Hello, everyone. Recently, I have shown my interest in concurrent programming (I can't help it. Others will. You can't say it). Then I will work hard to learn concurrent programming well. Next, let's enter the study together. Today, let's learn about the atomicity of thread safety
We've been talking about thread safety, thread safety, so what's his definition?
1. Thread safety definition
Thread safety definition:
When multiple threads access a class, no matter what scheduling strategy the runtime environment adopts or how these processes will execute alternately, and there is no need for any additional synchronization or collaboration in the main calling code, this class can show correct behavior, so this class is called thread safe.
Three characteristics:
Atomicity: provides mutually exclusive access. Only one thread can operate on it at a time.
Visibility: the modification of main memory by one thread can be observed by other threads in time (MESI plus bus sniffing mechanism).
Orderliness: one thread observes the execution order of instructions in other threads. Due to the instruction rearrangement optimization of cpu, the observation results are generally disordered.
2,Atomic
2.1 AtomicInteger
When it comes to atomicity, we have to mention that JDK provides us with good Atomic classes. They all complete atomicity through CAS.
In order to better understand its function, let's demonstrate some classes that are not atomic operations.
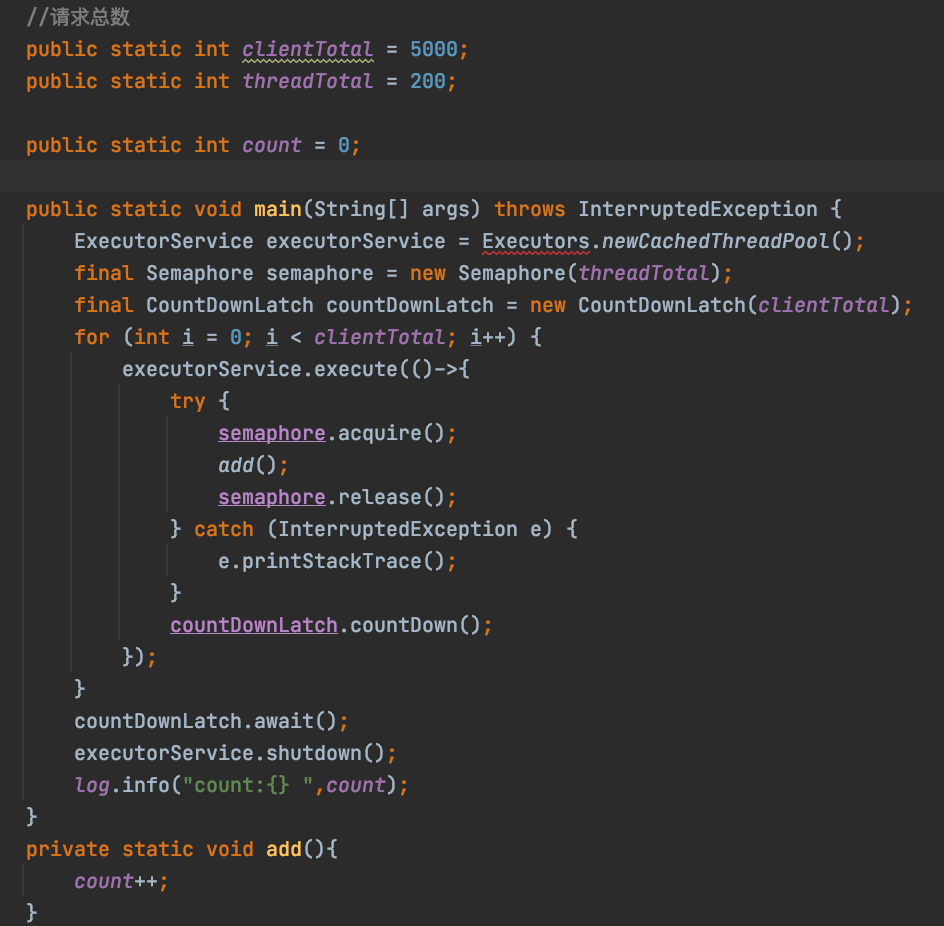
Let's look at the code I wrote above. We defined the number of users as 5000 and the concurrency as 200. We implemented it using Semaphore and CountDownLatch. So do we know the answer to the above code? I believe you know that the above scheme is not thread safe, so the count printed after execution will not be 5000. Then we know volatile can ensure memory visibility, so let's try it.
public static volatile int count = 0;
Then we add the volatile keyword. Do you know the execution result?
