Consistency hash of Dubbo load balancing policy
1 load balancing
Here is a quote from dubbo's official website——
LoadBalance means load balancing in Chinese. It is responsible for "sharing" network requests or other forms of load to different machines. Avoid excessive pressure on some servers in the cluster while others are idle. Through load balancing, each server can obtain the load suitable for its own processing capacity. While shunting high load servers, it can also avoid resource waste and kill two birds with one stone. Load balancing can be divided into software load balancing and hardware load balancing. In our daily development, it is generally difficult to touch hardware load balancing. However, software load balancing is still accessible, such as Nginx. In Dubbo, there are also load balancing concepts and corresponding implementations. Dubbo needs to allocate the call requests of service consumers to avoid excessive load on a few service providers. The service provider is overloaded, which will cause some requests to time out. Therefore, it is very necessary to balance the load on each service provider. Dubbo provides four load balancing implementations, namely RandomLoadBalance based on weight random algorithm, leadactiveloadbalance based on least active calls algorithm, ConsistentHashLoadBalance based on hash consistency, and roundrobin LoadBalance based on weighted polling algorithm. The code of these load balancing algorithms is not very long, but it is not easy to understand them. You need to have a certain understanding of the principles of these algorithms.
2 hash algorithm
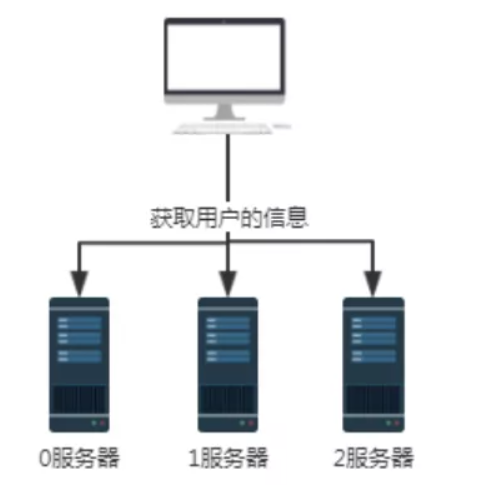
Figure 1 no hash algorithm requestAs shown above, assuming that servers 0, 1 and 2 store user information, when we need to obtain user information, we need to query servers 0, 1 and 2 respectively because we don't know which server the user information is stored in. The efficiency of obtaining data in this way is extremely low. For such a scenario, we can introduce hash algorithm.
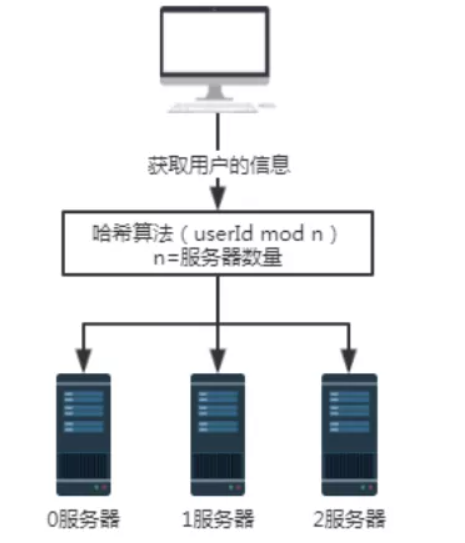
Figure 2 request after introducing hash algorithmIt is the same as the above scenario, but the premise is that each server stores user information according to a hash algorithm. Therefore, when taking user information, you can also take it according to the same hash algorithm.
Suppose we want to query the user information with the user number of 100. After a hash algorithm, for example, the userId mod n here, that is, 100 mod 3, the result is 1. Therefore, the request of user No. 100 will eventually be received and processed by server No. 1.
This solves the problem of invalid query.
But what problems will such a scheme bring?
When expanding or shrinking capacity, it will lead to a large number of data migration. It will also affect at least 50% of the data.
