Flow control Consumer
In order to avoid excessive traffic hitting the Consumer end and crushing the Consumer due to the sharp increase of traffic in Kafka, we need to limit the current of the Consumer. For example, when the amount of data processed reaches a certain threshold, the consumption is suspended, and when it is lower than the threshold, the consumption is resumed, which can enable the Consumer to maintain a certain rate to consume data, so as to avoid crushing the Consumer when the traffic increases sharply.
In other cases, a consumer assigns multiple partitions and consumes all partitions at the same time. These partitions have the same priority. In some cases, consumers need to consume some specified partitions first. When the specified partition has a small amount of or no consumable data, they will start consuming other partitions.
For example, in stream processing, when the processor obtains messages from two topics and combines the messages of the two topics, when one topic lags behind the other for a long time, the consumption will be suspended so that the laggard can catch up.
kafka supports dynamic control of consumption flow. pause(Collection) and resume(Collection) are used in future's poll(long) to suspend consumption of the assigned partition and restart consumption of the assigned suspended partition.
Combining token bucket to limit the current of kafka consumer:
- After the data is poll ed, go to the token bucket to get the token
- If the token is obtained, continue the business processing
- If the token cannot be obtained, the pause method is called to pause the Consumer and wait for the token
- When there are enough tokens in the token bucket, call the resume method to restore the consumption state of the Consumer
Next, write a specific code case to briefly demonstrate this current limiting idea. The token bucket algorithm uses the built-in in Guava, so you need to add a dependency on Guava in the project. For single machine current limiting, you can directly use the current limiting tool class RateLimiter provided by Google Guava. RateLimiter is based on token bucket algorithm and can deal with sudden traffic.
In addition to the most basic token bucket algorithm (smooth burst current limiting), Guava's RateLimiter also provides the algorithm implementation of smooth warm-up current limiting. Smooth burst current limiting is to put the token into the bucket according to the specified rate, and the smooth preheating current limiting will have a preheating time. Within the preheating time, the rate will gradually increase to the configured rate.
The added dependencies are as follows:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
<!-- or, for Android: -->
<!-- <version>31.0.1-android</version>-->
</dependency>
Then we can use Guava's current limiter to limit the current of the Consumer. The test code is as follows
/*
Flow control - current limiting
*/
private static void controlPause() {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "81.68.82.48:9092");
properties.setProperty("group.id", "groupxt");
properties.setProperty("enable.auto.commit", "false");
properties.setProperty("auto.commit.interval.ms", "1000");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer(properties);
TopicPartition p0 = new TopicPartition(TOPIC_NAME, 0);
TopicPartition p1 = new TopicPartition(TOPIC_NAME, 1);
TopicPartition p2 = new TopicPartition(TOPIC_NAME,2);
/*** Token generation rate in seconds */
//Control the consumption speed of each partition separately
final int permitsPerSecond1 = 5;
final int permitsPerSecond2 = 3;
final int permitsPerSecond3 = 6;
/*** Current limiter */
final RateLimiter LIMITER = RateLimiter.create(permitsPerSecond1);
final RateLimiter LIMITER2 = RateLimiter.create(permitsPerSecond2);
final RateLimiter LIMITER3 = RateLimiter.create(permitsPerSecond3);
// Consume and subscribe to a partition or multiple of a Topic
consumer.assign(Arrays.asList(p0,p1,p2));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));
//If no message is pulled, pull again
if (records.isEmpty()) {
continue;
}
// Each partition is handled separately
for(TopicPartition partition : records.partitions()){
List<ConsumerRecord<String, String>> pRecord = records.records(partition);
for (ConsumerRecord<String, String> record : pRecord) {
//When the business operation is executed, the messages pulled by the consumer will be blocked here. The consumer will not pull the next batch of messages until other business processes these messages
System.out.printf("patition = %d , offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
/*
1,After receiving the record information, take the token from the token bucket
2,If the token is obtained, continue the business processing
3,If the token cannot be obtained, pause waits for the token
4,When there are enough tokens in the token bucket, set the consumer to resume status
*/
// Current limiting partition 0
if (!LIMITER.tryAcquire()) {
System.out.println("Unable to get p0 Token, pause consumption p0");
consumer.pause(Arrays.asList( p0));
} else {
System.out.println("Get p0 Token, resume consumption p0");
