brief introduction
In concurrent programming, we sometimes need to use thread safe queues. If we want to implement a thread safe queue, there are two ways to implement it, one is to use blocking algorithm, the other is to use non blocking algorithm. The queue using blocking algorithm can be implemented by one lock (the same lock for queue entry and queue exit) or two locks (different locks for queue entry and queue exit), while the non blocking implementation can be implemented by cyclic CAS. Let's study how Doug Lea uses the non blocking method to implement the thread safe queue ConcurrentLinkedQueue.
ConcurrentLinkedQueue is an unbounded thread safe queue based on linked nodes. It uses the first in first out rule to sort the nodes. When we add an element, it will be added to the tail of the queue. When we get an element, it will return the element at the head of the queue. It adopts the "wait free" algorithm, which has some modifications on the Michael & Scott algorithm.
The class diagram of ConcurrentLinkedQueue is as follows:
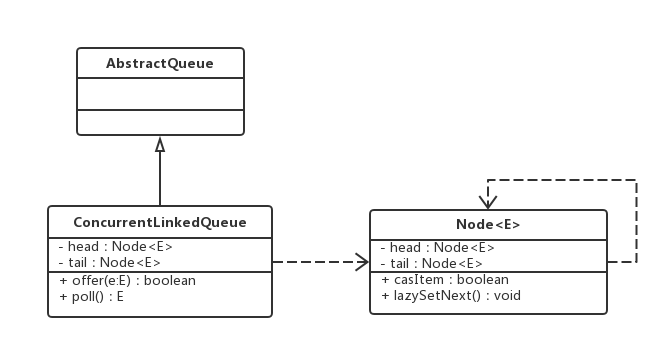
The ConcurrentLinkedQueue consists of a head Node and a tail Node. Each Node is composed of a Node element (item) and a reference to the next Node (next). Nodes are associated with each other through this next to form a queue with a linked list structure.
Detailed explanation of the source code of ConcurrentLinkedQueue
As we mentioned earlier, the nodes of ConcurrentLinkedQueue are of Node type:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
Node(E item) {
UNSAFE.putObject(this, itemOffset, item);
}
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}The Node class is also relatively simple and will not be explained. The ConcurrentLinkedQueue class has the following two construction methods:
// By default, the element stored in the head node is empty, and the tail node is equal to the head node
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
// Create queues from other collections
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
// Traversal node
for (E e : c) {
// If the node is null, a NullPointerException exception will be thrown directly
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
t.lazySetNext(newNode);
t = newNode;
}
}
if (h == null)
h = t = new Node<E>(null);
head = h;
tail = t;
}By default, the element stored in the head node is empty, and the tail node is equal to the head node.
head = tail = new Node<E>(null);
Let's take a look at the join and exit operations of ConcurrentLinkedQueue.
Queue operation
Queuing is to add the queued node to the end of the queue. In order to understand the changes of the queue and the changes of the head node and the tail node when joining the queue, I made a snapshot of the queue every time I added a node:
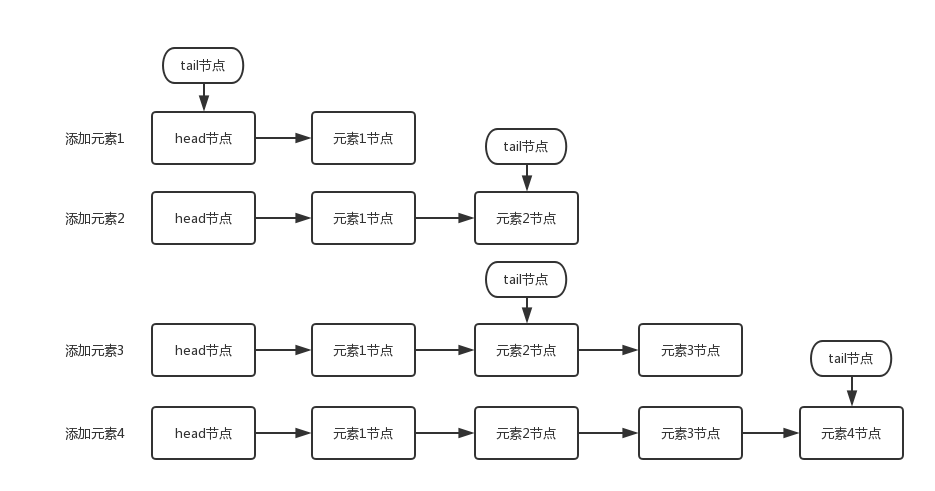
The element addition process shown in the above figure is as follows:
- Add element 1: the next node of the queue update head node is element 1 node. And because the tail node is equal to the head node by default, their next nodes all point to the element 1 node.
