A primer
The theme of this section is based on single threading, which implements concurrency with only one main thread (apparently only one cpu available), so let's first review the nature of concurrency: toggle + save state
The cpu is running a task that will be cut off to perform other tasks (switching is mandatory by the operating system) either because the task is blocked or if it takes too long to compute or if a higher priority program replaces it
Collaboration is essentially a thread. In the past, the switching of threaded tasks was controlled by the operating system, and I/O switching was encountered automatically. Now we use it to reduce the overhead of operating system switching (switching threads, creating registers, stacks, etc., switching between them), in our own processThe sequence controls the switching of tasks.
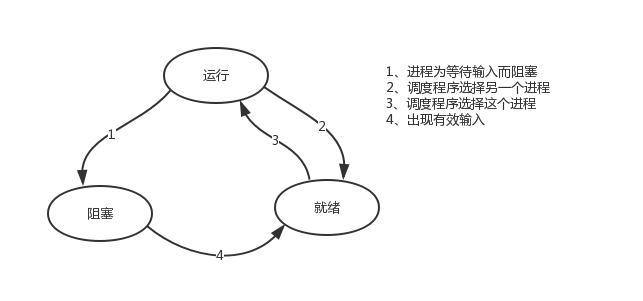
ps: When introducing process theory, mention the three execution states of a process and the thread is the execution unit, so you can also interpret the above figure as three states of a thread
1: The second scenario does not improve efficiency, just to allow the cpu to rain and rain and achieve the effect that all tasks appear to be executed "at the same time". If multiple tasks are purely computational, this switch reduces efficiency.We can verify this based on yield.Yield itself is a single-threaded way to save the running state of a task. Let's review it briefly:
#1 yiled can save state, which is similar to the thread state saved by the operating system, but yield ing is code-level controlled and lighter #2 send can switch between programs within a single thread by passing the result of one function to another
import time
def func1():
for i in range(11):
#yield
print('This is my first%s Printed again' % i)
time.sleep(1)
def func2():
g = func1()
#next(g)
for k in range(10):
print('Ha-ha, my first%s Printed the second time' % k)
time.sleep(1)
#next(g)
#Without writing yield, the next two tasks are to execute all the programs in func1 before executing the programs in func2. With yield, we have switched the two tasks + saved state
func1()
func2()
//Task Switch + Save Site via yieldTask Switch + Save Site via yield
# Computing intensive: efficiency comparison between serial and protocol
import time
def task1():
res = 1
for i in range(1,100000):
res += i
def task2():
res = 1
for i in range(1,100000):
res -= i
start_time = time.time()
task1()
task2()
print(time.time()-start_time)
import time
def task1():
res = 1
for i in range(1, 100000):
res += i
yield res
def task2():
g = task1()
res = 1
for i in range(1, 100000):
res -= i
next(g)
start_time = time.time()
task2()
print(time.time() - start_time)Comparison of IO-intensive Serial and Protocol
2. Switch in the first case.When a task encounters io, it is cut to task 2 to execute, so that the calculation of task 2 can be completed with the blocked time of task 1. This is why the efficiency is improved.
import time
def func1():
while True:
print('func1')
yield
def func2():
g=func1()
for i in range(10000000):
i+1
next(g)
time.sleep(3)
print('func2')
start=time.time()
func2()
stop=time.time()
print(stop-start)
yield Undetectable IO,Implementation encounters IO Automatic Switchingyield can not detect IO, to achieve automatic IO switching encountered
A concurrent program tells the Cpython interpreter that you are not nb or have a GIL lock. Okay, I will make a thread for you to execute, saving you the time to switch threads. I will switch faster than you do, avoiding a lot of overhead. For a single thread, we can't avoid the program going out.The IO operation is present, but if we can control multiple tasks under a single thread in our own program (i.e., at the user program level, not at the operating system level), we can switch to another task to compute when one task encounters an IO blockage, which ensures that the thread is as ready as possible, that is, at any timeThe state of being executed by the cpu is equivalent to hiding our IO operations as much as possible at the user program level to confuse the operating system and let it see that the thread seems to be computing all the time with less io, thus more cpu execution rights are assigned to our threads.