consumer.resume(Arrays.asList(p0));
}
// Current limiting partition 1
if (!LIMITER2.tryAcquire()) {
System.out.println("Unable to get p1 Pause consumption, token p1");
consumer.pause(Arrays.asList(p1));
} else {
System.out.println("Get p1 Token, resume consumption p1");
consumer.resume(Arrays.asList(p1));
}
// Current limiting partition 2
if (!LIMITER3.tryAcquire()) {
System.out.println("Unable to get p2 Token, suspend consumption p2");
consumer.pause(Arrays.asList(p2));
} else {
System.out.println("Get p2 Token, resume consumption p2");
consumer.resume(Arrays.asList(p2));
}
}
long lastOffset = pRecord.get(pRecord.size() -1).offset();
// offset in a single partition and commit
Map<TopicPartition, OffsetAndMetadata> offset = new HashMap<>();
offset.put(partition,new OffsetAndMetadata(lastOffset+1));
// Submit offset
consumer.commitSync(offset);
System.out.println("=============partition - "+ partition +" end================");
}
}
}
Other current limiting libraries can also be used, such as Bucket4j It is a very good current limiting Library Based on token / leaky bucket algorithm. Compared with Guava's current limiting tool class, Bucket4j provides more comprehensive current limiting functions. It not only supports single machine current limiting and distributed current limiting, but also integrated monitoring, which can be used with Prometheus and Grafana. However, after all, Guava is only a fully functional tool class library, and its out of the box current limiting function is more practical in many stand-alone scenarios.
The early version of single machine flow restriction in Spring Cloud Gateway is based on Bucket4j. Later, it was replaced by Resilience4j . Resilience4j is a lightweight fault-tolerant component inspired by Hystrix. Since Netflix announced that it would no longer actively develop Hystrix (opens new window), both Spring officials and Netflix recommend using resilience4j as current limiting fuse.
Generally, in order to ensure the high availability of the system, the current limiting and fusing of the project should be done together. Resilience4j not only provides current limiting, but also provides fuse, load protection, automatic retry and other functions to ensure the high availability of the system out of the box. Moreover, the ecology of resilience4j is also better. Many gateways use resilience4j as current limiting fuse. Therefore, resilience4j may be a better choice in most scenarios. For some simple current limiting scenarios, Guava or Bucket4j is also a good choice.
Distributed current limiting
Common schemes of distributed current limiting:
- Current limiting with middleware rack: you can realize the corresponding current limiting logic with Sentinel or Redis.
- Gateway layer current limit: a commonly used scheme, which directly arranges the current limit at the gateway layer. However, the current limitation of gateway layer usually needs the help of Middleware / framework. For example, RedisRateLimiter, the distributed current limiting implementation of Spring Cloud Gateway, is based on Redis+Lua. For another example, Spring Cloud Gateway can integrate Sentinel for current limiting.
If you want to manually implement current limiting logic based on Redis, it is recommended to cooperate with Lua script. There are also many ready-made scripts on the Internet for your reference, such as the Apache Gateway project ShenYu The RateLimiter current limiting plug-in implements the token bucket algorithm / parallel licensing bucket algorithm, leaky bucket algorithm and sliding window algorithm based on Redis + Lua.
Consumer consumption control
The flow control of kafka is mentioned above to avoid pulling too many messages and causing service collapse. But sometimes we need to consume the information produced by producers in time and quickly to avoid the problem of consumption backlog. What should we do?
Consumption is too slow
Increase the number of partitions of Topic and increase the number of consumers in the consumption group at the same time, and then multi-threaded consumption messages to improve the consumption speed. When consumers are the most, one partition can be consumed by one consumer
Spending too fast
The above token bucket and other current limiting methods can be adopted, and kafka's own parameters can also be adjusted
Adjustment parameters:
- fetch.max.bytes: the maximum number of messages to obtain data at a time.
- max.poll. Records < = throughput: the maximum number of messages returned by a single poll call. If the processing logic is very light, this value can be increased appropriately. The default value is 500
Number of data pieces from kafka at one time, max.poll Records data needs to be in session timeout. MS is finished within this time
consumer.poll(1000)
The Poll method of the new version of Consumer uses a mechanism similar to Select I/O, so all related events (including rebrance, message acquisition, etc.) occur in an event loop.
1000 is a timeout. Once enough data is obtained (parameter setting), consumer Poll (1000) will immediately return consumerrecords < string, string > records.