- Add element 2: the queue first sets the next node of element 1 node as element 2 node, and then updates the tail node to point to element 2 node.
- Add element 3: set the next node of the tail node to element 3 node.
- Add element 4: set the next node of element 3 as element 4 node, and then point the tail node to element 4 node.
The queueing operation mainly does two things. The first is to set the queueing node as the next node of the current queue tail node. The second is to update the tail node. If the next node of the tail node is not empty, set the queued node as the tail node. If the next node of the tail node is empty, set the queued node as the next node of the tail node. Therefore, it is important to understand that the tail node is not always the tail node.
The above analysis allows us to understand the queue joining process from the perspective of single thread queue joining, but the situation of multiple threads joining the queue at the same time becomes more complex, because other threads may jump the queue. If a thread is joining the queue, it must first obtain the tail node, and then set the next node of the tail node as the queue node. However, at this time, another thread may jump the queue, and the tail node of the queue will change. At this time, the current thread needs to suspend the queue operation, and then obtain the tail node again.
Let's look at the add (E) queue joining method of ConcurrentLinkedQueue:
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
// If e is null, a NullPointerException exception is thrown directly
checkNotNull(e);
// Create queued node
final Node<E> newNode = new Node<E>(e);
// Cycle CAS until joining the team is successful
// 1. Locate the last node according to the tail node; 2. Set the new node as the next node of the tail node; 3. casTail update tail node
for (Node<E> t = tail, p = t;;) {
// p is used to represent the tail node of the queue. Initially, it is equal to the tail node
// q is the next node of p
Node<E> q = p.next;
// Judge whether p is the tail node or not. The tail node is not necessarily the tail node. Judge whether it is the tail node or not based on whether the node's next is null
// If p is the tail node
if (q == null) {
// p is last node
// Set the next node of the p node as a new node. If the setting is successful, casNext returns true; Otherwise, false is returned, indicating that other threads have updated the tail node
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
// If P= t. Set the queued node as the tail node, and it doesn't matter if the update fails, because failure means that other threads have successfully updated the tail node
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
// During multi-threaded operation, the old head will be changed into a self reference during poll, and then the next of the head will be set to the new head
// Therefore, we need to find a new head again, because the node behind the new head is the active node
else if (p == q)
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
// Find tail node
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}From the perspective of source code, the whole process of joining the team mainly does two things:
- The first is to locate the tail node
- The second is to use CAS algorithm to set the queueing node as the next node of the tail node. If it is unsuccessful, try again.
The first step is to locate the tail node. The tail node is not always the tail node, so you must find the tail node through the tail node every time you join the queue. The tail node may be the tail node or the next node of the tail node. The first if in the loop body in the code is to judge whether the tail has a next node. If so, it means that the next node may be the tail node. To get the next node of the tail node, we need to pay attention to the situation that the p node is equal to the q node. The reasons for this situation will be introduced later.
The second step is to set the queue node as the tail node. p.casNext(null, newNode) method is used to set the queued node as the next node of the tail node of the current queue. If q is null, it means P is the tail node of the current queue. If not null, it means that other threads have updated the tail node, and it is necessary to retrieve the tail node of the current queue.
The tail node is not necessarily the design intention of the tail node
For the first in first out queue, the thing to do is to set the queue node as the tail node. The code and logic written by doug lea are still a little complicated. So can I do it in the following ways?
