Guava is Google's open source Java class library, which provides a tool class RateLimiter. Let's take a look at the use of RateLimiter to give you a sensory impression of current limiting. Suppose we have a thread pool, which can only process two tasks per second. If the task submitted is too fast, it may lead to system instability. At this time, we need to use flow restriction.
In the following example code, we create a current limiter with a flow rate of 2 requests / second. How to understand the flow rate here? Intuitively, two requests per second means that up to two requests per second are allowed to pass through the current limiter. In fact, in Guava, the flow rate has a deeper meaning: it is a concept of uniform speed. Two requests per second is equivalent to one request / 500 milliseconds.
Before submitting a task to the thread pool, calling the acquire() method can play the role of current limiting. Through the execution results of the sample code, the time interval between task submission to the thread pool is basically stable at 500 milliseconds.
/* Flow rate of current limiter: 2 requests / sec= */
RateLimiter.create( 2.0 );
/* Thread pool for executing tasks */
ExecutorService es = Executors
.newFixedThreadPool( 1 );
/* Record the last execution time */
prev = System.nanoTime();
/* The test was performed 20 times */
for ( int i = 0; i < 20; i++ )
{
/* Current limiter */
limiter.acquire();
/* Submit task to execute asynchronously */
es.execute( () - > {
long cur = System.nanoTime();
/* Print interval: ms */
System.out.println(
(cur - prev) / 1000_000 );
prev = cur;
} );
}
Output results:
...
500
499
499
500
499Classical current limiting algorithm: token bucket algorithm
Guava's current limiter is still very simple to use. How is it implemented? Guava adopts the token bucket algorithm. Its core is to get the token if you want to pass through the current limiter. In other words, as long as we can limit the rate of issuing tokens, we can control the flow rate. The token bucket algorithm is described in detail as follows:
- The token is added to the token bucket at a fixed rate. Assuming that the current limiting rate is r / s, one token will be added every 1/r second;
- Assuming that the capacity of the token bucket is b, if the token bucket is full, the new token will be discarded;
- The premise that the request can pass through the current limiter is that there is a token in the token bucket.
In this algorithm, the current limiting rate r is easy to understand, but how to understand the capacity b of the token bucket? b is actually the abbreviation of burst, which means the maximum burst flow allowed by the current limiter. For example, b=10, and the token in the token bucket is full. At this time, the current limiter allows 10 requests to pass through the current limiter at the same time. Of course, it is only burst traffic. These 10 requests will take away 10 tokens, so the subsequent traffic can only pass through the current limiter at rate r.
How to implement the token bucket algorithm in Java? It is likely that your intuition will tell you the producer consumer mode: a producer thread regularly adds tokens to the blocking queue, while the thread trying to pass through the restrictor acts as a consumer thread. It is allowed to pass through the restrictor only when it obtains tokens from the blocking queue.
This algorithm looks very perfect, and the implementation is very simple. If the concurrency is small, there is no problem with this implementation. But the actual situation is that most of the current limiting scenarios are high concurrency scenarios, and the system pressure is approaching the limit. At this time, there is a problem with this implementation. The problem lies in the timer. In the high concurrency scenario, when the system pressure is close to the limit, the accuracy error of the timer will be very large. At the same time, the timer itself will create a scheduling thread, which will also affect the performance of the system.
So what's a good way to implement it? Of course, Guava's implementation does not use a timer. Let's see how it is implemented.
How Guava implements token bucket algorithm
Guava implements the token bucket algorithm with a very simple method. The key is to record and dynamically calculate the time of issuing the next token. Next, we introduce the implementation process of the algorithm in the simplest scenario. Suppose the capacity of the token bucket is b=1 and the current limiting rate is r = 1 request / s, as shown in the figure below. If there is no token in the current token bucket, the issuing time of the next token is in the third second, and a thread T1 requests a token in the second second second. How to deal with it?

Thread T1 request token diagram
For the thread requesting the token, it obviously needs to wait for 1 second, because it can get the token after 1 second (the third second). At this time, it should be noted that the time for issuing the next token should also be increased by 1 second. Why? Because the token issued in the third second has been preempted by thread T1. After processing, see the following figure.

Thread T1 request end diagram
Suppose T1 preempts the token for the third second, and immediately another thread T2 requests the token, as shown in the following figure.
