This article will mainly talk about JDK version 1.8 Concurrent HashMap, its internal structure and many hash optimization algorithms are the same as JDK version 1.8 HashMap, so before reading this article, we must first understand HashMap, for reference. HashMap correlation In addition, there are also red and black trees in Concurrent HashMap, which can be viewed without affecting the overall structure of the map. red-black tree;
Concurrent HashMap Architecture Overview
1. Overview
The source code of CHM has more than 6k lines, which contains many contents and is not easy to understand. It is suggested that when looking at the source code, we should first grasp the overall structure context. For some exquisite optimization, the hash technique can understand the purpose first, without further study; after a clear grasp of the whole, we can understand it more quickly through gradual analysis;
CHM in JDK version 1.8 is very different from JDK version 1.7. We should pay attention to the distinction between CHM and JDK version 1.7. Segment segment locks are mainly used to solve concurrent problems in JDK version 1.7, but there are no slightly bloated structures in JDK version 1.8. The structure of CHM is basically the same as HashMap. They are arrays + linked lists + red-black trees, as shown in the figure.
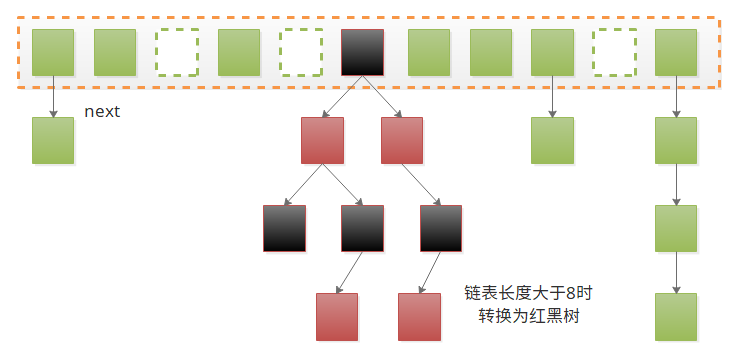
The main difference is that CHM supports concurrency:
- Use the Unsafe method to manipulate the internal elements of the array to ensure visibility; (U.getObjectVolatile, U. comparison AndSwapObject, U.putObjectVolatile);
- When updating and moving nodes, the corresponding hash bucket is locked directly, and the lock granularity is smaller, and it expands dynamically.
- Optimize the slow operation of expansion.
- Firstly, in the process of expansion, the node moves to the over-table nextTable first, and replaces the hash table when all nodes move.
- When moving, the hash table is divided into equal parts, and then the task expansion is received in reverse order. The sizeCtl tag is being expanded.
- When moving a hash bucket or encountering an empty bucket, mark it as a Forwarding Node node and point to nextTable.
- When other threads encounter Forwarding Node nodes while operating hash tables, they first help to expand (continue to receive subsection tasks), and then continue the previous operations after the expansion is completed.
- Optimizing hash table counter, using LongAdder, Striped64 similar ideas;
- And a large number of hash algorithm optimization and state variables optimization.
The above is not clear or relevant, mainly has an impression, roughly clear about the direction of CHM implementation, specific details will be explained in detail later with the source code;
2. Class definition and member variables
public class ConcurrentHashMap<K,V>
extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable {
private static final int MAXIMUM_CAPACITY = 1 << 30; // Maximum capacity
private static final int DEFAULT_CAPACITY = 16; // Default initialization capacity
private static final int DEFAULT_CONCURRENCY_LEVEL = 16; // Concurrent level, compatible with 1.7, not actually used
private static final float LOAD_FACTOR = 0.75f; // Fixed load factor, n - (n > > > > 2)
static final int TREEIFY_THRESHOLD = 8; // When the list exceeds 8, it turns into a red-black tree.
static final int UNTREEIFY_THRESHOLD = 6; // When the mangrove tree is below 6, it turns into a linked list
static final int MIN_TREEIFY_CAPACITY = 64; // When the tree minimum capacity is less than 64, expand the capacity first.
