Concurrent programming - panden's notes on concurrent programming in python
Serial, parallel and concurrent
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-vcijuIAg-1644766841076)(./img / serial parallel and concurrent. png)]
- Serial: multiple tasks are completed in sequence on one CPU
- Parallelism: it means that the number of tasks is less than or equal to the number of cpu cores, that is, tasks are really executed together
- Concurrency: a CPU uses time slice management to process multiple tasks alternately. Generally, the number of tasks exceeds the number of CPU cores. Through various task scheduling algorithms of the operating system, multiple tasks are "executed together" (in fact, there are always some tasks that are not executed, because the speed of switching tasks is quite fast, it seems that they are executed together)
Processes, threads, and coroutines
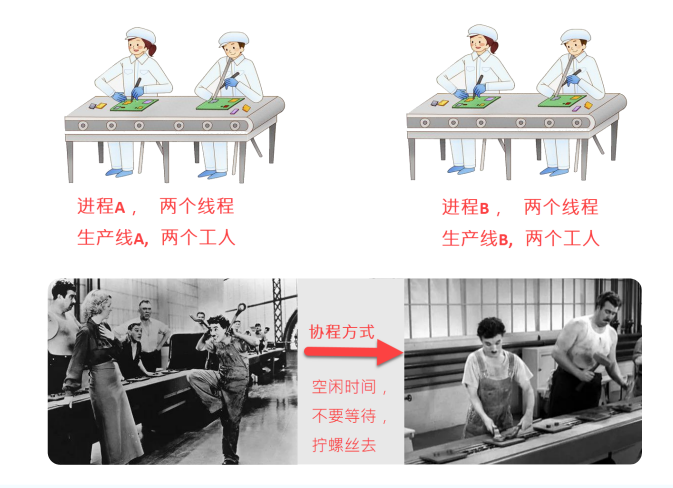
Note: collaboration is just a way of doing things
Relationship between process, thread and coroutine
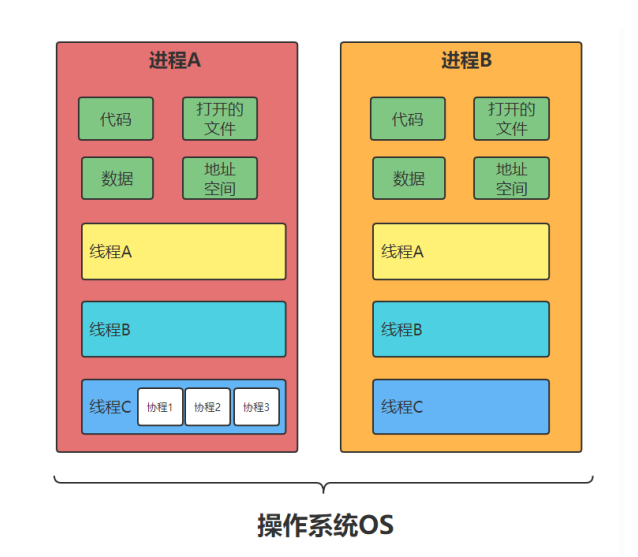
-
Thread is the smallest unit of program execution, and process is the smallest unit of resource allocation by the operating system;
-
A process is composed of one or more threads. Threads are different execution routes of code in a process;
-
Processes are independent of each other, but the memory space of the program (including code segments, data sets, heaps, etc.) and some process level resources (such as opening files and signals) are shared among threads in the same process, and the threads in a process are not visible in other processes;
-
Scheduling and switching: thread context switching is much faster than process context switching.