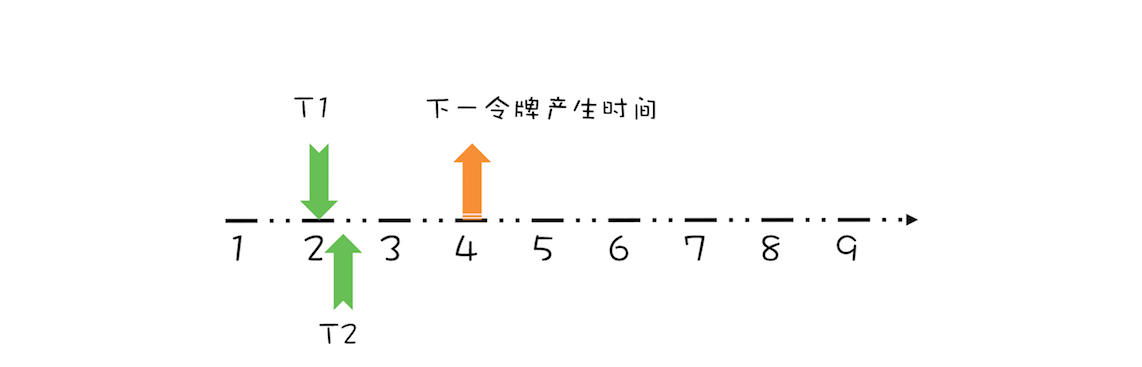
Thread T2 request token diagram
Obviously, since the generation time of the next token is the 4th second, thread T2 needs to wait for two seconds to obtain the token. At the same time, since T2 pre occupies the 4th second token, the generation time of the next token needs to be increased by 1 second. After complete processing, as shown in the figure below.
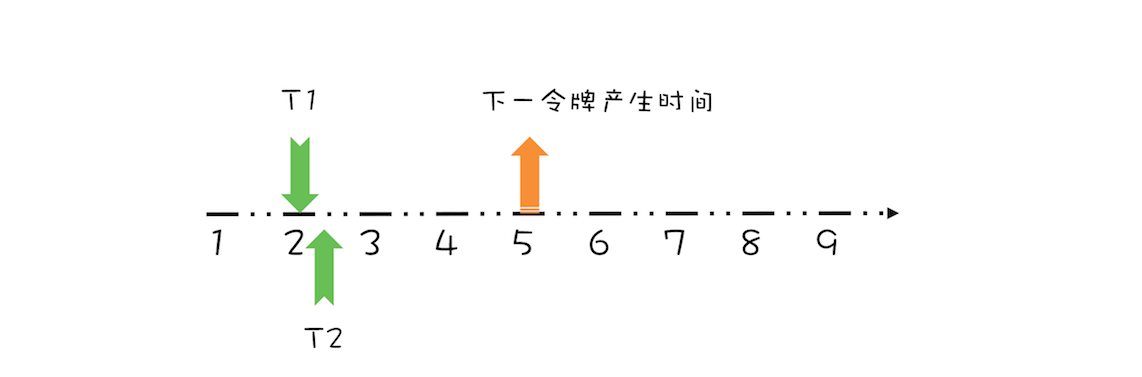
Thread T2 request end diagram
The above threads T1 and T2 request tokens before the next token generation time. What happens if the thread requests tokens after the next token generation time? Suppose that thread T3 requests a token five seconds after thread T1 requests a token, that is, the seventh second, as shown in the following figure.

Thread T3 request token diagram
Since a token has been generated in the fifth second, thread T3 can get the token directly without waiting. In the 7th second, the actual upper limit streamer can generate three tokens, and one token in the 5th, 6th and 7th seconds respectively. Since we assume that the capacity of the token bucket is 1, the tokens generated in the 6th and 7th seconds are discarded. In fact, you can also think of the reserved tokens in the 7th second and the discarded tokens in the 5th and 6th seconds, that is, the tokens in the 7th second are occupied by thread T3, so the generation time of the next token should be the 8th second, as shown in the figure below.

Thread T3 request end diagram
Through the above brief analysis, you will find that we only need to record the generation time of the next token and dynamically update it to easily complete the current limiting function. We can code the above algorithm. The example code is as follows. It is still assumed that the capacity of the token bucket is 1. The key is the reserve() method, which will pre allocate the token to the thread requesting the token and return the time when the thread can obtain the token. The implementation logic is mentioned above: if the thread requests a token after the next token generation time, the thread can obtain the token immediately; Conversely, if the request time is before the next token generation time, the thread obtains the token at the next token generation time. Since the next token has been preempted by the thread at this time, the generation time of the next token needs to be added with 1 second.
