1. Overview
As shown in the figure, thread safe collection classes can be divided into three categories
- Legacy thread safe collections such as Hashtable and Vector
- Thread safe Collections decorated with Collections, such as:
- Collections.synchronizedCollection
- Collections.synchronizedList
- Collections.synchronizedMap
- Collections.synchronizedSet
- Collections.synchronizedNavigableMap
- Collections.synchronizedNavigableSet
- Collections.synchronizedSortedMap
- Collections.synchronizedSortedSet
- **java.util.concurrent.*** You can find that they are regular, which contains three types of keywords: Blocking, CopyOnWrite and Concurrent
- Most implementations of Blocking are lock based and provide methods for Blocking
- Containers such as CopyOnWrite are relatively expensive to modify. They are modified by copying, which is suitable for reading more and writing less
- For Concurrent containers, many internal operations are optimized by CAS, which can generally provide high throughput, but it has the characteristics of weak consistency. For example, when iterators are used to traverse, if the container is modified, the iterators can still continue to traverse. At this time, the content is old. For example, the size operation may not be 100% accurate
- Compared with non secure containers, if changes occur during traversal, use the fail fast mechanism, that is, make the traversal fail immediately, throw the ConcurrentModificationException and stop traversal. For secure containers, use the fail save mechanism
Legacy thread safe collections are called legacy because they appear relatively early, and the way to ensure thread safety is to add the synchronized keyword to the method. The concurrency efficiency is too low
How do thread safe Collections decorated with Collections operate? Take Map as an example
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
//Stored in its own member variable
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map<? extends K, ? extends V> map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
private transient Set<K> keySet;
private transient Set<Map.Entry<K,V>> entrySet;
private transient Collection<V> values;
public Set<K> keySet() {
synchronized (mutex) {
if (keySet==null)
keySet = new SynchronizedSet<>(m.keySet(), mutex);
return keySet;
}
}
public Set<Map.Entry<K,V>> entrySet() {
synchronized (mutex) {
if (entrySet==null)
entrySet = new SynchronizedSet<>(m.entrySet(), mutex);
return entrySet;
}
}
public Collection<V> values() {
synchronized (mutex) {
if (values==null)
values = new SynchronizedCollection<>(m.values(), mutex);
return values;
}
}
public boolean equals(Object o) {
if (this == o)
return true;
synchronized (mutex) {return m.equals(o);}
}
public int hashCode() {
synchronized (mutex) {return m.hashCode();}
}
public String toString() {
synchronized (mutex) {return m.toString();}
}
// Override default methods in Map
@Override
public V getOrDefault(Object k, V defaultValue) {
synchronized (mutex) {return m.getOrDefault(k, defaultValue);}
}
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
synchronized (mutex) {m.forEach(action);}
}
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
synchronized (mutex) {m.replaceAll(function);}
}
@Override
public V putIfAbsent(K key, V value) {
synchronized (mutex) {return m.putIfAbsent(key, value);}
}
@Override
public boolean remove(Object key, Object value) {