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (;;) {
Node<E> t = tail;
if (t.casNext(null ,newNode) && casTail(t, newNode)) {
return true;
}
}
}Let the tail node always be the tail node of the queue, so that the amount of code is very small, and the logic is very clear and easy to understand. However, one disadvantage of this is that the tail node needs to be updated with cyclic CAS every time. If you can reduce the number of times CAS updates the tail node, you can improve the efficiency of joining the team.
In the implementation of JDK 1.7, doug lea uses the hops variable to control and reduce the update frequency of the tail node. Instead of updating the tail node to the tail node every time the node enters the queue, it updates the tail node when the distance between the tail node and the tail node is greater than or equal to the value of the constant hops (equal to 1 by default), The longer the distance between the tail node and the tail node, the fewer times to update the tail node with CAS. However, the negative effect of the longer distance is that the longer the time to locate the tail node each time you join the queue, because the loop body needs to cycle once more to locate the tail node, but this can still improve the efficiency of joining the queue, In essence, it reduces the write operation of volatile variable by increasing the read operation of volatile variable, and the cost of write operation of volatile variable is much greater than that of read operation, so the queue entry efficiency will be improved.
In the implementation of JDK 1.8, the update timing of tail is determined by whether p and t are equal. The implementation result is the same as that of JDK 1.7, that is, when the distance between tail node and tail node is greater than or equal to 1, the tail is updated.
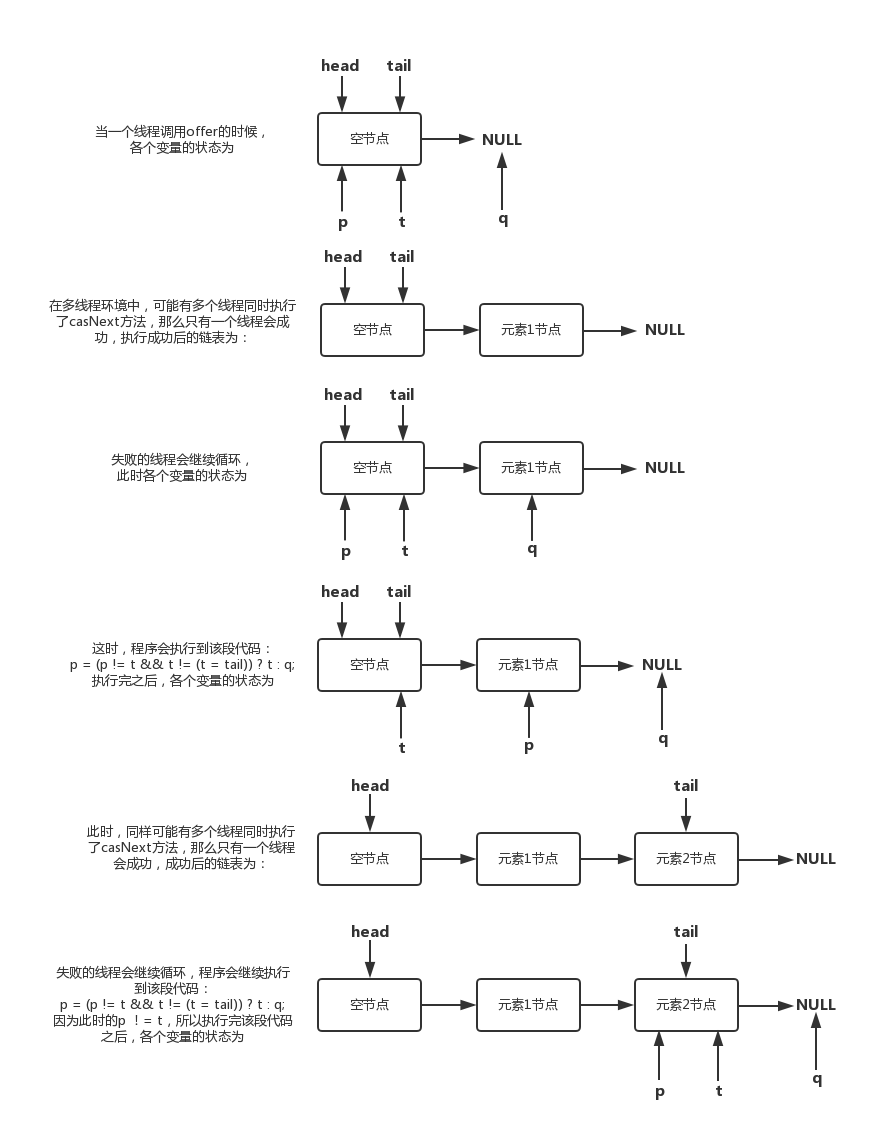
The overall logic of the queue joining operation of ConcurrentLinkedQueue is shown in the figure below:
Out of line operation
Out of the queue is to return a node element from the queue and clear the reference of the node to the element. Let's observe the changes of the head node through the out of queue snapshot of each node:
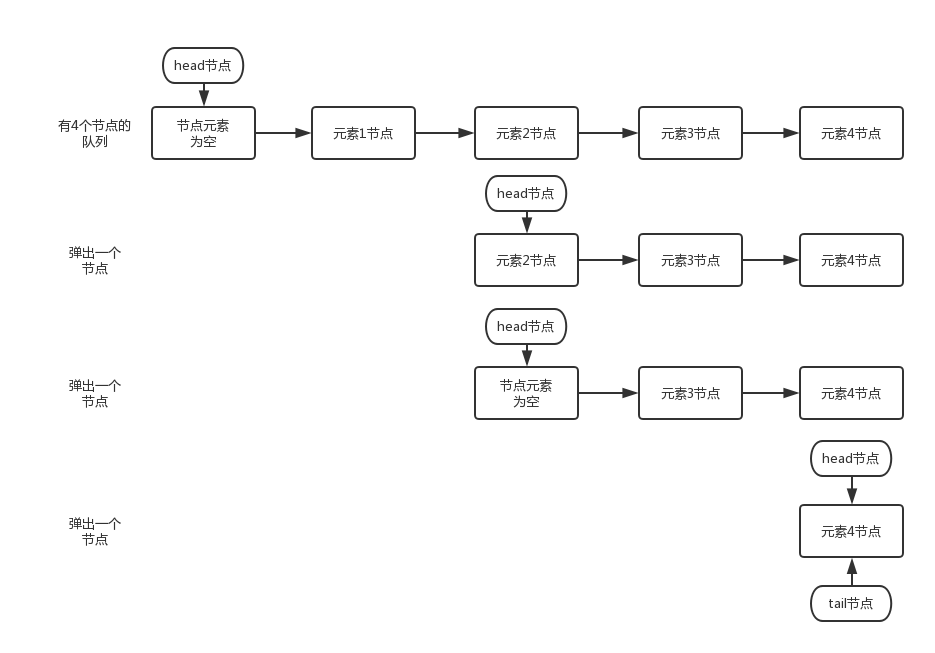
As can be seen from the above figure, the head node is not updated every time you leave the queue. When there are elements in the head node, the elements in the head node will pop up directly without updating the head node. Only when there is no element in the head node, the out of queue operation will update the head node. This method is also used to reduce the consumption of updating the head node with CAS, so as to improve the out of queue efficiency. Let's further analyze the process of leaving the team through the source code.
public E poll() {
restartFromHead:
for (;;) {
// Node p represents the first node, that is, the node that needs to leave the queue
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// If the element of the p node is not null, set the element referenced by the p node to null through CAS. If successful, return the element of the p node
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
// If P= h. Update head
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// If the element of the head node is empty or the head node has changed, it indicates that the head node has been modified by another thread.
// Then get the next node of the p node. If the next node of the p node is null, it indicates that the queue is empty
else if ((q = p.next) == null) {
// Update header node
updateHead(h, p);
return null;
}
// p == q, restart with a new head
else if (p == q)
continue restartFromHead;
// If the next element is not empty, the next node of the head node is set as the head node
else
p = q;
}
}
}The main logic of this method is to first obtain the element of the head node, and then judge whether the element of the head node is empty. If it is empty, it indicates that another thread has conducted a queue out operation to remove the element of the node. If it is not empty, use CAS to set the reference of the head node to null. If CAS succeeds, directly return the element of the head node, If it is not successful, it indicates that another thread has performed an out of queue operation and updated the head node, resulting in changes in the element and the need to retrieve the head node.
