It's very simple here. Only one is maintained internally `byte` Type `data` Array, actually `byte` It still occupies as much as one byte and can be optimized into `bit`Instead, it is only used to facilitate simulation. In addition, I created three different`hash`Function is actually a reference`HashMap`Hash jitter method, respectively, using its own `hash `A result that is different or different from shifting to the right. And provides a basic `add` and `contains` method.
Let's briefly test the effect of this bloom filter:
```java
public static void main(String[] args) {
Random random = new Random();
// Suppose we have 1 million data
int size = 1_000_000;
// Use a data structure to save all the actual values
LinkedList<Integer> existentNumbers = new LinkedList<>();
BloomFilter bloomFilter = new BloomFilter(size);
for (int i = 0; i < size; i++) {
int randomKey = random.nextInt();
existentNumbers.add(randomKey);
bloomFilter.add(randomKey);
}
// Verify that all existing numbers exist
AtomicInteger count = new AtomicInteger();
AtomicInteger finalCount = count;
existentNumbers.forEach(number -> {
if (bloomFilter.contains(number)) {
finalCount.incrementAndGet();
}
});
System.out.printf("Actual data volume: %d, Determine the amount of data: %d \n", size, count.get());
// Verify 10 nonexistent numbers
count = new AtomicInteger();
while (count.get() < 10) {
int key = random.nextInt();
if (existentNumbers.contains(key)) {
continue;
} else {
// This must be a nonexistent number
System.out.println(bloomFilter.contains(key));
count.incrementAndGet();
}
}
}
The output is as follows:
Actual data volume: 1000000, Determine the amount of data: 1000000 false true false true true true false false true false
This is what we mentioned earlier. When the bloom filter says that a value exists, the value may not exist. When it says that a value does not exist, it certainly does not exist, and there is a certain misjudgment rate
2) Manual implementation reference
Of course, the above version is particularly low, but the main idea is not bad. Here is a better version for your own implementation test:
import java.util.BitSet;
public class MyBloomFilter {
/**
* Size of digit group
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* Six different hash functions can be created from this array
*/
private static final int[] SEEDS = new int[]{3, 13, 46, 71, 91, 134};
/**
* Digit group. Elements in an array can only be 0 or 1
*/
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* An array of classes containing hash functions
*/
private SimpleHash[] func = new SimpleHash[SEEDS.length];
/**
* Initialize an array of multiple classes containing hash functions. The hash functions in each class are different
*/
public MyBloomFilter() {
// Initialize multiple different Hash functions
for (int i = 0; i < SEEDS.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* Add element to digit group
*/
public void add(Object value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
/**
* Determines whether the specified element exists in the bit array
*/
public boolean contains(Object value) {
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/**
* Static inner class. For hash operation!
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* Calculate hash value
*/
public int hash(Object value) {
int h;
return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h =
value.hashCode()) ^ (h >>> 16)));
}
}
}
3) Use the bloom filter in Google's open source Guava
The purpose of our own implementation is to make ourselves understand the principle of Bloom filter. The implementation of Bloom filter in Guava is quite authoritative, so we don't need to manually implement a bloom filter in the actual project.
First, we need to introduce Guava's dependency into the project:
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>28.0-jre</version> </dependency>
The actual use is as follows:
We have created a bloom filter that can store up to 1500 integers, and we can tolerate a false positive probability of 0.01%
// Create a bloom filter object BloomFilter<Integer> filter = BloomFilter.create( Funnels.integerFunnel(), 1500, 0.01); // Determine whether the specified element exists System.out.println(filter.mightContain(1)); System.out.println(filter.mightContain(2)); // Add element to bloom filter filter.put(1); filter.put(2); System.out.println(filter.mightContain(1)); System.out.println(filter.mightContain(2));
In our example, when the mightcontainer () method returns true, we can 99% determine that the element is in the filter. When the filter returns false, we can 100% determine that the element does not exist in the filter.
The implementation of the bloom filter provided by Guava is still very good (you can see its source implementation for details), but it has a major defect that it can only be used on a single machine (in addition, capacity expansion is not easy). Now the Internet is generally distributed. In order to solve this problem, we need to use the bloom filter in Redis.