synchronized (mutex) {return m.remove(key, value);}
}
@Override
public boolean replace(K key, V oldValue, V newValue) {
synchronized (mutex) {return m.replace(key, oldValue, newValue);}
}
@Override
public V replace(K key, V value) {
synchronized (mutex) {return m.replace(key, value);}
}
@Override
public V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
synchronized (mutex) {return m.computeIfAbsent(key, mappingFunction);}
}
@Override
public V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
synchronized (mutex) {return m.computeIfPresent(key, remappingFunction);}
}
@Override
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
synchronized (mutex) {return m.compute(key, remappingFunction);}
}
@Override
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
synchronized (mutex) {return m.merge(key, value, remappingFunction);}
}
private void writeObject(ObjectOutputStream s) throws IOException {
synchronized (mutex) {s.defaultWriteObject();}
}
}
- Presumably, there is not much difference from HashTable, which uses the synchronized keyword and calls the original Map. 🤕
2,ConcurrentHashMap
2.1. Simple application
Before explaining CHM, let's do a Demo to count words and prepare the test data first
static final String ALPHA = "abcedfghijklmnopqrstuvwxyz";
@SneakyThrows
public static void main(String[] args) {
int length = ALPHA.length();
int count = 200;
List<String> list = new ArrayList<>(length * count);
for (int i = 0; i < length; i++) {
char ch = ALPHA.charAt(i);
for (int j = 0; j < count; j++) {
list.add(String.valueOf(ch));
}
}
//Random disorder order
Collections.shuffle(list);
for (int i = 0; i < 26; i++) {
try (PrintWriter out = new PrintWriter(
new OutputStreamWriter(
new FileOutputStream("D:/temp/" + (i + 1) + ".txt")))) {
String collect = String.join("\n", list.subList(i * count, (i + 1) * count));
out.print(collect);
} catch (IOException e) {
e.printStackTrace();
}
}
}
Next, prepare the test code. The following code is used to read the content from the file set and simultaneously store the number of character occurrences in the Map set prepared by yourself
private static <V> void demo(Supplier<Map<String, V>> supplier,
BiConsumer<Map<String, V>, List<String>> consumer) {
Map<String, V> counterMap = supplier.get();
List<Thread> ts = new ArrayList<>();
for (int i = 1; i <= 26; i++) {
int idx = i;
Thread thread = new Thread(() -> {
List<String> words = readFromFile(idx);
consumer.accept(counterMap, words);
});
ts.add(thread);
}
ts.forEach(Thread::start);
//Wait for 26 threads to end
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(counterMap);
}
public static List<String> readFromFile(int i) {
ArrayList<String> words = new ArrayList<>();
try (BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream("D:/temp/"
+ i + ".txt")))) {
while (true) {
String word = in.readLine();
if (word == null) {
break;
}
words.add(word);
}
return words;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
First, use the ordinary HashMap to test
demo(
(Supplier<Map<String, Integer>>) HashMap::new,
(map, words) -> {
for (String word : words) {
Integer count = map.get(word);
map.put(word, count == null ? 1 : count + 1);
}
}
);

- It can be found that none of them is right, because 26 threads operate the same HashMap at the same time, resulting in thread safety problems. Let's try the thread safe class ConcurrentHashMap
demo(