class SimpleLimiter {
/* Next token generation time */
long next = System.nanoTime();
/* Token issuing interval: nanoseconds */
long interval = 1000_000_000;
/* Preempt the token and return the time when the token can be obtained */
synchronized long reserve( long now )
{
/*
* The request time is after the next token generation time
* Recalculate next token generation time
*/
if ( now > next )
{
/* Resets the next token generation time to the current time */
next = now;
}
/* Time when the token can be obtained */
long at = next;
/* Set next token generation time */
next += interval;
/* Returns the time the thread needs to wait */
return(Math.max( at, 0L ) );
}
/* Claim Token */
void acquire()
{
/* Time when token was requested */
long now = System.nanoTime();
/* Preemption token */
long at = reserve( now );
long waitTime = max( at - now, 0 );
/* Wait according to conditions */
if ( waitTime > 0 )
{
try {
TimeUnit.NANOSECONDS
.sleep( waitTime );
}catch ( InterruptedException e ) {
e.printStackTrace();
}
}
}
}What if the capacity of the token bucket is greater than 1? According to the token bucket algorithm, the token should be taken out of the token bucket first, so we need to calculate the number of tokens in the token bucket on demand. When a thread requests a token, it should be taken out of the token bucket first. The specific code implementation is as follows. We added a resync() method. In this method, if the thread requests a token after the next token generation time, the number of tokens in the token bucket will be recalculated. The calculation formula of the newly generated token is: (now next) / interval. You can understand it by referring to the diagram above. In the reserve() method, the logic of getting the token out of the token bucket first is added. However, it should be noted that if the token is out of the token bucket, there is no need to add an interval in the next.
class SimpleLimiter {
/* Number of tokens in the current token bucket */
long storedPermits = 0;
/* Capacity of token bucket */
long maxPermits = 3;
/* Next token generation time */
long next = System.nanoTime();
/* Token issuing interval: nanoseconds */
long interval = 1000_000_000;
/*
* If the request time is after the next token generation time, then
* 1. Recalculate the number of tokens in the token bucket
* 2. Reset the next token issuing time to the current time
*/
void resync( long now )
{
if ( now > next )
{
/* Number of newly generated tokens */
long newPermits = (now - next) / interval;
/* Add new token to token bucket */
storedPermits = min( maxPermits,
storedPermits + newPermits );
/* Reset the next token issuing time to the current time */
next = now;
}
}
/* Preempt the token and return the time when the token can be obtained */
synchronized long reserve( long now )
{
resync( now );
/* Time when the token can be obtained */
long at = next;
/* Tokens that can be provided in the token bucket */
long fb = min( 1, storedPermits );
/* Net token demand: first subtract the token in the token bucket */
long nr = 1 - fb;
/* Recalculate next token generation time */
next = next + nr * interval;
/* Recalculate tokens in token bucket */
this.storedPermits -= fb;
return(at);
}
/* Claim Token */
void acquire()
{
/* Time when token was requested */
long now = System.nanoTime();
/* Preemption token */
long at = reserve( now );
long waitTime = max( at - now, 0 );
/* Wait according to conditions */
if ( waitTime > 0 )
{
try {
TimeUnit.NANOSECONDS
.sleep( waitTime );
}catch ( InterruptedException e ) {
e.printStackTrace();
}
}
}
}summary
There are two classical current limiting algorithms, one is Token Bucket algorithm and the other is Leaky Bucket algorithm. The Token Bucket algorithm sends a token to the Token Bucket regularly, and requests that the token can be obtained from the Token Bucket before it can pass through the current limiter; In the Leaky Bucket algorithm, the request is injected into the Leaky Bucket like water. The Leaky Bucket will automatically leak water at a certain rate. The request can pass through the current limiter only when water can be injected into the Leaky Bucket. Token Bucket algorithm and Leaky Bucket algorithm are very much like the front and back of a coin, so you can refer to the implementation of Token Bucket algorithm to implement Leaky Bucket algorithm.
Above, we introduced how guava implements the token bucket algorithm. Our example code is a simplification of Guava RateLimiter. Guava RateLimiter extends the standard token bucket algorithm, for example, it can also support the preheating function. For the cache loaded on demand, the cache can support the concurrency of 50000 TPS after preheating, but the concurrency of 50000 TPS directly destroys the cache before preheating. Therefore, if it is necessary to limit the current of the cache, the current limiter also needs to support the preheating function. In the initial stage, the Limited flow rate r is very small, but it increases dynamically. The implementation of preheating function is very complex. Guava has built an integral function to solve this problem. If you are interested, you can continue to study it in depth.