b; (* Then press the base address of the current data area as the dynamic chain DL *)
s[t + 3] := p; (* Finally, press the current breakpoint as the return address RA *)
(* The above work is to protect the site before procedure call *)
b := t + 1; (* Point the base address of the current data area to SL location *)
p := a; (* from a The instruction continues to be executed at the indicated position, that is, the jump of program execution is realized *)
end;
int: (* If it is int instructions *)
t := t + a; (* Move stack top up a A space, that is, open up a A new memory unit *)
jmp: (* If it is jmp instructions *)
p := a; (* hold jmp Instruction operand a The value of is used as the instruction address for the next execution to realize unconditional jump *)
jpc: (* If it is jpc instructions *)
begin
if s[t] = 0 then (* Determine stack top value *)
p := a; (* If it is 0, jump, otherwise don't jump *)
t := t – 1 (* Free stack top space *)
end;
end(* with,case *)
until p = 0; (* If p Equal to 0 means that the return instruction from the subroutine is encountered when the main program is running, that is, the end of the whole program *)
write(' end pl/0');
end(* interpret *);
begin (* main *)
writeln('please input source program file name:');
readln(sfile);
assign(fin,sfile);
reset(fin);
for ch := chr(0) to chr(255) do ssym[ch] := nul;(* This cycle turns ssym Fill in all arrays nul *)
(* The reserved word list is initialized below. If the reserved word length is less than 10 characters, the redundant positions are filled with spaces to facilitate the search of reserved words by dichotomy during lexical analysis *)
word[1] := 'begin ';
word[2] := 'call ';
word[3] := 'const ';
word[4] := 'do ';
word[5] := 'end ';
word[6] := 'if ';
word[7] := 'odd ';
word[8] := 'procedure ';
word[9] := 'read ';
word[10] := 'then ';
word[11] := 'var ';
word[12] := 'while ';
word[13] := 'write ';
(* Reserved word symbol list. After finding the reserved word in the reserved word table above, you can the type of the reserved word in the corresponding position in this table *)
wsym[1] := beginsym;
wsym[2] := callsym;
wsym[3] := constsym;
wsym[4] := dosym;
wsym[5] := endsym;
wsym[6] := ifsym;
wsym[7] := oddsym;
wsym[8] := procsym;
wsym[9] := readsym;
wsym[10] := thensym;
wsym[11] := varsym;
wsym[12] := whilesym;
wsym[13] := writesym;
(* Initialize the symbol table and assign the possible symbols to the corresponding types. The types of other symbols due to the loop at the beginning are nul *)
ssym['+'] := plus;
ssym['-'] := minus;
ssym['*'] := times;
ssym['/'] := slash;
ssym['('] := lparen;
ssym[')'] := rparen;
ssym['='] := eql;
ssym[','] := comma;
ssym['.'] := period;
ssym['#'] := neq;
ssym[';'] := semicolon;
(* Initialization class PCODE Mnemonic table, which is mainly used for output classes PCODE Use of code *)
mnemonic[lit] := ' lit ';
mnemonic[opr] := ' opr ';
mnemonic[lod] := ' lod ';
mnemonic[sto] := ' sto ';
mnemonic[cal] := ' cal ';
mnemonic[int] := ' int ';
mnemonic[jmp] := ' jmp ';
mnemonic[jpc] := ' jpc ';
declbegsys := [constsym, varsym, procsym];
statbegsys := [beginsym, callsym, ifsym, whilesym];
facbegsys := [ident, number, lparen];
(* page(output) *)
err := 0; (* The number of errors is set to 0 *)
cc := 0; (* Lexical analysis line buffer pointer set to 0 *)
cx := 0; (* class PCODE Code table pointer set to 0 *)
ll := 0; (* Set the length of lexical analysis line buffer to 0 *)
ch := ' '; (* Lexical analysis: the current character is a space *)
kk := al; (* Set kk The value of is the maximum length of the allowed identifier, which is specified in the opinion getsym Process notes *)
getsym; (* Call the lexical analysis subroutine for the first time to obtain the first word of the source program( token) *)
block(0, 0, [period] + declbegsys + statbegsys); (* Start the syntax analysis of the main program (that is, the first sub program) *)
(* The layer where the main program is located is layer 0, the symbol table is temporarily empty, and the symbol table pointer refers to position 0 *)
if sym <> period then error(9);(* At the end of the main program analysis, a period indicating the end of the program shall be encountered *)
if err=0 then interpret else write(' errors in pl/0 program'); (* If the number of errors is 0, you can start interpreting the code generated by the compilation *)
99:writeln(* This label was originally used to exit the program, *)
end.