(Supplier<Map<String, Integer>>) ConcurrentHashMap::new,
(map, words) -> {
for (String word : words) {
Integer count = map.get(word);
map.put(word, count == null ? 1 : count + 1);
}
}
);

- The discovery is still the wrong result. Why? In fact, for thread safe collection classes, they can only ensure the thread safety of a corresponding method, but for the collection of multiple methods, they can not ensure the thread safety. It can be understood that in the scenario of high concurrency, our program uses thread safe collection, which still can not guarantee the correctness of the program, but uses non thread safe collection, The correctness of the procedure cannot be guaranteed
In order to ensure the correctness of our program output, we can try to add synchronized when counting letters
private static final Object LOCK = new Object();
public static void main(String[] args) {
demo(
(Supplier<Map<String, Integer>>) ConcurrentHashMap::new,
(map, words) -> {
synchronized (LOCK) {
for (String word : words) {
Integer count = map.get(word);
map.put(word, count == null ? 1 : count + 1);
}
}
}
);
}

- However, when we often choose to use ConcurrentHashMap, we pay attention to its low lock granularity. If we write this way, we might as well directly use HashMap to lock, which is more efficient. If this problem is solved, in fact, the ConcurrentHashMap class encapsulates some methods that meet this function, computeIfAbsent. If the target key is missing, We can calculate and generate a value, and then put the key value into the map, but we still lack an accumulation operation. Its thread safety can be guaranteed by using LongAdder
demo(
(Supplier<Map<String, LongAdder>>) ConcurrentHashMap::new,
(map, words) -> {
synchronized (LOCK) {
for (String word : words) {
//If the key is missing, you can calculate and generate a value, and then put the key value into the map
LongAdder count = map.computeIfAbsent(word, (k) -> new LongAdder());
//Internal use of cas to ensure thread safety
count.increment();
}
}
}
);

2.2. JDK 7 HashMap concurrent dead chain
2.2.1 problems
If you use HashMap in a single thread, there is naturally no problem. If the logic introduces multi-threaded concurrent execution due to code optimization in the later stage, you will find that the CPU consumption is 100% at an unknown point in time. By looking at the stack, you will be surprised to find that the threads are stuck in the get() method of HashMap. After the service is restarted, the problem disappears, It may reappear after a while. Why?
2.2.2 reproduction
- The first step is to ensure that the current JDK environment is 7
System.getProperty("java.version");

- The second step is to add the following test code. Be careful not to change the logic easily
public static void main(String[] args) {
// Test which numbers in java 7 have the same hash result
System.out.println("When the length is 16, the barrel subscript is 1 key");
for (int i = 0; i < 64; i++) {
if (hash(i) % 16 == 1) {
System.out.println(i);
}
}
System.out.println("When the length is 32, the barrel subscript is 1 key");
for (int i = 0; i < 64; i++) {
if (hash(i) % 32 == 1) {
System.out.println(i);
}
}
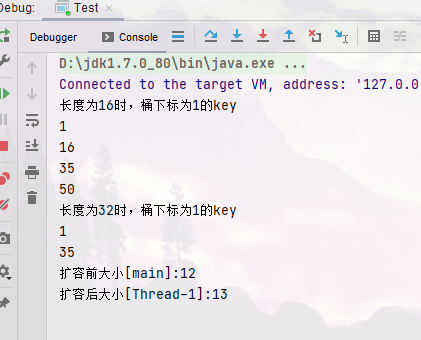
// 1, 35, 16, 50 when the size is 16, they are in a bucket
final HashMap<Integer, Integer> map = new HashMap<>();
// Put 12 elements
map.put(2, null);
map.put(3, null);
map.put(4, null);
map.put(5, null);