There is a situation of p == q in the operation of entering and leaving the team. How does this happen? Let's look at this operation:
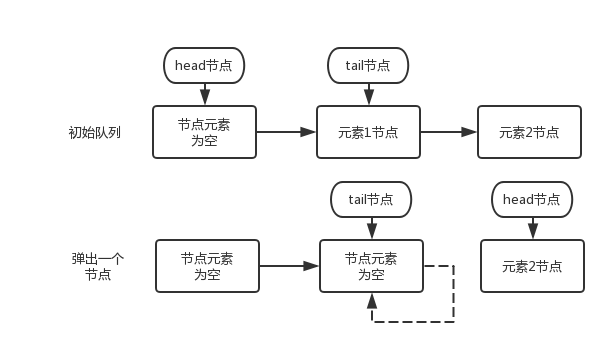
After a node pops up, the tail node has a dotted line pointing to itself. What does this mean? Let's look at the poll() method. In this method, after removing the element, the updateHead method will be called:
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
// Point the next field of the old head node h to H
h.lazySetNext(h);
}We can see that after updating the head, the next field of the old head node h will be pointed to H. the dotted line shown in the figure above also indicates the self reference of this node.
If there is another thread to add elements at this time, the next node obtained through tail is still itself, which leads to the situation of p == q. after this situation, it will trigger the update of the head and re point the p node to the head. All "alive" nodes (referring to the nodes not deleted) can be reached through traversal from the head, In this way, you can successfully get the tail node through the head, and then add elements.
Other relevant methods
peek() method
// Get the first element of the linked list (only read but not remove)
public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null || (q = p.next) == null) {
updateHead(h, p);
return item;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}As can be seen from the source code, peek operation will change the direction of head. After executing peek() method, head will point to the first node with non empty element.
size() method
public int size() {
int count = 0;
// first() gets the first node with non empty element, and returns null if it does not exist
// The succ(p) method obtains the successor node of p. if p = = the successor node of p, it returns head
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
// Maximum return integer MAX_ VALUE
if (++count == Integer.MAX_VALUE)
break;
return count;
}The size() method is used to obtain the number of elements in the current queue, but in a concurrent environment, the result may be inaccurate. Because the whole process is not locked, elements may be added or deleted from calling the size method to returning the result, resulting in inaccurate statistics of the number of elements.
remove(Object o) method
public boolean remove(Object o) {
// The deleted element cannot be null
if (o != null) {
Node<E> next, pred = null;
for (Node<E> p = first(); p != null; pred = p, p = next) {
boolean removed = false;
E item = p.item;
// Node element is not null
if (item != null) {
// If not, get the next node to continue matching
if (!o.equals(item)) {
next = succ(p);
continue;
}
// If it matches, set the corresponding node element to null through CAS operation
removed = p.casItem(item, null);
}
// Gets the successor node of the deleted node
next = succ(p);
// Remove the deleted node from the queue
if (pred != null && next != null) // unlink
pred.casNext(p, next);
if (removed)
return true;
}
}
return false;
}contains(Object o) method
public boolean contains(Object o) {
if (o == null) return false;
// Traversal queue
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
// Returns true if a matching node is found
if (item != null && o.equals(item))
return true;
}
return false;
}This method is similar to the size method. It may return an error result. For example, when the method is called, the element is still in the queue, but the element is deleted during traversal, then false will be returned.
ConcurrentLinkedQueue is a concurrent secure non blocking queue. In essence, we use spin CAS to complete the operation of entering and leaving the team, but we don't play in a general way.
Ordinary non blocking algorithm
The following is my own implementation of using spin CAS to achieve concurrent and safe queue entry and exit operations.
The design idea is that the head pointer points to the head of the queue every time you leave the queue, and the tail pointer points to the tail of the queue every time you join the queue.
