First of all, what is Liuli? This is an open source project I recently developed. The main purpose is to enable friends with reading habits to quickly build a multi-source, clean and personalized reading environment.
Why Liuli?
Liuli was originally named 2C, and the friends of the communication group behind provided the name of Liuli, which is taken from the clear boundary of Liuli and the Zen pass of Xue Li in Mei Yaochen's "Huishan temple in goushanzi Jinci Temple". Its implication is also in line with the intention of the project:
Build a pure land for users to read, such as the East glazed world
It's been one month since the last release (I'm too late to reflect). Today, I'm glad to announce that Liuli has another wave of updates! 🥳 See for details v0.2.0 task Kanban.
Next, I will use the latest version of Liuli v0 1.5, let's introduce how to build a pure RSS official account information flow based on Liuli.
start
First of all, let's start with the demand. At present, I have three demands:
- Aggregate the current subscription official account, output through RSS and subscribe separately.
- Advertising recognition of subscribed articles
- Make a quick backup of the article
The above appeal is precisely the theme of this article to build a pure RSS official account information flow. The specific implementation is not detailed here, and it is interesting to exchange in the communication group. This article only says how to use it.
If you've read the one I wrote before Build a clean and personalized official account environment. , you may have some knowledge about the concepts of collector, processor, distributor, etc., but here for the sake of reading consistency, so let's introduce it again. First, let's look at the architecture diagram:
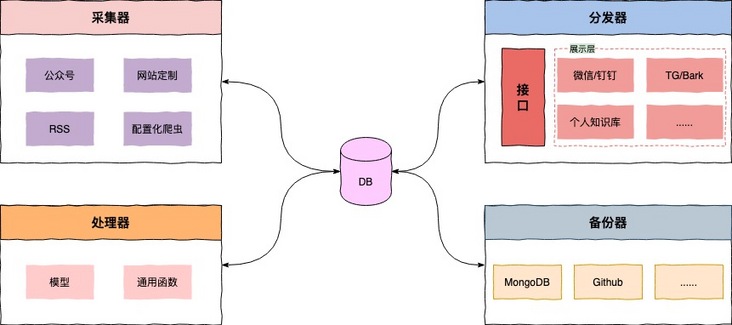
Briefly explain:
- Collector: monitoring the official account or blog and other custom reading sources, and entering the Liuli in uniform standard format as input source.
- Processor: customize the target content, such as using machine learning to realize automatic labeling of an advertisement classifier based on historical advertisement data, or introducing hook function to execute at relevant nodes;
- Distributor: rely on the interface layer for data request & response, provide personalized configuration for users, and then distribute automatically according to the configuration, and flow clean articles to wechat, nailing, TG and even self built websites;
- Backup device: backup the processed articles, such as persisting to the database or GitHub.
In fact, it doesn't matter if you don't understand the process. Just know how to use it. Next, please follow the tutorial step by step in detail. It's best to have a computer to follow the operation.
use
OK, the main play begins. Liuli's deployment is very convenient. It is recommended that you use Docker for deployment, so you need to install Docker on your equipment before you start. If not, click here install Just.
to configure
The current configuration of Liuli is mainly divided into two parts:
- Global configuration: refers to the global environment variable. See for relevant descriptions Liuli environment variable
- Task configuration: this configuration is formed for the problems that users need to solve. For example, this article will generate a configuration to collect, process and output official account numbers (RSS).
Global configuration
First, let's talk about the global configuration. In fact, the configuration provided by default can also make everyone run. However, if you need to distribute articles to wechat or nailing, you need to fill in the relevant configuration. Well, let's start. Please open the terminal or create some folders or files in a familiar way.