map.put(6, null);
map.put(7, null);
map.put(8, null);
map.put(9, null);
map.put(10, null);
map.put(16, null);
map.put(35, null);
map.put(1, null);
System.out.println("Size before capacity expansion[main]:" + map.size());
new Thread() {
@Override
public void run() {
// Put the 13th element and expand the capacity
map.put(50, null);
System.out.println("Size after capacity expansion[Thread-0]:" + map.size());
}
}.start();
new Thread() {
@Override
public void run() {
// Put the 13th element and expand the capacity
map.put(50, null);
System.out.println("Size after capacity expansion[Thread-1]:" + map.size());
}
}.start();
}
static int hash(Object k) {
int h = 0;
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
- The third step is to mark the breakpoint on line 590 of the HashMap source code. Note that the breakpoint type is set to Thread. Otherwise, after one Thread is disconnected, the other will be, and then add a breakpoint condition
newTable.length==32 &&
(
Thread.currentThread().getName().equals("Thread-0")||
Thread.currentThread().getName().equals("Thread-1")
)
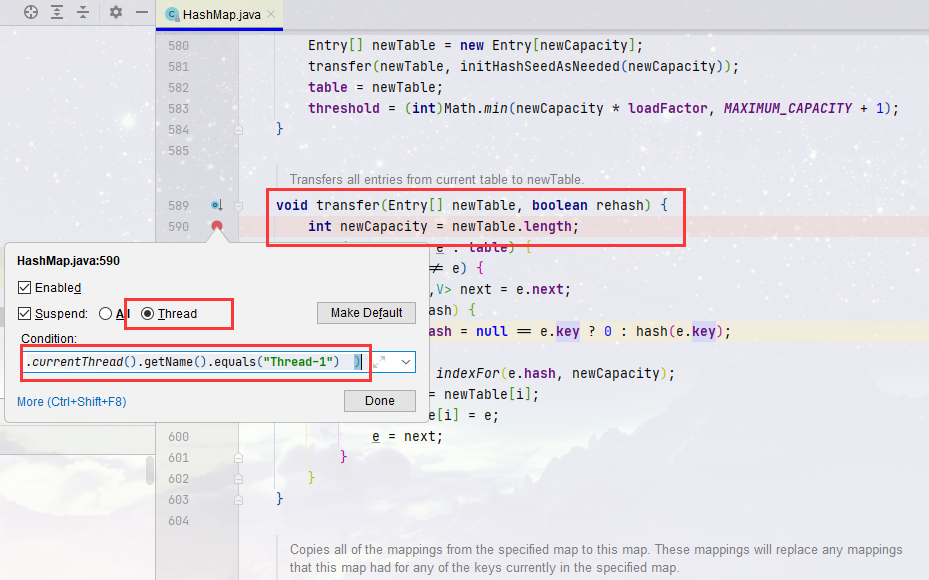
- When debugging, note that some attributes of IDEA are not visible in the non Object view during debugging. It is necessary to change the following view type to Object, and other invisible attributes can also be set in this way
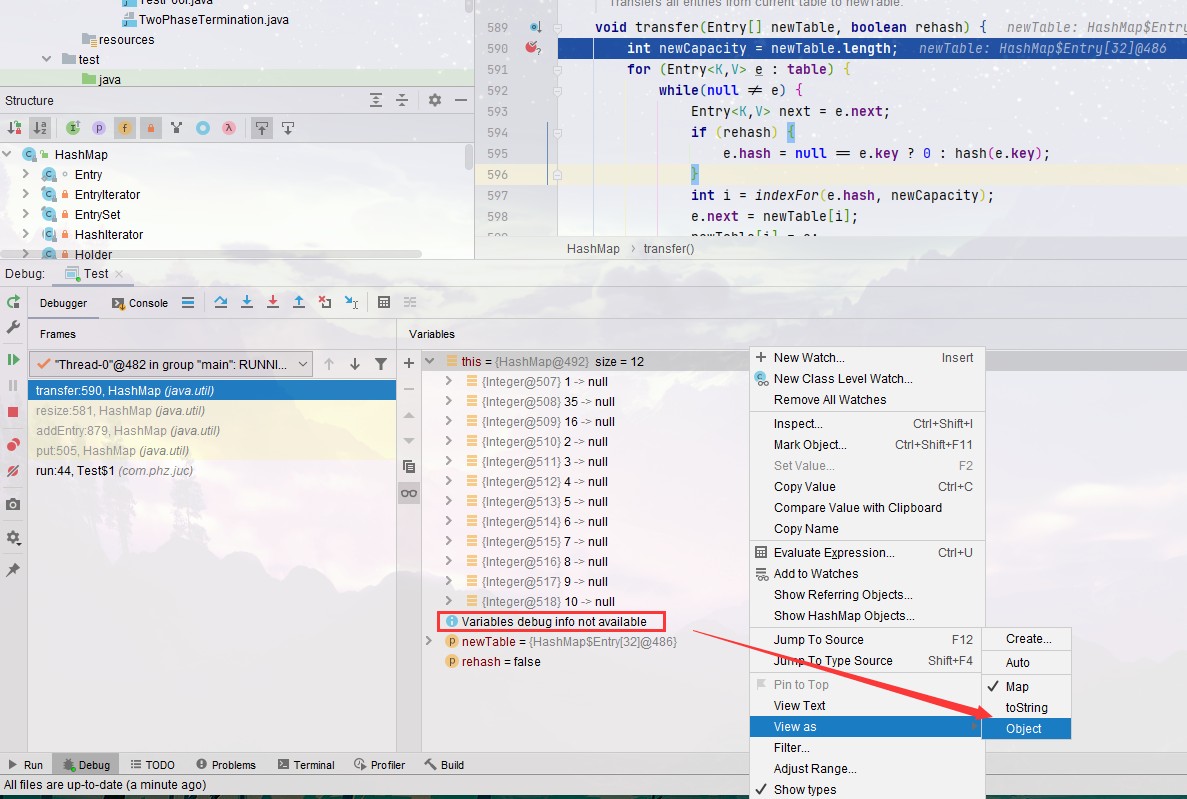
It can be seen that there are three nodes at the position of 1. When our program put s, the order is 16 - > 35 - > 1, which can be reflected here. In case of Hash conflict, the node pointing order is the reverse order of addition
- Step to line 594, and then add a breakpoint here. The purpose is to make Thread-1 stop here after running again. The following breakpoint conditions also need to be added
Thread.currentThread().getName().equals("Thread-0")
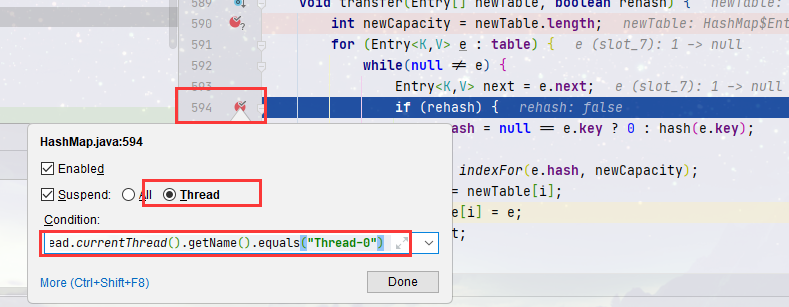
- Remember that e and next are 1 and 35 respectively, that is:
e:1 -> 35 -> 16 -> null next : 35 -> 16 -> null

- Select Threads-1 in the resume panel
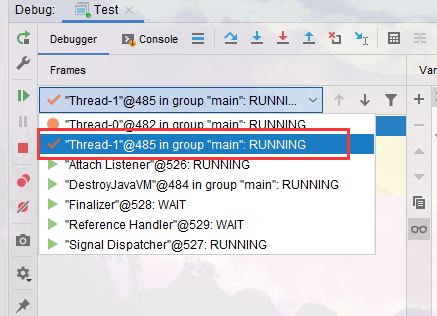
- Let it execute directly. You can see that the expansion is completed
- Now there's only Thread-0 left and it's stopped
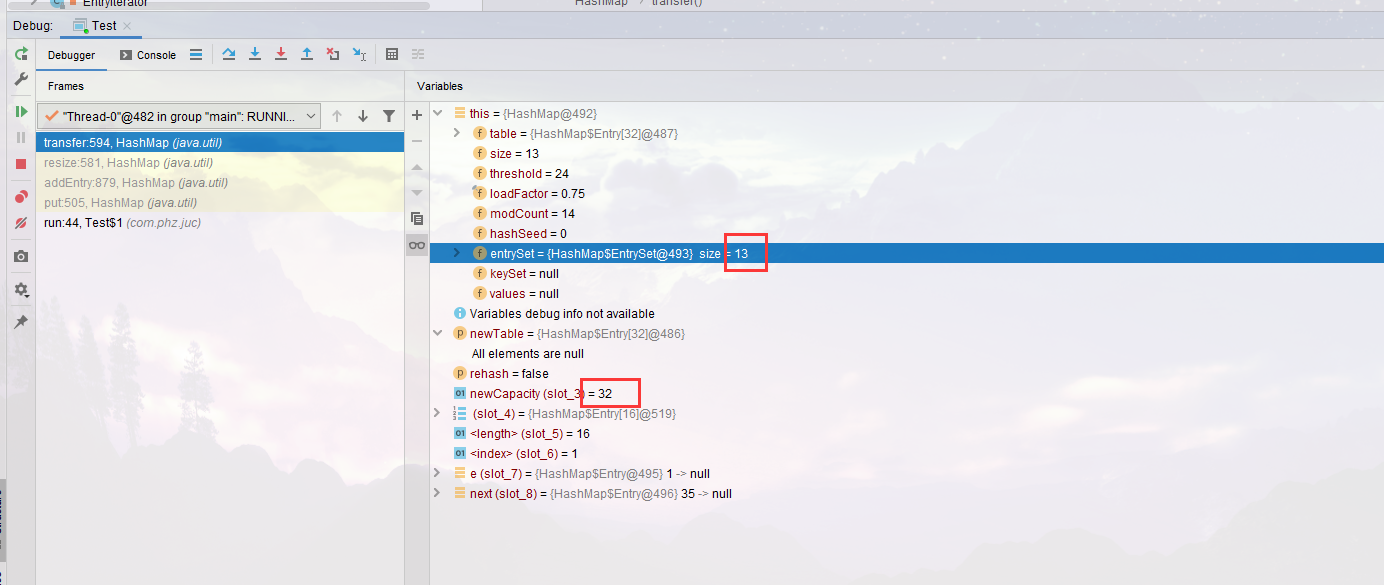
- Now let's take a look at the position of 1. When we rehash, the order of accessing the linked list is opposite to the order we re insert, so 1 - > 35 becomes 35 - > 1, and the original 16 is transferred to other places through rehash
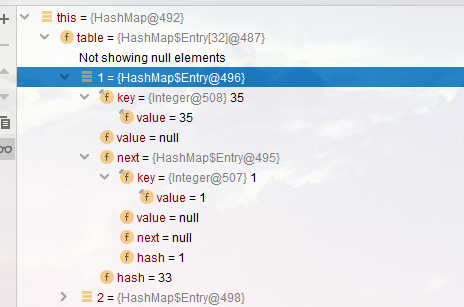
- OK, now let's focus on e and next again
e:1 -> 35 -> 16 -> null next : 35 -> 16 -> null
- Now it's
e : (1)->null next:(35)->(1)->null
- When Thread-1 is expanded, the linked list is also added later and put into the chain header. Therefore, the linked list is reversed. Although the result of Thread-1 is correct, Thread-0 will continue to run after it is finished. Now execute in one step and enter the next cycle. At this time, observe the newTable. It adds 1, and e = 35, next = 1
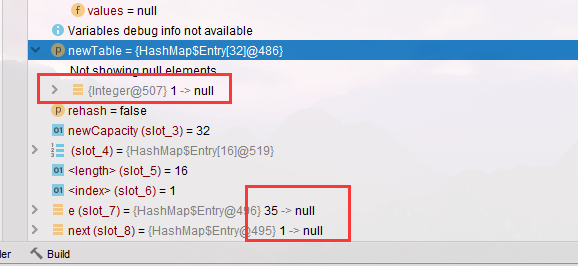
- Execute the cycle again, 35 - > 1
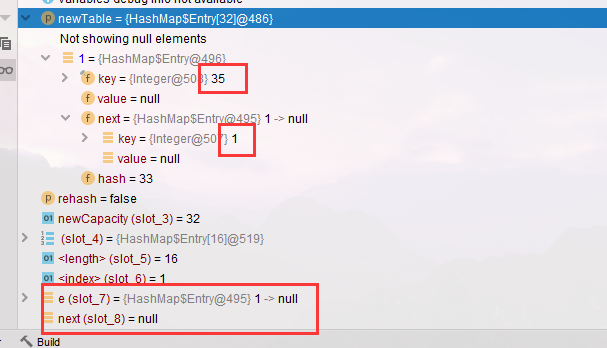
- Execute the loop again. At this time, e = 1 rejoins the head node, 1 - > 35, and there will be 1 - > 35 - > 1
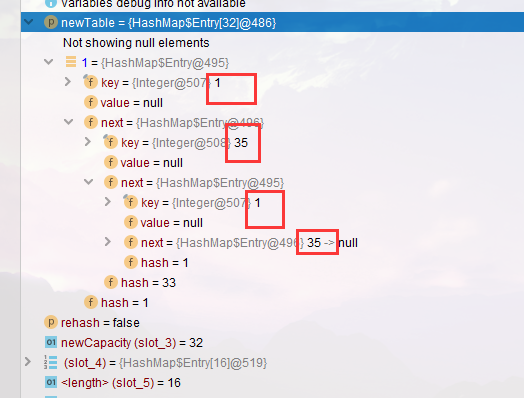
- Then it got stuck
2.2.3 overview of HashMap data structure
After understanding the context, let's review the data structure of HashMap.