2, GeoHash find people nearby
Like WeChat's "nearby people", the "nearby restaurant" of the US group, how did Alipay share the "nearby car"?
1. Use the database to find people nearby
As we all know, any position on the earth can be represented by two-dimensional longitude and latitude. Longitude range [- 180, 180], latitude range [- 90, 90], latitude plus and minus are bounded by the equator, North plus South minus, longitude plus and minus are bounded by the prime meridian (Greenwich Observatory, UK), East plus West minus. For example, the longitude and latitude coordinates of the monument to the people's Heroes in Beijing are (39.904610, 116.397724), which are positive numbers, because China is located in the Northeast hemisphere.
Therefore, after we use the database to store the longitude and latitude information of all people, we can divide a rectangular range based on the current coordinate node to know the people nearby, as shown in the following figure:
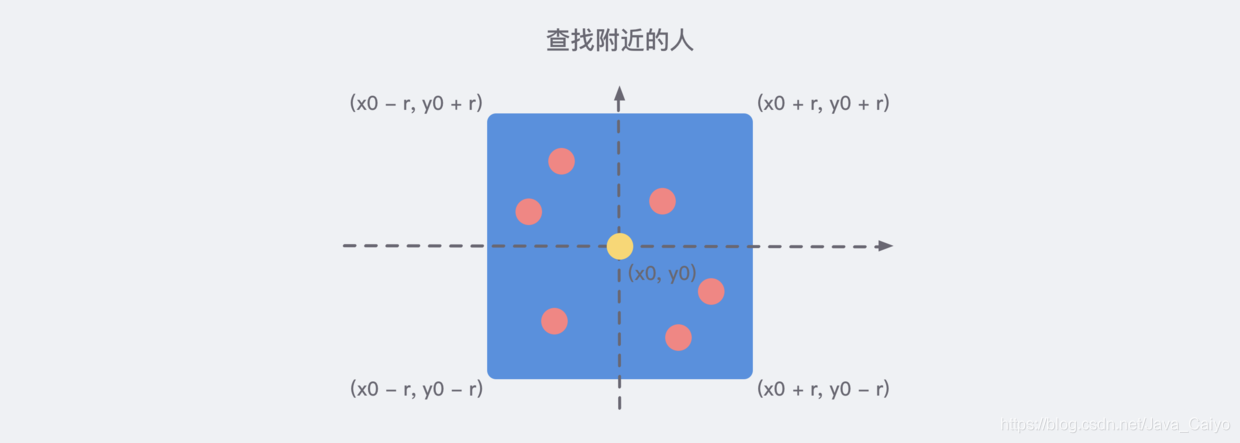
Therefore, it is easy to write the following pseudo SQL statements:
SELECT id FROM positions WHERE x0 - r < x < x0 + r AND y0 - r < y < y0 + r
If we want to know the distance from each coordinate element and sort it further, we need some calculation.
When the distance between two coordinate elements is not very far, we can simply use the Pythagorean theorem to get the distance between them. However, it should be noted that the earth is not a standard sphere, and the density of longitude and latitude is different. Therefore, when we use the Pythagorean theorem to calculate the square and then sum, we need to weigh according to certain coefficients. Of course, if you are not accurate, weighting is not necessary.
Referring to reference 2 below, we can almost write the following optimized SQL statements: (for reference only)
SELECT * FROM users_location WHERE latitude > '.$lat.' - 1 AND latitude < '.$lat.' + 1 AND longitude > '.$lon.' - 1 AND longitude < '.$lon.' + 1 ORDER BY ACOS(SIN( ( '.$lat.' * 3.1415 ) / 180 ) * SIN( ( latitude * 3.1415 ) / 180 ) + COS( ( '.$lat.' * 3.1415 ) / 180 ) * COS( ( latitude * 3.1415 ) / 180 ) * COS( ( '.$lon.' * 3.1415 ) / 180 - ( longitude * 3.1415 ) / 180 ) ) * 6380 ASC LIMIT 10 ';
In order to meet the high-performance rectangular region algorithm, the data table also needs to add the longitude and latitude coordinates with the two-way composite index (x, y), which can meet the maximum optimization query performance.