mkdir liuli cd liuli # Store the scheduling task configuration. It is named default by default json mkdir liuli_config # database mkdir mongodb_data # Drop down docker compose configuration # If the network is not good, please fill it in manually. See the appendix for the contents wget https://raw.githubusercontent.com/howie6879/liuli/main/docker-compose.yaml # Configure pro Env see the Liuli environment variable in the global configuration vim pro.env
For pro Env, if you want to know more, please check it Global configuration Of course, it doesn't matter if you don't want to see it. Just follow this tutorial. First, copy the following configuration to pro env:
PYTHONPATH=${PYTHONPATH}:${PWD}
LL_M_USER="liuli"
LL_M_PASS="liuli"
LL_M_HOST="liuli_mongodb"
LL_M_PORT="27017"
LL_M_DB="admin"
LL_M_OP_DB="liuli"
LL_FLASK_DEBUG=0
LL_HOST="0.0.0.0"
LL_HTTP_PORT=8765
LL_WORKERS=1
# There are so many configurations above that you don't need to change. Only the following ones need to be configured separately
# Please fill in your actual IP address
LL_DOMAIN="http://{real_ip}:8765"
# Please fill in wechat distribution configuration
LL_WECOM_ID=""
LL_WECOM_AGENT_ID="-1"
LL_WECOM_SECRET=""Assuming you use wechat as the distribution terminal like me, you only need to obtain the following parameters through the following steps:
- LL_WECOM_ID
- LL_WECOM_AGENT_ID
- LL_WECOM_SECRET
The acquisition process is as follows. Please register one with your mobile phone number first Enterprise wechat.
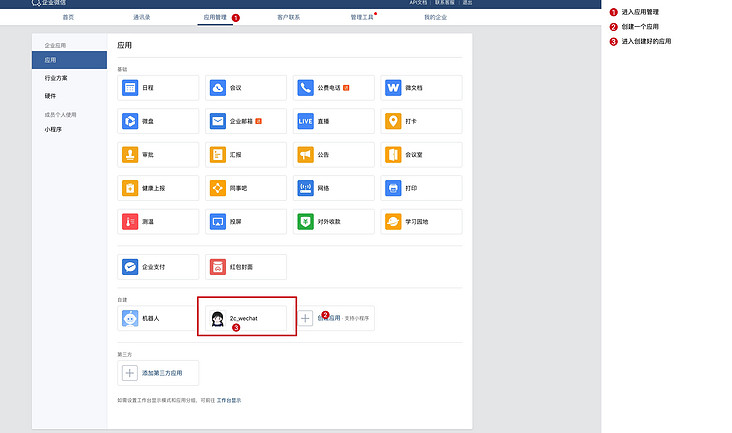
First, create applications:
Get correlation ID:
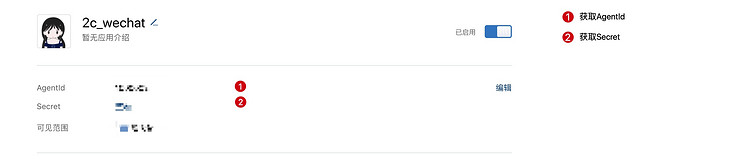
Enterprise ID is in my enterprise - > enterprise information - > Enterprise ID.
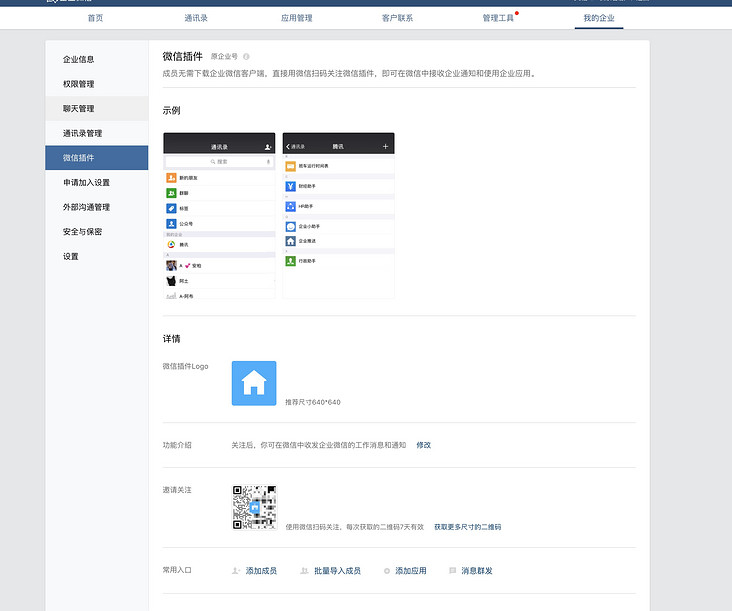
To facilitate receiving messages on wechat, remember to open the wechat plug-in, enter the location shown in the figure below, scan the code and pay attention to your QR Code:
Now that you have obtained the following three parameters, please go to the corresponding configuration and fill in the secret key.