-
Internally, HashMap uses an Entry array to save key and value data. When a pair of keys and values are added, the index of the array will be obtained through a hash algorithm. The algorithm is very simple. According to the hash value of the key, the size of the array is modeled hash & (length-1), and the result is inserted into the position of the array. If there are elements in the position, This indicates that there is a hash conflict, which will generate a linked list at the index position.
-
If there is a hash conflict, the worst case is that all elements are located in the same location to form a long linked list. In this way, when get ting a value, the worst case needs to traverse all nodes, and the performance becomes O(n). Therefore, the hash value algorithm of elements and the initial size of HashMap are very important.
-
When inserting a new node, if the same key does not exist, it will judge whether the current internal element has reached the threshold (0.75 of the array size by default). If the threshold has been reached, it will expand the array and rehash the elements in the linked list.
2.2.4 process analysis
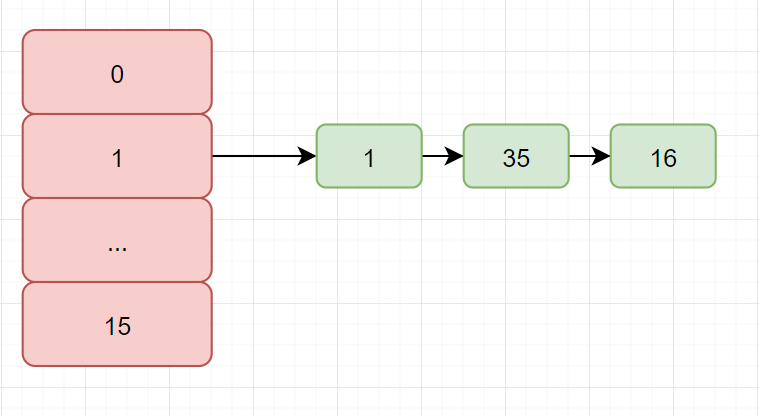
Original map (omit other nodes)
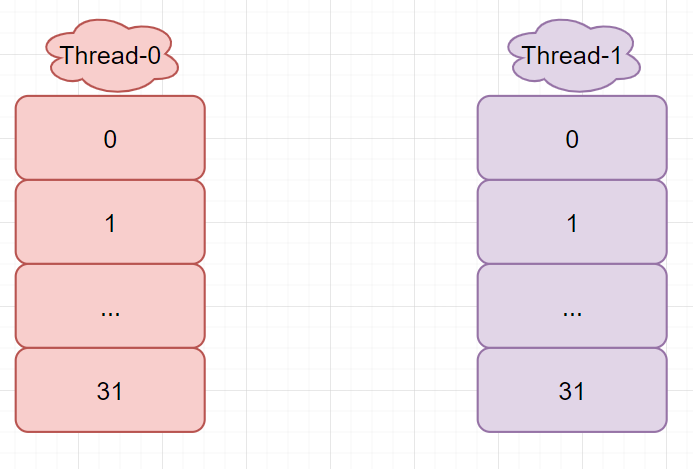
After Thread-0 and Thread-1 perform the capacity expansion operation, a new entry array newTable is created at the same time
Thread-0 is executed to entry < K, V > next = e.next; The time slice runs out and hangs. At this time
- e -> 1 -> 35 -> 16 -> null
- next -> 35 -> 16 -> null
Thread-1 executes normally. Since JDK7 uses the header insertion method when inserting the linked list, the order of the new linked list copied by thread-1 after rehash is opposite to that before (16 is transferred to other places)
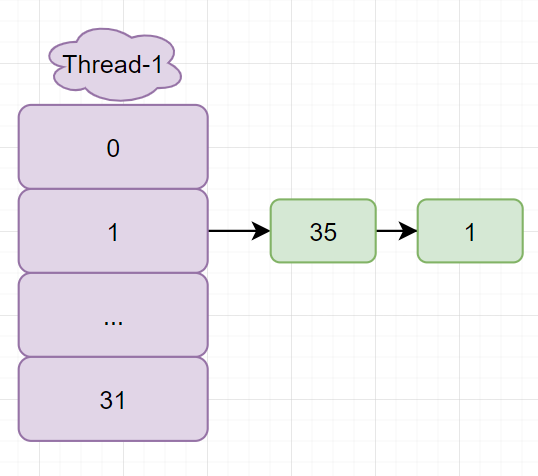
At this time, the variable E of Thread-0 still points to 1, and next points to 35. Start the circular operation, insert 1 into the linked list, e becomes the successor 35, and next is equal to the successor 1 of 35
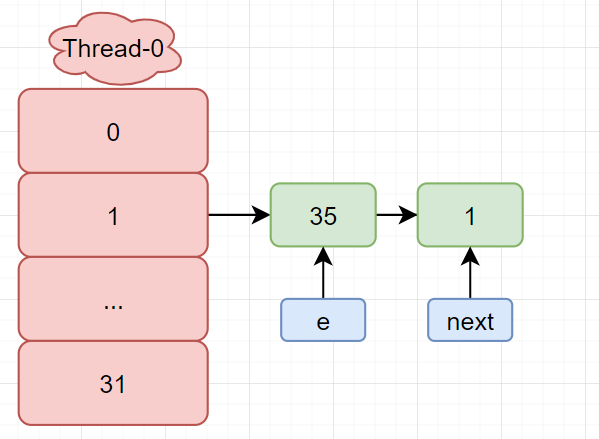
Again, loop e = 1, next = null
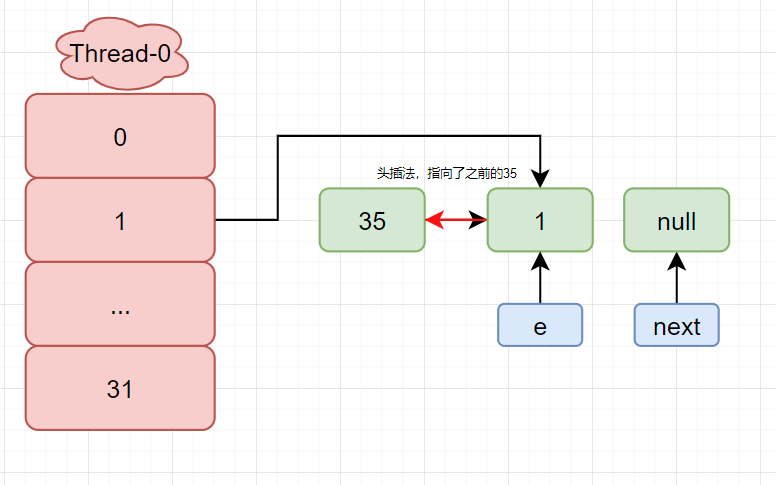
At this point, 35 and 1 point to each other respectively, forming a dead chain
2.2.6. jdk8 changes
JDK 8 has adjusted the capacity expansion algorithm to no longer add elements to the chain header (but maintain the same order as before the capacity expansion), but it still does not mean that the capacity can be safely expanded in a multi-threaded environment, and there will be other problems (such as data loss during capacity expansion), but the official will not fix it, because you are not allowed to use HashMap in high concurrency scenarios, Mingming asked you to use ConcurrentHashMap
2.3 principle of JDK8 ConcurrentHashMap
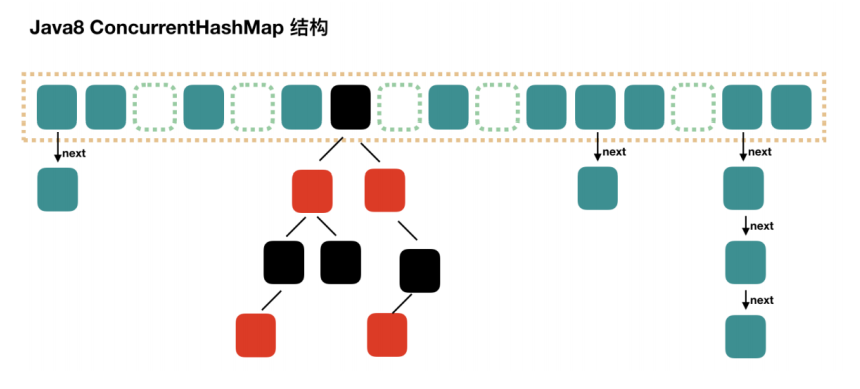
2.3.1 important attributes and internal classes
// The default is 0
// - 1 when initialized
// In case of capacity expansion, it is - (1 + number of capacity expansion threads)
// After initialization or capacity expansion is completed, it is the threshold size of the next capacity expansion
private transient volatile int sizeCtl;
// The entire ConcurrentHashMap is a Node []
static class Node<K,V> implements Map.Entry<K,V> {}
// hash table
transient volatile Node<K,V>[] table;
// New hash table during capacity expansion
private transient volatile Node<K,V>[] nextTable;
// During capacity expansion, if a bin is migrated, use ForwardingNode as the head node of the old table bin, key = -1
static final class ForwardingNode<K,V> extends Node<K,V> {}
// It is used in compute and computeIfAbsent. It is used to occupy the bit. After the calculation is completed, it is replaced with an ordinary Node
static final class ReservationNode<K,V> extends Node<K,V> {}
// As the head node of the red black tree, it stores root and first, and its child node is also TreeNode
static final class TreeBin<K,V> extends Node<K,V> {}
// As the node of treebin, store parent, left, right
static final class TreeNode<K,V> extends Node<K,V> {}
Important methods
// Get the ith Node in Node [] static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) // cas modifies the value of the ith Node in Node [], where c is the old value and v is the new value static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) // Directly modify the value of the ith Node in Node [], and v is the new value static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v)