If you don't get enough data, it will block 1000ms, but it will return after no more than 1000ms.
Consumer Rebalance resolution
Consumer has a rebalance feature, that is, re load balancing, which depends on a coordinator. Rebalance is triggered whenever a consumer in the Consumer Group exits or a new consumer joins.
The reason for re load balancing is to redistribute the data processed by the exiting Consumer to other consumers in the group for processing. Or when a new Consumer is added, the load pressure of other consumers in the group will be re distributed evenly, instead of saying that a new Consumer is idle.
The following is a brief description of how members of the group interact with the coordinator when Rebalance is triggered in various situations.
1. New member join:
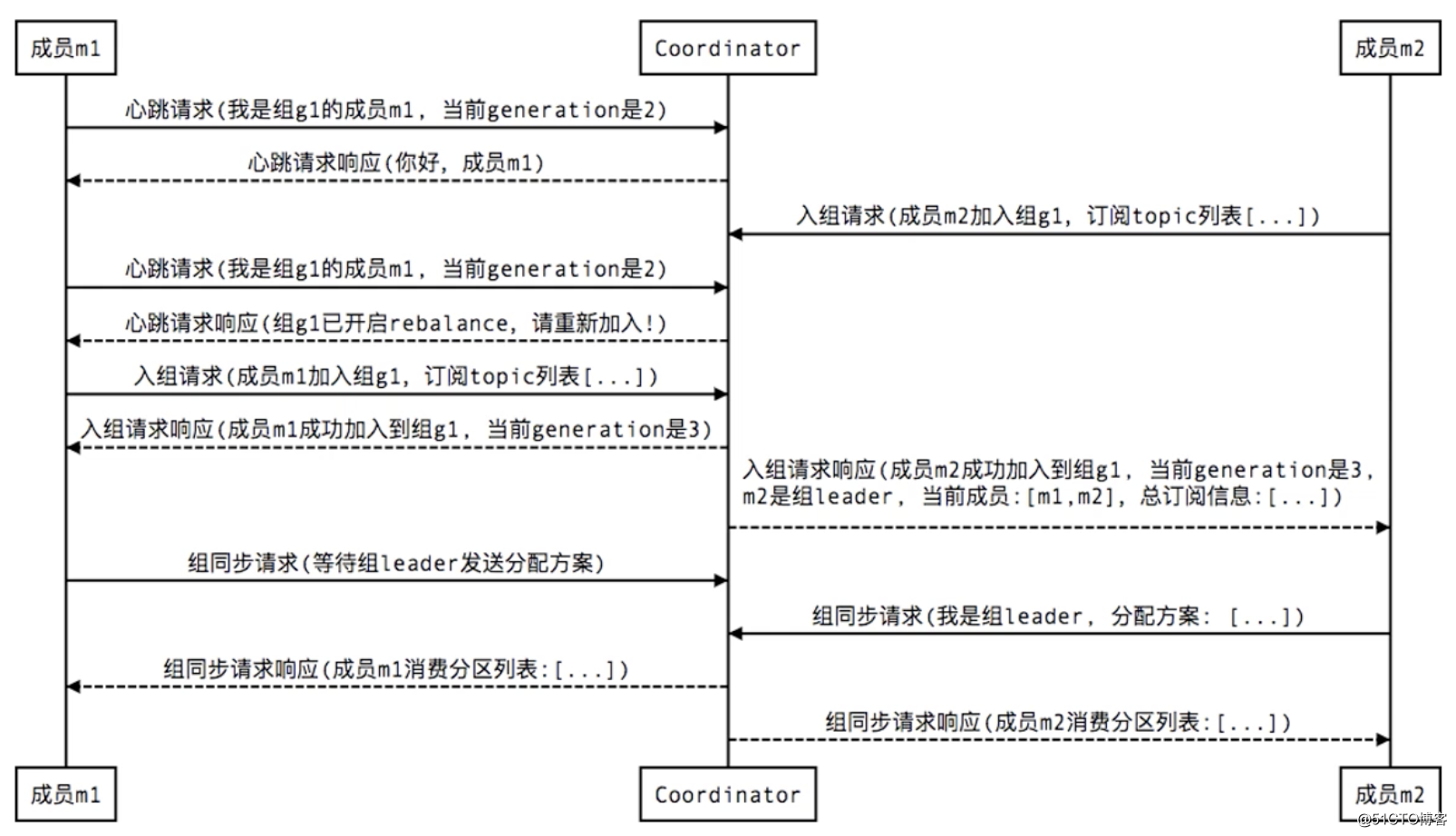
The Coordinator in the figure is the Coordinator. When new members join, all members will be required to disconnect and then reconnect. Generation is similar to the version number in an optimistic lock. It will be updated every time a member is successfully grouped. It also plays a role of concurrency control to avoid submitting dirty data of offset. Each time an offset is submitted, the version number of generation should be taken with it. Only when the