- Process: it has its own independent heap and stack, neither sharing heap nor stack. The process is scheduled by the operating system; Process switching requires the most resources and is inefficient
- Thread: it has its own independent stack and shared heap. Shared heap and no stack are shared. Standard threads are scheduled by the operating system; Thread switching requires average resources and efficiency (of course, without considering GIL)
- Coroutine: it has its own independent stack and shared heap. The shared heap does not share the stack. The coroutine is displayed and scheduled by the programmer in the code of the coroutine; Collaborative process switching has small task resources and high efficiency
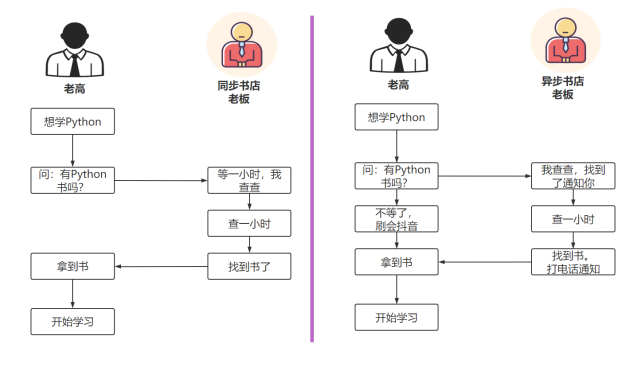
Synchronous and asynchronous
Synchronous and asynchronous emphasize the message communication mechanism, so asynchronous programming only appears in network communication
- Synchronization: A calls B and waits for B to return the result before A continues to execute
- Asynchronous: A calls B, and A continues to execute without waiting for B to return results; B has the result, inform A, and A will deal with it again.
Thread usage
How threads are created
Python's standard library provides two modules:_ thread and threading_ thread is a low-level module and threading is a high-level module, right_ thread is encapsulated. In most cases, we only need to use the advanced module threading.
Threads can be created in two ways:
- 1. Packaging method
from threading import Thread
from time import sleep
def func1(name):
print(f'thread {name} start')
for i in range(3):
print(f'thread : {name}. {i}')
sleep(1)
print(f'thread {name} end')
if __name__ == '__main__':
print("Main thread: strat")
# Create thread
t1 = Thread(target=func1,args=("1",))
t2 = Thread(target=func1,args=("2",))
# Start thread
t1.start()
t2.start()
print('Main thread: end')
- 2. Class packaging
from threading import Thread
from time import sleep
class MyThread(Thread):
def __init__(self,name):
Thread.__init__(self)
self.name = name
# Method override, the run function name cannot be changed
def run(self):
print(f'thread {self.name} start')
for i in range(3):
print(f'thread : {self.name}. {i}')
sleep(1)
print(f'thread {self.name} end')
if __name__ == '__main__':
print("Main thread: strat")
# Create thread
t1 = MyThread('1')
t2 = MyThread('2')
# Start thread
t1.start()
t2.start()
print('Main thread: end')
Threads are executed uniformly through the start() method
join
In the previous code, we will find that the main thread will not wait for the end of the child thread; We can use the join method to make the main thread wait for the end of the child thread;
from threading import Thread
from time import sleep
def func1(name):
print(f'thread {name} start')
for i in range(3):
print(f'thread : {name}. {i}')
sleep(1)
print(f'thread {name} end')
if __name__ == '__main__':
print("Main thread: strat")
# Create thread
t1 = Thread(target=func1,args=("1",))
t2 = Thread(target=func1,args=("2",))
# Start thread
t1.start()
t2.start()
# The main thread waits for the end of the child thread
t1.join()
t2.join()
print('Main thread: end')
Daemon thread
The main feature of daemon thread is its life cycle. When the main thread dies, it dies. In python, the thread sets whether it is a daemon thread through setDaemon(True|False).
The daemon of GC threads is the most convenient function of GC application daemon threads.
Observe the following codes:
from threading import Thread
from time import sleep
class MyThread(Thread):
def __init__(self,name):
Thread.__init__(self)
self.name = name
# Method override, the run function name cannot be changed
def run(self):
print(f'thread {self.name} start')
for i in range(3):
print(f'thread : {self.name}. {i}')
sleep(1)
print(f'thread {self.name} end')
if __name__ == '__main__':
print("Main thread: strat")
# Create thread
t1 = MyThread('1')
t2 = MyThread('2')
# Set daemon thread
t1.daemon = True # When the main thread dies, the t1 thread also dies
# Start thread
t1.start()
t2.start()
print('Main thread: end')
result:
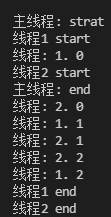
Here, the t1 thread is set as the guard thread. According to the principle, after the main thread end s, the t1 thread should no longer execute, but in fact: since there are two threads under the main thread, the main thread does not really die out although the main thread has finished executing. The main thread terminates after waiting for the t2 thread to finish executing and terminating the operation of t1 (guard thread)
What if we set both threads as guard threads, the result will be as we want?