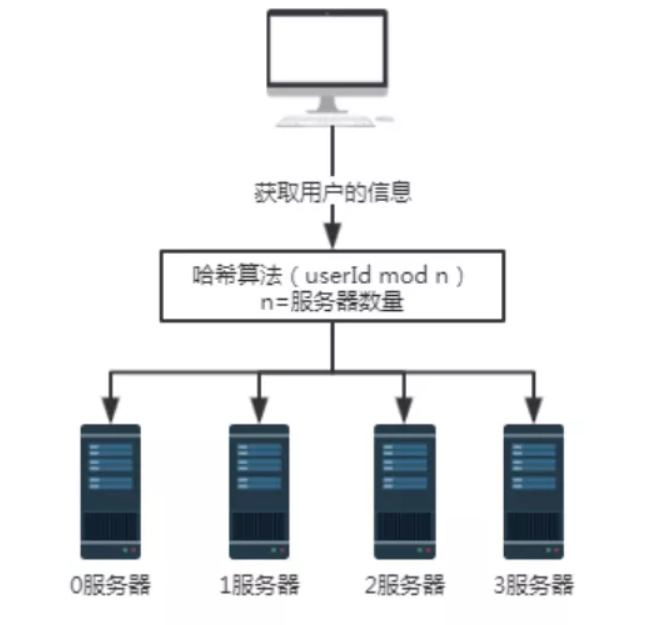
Figure 3 adding a serverTo illustrate the problem, add a server 3. The number n of servers has changed from 3 to 4. When querying the user information with user number 100, the 100 mod 4 result is 0. At this time, the request is received by server 0.
- When the number of servers is 3, the request with user number 100 will be processed by server 1.
- When the number of servers is 4, the request with user number 100 will be processed by server 0.
Therefore, when the number of servers increases or decreases, a large number of data migration will be involved.
For the above hash algorithm, its advantage is simple and easy to use, which is adopted by most database and table rules. Generally, the number of partitions is estimated in advance according to the amount of data.
The disadvantage is that when the number of nodes changes due to the expansion or contraction of nodes, the mapping relationship of nodes needs to be recalculated, which will lead to data migration. Therefore, the capacity expansion is usually doubled to avoid all data mappings being disrupted, resulting in full migration. In this way, only 50% of the data migration will occur.
consistent hashing algorithm
**The consistent hash algorithm was proposed by Karger of MIT and his collaborators in 1997. At the beginning of the algorithm, it was used for load balancing of large-scale cache system** Its working process is as follows: first, generate a hash for the cache node according to ip or other information, and project the hash onto the ring of [0, 232 - 1]. When there is a query or write request, a hash value is generated for the key of the cache item. Then, find the first cache node greater than or equal to the hash value, and query or write cache entries in this node. If the current node hangs, you can find another cache node larger than its hash value for the cache item when querying or writing to the cache next time. The general effect is shown in the figure below, and each cache node occupies a position on the ring. If the hash value of the key of the cache item is less than the hash value of the cache node, the cache item is stored or read in the cache node. For example, the cache entries corresponding to the following green dots will be stored in the cache-2 node. Since cache-3 hangs, the cache items that should have been stored in this node will eventually be stored in cache-4 node.
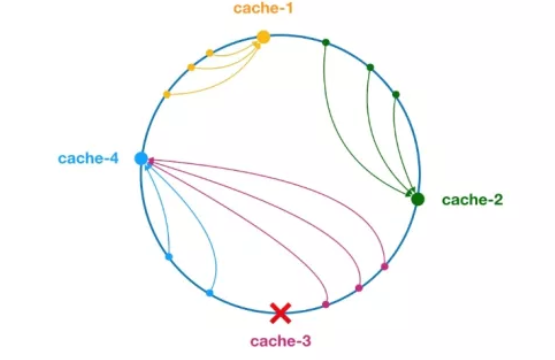
Figure 4 consistent hash algorithmIn the consistent hash algorithm, whether adding nodes or downtime nodes, the affected interval is only the interval between the first server encountered counterclockwise in the hash ring space, and other intervals will not be affected.