private static final int MIN_TRANSFER_STRIDE = 16; // Disassemble the scattered list for expansion, minimum step size
private static int RESIZE_STAMP_BITS = 16;
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; // Maximum Threads Participating in Expansion
static final int NCPU = Runtime.getRuntime().availableProcessors(); // CPU number
transient volatile Node<K,V>[] table; // Hash table
private transient volatile Node<K,V>[] nextTable; // Excessive table in expansion
private transient volatile int sizeCtl; // The most important state variables, described in more detail below
private transient volatile int transferIndex; // Expansion schedule indication
private transient volatile long baseCount; // Counter, base cardinality
private transient volatile int cellsBusy; // Counter, concurrent marker
private transient volatile CounterCell[] counterCells; // Counter, concurrent accumulation
public ConcurrentHashMap() { }
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); // Note that this is not 0.75, as described later.
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor); // Notice the initialization here.
int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
...
}There are several important points above, which I will talk about separately here:
LOAD_FACTOR:
The load coefficients here are obviously different from those of other Maps such as HashMap.
Normally, the default coefficient is 0.75, which can be passed in by the constructor. When the number of nodes size exceeds the load Factor * capacity, it can be expanded.
The coefficient of CMH is fixed at 0.75 (expressed by N - (n > > > > 2). The coefficient passed by the constructor only affects the initialization capacity. See the fifth constructor.
-
In the second constructor above, initialCapacity + (initialCapacity > > > > 1) + 1), which is not the default 0.75, can be regarded as bug or optimization, see
sizeCtl:
sizeCtl is the most important state variable in CHM, which includes many middle states. This article first introduces the whole to help the later source code understand.
sizeCtl = 0: initial value, no initial capacity has been specified;
-
sizeCtl > 0 :
- table is not initialized, indicating the initialization capacity;
- The table has been initialized to represent the expansion threshold (0.75n).
SizeCtl = 1: Indicates that initialization is in progress;
-
SizeCtl < - 1: Indicates that expansion is under way. The specific structure is shown in the figure.
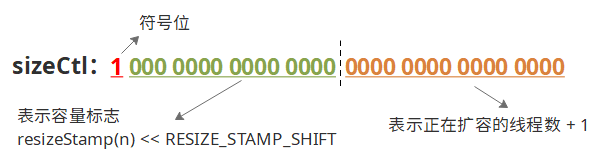
The calculation code is as follows:
/*
* n=64
* Integer.numberOfLeadingZeros(n)=26
* resizeStamp(64) = 0001 1010 | 1000 0000 0000 0000 = 1000 0000 0001 1010
*/
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}So resizeStamp (64) << RESIZE_STAMP_SHIFT) +2 means that the expansion target is 64, and one thread is expanding.
3. Node node
static class Node<K,V> implements Map.Entry<K,V> { // Hash table common node
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node<K,V> find(int h, Object k) {} // When expanding capacity, the transfer nodes are queried by polymorphic queries.
}
static final class ForwardingNode<K,V> extends Node<K,V> { // Identifying Expansion Nodes
final Node<K,V>[] nextTable; // Point to the member variable ConcurrentHashMap.nextTable
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null); // Hash = 1, fast determination of ForwardingNode node
this.nextTable = tab;
}
Node<K,V> find(int h, Object k) {}
}
static final class TreeBin<K,V> extends Node<K,V> { // Root node of red-black tree
TreeBin(TreeNode<K,V> b) {
super(TREEBIN, null, null, null); // Hash = 2, fast determination of red and black trees,
...