from threading import Thread
from time import sleep
class MyThread(Thread):
def __init__(self,name):
Thread.__init__(self)
self.name = name
# Method override, the run function name cannot be changed
def run(self):
print(f'thread {self.name} start')
for i in range(3):
print(f'thread : {self.name}. {i}')
sleep(1)
print(f'thread {self.name} end')
if __name__ == '__main__':
print("Main thread: strat")
# Create thread
t1 = MyThread('1')
t2 = MyThread('2')
# Set daemon thread
t1.daemon = True # When the main thread dies, the t1 thread also dies
t2.daemon = True # The main thread dies, and the t2 thread dies
# Start thread
t1.start()
t2.start()
print('Main thread: end')
The result is as we wish

GIL global lock
The execution of Python code is controlled by the python virtual machine (also known as the interpreter main loop, CPython version). At the beginning of Python design, it is considered that only one thread is executing in the interpreter main loop, that is, at any time, only one thread is running in the interpreter. Access to the python virtual machine is controlled by the global interpreter lock (GIL), which ensures that only one thread is running at the same time.
When dealing with multithreading, multiple threads access the same object, and some threads also want to modify the object. At this time, we need to use "thread synchronization". Thread synchronization is actually a waiting mechanism. Multiple threads that need to access this object at the same time enter the waiting pool of this object to form a queue. After the previous thread is used, the next thread can be used again.
Thread synchronization and mutexes are not used
Simulation scenario: Lao Wang and his wife go to the ATM machine to withdraw money at the same time (at different locations). There is only 100 yuan in the account, and both want to withdraw 80 yuan. What happens if the thread is not synchronized? Write a simulation program to see
from threading import Thread
from time import sleep
class Account:
def __init__(self, money, name):
self.money = money
self.name = name
# Simulated withdrawal action
class Drawing(Thread):
def __init__(self,drawingNum,account):
Thread.__init__(self)
self.drawingNum = drawingNum
self.account = account
self.expenseTotal = 0
def run(self):
# If you want to fart
if self.account.money < self.drawingNum:
return
sleep(1) # If it is judged that ten thousand people can withdraw money, it will be blocked, which is to test the conflict problem
self.account.money -= self.drawingNum
self.expenseTotal += self.drawingNum
print(f'account:{self.account.name}, The balance is:{self.account.money}')
print(f'account:{self.account.name}, A total of:{self.expenseTotal}')
if __name__ == '__main__':
a1 = Account(100,'Lao Wang')
draw1 = Drawing(80,a1) # Define a thread to withdraw money
draw2 = Drawing(80,a1) # Then define a thread to withdraw money
draw1.start()
draw2.start()
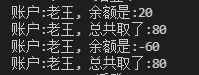
It can be found that the account balance has become negative, which is the result of the operation when thread synchronization is not used
Using thread synchronization
We can realize thread synchronization through "locking mechanism". The locking mechanism has the following key points:
- The same lock object must be used
- The function of mutex is to ensure that only one thread can operate the shared data at the same time, so as to ensure that there will be no error problems in the shared data
- The benefit of using mutexes is to ensure that a critical piece of code can only be executed completely by one thread from beginning to end
- Using mutex will affect the efficiency of code execution
- Holding multiple locks at the same time is prone to deadlock
mutex
- Lock the shared data to ensure that only one thread can operate at the same time.
- Note: a mutex lock is robbed by multiple threads. The thread that grabs the lock executes first. The thread that does not grab the lock needs to wait. After the mutex lock is used and released, other waiting threads will grab the lock.
The threading module defines the Lock variable, which is essentially a function. You can obtain a mutex by calling this function.
from threading import Thread, Lock
from time import sleep
class Account:
def __init__(self, money, name):
self.money = money
self.name = name
# Simulated withdrawal action
class Drawing(Thread):
def __init__(self,drawingNum,account):
Thread.__init__(self)
self.drawingNum = drawingNum
self.account = account
self.expenseTotal = 0
def run(self):
lock1.acquire() # Take the lock
# If you want to fart
if self.account.money < self.drawingNum:
print('Insufficient account balance')
return
sleep(1) # If it is judged that ten thousand people can withdraw money, it will be blocked, which is to test the conflict problem
self.account.money -= self.drawingNum
self.expenseTotal += self.drawingNum
lock1.release()
print(f'account:{self.account.name}, The balance is:{self.account.money}')
print(f'account:{self.account.name}, A total of:{self.expenseTotal}')
if __name__ == '__main__':
a1 = Account(100,'Lao Wang')
lock1 = Lock()
draw1 = Drawing(80,a1) # Define a thread to withdraw money
draw2 = Drawing(80,a1) # Then define a thread to withdraw money
draw1.start()
draw2.start()

Deadlock problem
In multithreaded programs, a large part of the deadlock problem is caused by a thread acquiring multiple locks at the same time.
