Introduction
Previously, we learned the concepts of thread and process, and learned that * * process is the smallest unit of resource allocation in the operating system, and thread is the smallest unit of CPU scheduling** In principle, we have improved the utilization of CPU a lot. However, we know that whether creating multiple processes or creating multiple threads to solve the problem, it takes a certain amount of time to create processes, create threads, and manage the switching between them.
With the continuous improvement of our pursuit of efficiency, it has become a new topic to realize concurrency based on single thread, that is, to realize concurrency with only one main thread (obviously, there is only one available cpu). This saves the time it takes to create a line process.
Therefore, we need to review the essence of Concurrency: switching + saving state
When the cpu is running a task, it will cut off to execute other tasks in two cases (the switching is forcibly controlled by the operating system). One case is that the task is blocked, and the other case is that the calculation time of the task is too long
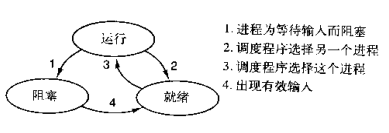
ps: when introducing the process theory, the three execution states of the process are mentioned, and the thread is the execution unit. Therefore, the above figure can also be understood as the three states of the thread
1: In the second case, the efficiency cannot be improved. It is just to make the cpu wet and wet, so as to achieve the effect that all tasks seem to be executed "at the same time". If multiple tasks are purely computational, this switching will reduce the efficiency.
Therefore, we can verify based on yield. Yield itself is a method that can save the running state of a task under a single thread. Let's briefly review:
#1. LED can save the state. The state saving of yield is very similar to the thread state saving of the operating system, but yield is controlled at the code level and is more lightweight #2 send can transfer the result of one function to another function, so as to realize the switching between programs in a single thread
Simply switching will reduce the operation efficiency
#Serial execution
import time
def consumer(res):
'''Task 1:receive data ,Processing data'''
pass
def producer():
'''Task 2:production data '''
res=[]
for i in range(10000000):
res.append(i)
return res
start=time.time()
#Serial execution
res=producer()
consumer(res) #Writing as consumer(producer()) will reduce execution efficiency
stop=time.time()
print(stop-start) #1.5536692142486572
#Concurrent execution based on yield
import time
def consumer():
'''Task 1:receive data ,Processing data'''
while True:
x=yield
def producer():
'''Task 2:production data '''
g=consumer()
next(g)
for i in range(10000000):
g.send(i)
start=time.time()
#Based on the state saved by yield, the two tasks can be switched back and forth directly, that is, the effect of concurrency
#PS: if printing is added to each task, it is obvious that the printing of the two tasks is performed simultaneously
producer()
stop=time.time()
print(stop-start) #2.0272178649902344
2: Switching in the first case. When task 1 encounters io, switch to task 2 for execution. In this way, the blocking time of task 1 can be used to complete the calculation of task 2. This is why the efficiency is improved.
yield Unable to meet io block
import time
def consumer():
'''Task 1:receive data ,Processing data'''
while True:
x=yield
def producer():
'''Task 2:production data '''
g=consumer()
next(g)
for i in range(10000000):
g.send(i)
time.sleep(2)
start=time.time()
producer() #Concurrent execution, but the task producer will block when it encounters io and will not switch to other tasks in the thread for execution
stop=time.time()
print(stop-start)
For a single thread, we cannot avoid io operations in the program, but if we can control multiple tasks under a single thread in our own program (i.e. user program level rather than operating system level), we can switch to another task for calculation when one task encounters io blocking, so as to ensure that the thread can be in the ready state to the greatest extent, That is, the state that can be executed by the cpu at any time is equivalent to that we hide our io operations to the greatest extent at the user program level, so that we can confuse the operating system and let it see that the thread seems to be calculating all the time, and there is less io, so we allocate more execution permissions of the cpu to our threads.
The essence of a collaborative process is that in a single thread, the user controls a task and switches another task to execute when it is io blocked, so as to improve efficiency. In order to realize it, we need to find a solution that can meet the following conditions at the same time:
#1. The switching between multiple tasks can be controlled. Before switching, the state of the task can be saved so that when it is run again, it can continue to execute based on the suspended position.