The answer is less than or equal to 5000. Maybe you don't understand the result. Why is this? Isn't it to ensure that the memory is visible. In fact, it does ensure that the memory is visible, but count + + is not an Atomic operation. It is equivalent to assigning a value first and then adding 1. It is a two-step operation. In this case, there will be problems, which is why the atomicity of volatile is not guaranteed. We can solve this problem by using Atomic class because it is Atomic operation.
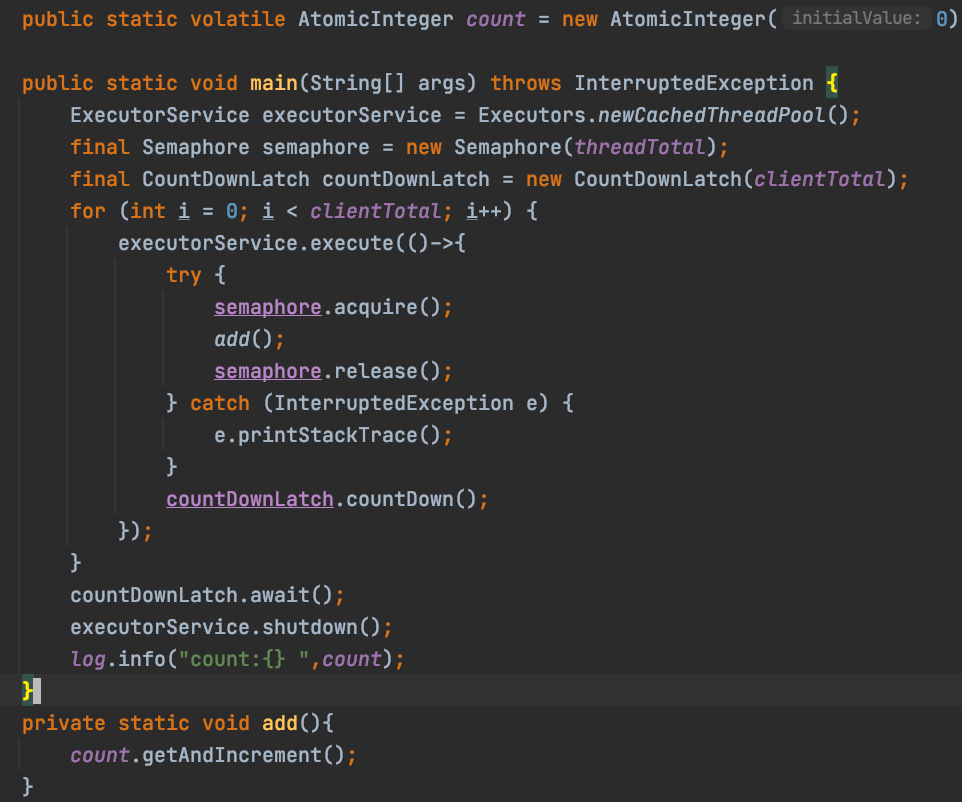
So why can he guarantee atomicity? Next, let's see what the getAndIncrement() method does.
private static void add(){
//Call getAndIncrement()
count.getAndIncrement();
}
public final int getAndIncrement() {
//Call the getAndAddInt method of the unsafe class, and pass in its own reference, value and added 1
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
Let's focus on the getAndAddInt method. In the method parameters, the first parameter represents the reference of the current class, the second parameter represents the current value, and the third parameter represents how much to add.