For example: two people have to cook. They both need a "pot" and a "kitchen knife" to cook.
from threading import Thread, Lock
from time import sleep
def fun1():
lock1.acquire()
print('fun1 Get the kitchen knife')
sleep(2)
lock2.acquire()
print('fun1 Get the pot')
lock2.release()
print('fun1 Release pot')
lock1.release()
print('fun1 Release the kitchen knife')
def fun2():
lock2.acquire()
print('fun2 Get the pot')
lock1.acquire()
print('fun2 Get the kitchen knife')
lock1.release()
print('fun2 Release the kitchen knife')
lock2.release()
print('fun2 Release pot')
if __name__ == '__main__':
lock1 = Lock()
lock2 = Lock()
t1 = Thread(target=fun1)
t2 = Thread(target=fun2)
t1.start()
t2.start()
Deadlock is caused by "synchronization block needs to hold multiple locks at the same time". To solve this problem, the idea is very simple: the same code block should not hold two object locks at the same time.
Thread semaphore
After the mutex is used, only one thread can access a resource at the same time. If we want N (specified value) threads to access a resource at the same time? At this time, semaphores can be used. Semaphores control the number of resources accessed simultaneously. Semaphores are similar to locks. Locks allow only one object (process) to pass at the same time, and semaphores allow multiple objects (processes) to pass at the same time.
Application scenario
- When reading and writing files, generally only one thread can write, while multiple threads can read files at the same time. If it is necessary to limit the number of threads reading files at the same time, semaphores can be used at this time (if mutex is used, it is to limit that only one thread can read files at the same time).
- When crawling for data.
# One room, only two people are allowed to enter
from threading import Semaphore,Thread
from time import sleep
def home(name,se):
se.acquire()
print(f'{name}get into the room')
sleep(2)
print(f'***{name}Get out of the room')
se.release()
if __name__ == '__main__':
se = Semaphore(2) # Semaphore object
for i in range(7):
t = Thread(target = home,args=(f'tom {i}', se))
t.start()
Event object
Principle: the event object contains a signal flag that can be set by the thread, which allows the thread to wait for some events to occur. In the initial case, the signal flag in the event object is set to false. If a thread waits for an event object and the flag of the event object is false, the thread will be blocked until the flag is true. If a thread sets the signal flag of an event object to true, it will wake up all threads waiting for an event object. If a thread waits for an event object that has been set to true, it will ignore the event and continue to execute
Event() can create an event management flag, which is False by default. There are four main methods of event object that can be called:
| Method name | explain |
|---|---|
| event.wait(timeout=None) | The thread calling this method will be blocked. If the timeout parameter is set, the thread will stop blocking and continue to execute after timeout; |
| event.set() | Set the flag of event to True, and all threads calling the wait method will be awakened |
| event.clear() | Set the flag of event to False, and all threads calling the wait method will be blocked |
| event.is_set() | Judge whether the flag of event is True |
Let's simulate the following picture with a program:

import threading
import time
def chihuoguo(name):
print(f'{name}Already started')
print(f'buddy{name}Has entered the dining state')
time.sleep(1)
event.wait()
print(f'{name}Got the notice')
print(f'buddy{name}Start eating!')
if __name__ == '__main__':
event = threading.Event()
thread1 = threading.Thread(target=chihuoguo,agrs=('tom',))
thread2 = threading.Thread(target=chihuoguo,agrs=('cherry',))
# Open thread
thread1.start()
thread2.start()
# Wait for the event object to unravel
for i in range(10):
time.sleep(1)
print(">"*(i+1) + '-' * (9-i))
print('--->>> The main thread informs the child to eat')
event.set()

Producer / consumer model
In multithreaded environment, we often need the concurrency and cooperation of multiple threads. At this time, we need to understand an important multi-threaded concurrent cooperation model "producer / consumer model".