2. Brief description of geohash algorithm
This is an algorithm commonly used in the industry for sorting geographic location distance, and Redis also adopts this algorithm. GeoHash algorithm maps the two-dimensional longitude and latitude data to one-dimensional integers, so that all elements will be mounted on a line, and the distance between the two-dimensional coordinates close to each other will be very close to the points after mapping to one-dimensional coordinates. When we want to calculate "people nearby", we first map the target position to this line, and then get the nearby points on this one-dimensional line.
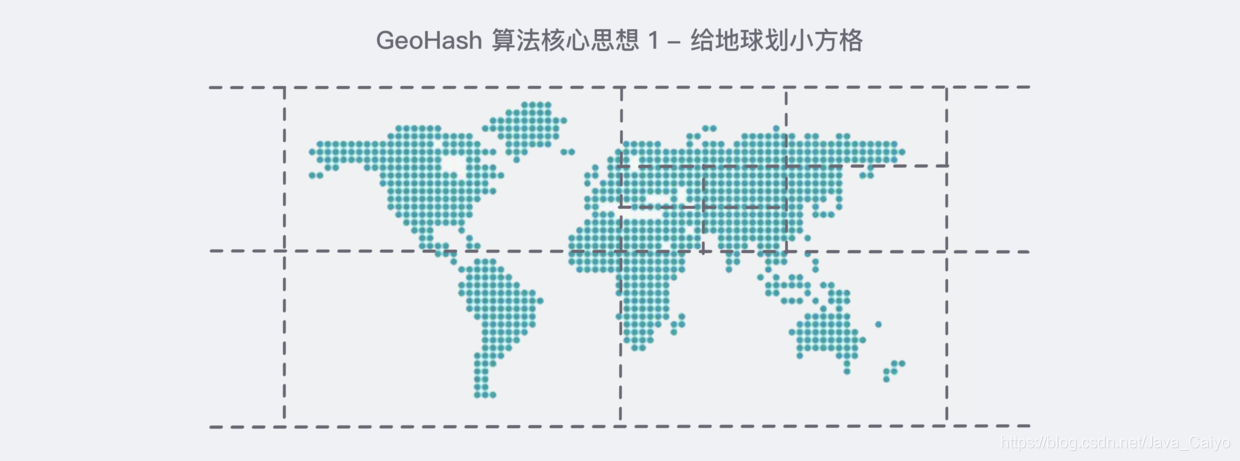
Its core idea is to regard the whole earth as a two-dimensional plane, and then divide the plane into a small grid. Each coordinate element is located in the only grid. The smaller the grid after equal division, the more accurate the coordinates are, similar to the following figure:
We need to code the divided earth:
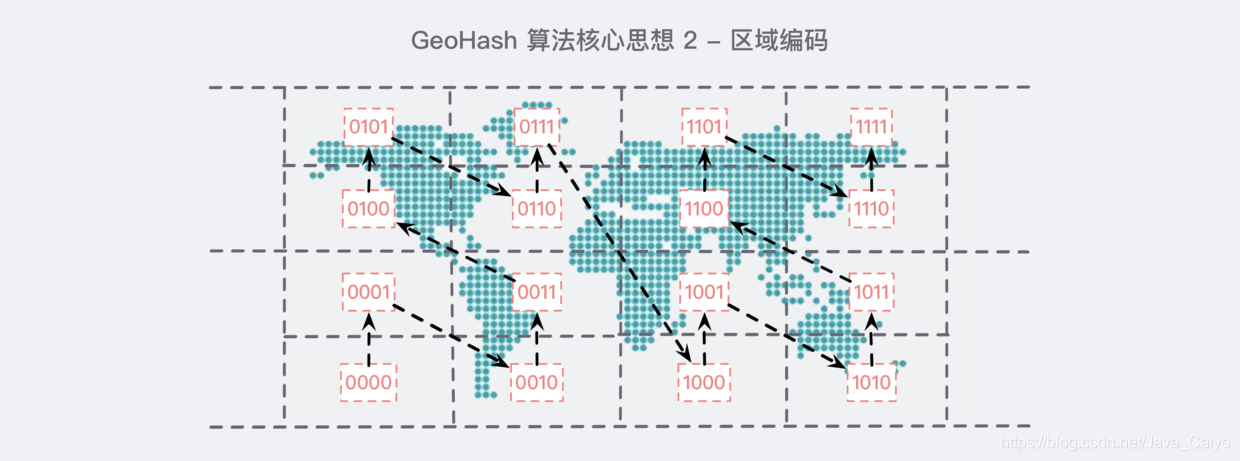
After coding in this order, if you observe it carefully for a while, you will find some rules:
- In all horizontal codes, the 2nd and 4th bits are the same, for example, the first 0101 and the second 0111 in the first row, and their 2nd and 4th bits are 1;
- In all vertical codes, the first and third bits are incremented. For example, the first 0101 in the first row, if the first and third bits are carried out separately, it is 00. Similarly, look at the second 0111 in the first row. In the same way, the first and third bits are carried out as 01, which happens to be 00 incremented by one;
Through this rule, we encode each small block in a certain order. The benefits of this are obvious: the coordinates of each element can be uniquely identified on the encoded map, and the specific location will not be exposed. Because the area is shared, I can tell you that I am near the park, But you don't know where it is.