However, consistent hashing is also problematic:
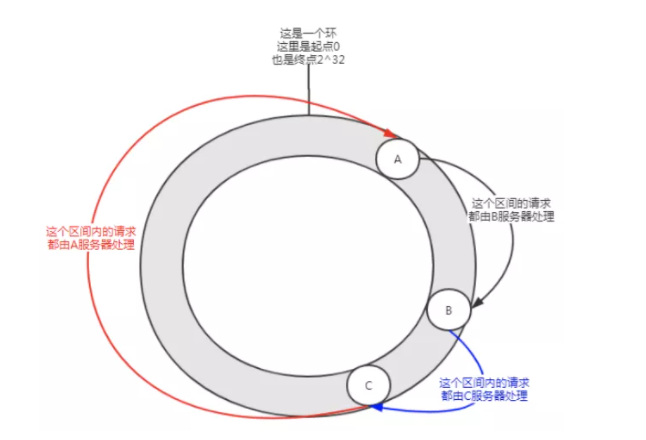
Figure 5 data tiltThis distribution may occur when there are few nodes, and service A will bear most of the requests. This situation is called data skew.
How to solve the problem of data skew?
Join the virtual node.
First, a server can have multiple virtual nodes as needed. Suppose a server has n virtual nodes. During hash calculation, the hash value can be calculated in the form of IP + port + number. The number is a number from 0 to n. Because the IP + ports are the same, the N nodes point to the same machine.
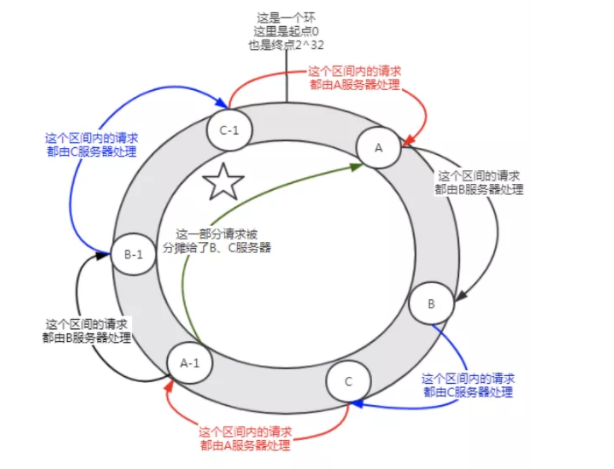
Figure 6 introduction of virtual nodesBefore joining the virtual node, server a undertakes most of the requests. However, suppose that each server has a virtual node (A-1, B-1, C-1), which falls in the position shown in the above figure after hash calculation. Then the requests undertaken by server a are allocated to B-1 and C-1 virtual nodes to a certain extent (the part marked with five pointed stars in the figure), which is actually allocated to servers B and C.
In the consistent hash algorithm, adding virtual nodes can solve the problem of data skew.
4 Application of consistent hash in DUBBO
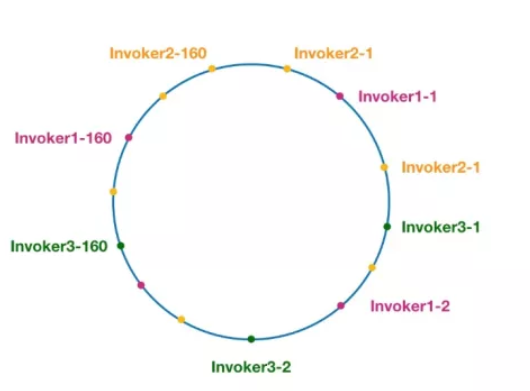
Figure 7 consistency hash ring in DubboNodes with the same color here belong to the same service provider, such as Invoker1-1, Invoker1-2,..., Invoker1-160. The purpose of this is to introduce virtual nodes to disperse invokers on the ring and avoid the problem of data skew. The so-called data skew refers to the situation that a large number of requests fall on the same node due to the lack of dispersion of nodes, while other nodes will only receive a small number of requests. For example:
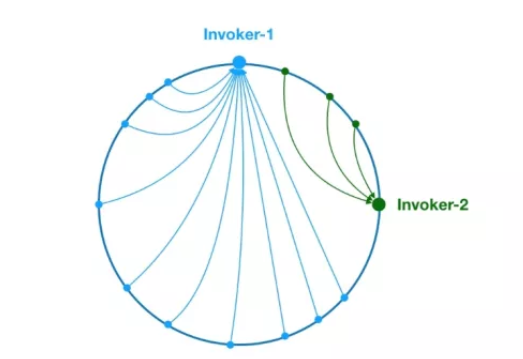
Figure 8 data skew problemAs mentioned above, due to the uneven distribution of Invoker-1 and Invoker-2 on the ring, 75% of the requests in the system will fall on Invoker-1 and only 25% of the requests will fall on Invoker-2. The solution to this problem is to introduce virtual nodes to balance the requests of each node.