- Producer: producer refers to the module responsible for production data (here, the module may be: method, object, thread and process)
- Consumer: consumer refers to the module responsible for processing data (here, the module may be: method, object, thread, process)
- Buffer: consumers cannot directly use the producer's data. There is a "buffer" between them. The producer puts the produced data into the "buffer", and the consumer takes the data to be processed from the "buffer".
Buffer is the core of concurrency. The setting of buffer has three advantages
- Realize the concurrent cooperation of threads
- Decoupling producers and consumers (but through middleware...)
- Solve the imbalance between busy and idle time and improve efficiency
Buffer and queue objects
Perhaps the safest way to send data from one thread to another is to use the Queue in the Queue library. Create a Queue object shared by multiple threads that add or remove elements to the Queue by using put() and get() operations. The Queue object already contains the necessary locks, so you can use it to share data safely among multiple threads.
from queue import Queue
from time import sleep
import random
from threading import Thread
def producer():
num = 1
while True:
if queue.qsize() < 5:
print(f'production{num}number,Big steamed bread')
queue.put(f"Big steamed bread:{num}number")
num += 1
sleep(random.randint(1,4))
else:
print('The steamed bread basket is slow,Waiting for someone to pick it up')
sleep(1)
def consumer():
while True:
if queue.qsize() > 0:
print(f'Get steamed bread:{queue.get()}')
sleep(random.randint(1,5))
else:
print('Come on, I'm starving...')
sleep(1)
if __name__ == '__main__':
queue = Queue()
t1 = Thread(target=producer)
t2 = Thread(target=consumer)
t1.start()
t2.start()
process
Process benefits:
- The multi-core computer can be used for parallel execution of tasks to improve the execution efficiency
- The operation is not affected by other processes and is easy to create
- Space independence, data security
How the process is created (method mode)
- 1. Packaging method
- 2. Class packaging
After creating the process, start the process with start()
from multiprocessing import Process
import os
from time import sleep
def fun(name):
print(f'Current process ID:{os.getpid()}')
print(f'Parent process ID:{os.getppid()}')
print(f'Process: {name}, start')
sleep(3)
print(f'Process:{name} end')
# Class method creation
class MyProcess(Process):
def __init__(self,name):
Process.__init__(self)
self.name = name
def run(self):
print(f'Current process ID:{os.getpid()}')
print(f'Parent process ID:{os.getppid()}')
print(f'Process: {self.name}, start')
sleep(3)
print(f'Process:{self.name} end')
# For the bug of multi process implementation on windows, if the restriction of main is not added, the process will be created infinitely recursively,
if __name__ == '__main__':
print("Current process ID:",os.getpid())
p1 = Process(target=fun,args=('p1',))
p2 = Process(target=fun,args=('p2',))
p1.start()
p2.start()
# p1 = MyProcess('p1')
# p2 = MyProcess('p2')
# p1.start()
# p2.start()
Interprocess communication
It is worth noting that: interprocess communication should transfer data to each process. Although on the surface, this data is a global variable, when each process runs, it is independent of each other and does not share data
from multiprocessing import Process,Queue
from time import sleep
class MyProcess(Process):
def __init__(self,name,mq):
Process.__init__(self)
self.name = name
self.mq = mq
def run(self):
print(f'Process: {self.name}, start')
temp = self.mq.get()
print(f'get Date:{temp}')
sleep(2)
print(f'put Data:{temp}' + '1')
self.mq.put(temp+'1')
print(f'Process:{self.name} end')
if __name__ == '__main__':
mq = Queue()
mq.put('1')
mq.put('2')
mq.put('3')
# Process list
p_list = []
for i in range(3):
p1 = MyProcess(f'p{i}',mq)
p_list.append(p1)
p1.start()
p1.join() # Keep the main process waiting
for i in range(3):
print(mq.get())
Pipe realizes inter process communication
The Pipe method returns (conn1, conn2) representing the two ends of a Pipe.
- The Pipe method has a duplex parameter. If the duplex parameter is True (the default), this parameter is in full duplex mode, that is, conn1 and conn2 can send and receive.