In short, through the above idea, we can turn any coordinate into a string of binary codes, similar to 11010010110001000100 (note that longitude and dimension appear alternately...), through this integer, we can restore the coordinates of the element. The longer the integer, the smaller the loss of the restored coordinate value. For the "people nearby" function, the loss of a little longitude is negligible.
Finally, the encoding operation of Base32 (0~9, a~z, removing the four letters a/i/l/o) turns it into a string. For example, the string above becomes wx4g0ec1.
In Redis, the longitude and latitude are encoded with 52 bit integers and put into zset. The value of zset is the key of the element and the score is the 52 bit integer value of GeoHash. Although the score of zset is a floating-point number, it can be stored losslessly for 52 bit integer values.
3. Use Geo in Redis
The following is quoted from reference 1 - Redis deep adventure
When using Redis for Geo query, we should always think that its internal structure is actually just a zset(skiplist). Other elements near the coordinates can be obtained by zset's score sorting (the actual situation is more complex, but this understanding is enough). The original coordinates of the elements can be obtained by restoring the score to the coordinate value.
Redis provides only 6 Geo commands, which can be easily mastered.
1) Increase
The geoadd instruction carries a set name and multiple longitude and latitude name triples. Note that multiple triples can be added here.
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin (integer) 1 127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader (integer) 1 127.0.0.1:6379> geoadd company 116.489033 40.007669 meituan (integer) 1 127.0.0.1:6379> geoadd company 116.562108 39.787602 jd 116.334255 40.027400 xiaomi (integer) 2
It's strange... Redis does not directly provide Geo deletion instructions, but we can operate Geo data through zset related instructions, so the zrem instruction can be used for element deletion.
2) Distance
The geodist instruction can be used to calculate the distance between two elements, carrying the set name, two names and distance units.
127.0.0.1:6379> geodist company juejin ireader km "10.5501" 127.0.0.1:6379> geodist company juejin meituan km "1.3878" 127.0.0.1:6379> geodist company juejin jd km "24.2739" 127.0.0.1:6379> geodist company juejin xiaomi km "12.9606" 127.0.0.1:6379> geodist company juejin juejin km "0.0000"
We can see that nuggets are closest to meituan because they are all in Wangjing. The units of distance can be m, km, ml and ft, representing meters, kilometers, miles and feet respectively.
3) Get element location
The geopos instruction can obtain the longitude and latitude coordinates of any element in the set, and can obtain multiple coordinates at a time.
127.0.0.1:6379> geopos company juejin 1) 1) "116.48104995489120483" 2) "39.99679348858259686" 127.0.0.1:6379> geopos company ireader 1) 1) "116.5142020583152771" 2) "39.90540918662494363" 127.0.0.1:6379> geopos company juejin ireader 1) 1) "116.48104995489120483" 2) "39.99679348858259686" 2) 1) "116.5142020583152771" 2) "39.90540918662494363"
We observe that there is a slight error between the obtained longitude and latitude coordinates and the coordinates entered by geoadd. The reason is that the one-dimensional mapping of two-dimensional coordinates by Geohash is lossy, and there will be a small difference in the values restored through mapping. For the function of "people nearby", this error is nothing at all.