}
}
static final class TreeNode<K,V> extends Node<K,V> { } // The hash of the common node of the red-black tree is the same as that of the Node node > 0.4. Hash Computing
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
// Let the high 16 bits participate in the hash bucket positioning operation while ensuring that hash is positive
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}Besides,
- tableSizeFor: Converts the capacity to a power greater than n and the smallest 2;
- Except residue method: hash% length = hash & (length-1);
- Hash bucket positioning after expansion: (e. hash & oldCap), 0 - position unchanged, 1 - original position + oldCap;
The above specific principles of hash optimization, as mentioned in previous blogs, are not repeated. HashMap correlation;
5. Hash bucket visibility
We all know that even if an array is declared volatile, it can only guarantee the visibility of its reference itself. The visibility of its internal elements can not be guaranteed. If it is locked every time, the efficiency will be greatly reduced. In CHM, the Unsafe method is used to ensure that:
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}Source code analysis
1. initTable method
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0) Thread.yield(); // There are other threads initializing
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { // Set state-1
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY; // Note that the sizeCtl at this time represents the initial capacity and the expansion threshold after completion.
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2); // Same 0.75n
}
} finally {
sizeCtl = sc; // Note that there are no CAS updates, and that's the clarity of the state variables, because there's no competition here with - 1 set up earlier.
}
break;
}
}
return tab;
}2. get method
The get method may not be very long, but it guarantees memory consistency in the unlocked state. Every sentence of his code should be carefully understood and imagined what would happen if there was competition.
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); // Calculate hash
if ((tab = table) != null && (n = tab.length) > 0 && // Ensure that the table is initialized
// Make sure that the corresponding hash bucket is not empty, note that this is Volatile semantic acquisition; because the expansion is a complete copy, so as long as it is not empty, the list must be complete.
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// Hash < 0, it is bound to expand, the original location of the nodes may all move to the i + oldCap location, so the use of polymorphism to the next table to find
else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) { // Traversing linked list
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}3. putVal method
Note that neither the key nor value of CHM can be empty
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode()); // hash computing
int binCount = 0; // State variable, which mainly indicates the number of nodes in the lookup list, and finally decides whether to turn to red-black tree or not.
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) tab = initTable(); // Initialization
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // cas gets hash bucket
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) // cas Update, Continue Cyclic Update When Failed
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); // When expanding capacity, help expand capacity first
else {
V oldVal = null;
synchronized (f) { // Note that only one hash bucket is locked here, so it is less granular than the Segment Segment Lock in 1.7
if (tabAt(tab, i) == f) { // Verify that the hash bucket has moved
if (fh >= 0) { // Hash >= 0 is necessarily a common node, so traversing the list directly is enough.
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if(e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { // Search success
oldVal = e.val;
if (!onlyIfAbsent) e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) { // When the lookup fails, add a new node directly at the end
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // root node
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { // Red and Black Tree Search
oldVal = p.val;
if (!onlyIfAbsent) p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); // If the length of the list is greater than 8, turn to a red-black tree.
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount); // Count plus one. Note that counter is used here. Ordinary Atomic variables may still be called performance bottlenecks.
return null;
}The specific flow chart is shown as follows:
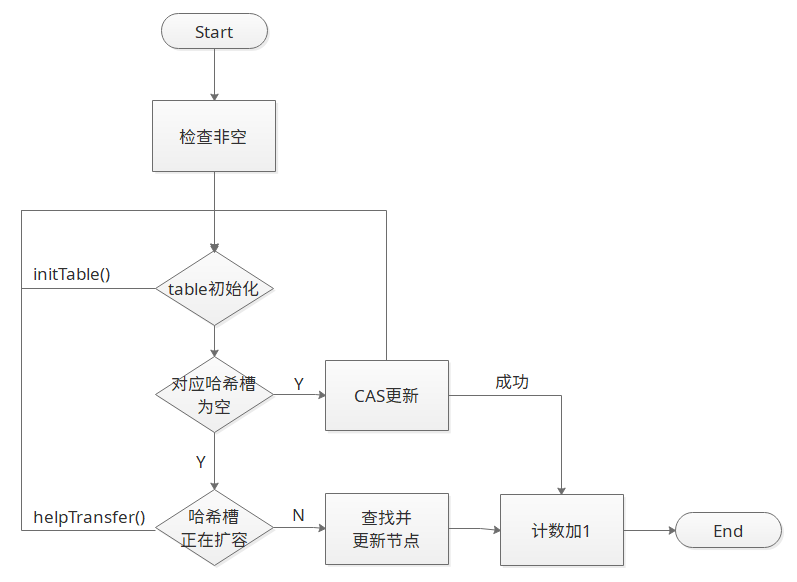
4. expansion
Expansion has always been a slow operation, and the ingenious use of task partitioning in CHM makes it possible for multiple threads to participate in the expansion at the same time. In addition, there are two conditions for expansion:
- When the chain length exceeds 8, but the capacity is less than 64, expansion occurs.