- If duplex is False, conn1 is only responsible for receiving messages and conn2 is only responsible for sending messages. The send and recv methods are the methods of sending and receiving messages, respectively.
- For example, in full duplex mode, you can call conn1 Send send message, conn1 Recv receives the message. If there is no message to receive, the recv method will always block. If the pipeline has been closed, the recv method will throw eomirror.
import multiprocessing
from time import sleep
def func1(conn1):
sub_info = "Hello!"
print(f'Process 1--{multiprocessing.current_process().pid}send data: {sub_info}')
sleep(1)
conn1.send(sub_info)
print(f'From process 2:{conn1.recv()}')
sleep(1)
def func2(conn2):
sub_info = "Hello!"
print(f'Process 2--{multiprocessing.current_process().pid}send data: {sub_info}')
sleep(1)
conn2.send(sub_info)
print(f'From process 1:{conn2.recv()}')
sleep(1)
if __name__ == '__main__':
conn1,conn2 = multiprocessing.Pipe()
process1 = multiprocessing.Process(target=func1, args=(conn1,))
process2 = multiprocessing.Process(target=func2, args=(conn2,))
# Promoter process
process1.start()
process2.start()
Manage implements interprocess communication
from multiprocessing import Process,Manager
def func(name,m_list,m_dict):
m_dict['age'] = 19
m_list.append('I'm a handsome man!!')
if __name__ == '__main__':
# Manager and multiprocessing Queue has the same communication mode as global variables
# Although only one process is written here, it is the same to write two processes. You can communicate
with Manager() as mgr:
m_list = mgr.list()
m_dict = mgr.dict()
m_list.append('I am PD!!!')
p1 = Process(target=func, args=('p1',m_list,m_dict))
p1.start()
p1.join()
print(m_dict)
print(m_dict)
Process POOL
The process pool can provide users with a specified number of processes, that is, when a new request is submitted to the process pool, if the pool is not full, a new process will be created to execute the request; Conversely, if the number of processes in the pool has reached the specified maximum, the request will wait. As long as there are processes in the pool idle, the request can be executed.
Advantages of using process pool
- Improve efficiency, save the time of developing process, developing memory space and destroying process
- Save memory space
| Class / method | function | parameter |
|---|---|---|
| Pool(processes) | Create process pool object | Processes indicates how many processes are in the process pool |
| pool.apply_async(func,args,kwds) | Asynchronous execution; Put events into the process pool queue | Func event function args passes parameters to func in tuple form and kwds returns parameters to func in dictionary form: returns an object representing process pool events. The return value of the event function can be obtained through the get method of the return value |
| pool.apply(func,args,kwds) | Synchronous execution; Put events into the process pool queue | Func event function args passes parameters to func in tuple form and kwds passes parameters to func in dictionary form |
| pool.close() | Close process pool | |
| pool.join() | Recycle process pool | |
| pool.map(func,iter) | Similar to python's map function, put the events to be done into the process pool | func function to execute iter iteration object |
from multiprocessing import Pool
import os
from time import sleep
def func(name):
print(f'Current process ID:{os.getpid()},{name}')
sleep(2)
return name
def func2(args):
print(f'callback:{args}')
if __name__ == '__main__':
pool = Pool(5)
pool.apply_async(func=func,args=('pd',),callback=func2)
pool.apply_async(func=func,args=('pdd',),callback=func2)
pool.apply_async(func=func,args=('cpdd',),callback=func2)
pool.apply_async(func=func,args=('Hello pd',))
pool.apply_async(func=func,args=('Hello pdd',))
pool.apply_async(func=func,args=('Hello cpdd',))
pool.apply_async(func=func,args=('bye pd',))
pool.apply_async(func=func,args=('bye pdd',))
pool.apply_async(func=func,args=('bye cpdd',))
pool.close() # If you use with, you don't need to close it
pool.join()
Functional programming:
from multiprocessing import Pool
import os
from time import sleep
def func1(name):
print(f'Of the current process ID: {os.getpid()},{name}')
sleep(2)
return name
if __name__ == '__main__':
with Pool(5) as pool:
args = pool.map(func1,('pd','pdd','cpdd','Hello pd','Hello pdd',
'Hello cpdd','bye pd','bye pdd','bye cpdd'))
for a in args:
print(a)
Collaborative process (key)
The full name of collaborative process is "collaborative program", which is used to realize task collaboration. It is a more lightweight existence in threads than threads, which is managed by programmers who write their own programs.