4) Gets the hash value of the element
Geohash can obtain the longitude and latitude encoding string of elements. As mentioned above, it is base32 encoding. You can use this coded value to http://geohash.org/ Direct positioning in ${hash}, which is the standard coding value of geohash.
127.0.0.1:6379> geohash company ireader 1) "wx4g52e1ce0" 127.0.0.1:6379> geohash company juejin 1) "wx4gd94yjn0"
Let's open the address http://geohash.org/wx4g52e1ce0 , observe whether the map points to the correct position:
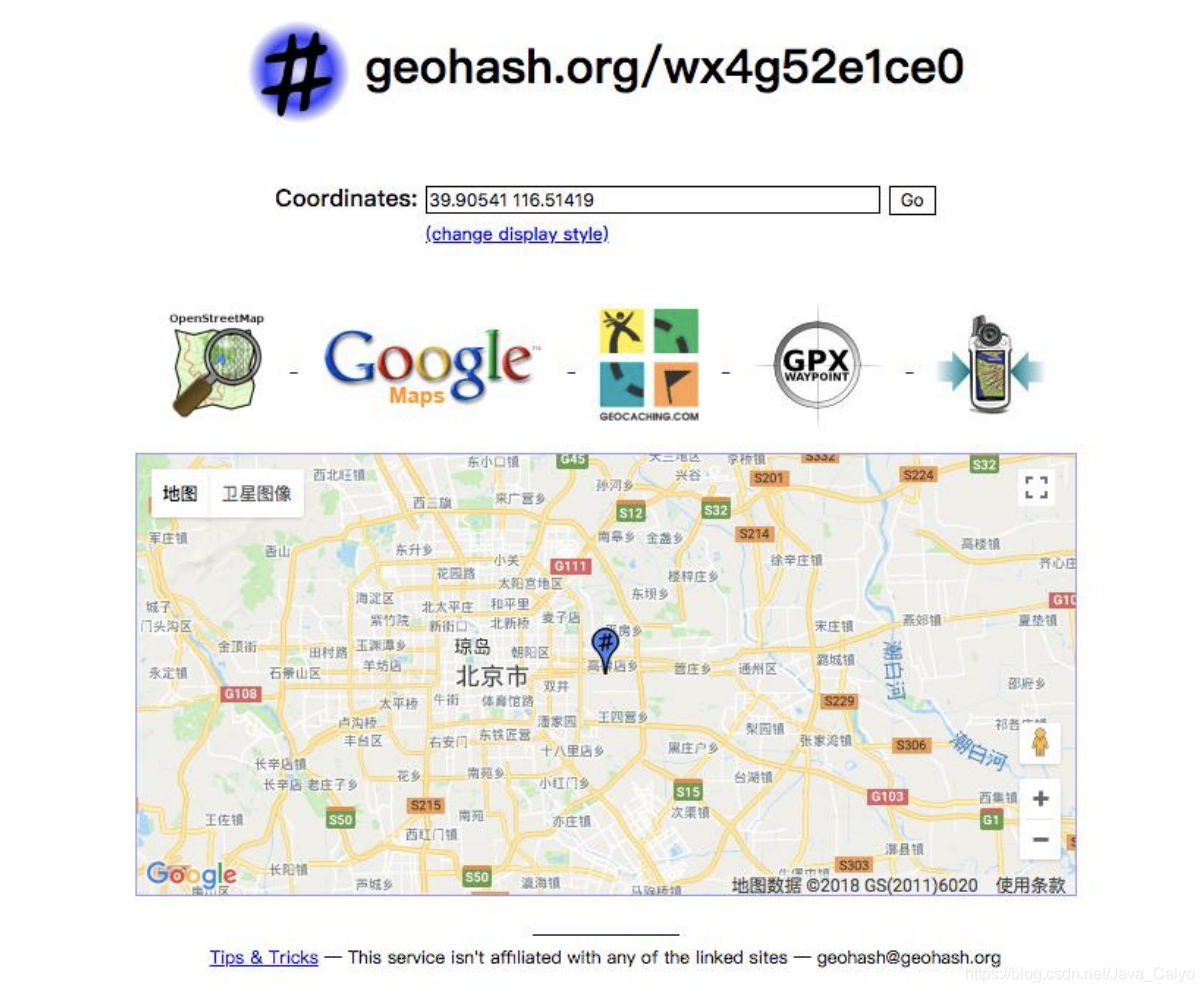
Good, that's the position. It's very accurate.