2.3.3. Constructor
JDK 8 is lazy initialization. In the construction method, only the size of the table is calculated, and it will be created when it is used for the first time
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// tableSizeFor still guarantees that the calculated size is 2^n, that is, 16,32,64
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
2.3.4,get
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// The spread method ensures that the return result is a positive number
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// If the header node is already the key to be found
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// A negative hash number indicates that the bin is in capacity expansion (- 1) or treebin (- 2). In this case, call the find method to find it
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// Normally traverse the linked list and compare with equals
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
2.3.5,put
- Put also has an overloaded three parameter method. The third parameter indicates whether to overwrite the existing value. If it already exists, it cannot be put
- HashMap allows null values, but ConcurrentHashMap does not
- map initialization is lazy
- If the length of the linked list > = the treelization threshold (8), the linked list will be transformed into a red black tree, but it will not be transformed into a red black tree immediately. First, the capacity will be expanded. If the length of the hash table has not reached 64, it will expand the capacity first and disperse the data again. If the length of the linked list is greater than or equal to 8 after the capacity expansion, it will not be expanded again and will be transformed into the data structure of the red black tree
- When initializing the hash table, only one thread can be created. Other threads will not block, but are busy, etc
- After the put is successful, we will learn from the idea of LongAdder, call the addCount method to count the segments, save the number of elements in each position, and judge whether the current capacity expansion is needed
public V put(K key, V value) {
//The third parameter is whether to overwrite the existing value. If it already exists, it cannot be put
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
//HashMap allows null values, but ConcurrentHashMap does not
if (key == null || value == null) throw new NullPointerException();
// Among them, the spread method will integrate the high and low positions, which has better hash performance
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f is the chain header node
// fh is the hash of the chain header node
// i is the subscript of the linked list in the table
Node<K,V> f; int n, i, fh;
// To create a table
if (tab == null || (n = tab.length) == 0)
// cas is used to initialize the table, which does not need to be synchronized. It is created successfully and enters the next cycle
tab = initTable();
// To create a chain header node
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// cas is used to add the chain header, and synchronized is not required
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
// Judge whether the head node is - 1. If so, other threads are expanding capacity, and then return it to help expand capacity
else if ((fh = f.hash) == MOVED)
// After help, enter the next cycle
tab = helpTransfer(tab, f);
//Neither expansion nor initialization, or subscript conflict
else {
V oldVal = null;
// Lock chain header node
synchronized (f) {
// Confirm again that the chain header node has not been moved
if (tabAt(tab, i) == f) {
// Linked list, red black tree is - 2
if (fh >= 0) {
//Linked list length
binCount = 1;
// Traversal linked list
for (Node<K,V> e = f;; ++binCount) {
K ek;
// Find the same key
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
// to update
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// It is already the last Node. Add a new Node and add it to the end of the linked list
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// Red black tree
else if (f instanceof TreeBin) {
Node<K,V> p;
//Tree height
binCount = 2;
// putTreeVal will check whether the key is already in the tree. If yes, the corresponding TreeNode will be returned