- When the number of nodes exceeds the threshold, expansion occurs.
The expansion process can be described as:
- Firstly, in the process of expansion, the node moves to the over-table nextTable first, and replaces the hash table when all nodes move.
- When moving, the hash table is divided into equal parts, and then the task expansion is received in reverse order. The sizeCtl tag is being expanded.
- When moving a hash bucket or encountering an empty bucket, mark it as a Forwarding Node node and point to nextTable.
- When other threads encounter Forwarding Node nodes while operating hash tables, they first help to expand (continue to receive subsection tasks), and then continue the previous operations after the expansion is completed.
The graphical representation is as follows:
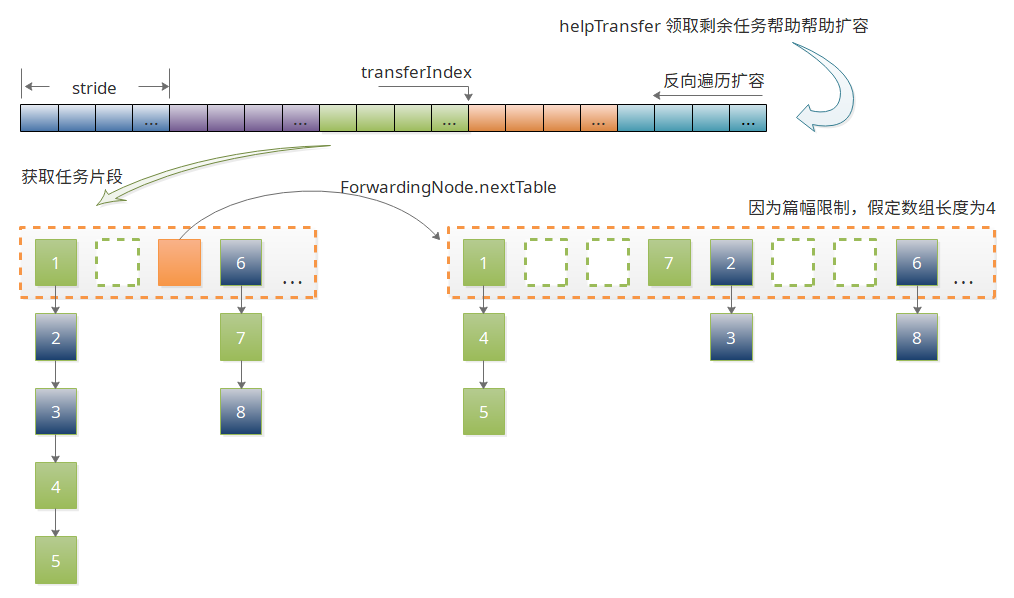
Source code analysis is as follows:
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // Calculating Task Step Size Based on CPU Number
if (nextTab == null) { // Initialize nextTab
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; // Doubling capacity
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE; // When OOM occurs, it is no longer expandable
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); // Mark empty barrels, or barrels that have been transferred
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) { // Reverse ergodic expansion
Node<K,V> f; int fh;
while (advance) { // Get the hash bucket forward
int nextIndex, nextBound;
if (--i >= bound || finishing) // Hash bucket has been fetched, or exit when completed
advance = false;
else if ((nextIndex = transferIndex) <= 0) { // Traversing to the head node, there is no barrel to be migrated, the thread is ready to exit
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { // Complete the current task and get the next batch of hash buckets
bound = nextBound;
i = nextIndex - 1; // The index points to the next batch of hash buckets
advance = false;
}
}
// I < 0: indicates that the expansion is over and there is no hash bucket to be moved
// I >= n: End of expansion, check again for confirmation
// I + n >= nextn: When replacing table s with nextTable, threads entering the expansion will appear
if (i < 0 || i >= n || i + n >= nextn) { // Complete expansion and prepare to withdraw
int sc;
if (finishing) { // Two checks to update variables only when the last expansion thread exits
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1); // 0.75*2*n
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { // Extended threads minus one
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; // Not the last thread, exit directly
finishing = advance = true; // Last thread, check again
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null) // The current node is empty, marked directly as Forwarding Node, and then proceeds to fetch the next bucket
advance = casTabAt(tab, i, null, fwd);
// Previous threads have completed the bucket's movement and skipped it directly. Normally, there will be no Forwarding Node node in their own task interval.