5) Nearby companies
Geordiusbymember instruction is the most critical instruction. It can be used to query other elements near the specified element. Its parameters are very complex.
# Up to 3 elements within 20 kilometers are arranged in a positive direction according to the distance, and it will not exclude itself 127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 asc 1) "ireader" 2) "juejin" 3) "meituan" # Up to 3 elements within 20km are inverted by distance 127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 desc 1) "jd" 2) "meituan" 3) "juejin" # Three optional parameters withclass withlist withhash are used to carry additional parameters # Withlist is very useful. It can be used to display the distance 127.0.0.1:6379> georadiusbymember company ireader 20 km withcoord withdist withhash count 3 asc 1) 1) "ireader" 2) "0.0000" 3) (integer) 4069886008361398 4) 1) "116.5142020583152771" 2) "39.90540918662494363" 2) 1) "juejin" 2) "10.5501" 3) (integer) 4069887154388167 4) 1) "116.48104995489120483" 2) "39.99679348858259686" 3) 1) "meituan" 2) "11.5748" 3) (integer) 4069887179083478 4) 1) "116.48903220891952515" 2) "40.00766997707732031"
In addition to the geordiusbymember command to query nearby elements according to elements, Redis also provides to query nearby elements according to coordinate values. This command is more useful. It can calculate "nearby cars" and "nearby restaurants" according to the user's location. Its parameters are basically the same as those of geordiusbymember, except that the target element is changed to the longitude and latitude coordinate value:
127.0.0.1:6379> georadius company 116.514202 39.905409 20 km withdist count 3 asc 1) 1) "ireader" 2) "0.0000" 2) 1) "juejin" 2) "10.5501" 3) 1) "meituan" 2) "11.5748"
6) Precautions
In a map application, there may be millions of car data, restaurant data and human data. If Redis's Geo data structure is used, they will all be placed in a zset set. In the Redis cluster environment, collections may migrate from one node to another. If the data of a single key is too large, it will have a great impact on the migration of the cluster. In the cluster environment, the amount of data corresponding to a single key should not exceed 1M, otherwise the cluster migration will be stuck and the normal operation of online services will be affected.
Therefore, it is recommended that Geo's data be deployed using a separate Redis instance instead of a cluster environment.
If the amount of data is more than 100 million or more, Geo data needs to be split by country, province, city, and even by district in populous megacities. This can significantly reduce the size of a single zset set.
3, Persistence
1. Introduction to persistence
All Redis data is stored in memory. If it goes down suddenly, all data will be lost. Therefore, there must be a mechanism to ensure that Redis data will not be lost due to failure. This mechanism is Redis's persistence mechanism, which will save the database state in memory to disk.