The implementation is simple and clear, but Doug Lea thinks it's too spicy. He wants to optimize it again
public class NonLockQueue<T> extends AbstractQueue<T> implements Queue<T> {
public NonLockQueue() {
Node empty = new Node(null);
head = tail = empty;
}
@Override
public boolean offer(T t) {
Node<T> n = new Node(t);
for (; ; ) {
Node<T> p = tail;
if (!p.casNext(null, n)) {
continue;
}
tail = n;
break;
}
return true;
}
@Override
public T poll() {
for (; ; ) {
Node<T> h = head;
Node<T> next = h.next;
if (next == null) {
return null;
}
if (!casHead(h, next)) {
continue;
}
h.next = h;
T val = next.item;
next.item = null;
return val;
}
}
}
Doug Lea's non blocking algorithm
Doug Lea's non blocking algorithm can be summarized as follows
- The head/tail does not always point to the head/tail node of the queue, that is, the queue is allowed to be in an inconsistent state. This feature separates the two steps that need to be atomized together when entering / leaving the queue, so as to narrow the range of atomized update values to unique variables when entering / leaving the queue. This is the key to the implementation of non blocking algorithm.
- Because queues are sometimes in an inconsistent state. Therefore, ConcurrentLinkedQueue uses three invariants to maintain the correctness of the non blocking algorithm
- Update the head/tail in batch mode to reduce the cost of queue in / out operation as a whole.
Three invariants followed
(I) basic invariants
1. next=null of the last node in the queue
2. Traverse the nodes from the head to ensure that all valid nodes can be traversed through the next (casNext operation must be carried out before entering the queue to ensure that the tail may point to the deleted node, so traversing from the tail cannot ensure that the last node can be traversed)
(II) invariant of head
1,head!=null
2. The head will not point to the deleted node (h.next=h after casHead)
(III) invariant of tail
1,tail!=null
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
/**
* Set the current node as an invalid node (item=null)
* Lag operation updateHead
*/
if (item != null && p.casItem(item, null)) {
if (p != h)
// head pointer moves back
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
else if ((q = p.next) == null) {
/**
* Indicates p.item = null & & p.next = = null
* How head is still h and H= p, then modify the head to p
*/
updateHead(h, p);
return null;
}
else if (p == q)
/**
* Indicates that p is a deleted node
* Reassign h = head
*/
continue restartFromHead;
else
/**
* Since p.item = = null & & p.next= null &&p.next!= P is assigned p = q
*/
p = q;
}
}
}
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
/**
* Indicates that p is currently the last node in the queue
*/
if (p.casNext(null, newNode)) {
if (p != t)
casTail(t, newNode);
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q) {
/**
* q!=null && p==q Description: the current node is a deleted node
* If tail has been updated, p is assigned to tail, otherwise it is assigned to head [it can be seen from the invariant that the head node can traverse to the last node in the queue]
*/
p = (t != (t = tail)) ? t : head;
}else
/**
* q!=null && p!=q Indicates that the current node is not the last node in the queue
* When tail is updated, p=tail is assigned; otherwise, q is assigned
*/
p = (p != t && t != (t = tail)) ? t : q;
}
}
summary
The implementation of the non blocking algorithm of ConcurrentLinkedQueue can be summarized as follows:
- The use of CAS atomic instructions to handle concurrent access to data is the basis for the implementation of non blocking algorithm.
- The head/tail does not always point to the head/tail node of the queue, that is, the queue is allowed to be in an inconsistent state. This feature separates the two steps that need to be atomized together when entering / leaving the queue, so as to narrow the range of atomized update values to unique variables when entering / leaving the queue. This is the key to the implementation of non blocking algorithm.
- Because queues are sometimes in an inconsistent state. For this purpose, ConcurrentLinkedQueue uses Three invariants To maintain the correctness of the non blocking algorithm.
- Update the head/tail in batch mode to reduce the cost of queue in / out operation as a whole.
- In order to facilitate garbage collection, the queue uses a unique head update mechanism; In order to ensure backward traversal from deleted nodes to all non deleted nodes, the queue uses a unique backward propulsion strategy.
reference material
Fang Tengfei: the art of Java Concurrent Programming
Implementation of non blocking algorithm in concurrent container