Task configuration
The task configuration is mainly to enable users to use Liuli more personalized, so as to meet the needs of users. At present, Liuli can only support official account collection, filtering, distribution and backup operation. This is the core purpose of this article. We will copy the following contents to liuli_config/default.json:
{
"name": "default",
"author": "liuli_team",
"collector": {
"wechat_sougou": {
"wechat_list": [
"Lao Hu's locker"
],
"delta_time": 5,
"spider_type": "playwright"
}
},
"processor": {
"before_collect": [],
"after_collect": [{
"func": "ad_marker",
"cos_value": 0.6
}, {
"func": "to_rss",
"link_source": "github"
}]
},
"sender": {
"sender_list": ["wecom"],
"query_days": 7,
"delta_time": 3
},
"backup": {
"backup_list": ["mongodb"],
"query_days": 7,
"delta_time": 3,
"init_config": {},
"after_get_content": [{
"func": "str_replace",
"before_str": "data-src=\"",
"after_str": "src=\"https://images.weserv.nl/?url="
}]
},
"schedule": {
"period_list": [
"00:10",
"12:10",
"21:10"
]
}
}Pay attention to wechat above_ List field, you only need to input the official account you want to subscribe to, then the interface will be configured to make use of it first.
start-up
Thank you for seeing here. Now there is only one line of command before success. Please check whether the file tree under the liuli directory looks like this:
(base) [liuli] tree -L 1 ├── docker-compose.yaml ├── liuli_config ├────default.json ├── mongodb_data └── pro.env
After confirming that there is no problem, execute:
docker-compose up -d
Not surprisingly, you will see that Docker starts the three containers:

View liuli_schedule, there will be a log as follows:
The output log is as follows:
Loading .env environment variables... [2022:01:26 23:09:24] INFO Liuli Schedule(v0.1.5) started successfully :) [2022:01:26 23:09:24] INFO Liuli Schedule time: 00:10 12:10 21:10 [2022:01:26 23:09:36] INFO Liuli playwright Locker for matching official account Lao Hu(howie_locker) success! Extracting latest articles: My Weekly (Issue 023) [2022:01:26 23:09:39] INFO Liuli The official account is persistent and successful.! 👉 Lao Hu's locker [2022:01:26 23:09:40] INFO Liuli 🤗 The official account of WeChat is updated.(1/1) ... [2022:01:26 23:09:45] INFO Liuli Backup completed!
After execution, you can enter the MongoDB database, and the following collection will appear:
- liuli_articles: get meta information of articles
- liuli_backup: backup all articles
- liuli_rss: generated RSS
- liuli_send_list: distribution status