The essence of a collaboration is that in a single thread, the user controls one task to switch to another task to execute when io is blocked, thereby increasing efficiency.To achieve this, we need to find a solution that meets both the following conditions:
#1. You can control the switching between multiple tasks by saving the state of the task before switching so that when it is run again, execution can continue based on where it is paused. #2.As a supplement to 1, you can detect io operations and switch only when io operations are encountered
Introduction to the Second Program
Coprocess: Concurrency under a single thread, also known as micro-threading, fiber.The English name is Coroutine.A sentence tells you what a thread is: A collaboration is a user-friendly lightweight thread, that is, a collaboration is dispatched under the control of the user program itself.,
* It should be emphasized that:
#1. python threads are at the kernel level and are dispatched under the control of the operating system (for example, if a single thread encounters io or if it takes too long to execute, it will be forced to surrender cpu execution privileges and switch other threads to run) #2. Open a protocol within a single thread, once you encounter io, you control the switch from the application level (not the operating system) to increase efficiency (!!!Efficiency-independent switching of non-io operations)
Contrast switching of operating system control threads, users control switching of protocols within a single thread
The advantages are as follows:
#1. The protocol has less switching overhead, belongs to program-level switching, is completely unaware by the operating system, and is therefore lighter #2. Concurrency can be achieved within a single thread, maximizing cpu utilization
The shortcomings are as follows:
#1. The essence of a coprocess is that it can't take advantage of multiple cores under a single thread. It can be a program that opens multiple processes, multiple threads per process, and a coprocess within each thread. #2. A collaboration refers to a single thread, so if the collaboration is blocked, the entire thread will be blocked
Summarize the characteristics of the program:
- Concurrency must be achieved in a single thread
- Modifying shared data without locking
- Save multiple control flow context stacks in the user program
- Additional: One protocol automatically switches to another protocol when it encounters IO operations (how to achieve detection IO, yield, greenlet cannot do it, gevent module (select mechanism) is used)
Three Greenlet s
If we have 20 tasks in a single thread, the way to switch between multiple tasks is too cumbersome using the yield Generator (we need to get the generator initialized once before calling send.)Very cumbersome), but using the greenlet module can easily switch these 20 tasks directly
#install pip3 install greenlet
#The real coprocess module is the switch done with greenlet
from greenlet import greenlet
def eat(name):
print('%s eat 1' %name) #2
g2.switch('taibai') #3
print('%s eat 2' %name) #6
g2.switch() #7
def play(name):
print('%s play 1' %name) #4
g1.switch() #5
print('%s play 2' %name) #8
g1=greenlet(eat)
g2=greenlet(play)
g1.switch('taibai')#You can pass in a parameter the first time you switch, and you don't need a 1 laterSimple switching (without io or repeated open memory operations) can slow down program execution
#Sequential execution
import time
def f1():
res=1
for i in range(100000000):
res+=i
def f2():
res=1
for i in range(100000000):
res*=i
start=time.time()
f1()
f2()
stop=time.time()
print('run time is %s' %(stop-start)) #10.985628366470337
#switch
from greenlet import greenlet
import time
def f1():
res=1
for i in range(100000000):
res+=i
g2.switch()
def f2():
res=1
for i in range(100000000):
res*=i
g1.switch()
start=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
stop=time.time()
print('run time is %s' %(stop-start)) # 52.763017892837524
//Efficiency comparisonEfficiency comparison
greenlet simply provides a more convenient way to switch than generator. If IO is encountered when a task is cut to execution, it will be blocked in place and will still not solve the problem of IO auto-switch to improve efficiency.

The above figure is the true meaning of the collaboration. Although we do not avoid the inherent I/O time, we use this time to do other things. Generally, in our work, we are process+thread+collaboration to achieve concurrency in order to achieve the best concurrency effect. If we have a 4-core cpu, we usually start five processes.Twenty threads per process (five times the number of CPUs), each of which can start 500 protocols, can be used to achieve concurrency when crawling pages on a large scale and waiting for network latency.The number of concurrencies = 5 * 20 * 500 = 50,000 concurrencies, which is the largest number of concurrencies for a general 4 CPU machine.nginx has a maximum load of 5w at load balancing
The code for these 20 tasks in a single thread usually has both computational and blocking operations, so we can use the blocked time to execute Task 2 when we encounter a blocking operation on Task 1.That way, you can be more efficient, which uses the Gevent module.
Introduction to Four Gevent s
#install pip3 install gevent
Gevent is a third-party library that allows easy concurrent synchronous or asynchronous programming via gevent. The main mode used in gevent is Greenlet, which is a lightweight protocol that connects to Python as a C extension.Greenlet runs entirely inside the main program operating system processes, but they are dispatched collaboratively.
#usage g1=gevent.spawn(func,1,2,3,x=4,y=5)Create a collaboration object g1,spawn The first parameter in parentheses is the function name, such as eat,There can be multiple parameters, either positional or keyword arguments, that are passed to the function eat Of, spawn Is Asynchronous Submit Task g2=gevent.spawn(func2) g1.join() #Waiting for g1 to end g2.join() #When waiting for g2 to finish someone's test, you will find that you can execute g2 without writing a second join. Yes, the collaboration helps you switch execution, but you will find that if the tasks in g2 take a long time to execute, but you don't write a join, you won't finish the tasks left until g2 #Or two steps above: gevent.joinall([g1,g2]) g1.value#Get the return value of func1
Automatically switch tasks when IO congestion occurs
import gevent
def eat(name):
print('%s eat 1' %name)
gevent.sleep(2)
print('%s eat 2' %name)
def play(name):
print('%s play 1' %name)
gevent.sleep(1)
print('%s play 2' %name)
g1=gevent.spawn(eat,'egon')
g2=gevent.spawn(play,name='egon')
g1.join()
g2.join()
#Or gevent.joinall([g1,g2])
print('main')
//I/O switch encounteredI/O switch encountered
The example gevent.sleep(2) above simulates an io blocking that gevent can recognize.