When IO blocking occurs, the CPU waits for IO to return and is in idle state. At this time, other tasks can be performed by using the collaborative process. When the IO returns the result, it returns to process the data. Make full use of the waiting time of IO and improve the efficiency.
Core of collaborative process (surrender and recovery of control flow)
- Each collaborative process has its own execution stack, which can save its own execution site
- The user program can create the cooperation process as needed (for example, when encountering io operation)
- When a coroutine "yield s" the execution right, it will save the execution site (save the register context and stack at the time of interruption), and then switch to other coroutines
- When the collaboration resumes execution, it will resume to the state before interruption according to the previously saved execution site and continue to execute. In this way, a lightweight multi task model scheduled by user state is realized through the collaboration
Advantages of collaborative process
- Due to its own context and stack, there is no overhead of thread context switching. It belongs to program level switching, which is completely invisible to the operating system, so it is more lightweight;
- No locking and synchronization overhead of atomic operation;
- It is convenient to switch the control flow and simplify the programming model
- The effect of concurrency can be achieved in a single thread, making maximum use of CPU, with high scalability and low cost (Note: it is not a problem for a CPU to support tens of thousands of concurrency processes, so it is very suitable for high concurrency processing)
Note: asyncio collaboration is a better way to write crawlers. Better than multithreading and multiprocessing Opening up new threads and processes is very time-consuming.
Disadvantages of collaborative process
- Unable to use multi-core resources: the essence of a collaborative process is a single thread. It cannot use multiple cores of a single CPU at the same time. The collaborative process needs to cooperate with the process to run on multiple CPUs.
asyncio implementation process
- Normal functions will not be interrupted during execution, so you need to add async if you want to write a function that can be interrupted
- async is used to declare a function as an asynchronous function. The characteristic of asynchronous function is that it can suspend during the execution of the function to execute other asynchronous functions. When the suspension condition (assuming that the suspension condition is sleep(5)) disappears, that is, it will come back for execution after 5 seconds
- await is used to declare that a program is suspended. For example, if an asynchronous program needs to wait a long time to execute a certain step, it will suspend it to execute other asynchronous programs.
- asyncio is python 3 5 is an important package for python to realize concurrency. This package uses event loop to drive concurrency.
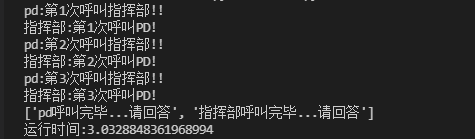
import time
import asyncio
async def func1():
for i in range(1,4):
print(f'pd:The first{i}Call headquarters!!')
await asyncio.sleep(1)
return 'pd Call over...Please answer the questions'
async def func2():
for k in range(1,4):
print(f'headquarters:The first{k}Second call PD!')
await asyncio.sleep(1)
return 'Headquarters call over...Please answer the questions'
async def main():
res = await asyncio.gather(func1(), func2())
# await asynchronously executes func1 method
# gather alternates between func1() and func2()
# The return value is the list of return values of the function
print(res)
if __name__ == '__main__':
start = time.time()
asyncio.run(main())
end = time.time()
print(f'Running time:{end-start}')
Come back and execute
- await is used to declare that the program is suspended. For example, if the asynchronous program needs to wait for a long time to execute a certain step, suspend it to execute other asynchronous programs.
- asyncio is python 3 5 is an important package for python to realize concurrency. This package uses event loop to drive concurrency.
import time
import asyncio
async def func1():
for i in range(1,4):
print(f'pd:The first{i}Call headquarters!!')
await asyncio.sleep(1)
return 'pd Call over...Please answer the questions'
async def func2():
for k in range(1,4):
print(f'headquarters:The first{k}Second call PD!')
await asyncio.sleep(1)
return 'Headquarters call over...Please answer the questions'
async def main():
res = await asyncio.gather(func1(), func2())
# await asynchronously executes func1 method
# gather alternates between func1() and func2()
# The return value is the list of return values of the function
print(res)
if __name__ == '__main__':
start = time.time()
asyncio.run(main())
end = time.time()
print(f'Running time:{end-start}')