First define a var5 variable, then get the value from main memory, and then go through the do while loop. There is a very important method, compareAndSwapInt, which compares and replaces. This method means that. I compare my current value with the value in memory. If one is inconsistent, continue to compare and get the value from memory. When it is consistent, add and return.
Let's look at the initials of the method name of compareAndSwapInt. We can see that this is CAS!
2.2 AtomicLong
AtomicLong is used in the same way as AtomicInteger. Let's take a look at an example:
//Total requests
public static int clientTotal = 5000;
public static int threadTotal = 200;
public static AtomicLong count = new AtomicLong(0);
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
add();
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{} ",count);
}
private static void add(){
count.getAndIncrement();
}
We are now using AtomicLong, which can ensure atomicity.
What about his underlying implementation
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
We can clearly see that CAS logic algorithm is also used.
2.3 LongAdder
For example, I work as a big data real-time processing platform. I often encounter the need to count the number of incoming data, the number of processed data, and the number that failed to pass the verification in the flink. At this time, we often encounter the demand for the total amount. At this time, we can adopt LongAddr, which was generated after java 1.8.
Let's take a look at the sample code:
//Total requests
public static int clientTotal = 5000;
public static int threadTotal = 200;
public static LongAdder count = new LongAdder();
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
add();
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{} ",count);
}
private static void add(){
count.increment();
}
We can see that there is only a little difference in use, so why does this LongAdder appear? Because when using AtomicLong, if there is a fierce competition for resources, it will frequently go to memory to obtain values, and then calculate and replace them. At this time, it will have a performance impact.
This problem will not occur in LongAdder. In fact, in the jdk, for ordinary double variables and long variables, the jvm allows a 64 bit read or write operation to be split into two 32-bit operations.
So what is the core idea of LongAdder? Separating hot data, that is, it roughly means making its own values into an array, and then the thread comes and hash to a certain point for updating. The final value is the result of cumulative summation, but there will also be a problem, that is, when high concurrency and frequent updates, There may be some errors in the data.
2.4 AtomicBoolean
I won't do code demonstration for this class. Let's take a look at the underlying logic:
public final boolean compareAndSet(boolean expect, boolean update) {
int e = expect ? 1 : 0;
int u = update ? 1 : 0;
return unsafe.compareAndSwapInt(this, valueOffset, e, u);
}
We look at this method. In fact, the bottom layer of logic is to convert our boolean type into our int type for calculation, and use the casInt method of unsafe class.
2.5 AtomicReference
Let's take a look at his use
private static AtomicReference<Integer> count = new AtomicReference<>(0);
public static void main(String[] args) {
count.compareAndSet(0,1);
count.compareAndSet(0,1);
count.compareAndSet(1,3);
log.info(String.valueOf(count.get()));
}
We can see that similar to other classes in Atomic, a reference object is wrapped as Atomic.
2.6 ABA issues
In fact, we can find a problem here. What is the problem? That is, if my initial value is 0, I will modify it to 1. If my initial value is 1, I will modify it to 0. At this time, the middle value changes. If other threads use this value, it changes, but others don't know, This is the ABA problem of CAS.
To solve this problem is to add versions. For example, if I update to 0, then it is version 0, change to 2 is version 1, and so on. Operations like this can solve the ABA problem. As long as it is modified, it will change.
2.7 AtomicStampedReference
The emergence of this class is to solve the ABA problem.
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
No more examples, but here we see that he has added a version comparison.
3. Summary
1. We introduced some CAS principles under Atomic packages, that is, unsafe Compareandswapxxx, its core principle is to compare and then replace.
2. Then we looked at AtomicLong and LongAdder. When there are not so many high concurrency cases, we can use LongAdder to increase the operation efficiency.
3. The ABA problem is that under our multithreading, the original value is restored after the value is modified, and other threads will not know the update process. This is also the ABA problem.
4. In order to solve the ABA problem of CAS, there is atomicstamppreference, which is based on version number comparison.
Well, thank you for watching. I'm fat, a code animal who loves learning.