#2. As a supplement to 1: io operations can be detected, and switching occurs only when io operations are encountered
Introduction to collaborative process
Co process: it is concurrency under single thread, also known as micro thread and fiber process. English name Coroutine. What is a thread in one sentence: a Coroutine is a lightweight thread in user mode, that is, the Coroutine is controlled and scheduled by the user program itself.
It should be emphasized that:
#1. python threads belong to the kernel level, that is, they are scheduled under the control of the operating system (for example, if a single thread encounters io or the execution time is too long, it will be forced to hand over the cpu execution permission and switch other threads to run) #2. Start the co process in a single thread. Once io is encountered, it will control the switching from the application level (rather than the operating system) to improve efficiency (!!! The switching of non io operations has nothing to do with efficiency)
Compared with the switching of operating system control threads, users control the switching of coprocesses in a single thread
The advantages are as follows:
#1. The switching overhead of the cooperative process is smaller. It belongs to program level switching, which is completely invisible to the operating system, so it is more lightweight
#2. The effect of concurrency can be realized in a single thread to maximize the use of cpu
The disadvantages are as follows:
#1. The essence of a collaboration is that multiple cores cannot be used under a single thread. One program can start multiple processes. Multiple threads are opened in each process, and the collaboration is opened in each thread
#2. A coroutine refers to a single thread, so once the coroutine is blocked, the whole thread will be blocked
Summarize the characteristics of collaborative process:
1. Concurrency must be implemented in only one single thread
2. No lock is required for modifying shared data
3. The user program saves the context stack of multiple control flows
4. Add: one collaboration automatically switches to other collaboration when encountering IO operation (how to detect IO, yield and greenlet cannot be realized, so gevent module (select mechanism) is used)
Greenlet module
Installation: pip3 install greenlet
greenlet Realize state switching
from greenlet import greenlet
def eat(name):
print('%s eat 1' %name)
g2.switch('egon')
print('%s eat 2' %name)
g2.switch()
def play(name):
print('%s play 1' %name)
g1.switch()
print('%s play 2' %name)
g1=greenlet(eat)
g2=greenlet(play)
g1.switch('egon')#You can pass in parameters during the first switch, and you don't need them in the future
Simple switching (without io or repeated operations to open up memory space) will reduce the execution speed of the program
Efficiency comparison
#Sequential execution
import time
def f1():
res=1
for i in range(100000000):
res+=i
def f2():
res=1
for i in range(100000000):
res*=i
start=time.time()
f1()
f2()
stop=time.time()
print('run time is %s' %(stop-start)) #10.985628366470337
#switch
from greenlet import greenlet
import time
def f1():
res=1
for i in range(100000000):
res+=i
g2.switch()
def f2():
res=1
for i in range(100000000):
res*=i
g1.switch()
start=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
stop=time.time()
print('run time is %s' %(stop-start)) # 52.763017892837524
greenlet only provides a more convenient switching mode than the generator. When switching to a task execution, if IO is encountered, it will block in place. It still does not solve the problem of automatic IO switching to improve efficiency.
The code of these 20 tasks in a single thread usually has both computing operations and blocking operations. We can use the blocking time to execute task 2 when we encounter blocking in task 1.... In this way, the efficiency can be improved, which uses the Gevent module.
Gevent module
Installation: pip3 install gevent
Gevent is a third-party library, which can easily realize concurrent synchronous or asynchronous programming through gevent. The main mode used in gevent is Greenlet, which is a lightweight process connected to Python in the form of C extension module. Greenlets all run inside the main program operating system process, but they are scheduled cooperatively.