For time.sleep(2) or other blockages, gevent is not directly identifiable and needs to be patched with the following line of code
from gevent import monkey;monkey.patch_all() must be placed before the patched person, such as time, before the socket module
Or let's just remember that to use gevent, you need to put from gevent import monkey;monkey.patch_all() at the beginning of the file
from gevent import monkey;monkey.patch_all() #Must be written at the top, all the blockages after this sentence are recognizable
import gevent #Import directly
import time
def eat(): #print()
print('eat food 1')
time.sleep(2) #The sleep of the time module can be recognized by adding a mokey
print('eat food 2')
def play():
print('play 1')
time.sleep(1) #Toggle back and forth until the end of an I/O time, which is what we gevent did, is no longer an uncontrollable operating system.
print('play 2')
g1=gevent.spawn(eat)
g2=gevent.spawn(play_phone)
gevent.joinall([g1,g2])
print('main')You can use threading.current_thread().getName() to look at each g1 and g2, and the result is DummyThread-n, which is a pseudo thread, a virtual thread, which is actually inside a thread
Task switching for process threads is switched by the operating system itself and is beyond your control
The protocol is switched by its own program (code), which can be controlled by itself. The program will switch tasks and achieve concurrent effect only when it encounters IO operations recognized by the protocol module. If no program has IO operations, it is basically serial execution.
Synchronization and Asynchronization of Five Gevent s
from gevent import spawn,joinall,monkey;monkey.patch_all()
import time
def task(pid):
"""
Some non-deterministic task
"""
time.sleep(0.5)
print('Task %s done' % pid)
def synchronous():
for i in range(10):
task(i)
def asynchronous():
g_l=[spawn(task,i) for i in range(10)]
joinall(g_l)
if __name__ == '__main__':
print('Synchronous:')
synchronous()
print('Asynchronous:')
asynchronous()
#An important part of the above program is to encapsulate the task function into gevent.spawn of the Greenlet internal thread.The initialized list of greenlets is stored in the array threads, which is passed to the gevent.joinall function, which blocks the current process and executes all given greenlets.The execution process will only continue down after all the greenlets have been executed.
//Protocol: synchronous asynchronous comparisonProtocol: synchronous asynchronous comparison
Examples of Six Gevent s
from gevent import monkey;monkey.patch_all()
import gevent
import requests
import time
def get_page(url):
print('GET: %s' %url)
response=requests.get(url)
if response.status_code == 200:
print('%d bytes received from %s' %(len(response.text),url))
start_time=time.time()
gevent.joinall([
gevent.spawn(get_page,'https://www.python.org/'),
gevent.spawn(get_page,'https://www.yahoo.com/'),
gevent.spawn(get_page,'https://github.com/'),
])
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
//Collaborative applications: CrawlersCollaborative applications: Crawlers
Add a serial code at the end of the above program to see the efficiency: If your program doesn't need to be too efficient, there won't be any concurrent, collaborative, etc.
print('--------------------------------')
s = time.time()
requests.get('https://www.python.org/')
requests.get('https://www.yahoo.com/')
requests.get('https://github.com/')
t = time.time()
print('Serial Time>>',t-s)Seven Gevent Applications Example Two
Socket concurrency under single threads through gevent (from gevent import monkey;monkey.patch_all() must be placed before importing the socket module, otherwise gevent cannot recognize the blocking of the socket)
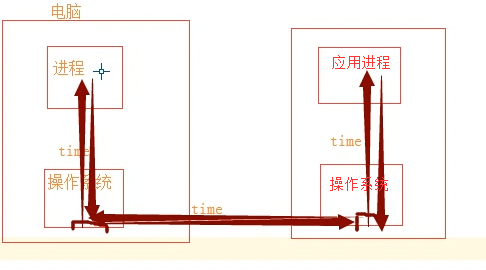
Multiple time delays in a network request
from gevent import monkey;monkey.patch_all()
from socket import *
import gevent
#If you don't want to patch money.patch_all(), you can use the socket that comes with gevent
# from gevent import socket
# s=socket.socket()
def server(server_ip,port):
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind((server_ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
gevent.spawn(talk,conn,addr)
def talk(conn,addr):
try:
while True:
res=conn.recv(1024)
print('client %s:%s msg: %s' %(addr[0],addr[1],res))
conn.send(res.upper())
except Exception as e:
print(e)
finally:
conn.close()
if __name__ == '__main__':
server('127.0.0.1',8080)
//Server
//ServerServer
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
msg=client.recv(1024)
//ClientClient
from threading import Thread
from socket import *
import threading
def client(server_ip,port):
c=socket(AF_INET,SOCK_STREAM) #The socket object must be added to the function, that is, in the local namespace, and out of the function, shared by all threads. If you share a socket object, the client port will always be the same
c.connect((server_ip,port))
count=0
while True:
c.send(('%s say hello %s' %(threading.current_thread().getName(),count)).encode('utf-8'))
msg=c.recv(1024)
print(msg.decode('utf-8'))
count+=1
if __name__ == '__main__':
for i in range(500):
t=Thread(target=client,args=('127.0.0.1',8080))
t.start()
//Multiple threads concurrently with multiple clients, it is OK to request the server aboveMultiple threads concurrently with multiple clients, it is OK to request the server above