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
// Release the lock of the chain header node
}
//Judge whether to expand capacity
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
// If the length of the linked list > = the treelization threshold (8), the linked list will be transformed into a red black tree, but it will not be transformed into a red black tree immediately. First, the capacity will be expanded. If the length of the hash table has not reached 64, it will expand the capacity first and disperse the data again. If the length of the linked list is greater than or equal to 8 after the capacity expansion, it will not be expanded again and will be transformed into the data structure of the red black tree
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// Increase the size count and save the element depth at each position
addCount(1L, binCount);
return null;
}
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
//If another thread is already creating the table, it will give the permission
Thread.yield();
// Try to set sizeCtl to - 1 (to initialize table)
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
// Obtain the lock and create the table. At this time, other threads will yield in the while() loop until the table is created
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
//Prepare the value to be expanded next time
sc = n - (n >>> 2);
}
} finally {sizeCtl = sc;
}
break;
}
}
return tab;
}
// check is the number of previous bincounts
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if (
// There are already counter cells. Add them to the cell
(as = counterCells) != null ||
// Not yet. Add up to baseCount
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)
) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (
// No counterCells yet
as == null || (m = as.length - 1) < 0 ||
// No cell yet
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
// cell cas failed to increase count
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
) {
// Create the accumulation cell array and cell, and try again
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// Get the number of elements
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//Is it greater than the expansion threshold
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// newtable has been created to help expand the capacity
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// The capacity needs to be expanded. At this time, the newtable is not created
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
2.3.6 Size calculation process
Because the calculation of the size of ConcurrentHashMap actually occurs in the operation of put and remove to change the collection elements
-
No competition occurs, and the count is accumulated to baseCount
-
If there is competition, create counter cell s and add a count to one of them
- Counter cells initially has two cells. If the counting competition is fierce, a new cell will be created to accumulate the counting
public int size() { long n = sumCount(); return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n); } final long sumCount() { CounterCell[] as = counterCells; CounterCell a; // Add the baseCount count to all cell counts long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }
2.4 principle of JDK7 ConcurrentHashMap
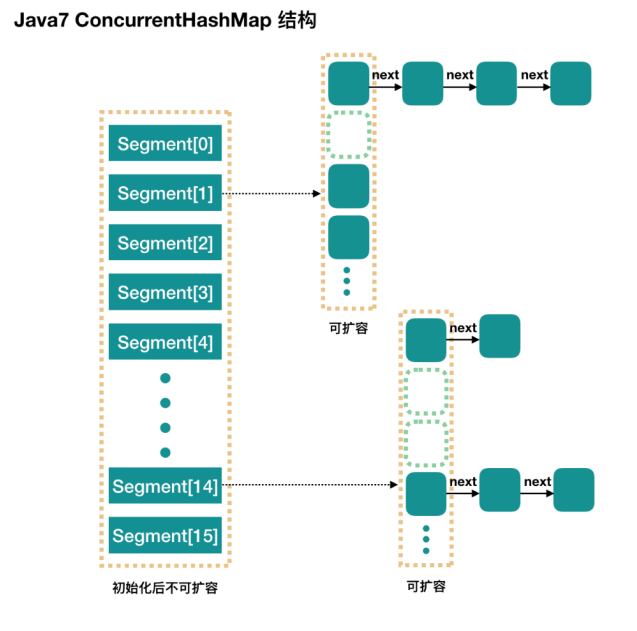
It maintains an array of segments, and each segment corresponds to a lock (in fact, it inherits from ReentrantLock and is a lock itself)
- Advantages: if multiple threads access different segment s, there is actually no conflict, which is similar to that in jdk8 (added to each chain header)
- Disadvantages: the default size of the Segments array is 16. This capacity cannot be changed after initialization is specified, and it is not lazy initialization
2.4.1. Constructor
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// ssize must be 2^n, i.e. 2, 4, 8, 16 Represents the size of the segments array
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// segmentShift defaults to 32 - 4 = 28
this.segmentShift = 32 - sshift;
// segmentMask defaults to 15, that is, 0000 1111
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// Create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