version number corresponds, the submitted offset is considered to be valid and the submission will be received
2. Group member crash / abnormal exit:
If a consumer goes down, it will rebalance and reassign the partition
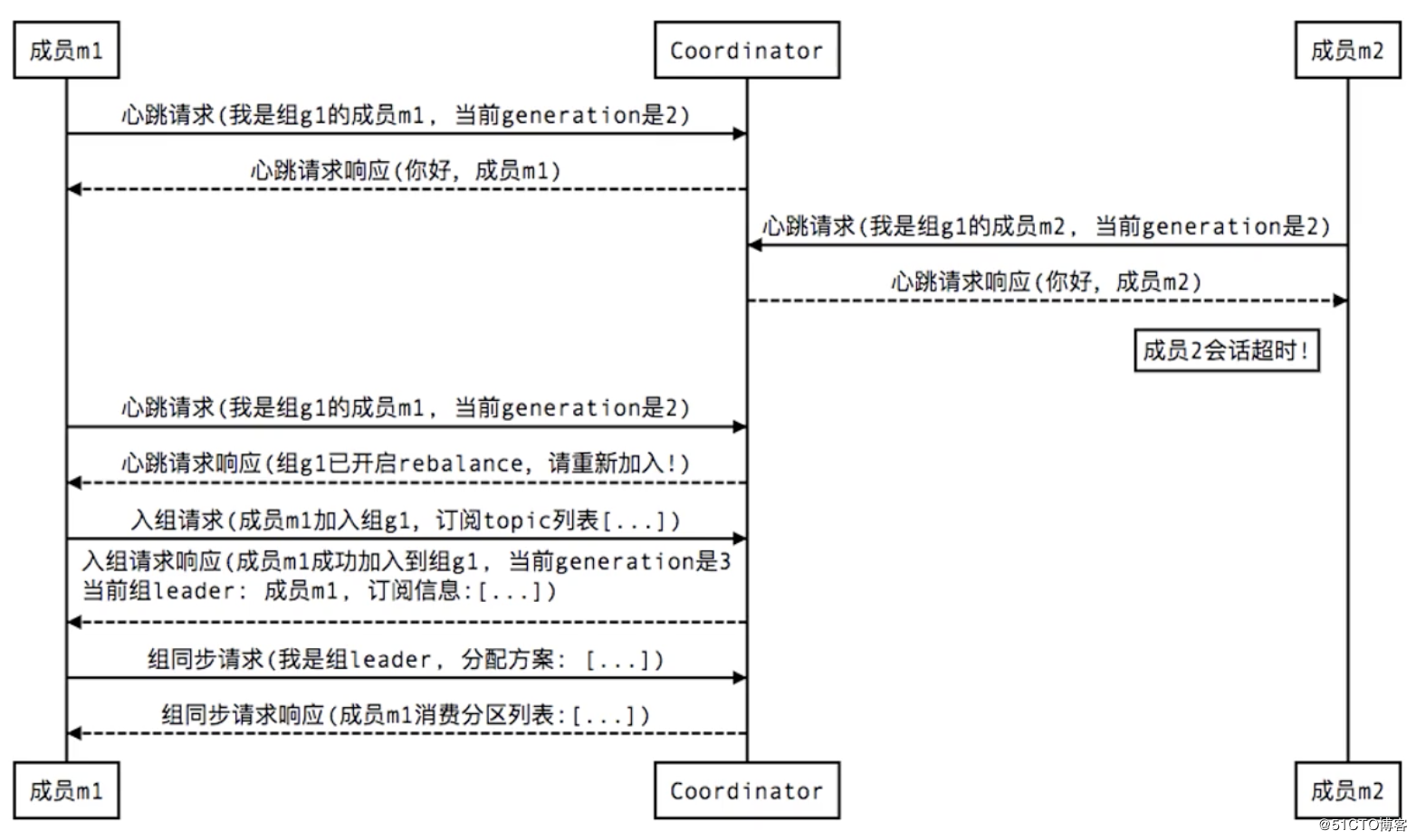
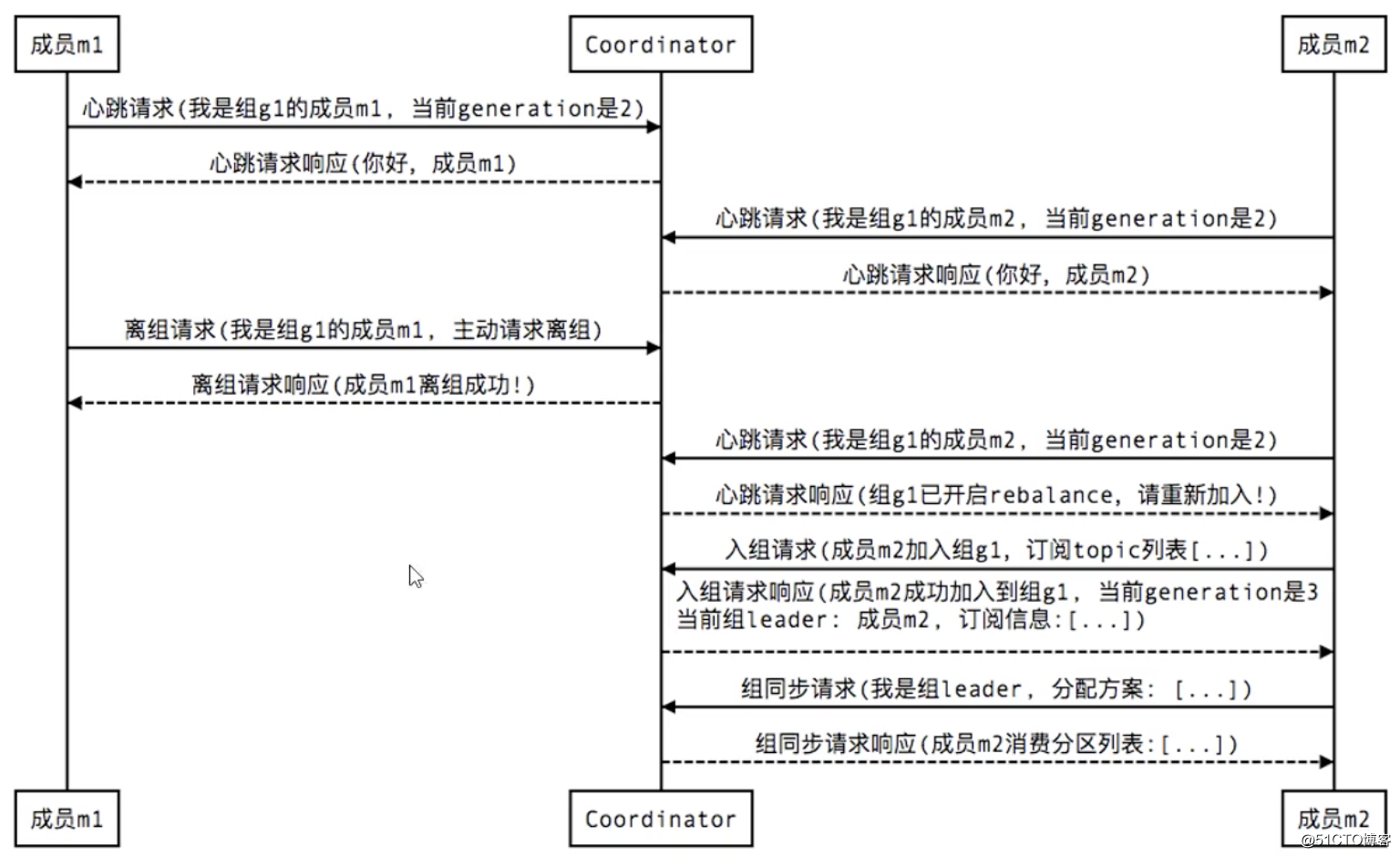
3. member leave group:
4. When the Consumer submits a member commit offset, there will be a similar interaction process:
If the offset is not submitted successfully, but the business is done again, it may lead to repeated consumption
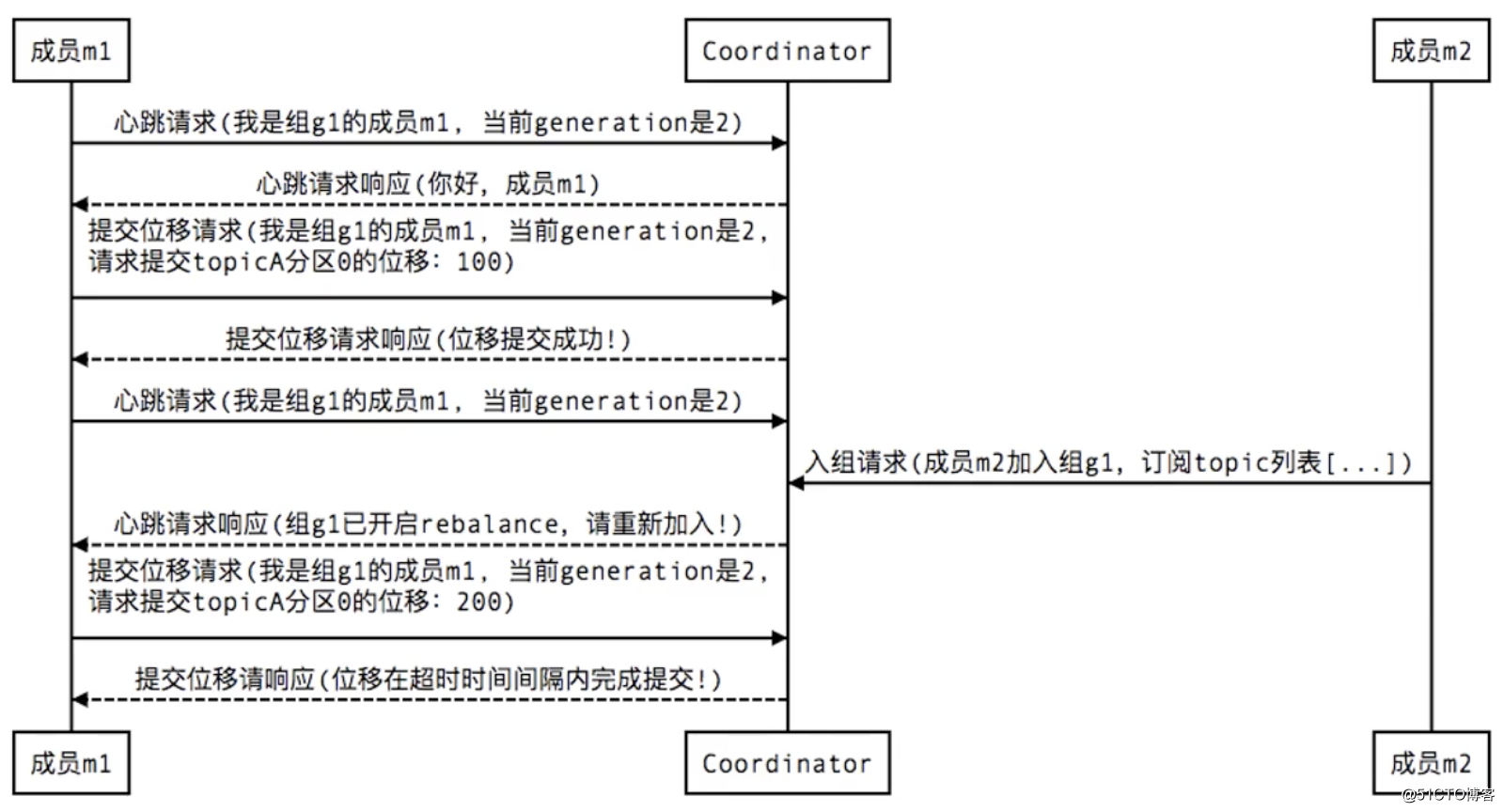
References:
- https://javaguide.cn/high-availability/limit-request/
- https://www.orchome.com/451#item-9
- https://blog.csdn.net/weixin_33797791/article/details/88003844?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase
- https://blog.51cto.com/zero01/2498017
- https://www.cnblogs.com/yangxusun9/p/13049132.html
(blogging is mainly to summarize and sort out their own learning. Most of the materials come from books, online materials and their own practice. It is not easy to sort out, but there are inevitable deficiencies. If there are mistakes, please criticize and correct them in the comment area. At the same time, thank the bloggers and authors for their hard sorting out resources and shared knowledge.)