Here, the background knowledge is popularized, and then start to analyze the source code. Let's start with the doSelect method of ConsistentHashLoadBalance, as follows:
public class ConsistentHashLoadBalance extends AbstractLoadBalance {
private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors =
new ConcurrentHashMap<String, ConsistentHashSelector<?>>();
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
String methodName = RpcUtils.getMethodName(invocation);
String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;
// Get the original hashcode of invokers
int identityHashCode = System.identityHashCode(invokers);
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
// If invokers is a new List object, it means that the number of service providers has changed, which may be added or reduced.
// The selector identityHashCode != Identityhashcode condition holds
if (selector == null || selector.identityHashCode != identityHashCode) {
// Create a new ConsistentHashSelector
selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
// Call the select method of ConsistentHashSelector to select Invoker
return selector.select(invocation);
}
private static final class ConsistentHashSelector<T> {...}
}
As mentioned above, the doSelect method mainly does some pre work, such as detecting whether the invokers list has changed, and creating a ConsistentHashSelector. When this is done, we start to call the select method of ConsistentHashSelector to execute the load balancing logic. Before analyzing the select method, let's take a look at the initialization process of the consistency hash selector ConsistentHashSelector, as follows:
private static final class ConsistentHashSelector<T> {
// Using TreeMap to store Invoker virtual nodes
private final TreeMap<Long, Invoker<T>> virtualInvokers;
private final int replicaNumber;
private final int identityHashCode;
private final int[] argumentIndex;
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
// Get the number of virtual nodes. The default is 160
this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);
// Get the parameter subscript value involved in hash calculation. By default, hash operation is performed on the first parameter
String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
for (Invoker<T> invoker : invokers) {
String address = invoker.getUrl().getAddress();
for (int i = 0; i < replicaNumber / 4; i++) {
// Perform md5 operation on address + i to obtain a 16 byte array
byte[] digest = md5(address + i);
// Four hash operations are performed on some bytes of digest to obtain four different long positive integers
for (int h = 0; h < 4; h++) {
// When h = 0, take 4 bytes with subscript 0 ~ 3 in digest for bit operation
// When h = 1, take 4 bytes with subscripts 4 ~ 7 in digest for bit operation
// The process is the same as above when h = 2 and H = 3
long m = hash(digest, h);
// Store the mapping relationship from hash to invoker in virtualInvokers,
// Virtual invokers needs to provide efficient query operations, so TreeMap is selected as the storage structure
virtualInvokers.put(m, invoker);
}
}
}
}
}
The construction method of ConsistentHashSelector implements a series of initialization logic, such as obtaining the number of virtual nodes from the configuration and the parameter subscripts participating in hash calculation. By default, only the first parameter is used for hash. It should be noted that the load balancing logic of ConsistentHashLoadBalance is only affected by parameter values, and requests with the same parameter values will be assigned to the same service provider. ConsistentHashLoadBalance does not relate to weight, so you should pay attention to it when using it.