- You can see that ConcurrentHashMap does not implement lazy initialization, and the space occupation is unfriendly. This Segmentshift and this The function of the segmentmask is to determine which segment the hash result of the key is matched to
For example, to find the position of segment according to a hash value, first move the high position to the low position this Segmentshift bit
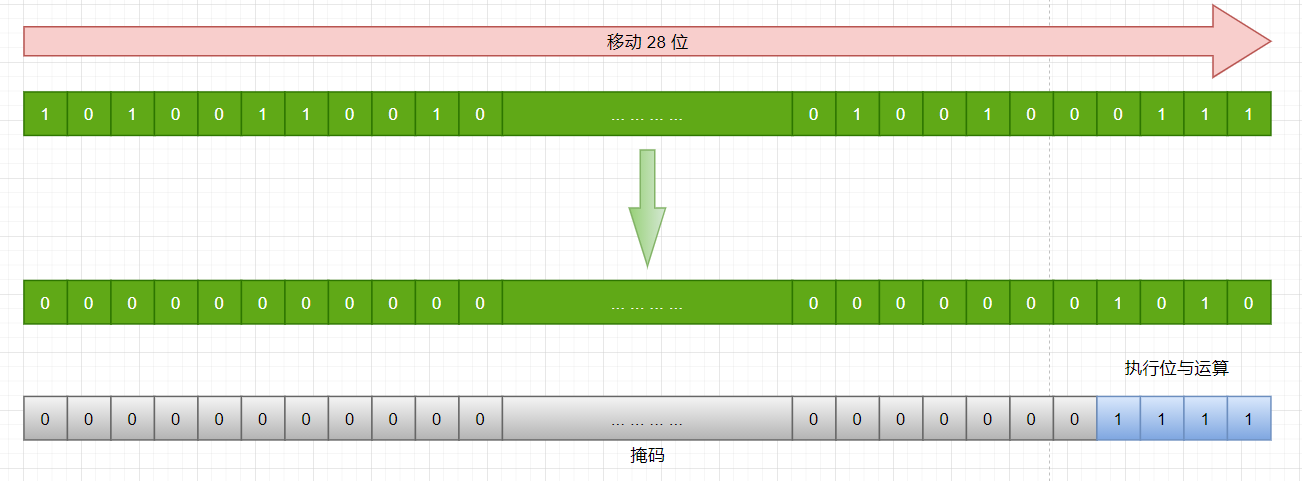
- Finally, 1010 is obtained, that is, the segment with subscript 10
2.4.2,put
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// Calculate the segment subscript
int j = (hash >>> segmentShift) & segmentMask;
// Obtain the segment object and judge whether it is null. If yes, create the segment
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null) {
// At this time, it is uncertain whether it is really null, because other threads also find that the segment is null,
// Therefore, cas is used in ensuesegment to ensure the security of the segment
s = ensureSegment(j);
}
// Enter the put process of segment
return s.put(key, hash, value, false);
}
segment inherits ReentrantLock and its put method is
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// Try locking
HashEntry<K,V> node = tryLock() ? null :
// If not, enter the scanAndLockForPut process
// If it is a multi-core cpu, try lock 64 times at most and enter the lock process
// During the trial, you can also check whether the node is in the linked list. If not, you can create it
scanAndLockForPut(key, hash, value);
// After execution, the segment has been locked successfully and can be executed safely
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// to update
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// newly added
// 1) Before waiting for the lock, the node has been created and the next point to the chain header
if (node != null)
node.setNext(first);
else
// 2) Create a new node
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 3) Capacity expansion
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// Take node as the chain header
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
2.4.3,rehash
It occurs in the put, because the lock has been obtained at this time, so there is no need to consider thread safety when rehash
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// Go through the linked list and reuse the idx unchanged nodes after rehash as much as possible
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// The remaining nodes need to be created
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// New nodes are added only after capacity expansion is completed
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
// Replace with a new HashEntry table
table = newTable;
}
2.4.4,get
Get is not locked, and the UNSAFE method is used to ensure visibility. In the process of capacity expansion, get takes the content from the old table first, and take the content from the new table after get
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
// u is the offset of the segment object in the array
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// s is segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
2.4.5. Size calculation process
- Before calculating the number of elements, calculate twice without locking. If the results are the same, it is considered that the number is returned correctly
- If not, retry. If the number of retries exceeds 3, lock all segment s, recalculate the number, and return
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
// If the number of retries exceeds, all segment s need to be created and locked
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
2.5 summary
-
The segmentation lock used by ConcurrentHashMap in JDK7 means that only one thread can operate on each Segment at the same time. Each Segment is a structure similar to HashMap array, which can be expanded, and its conflicts will be transformed into linked lists. However, the number of segments cannot be changed once initialized.
-
The concurrent HashMap in JDK8 uses the Synchronized locking CAS mechanism. The structure has also evolved from Segment array + HashEntry array + linked list in JDK7 to node array + linked list / red black tree. Node is similar to a HashEntry structure. When the number of elements in its linked list reaches the threshold of 8, it will be transformed into a red black tree, and it will return to the linked list when the conflict is less than 6.