1) What happens to persistence? From memory to disk
Let's think about the persistence of Redis as an "in memory database". Generally speaking, the following things need to happen from the client initiating the request to the server actually writing to the disk:
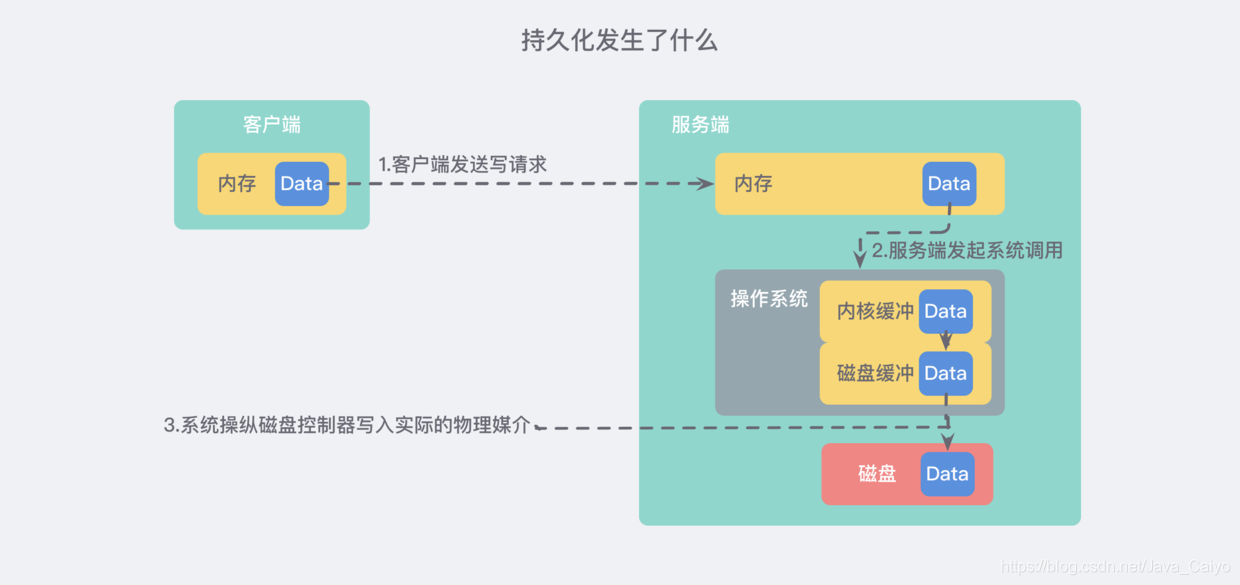
The detailed text description is as follows:
- The client sends a write command to the database (the data is in the memory of the client)
- The database receives a write request from the client (the data is in the memory of the server)
- The database calls the system API to write data to disk (the data is in the kernel buffer)
- The operating system transfers the write buffer to the disk controller (the data is in the disk cache)
- The disk controller of the operating system writes data to the actual physical medium (the data is on disk)
Note: the above process is actually extremely streamlined. In the actual operating system, there will be much more caches and buffers
2) How to ensure the security of persistence as much as possible
If our fault only involves the software level (the process is terminated by the administrator or the program crashes) and does not touch the kernel, we will consider it successful after the successful return of step 3 above. Even if the process crashes, the operating system will still help us write data to disk correctly.
If we consider more catastrophic things such as power failure / fire, it is safe only after completing step 5.
Therefore, we can conclude that the most important stages of data security are steps 3, 4 and 5, namely:
- How often does the database software call the write operation to transfer the user space buffer to the kernel buffer?
- How often does the kernel flush data from the buffer to the disk controller?
- How often does the disk controller write data to the physical media?
- Note: if a catastrophic event really happens, we can see from the process in the figure above that any step may be accidentally interrupted and lost, so we can only ensure the security of data as much as possible, which is the same for all databases.
Let's start with step three. The Linux system provides a clear and easy-to-use POSIX file API for operating files. Over the past 20 years, many people still talk about the design of this API. I think one of the reasons is that you can clearly know the purpose of this API from the name of the API:
Kafka advanced knowledge points

Kafka advanced knowledge points

The 44 Kafka knowledge points (Basic + Advanced + Advanced) are analyzed as follows
Security, which is the same for all databases.
Let's start with step three. The Linux system provides a clear and easy-to-use POSIX file API for operating files. Over the past 20 years, many people still talk about the design of this API. I think one of the reasons is that you can clearly know the purpose of this API from the name of the API:
Kafka advanced knowledge points
[external chain picture transferring... (img-pUIAh7VV-1628140079975)]
Kafka advanced knowledge points
[external chain picture transferring... (img-QfdNF2Nh-1628140079976)]
The 44 Kafka knowledge points (Basic + Advanced + Advanced) are analyzed as follows
[external chain picture transferring... (img-uM6KTOuv-1628140079977)]
Due to the limited space, the editor has compiled the above * * Kafka source code analysis and practice, Kafka interview topic analysis, review and learning necessary 44 Kafka knowledge points (Basic + Advanced + Advanced), all of which are PDF documents * *, Friends in need can download it here for free