else if ((fh = f.hash) == MOVED) // Here is the robustness test under extreme conditions
advance = true; // already processed
// Start processing list
else {
// Note that lock-free access is possible at get because the expansion is a full-copy node and the hash bucket is updated after completion.
// When putting, the node is added directly to the tail to get the modified value. If putting operation is allowed, dirty reading will occur at last.
// So put and transfer need to compete for the same lock, the corresponding hash bucket, to ensure memory consistency.
synchronized (f) {
if (tabAt(tab, i) == f) { // Make sure the same bucket is locked
Node<K,V> ln, hn;
if (fh >= 0) { // Normal node
int runBit = fh & n; // Hash & n, Judging the Expanded Index
Node<K,V> lastRun = f;
// Here we find the continuous nodes in the same position after the last expansion of the list, so that the last section does not need to be copied again.
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
// In turn, the linked list is divided into lo and hi, i.e. the linked list with the same location and the linked list with the location + oldCap.
// Note that the last section of the list does not have new, but uses the original node directly.
// At the same time, the order of the list is also disrupted, lastRun to the end is in order, and the previous section is in reverse order.
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln); // Insert lo list
setTabAt(nextTab, i + n, hn); // Insert hi list
setTabAt(tab, i, fwd); // The hash bucket is moved and marked as ForwardingNode node
advance = true; // Continue to get the next bucket
}
else if (f instanceof TreeBin) { // Separation of red and black trees
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null; // To avoid the last reverse traversal, leave the reference of the header node first.
TreeNode<K,V> hi = null, hiTail = null; // Because sequential lists can speed up the construction of red and black trees
int lc = 0, hc = 0; // Also record the length of the lo, hi list
for (Node<K,V> e = t.first; e != null; e = e.next) { // Mid-order traversal of red and black trees
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null); // Constructing Red-Black Tree Node
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// Determine whether you need to convert it into a red-black tree, and if you have only one chain, you don't need to construct it.
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}There are other related methods that are not very complicated, so we will not go into details, such as tryPresize, helpTransfer, addCount.
5. counter
When acquiring Map.size, using Atomic variables can easily lead to excessive competition and performance bottlenecks, so CHM uses the counter method:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n);
}private transient volatile CounterCell[] counterCells; // Counter
@sun.misc.Contended static final class CounterCell { // @ sun.misc.Contended avoids pseudo-caching
volatile long value;
CounterCell(long x) { value = x; }
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) { // Cumulative count
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}There are many details, and then I will open a blog to explain them in detail.
summary
- First, the CHM of JDK 1.8 does not use Segment Segmentation Lock, but locks a single hash bucket directly.
- Use CAS operation on hash bucket in array to ensure its visibility
- Expansion is accelerated by means of task splitting and multi-threading simultaneous expansion.
- The idea of using counter for size
- The application of state variables in CHM makes many operations indifferent.