- liuli_backup_list: backup status
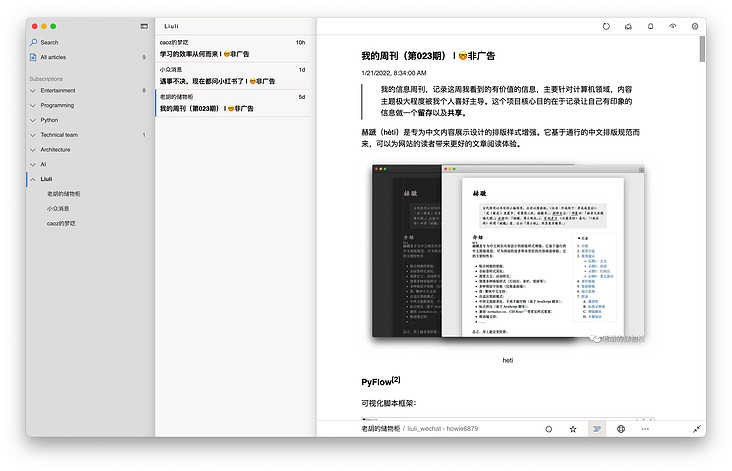
Assuming that your official account has a locker for Lao Hu, you can visit RSS's subscription address of Lao Hu's locker after the boot is completed. http://ip:8765/rss/liuli_wechat/ Lao Hu's lockers / have the following effects:
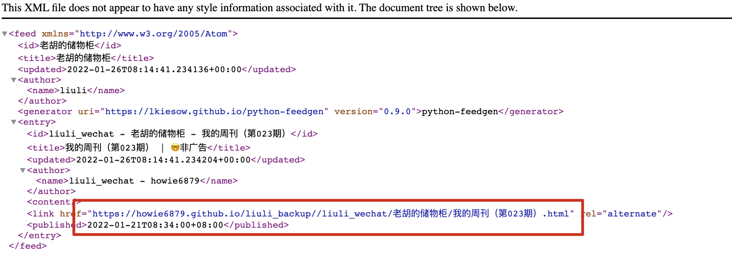
Pay attention to the red box. Because I use the GitHub backup device, the address displays the GitHub address. If you want to use this, you can refer to the tutorial Backup configuration , the effect of using GitHub backup is as follows:
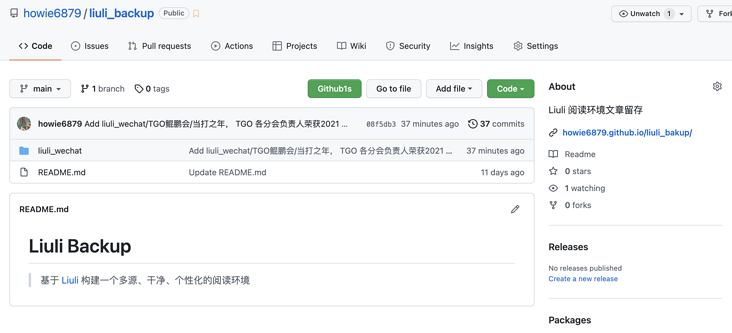
The articles updated every day will be automatically synchronized to this project by Liuli. If we all use Liuli's GitHub backup device to combine the backup results together, it will be a very huge force. We can look forward to it.
Exhibition
After Liuli is started successfully, for users, it is mainly perceived in the layer of distribution and subscription.
Effect drawing of wechat distribution terminal:
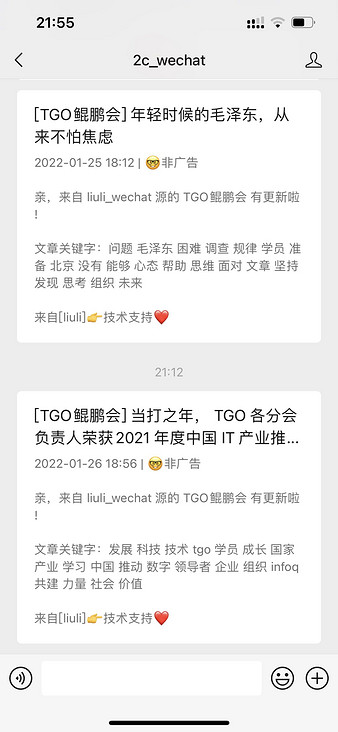
The subscription effect is as follows:
explain
This project is still in a very young and early stage. If you find it useful, I hope you can use it quickly and give some opinions as soon as possible to make Liuli grow faster.
If you think this project is good, please give Liuli a Star in GitHub. Click here for the project address 👉 liuli-io/liuli.
If you have any questions or comments in the process of building and using, you can directly mention Issue in GitHub or go directly into the group to chat with us (if expired, there is WeChat in the official account, and I'll pull you into the group).
appendix
docker-compose.yaml is configured as follows:
version: "3"
services:
liuli_api:
image: liuliio/api:v0.1.1
restart: always
container_name: liuli_api
ports:
- "8765:8765"
volumes:
- ./pro.env:/data/code/pro.env
links:
- liuli_mongodb
depends_on:
- liuli_mongodb
networks:
- liuli-network
liuli_schedule:
image: liuliio/schedule:v0.1.5
restart: always
container_name: liuli_schedule
volumes:
- ./pro.env:/data/code/pro.env
- ./liuli_config:/data/code/liuli_config
links:
- liuli_mongodb
depends_on:
- liuli_mongodb
networks:
- liuli-network
liuli_mongodb:
image: mongo:3.6
restart: always
container_name: liuli_mongodb
environment:
- MONGO_INITDB_ROOT_USERNAME=liuli
- MONGO_INITDB_ROOT_PASSWORD=liuli
ports:
- "27027:27017"
volumes:
- ./mongodb_data:/data/db
command: mongod
networks:
- liuli-network
networks:
liuli-network:
driver: bridge