Usage introduction g1=gevent.spawn(func,1,,2,3,x=4,y=5)Create a coroutine object g1,spawn The first parameter in parentheses is the function name, such as eat,There can be multiple parameters, which can be location arguments or keyword arguments, which are passed to the function eat of g2=gevent.spawn(func2) g1.join() #Wait for g1 to end g2.join() #Wait for g2 to end #Or the above two steps cooperate in one step: gevent joinall([g1,g2]) g1.value#Get the return value of func1
Example: encountered io Active switching
import gevent
def eat(name):
print('%s eat 1' %name)
gevent.sleep(2)
print('%s eat 2' %name)
def play(name):
print('%s play 1' %name)
gevent.sleep(1)
print('%s play 2' %name)
g1=gevent.spawn(eat,'egon')
g2=gevent.spawn(play,name='egon')
g1.join()
g2.join()
#Or gevent joinall([g1,g2])
print('main')
Gevent Sleep (2) simulates io blocking recognized by gevent, while time Sleep (2) or other blockages cannot be directly identified by gevent. You can identify them by patching with the following line of code
from gevent import monkey;monkey.patch_all() must be placed in front of the patched person, such as time and socket module
Or we can simply remember that to use gevent, you need to import from gevent into monkey; monkey. patch_ All() at the beginning of the file
from gevent import monkey;monkey.patch_all()
import gevent
import time
def eat():
print('eat food 1')
time.sleep(2)
print('eat food 2')
def play():
print('play 1')
time.sleep(1)
print('play 2')
g1=gevent.spawn(eat)
g2=gevent.spawn(play)
gevent.joinall([g1,g2])
print('main')
We can use threading current_ thread(). Getname() to view each g1 and g2. The result is dummy thread-n, that is, false thread
see threading.current_thread().getName()
from gevent import monkey;monkey.patch_all()
import threading
import gevent
import time
def eat():
print(threading.current_thread().getName())
print('eat food 1')
time.sleep(2)
print('eat food 2')
def play():
print(threading.current_thread().getName())
print('play 1')
time.sleep(1)
print('play 2')
g1=gevent.spawn(eat)
g2=gevent.spawn(play)
gevent.joinall([g1,g2])
print('main')
Synchronous and asynchronous of Gevent
from gevent import spawn,joinall,monkey;monkey.patch_all()
import time
def task(pid):
"""
Some non-deterministic task
"""
time.sleep(0.5)
print('Task %s done' % pid)
def synchronous(): # synchronization
for i in range(10):
task(i)
def asynchronous(): # asynchronous
g_l=[spawn(task,i) for i in range(10)]
joinall(g_l)
print('DONE')
if __name__ == '__main__':
print('Synchronous:')
synchronous()
print('Asynchronous:')
asynchronous()
# An important part of the above program is to encapsulate the task function into the gevent of the internal thread of Greenlet spawn.
# The initialized greenlet list is stored in the array threads, which is passed to gevent Joinall function,
# The latter blocks the current process and executes all given greenlet tasks. The execution process will only continue to go down after all greenlets are executed.
"""Code level"""
Third party gevent modular:Able to monitor independently IO Behavior and switching
from gevent import monkey;monkey.patch_all() # All IO behaviors can be detected only after the fixed code format is added
from gevent import spawn
import time
def play(name):
print('%s play 1' % name)
time.sleep(5)
print('%s play 2' % name)
def eat(name):
print('%s eat 1' % name)
time.sleep(3)
print('%s eat 2' % name)
start = time.time()
# play('jason') # Normal synchronous call
# eat('jason') # Normal synchronous call
g1 = spawn(play, 'jason') # Asynchronous commit
g2 = spawn(eat, 'jason') # Asynchronous commit
g1.join()
g2.join() # Wait for the monitored task to run
print('main', time.time() - start) # Realize concurrency under single thread to improve efficiency
The effect of concurrency of TCP server is realized by CO process
# Concurrency effect: a server can serve multiple clients at the same time
import socket
from gevent import monkey;monkey.patch_all()
from gevent import spawn
def talk(sock):
while True:
try:
data = sock.recv(1024)
if len(data) == 0:break
print(data)
sock.send(data+b'hello baby!')
except ConnectionResetError as e:
print(e)
sock.close()
break
def servers():
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen()
while True:
sock, addr = server.accept()
spawn(talk,sock)
g1 = spawn(servers)
g1.join()
# The client can set up hundreds of threads to send messages
"""
The best situation:Setting up multithreading under multi process