After obtaining the number of virtual nodes and parameter subscript configuration, the next thing to do is to calculate the hash value of virtual nodes and store the virtual nodes in TreeMap. This completes the initialization of the ConsistentHashSelector. Next, let's look at the logic of the select method.
public Invoker<T> select(Invocation invocation) {
// Change parameter to key
String key = toKey(invocation.getArguments());
// md5 operation on parameter key
byte[] digest = md5(key);
// Take the first four bytes of the digest array for hash operation, and then pass the hash value to the selectForKey method,
// Find the right Invoker
return selectForKey(hash(digest, 0));
}
private Invoker<T> selectForKey(long hash) {
// Find the Invoker whose first node value is greater than or equal to the current hash in the TreeMap
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();
// If the hash is greater than the largest position of the Invoker on the ring, then entry = null,
// The header node of TreeMap needs to be assigned to entry
if (entry == null) {
entry = virtualInvokers.firstEntry();
}
// Return to Invoker
return entry.getValue();
}
As mentioned above, the selection process is relatively simple. The first is to perform md5 and hash operations on the parameters to obtain a hash value. Then take this value to the TreeMap to find the target Invoker.
This completes the analysis of consistent hashloadbalance.
Before reading the source code of ConsistentHashLoadBalance, readers are advised to supplement the background knowledge first, otherwise it will be very difficult to understand the code logic.
5 application scenarios
- The earliest load balancing technology of DNS load balancing is realized through DNS. Multiple addresses are configured with the same name in DNS, so the client querying the name will get one of the addresses, so that different clients can access different servers to achieve the purpose of load balancing. DNS load balancing is a simple and effective method, but it can not distinguish the differences of servers, nor can it reflect the current running state of servers.
- Proxy server load balancing uses a proxy server to forward requests to internal servers. Using this acceleration mode can obviously improve the access speed of static web pages. However, we can also consider such a technology, which uses the proxy server to evenly forward requests to multiple servers, so as to achieve the purpose of load balancing.
- Address translation gateway load balancing is an address translation gateway that supports load balancing. It can map an external IP address to multiple internal IP addresses, and dynamically use one of the internal addresses for each TCP connection request to achieve the purpose of load balancing.
- In addition to these three load balancing methods, some protocols support functions related to load balancing, such as redirection capability in HTTP protocol. HTTP runs at the highest level of TCP connection.
- NAT load balancing NAT (Network Address Translation) is simply to convert an IP address to another IP address. It is generally used to convert an unregistered internal address to a legal and registered Internet IP address. It is suitable for solving the situation where the Internet IP address is tight and you don't want the outside of the network to know the internal network structure.
- Reverse Proxy load balancing common proxy method is to proxy the connection request of internal network users to access the server on the internet. The client must specify the proxy server and send the connection request originally sent directly to the server on the internet to the proxy server for processing. Reverse Proxy means that the proxy server accepts the connection request on the internet, then forwards the request to the server on the internal network, and returns the result obtained from the server to the client requesting connection on the internet. At this time, the proxy server appears as a server externally. Reverse Proxy load balancing technology is to dynamically forward connection requests from the internet to multiple servers on the internal network in the form of Reverse Proxy for processing, so as to achieve the purpose of load balancing.
The connection request to be sent directly to the server on the internet is sent to the proxy server for processing. Reverse Proxy means that the proxy server accepts the connection request on the internet, then forwards the request to the server on the internal network, and returns the result obtained from the server to the client requesting connection on the internet. At this time, the proxy server appears as a server externally. Reverse Proxy load balancing technology is to dynamically forward connection requests from the internet to multiple servers on the internal network in the form of Reverse Proxy for processing, so as to achieve the purpose of load balancing. - Hybrid load balancing in some large networks, due to the differences in hardware equipment, scale and services provided in multiple server clusters, the most appropriate load balancing method can be considered for each server cluster, Then load balance or cluster the multiple server clusters again to provide services to the outside world as a whole (that is, treat the multiple server clusters as a new server cluster), so as to achieve the best performance. This method is called hybrid load balancing. This method is sometimes used when the performance of a single balancing device cannot meet a large number of connection requests.