The purpose of this article is to make readers have a concrete understanding of namespace and cgroup. Of course, due to my limited knowledge of Linux, I can't go deep.
"Container is an execution environment that shares the kernel with the host system but is isolated from other process resources in the operating system", which is the core of understanding container technology. A container is an environment in which the processes running are the same as other processes in the operating system and enjoy the same hardware resources. The only difference is that the processes in the environment cannot see the existence of other processes and the operations will not affect each other, that is, the so-called isolation; The operation of multiple containers is to run their own processes in their own isolated environment.
Container is just an abstract logical concept. Those with the above characteristics can be called containers. The implementation of these characteristics depends on the namespace and cgroup provided by the Linux operating system. Namespace provides resource isolation to ensure that resource operations before different namespaces do not affect each other; Cggroup provides resource limits to ensure that the resource usage in a group will not exceed the preset.
namespace
Resource isolation, a complete running environment, that is, a so-called container, what resources need to be isolated? There are roughly the following categories
- Isolated file system: file operations do not affect each other
- Isolated network: the container needs to have independent IP, port, routing rules, etc
- Isolate hostname: the container needs to identify itself in the network
- Isolate interprocess communication: message queue, shared memory, etc
- Isolate user permissions: there should be complete user permissions in the container
- Isolation PID: the PID in the container needs to be isolated from the PID of the host machine
For each category, Linux provides isolation support on namespaces, that is, there are six different types of namespaces, each corresponding to different resources.
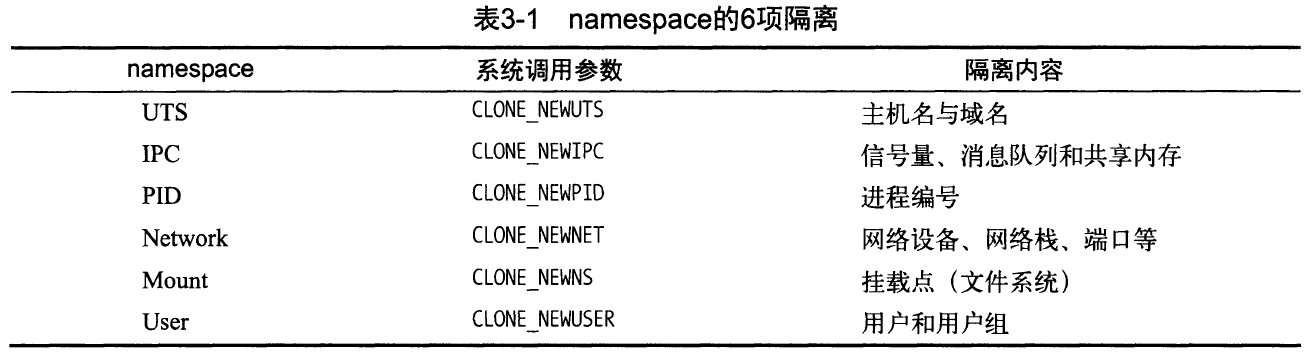
The purpose of namespace is to realize "lightweight virtualization service" (i.e. container), which is supported at the kernel level. Processes in the same namespace can be perceived and visible to each other; Processes in different namespaces can't see each other at all, just like in an independent operating system.
To start a container, you only need to create the process of the container in a new namespace. For this, Linux provides support through API
- clone(): create a separate namespace process
- setns(): add the current process to an existing namespace
- unshare(): resource isolation is performed on the original process, that is, the original process is still in the original namespace, but its created child processes are in the new namespace
To this end, we can write a simple code to experience and verify resource isolation, including the following c code
// namespace.c
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
// In the new process
int child_main(void* args) {
printf("In child processes!\n");
// Set new hostname
sethostname("NewNamespace", 12);
// Execute Bash and enter the bash console. Only when we enter exit will we exit the bash program and end the current function
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("Program start: \n");
// Create a sub process, and the sub process performs comprehensive resource isolation
int child_pid = clone(child_main, child_stack + STACK_SIZE,
CLONE_NEWIPC |
CLONE_NEWUTS |
CLONE_NEWPID |
CLONE_NEWNS |
CLONE_NEWNET |
CLONE_NEWUSER |
SIGCHLD, NULL);
printf("%d", CLONE_NEWUTS);
// Wait for the child process to end
waitpid(child_pid, NULL, 0);
printf("Exited \n");
return 0;
}
Compile and execute under linux (Note: root is required to execute successfully)
# Compile and execute root@10-9-175-15:/home/ubuntu/docker-learn# gcc -Wall namespace.c -o namespace.o && ./namespace.o Program start: In child processes! # Output current process number nobody@NewNamespace:/home/ubuntu/docker-learn$ echo $$ 1 # Exit bash and the process exits nobody@NewNamespace:/home/ubuntu/docker-learn$ exit exit 67108864 Exited
As you can see, in the new process
- The user name has changed from root to nobody, and the user has been isolated
- The hostname becomes the NewNamespace set by ourselves, indicating that the hostname is isolated
- The process number is 1, indicating that the PID is isolated. PID=1 is very important in Linux. It is called init process. It has privileges and plays a special role
Other resource isolation also has corresponding verification methods, but it does not hinder understanding, so we won't go into it here. However, from this, we can imagine that container implementations such as docker, containerd and runc create processes in an isolated namespace based on calls like the above.
cgroup
namespace is responsible for resource isolation, but the resources in different namespaces cannot be consumed indefinitely. Otherwise, it is easy to run out of resources due to bug s or malicious attacks of programs in the container, threatening the processes of other containers. Therefore, resource constraints are required, which requires cgroup. cgroup can not only limit resources, but also record resource usage statistics (this function can be used to charge cloud services), but also suspend and restore tasks.
There are several concepts in cgroup:
-
Task: task that identifies a process
-
cgroup: control group, which refers to a task group divided according to a certain resource control standard, and can contain one or more subsystems
-
Subsystem: subsystem, i.e. resource scheduling controller, such as CPU subsystem and memory subsystem. In detail, docker uses the following
- blkio: set input and output limits for block devices, such as disks
- cpu: scheduling of cpu
- cpuacct: automatically generate reports on CPU resource usage of tasks in cgroup
- cpuset: independent cpu and memory can be allocated for tasks in cgroup
- Devices: turn on or off the access of tasks in cgroup to devices
- freezer: suspend or resume tasks in cgroup
- Memory: set the memory usage limit of tasks in cgroup and generate their memory resource usage report
- perf_event: enables tasks in cgroup to conduct unified performance testing
- net_cls: it marks network packets with a hierarchy identifier to allow Linux traffic control programs to identify packets generated from specific cgroup s
-
hierarchy: hierarchical relationship, consisting of a series of cgroup s in a tree structure
We can see how many subsystems the current system has
root@10-9-175-15:/home/ubuntu/docker-learn# mount -t cgroup cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
You can see that each subsystem corresponds to a folder on the file system. Let's take a look at the cgroup of a running docker container:
When you view the docker container running locally, you can see a container with id ee4a4efd4a5b
root@10-9-175-15:/home/ubuntu/docker-learn# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ee4a4efd4a5b halohub/halo "/bin/sh -c 'java -X..." 10 months ago Up 22 hours 0.0.0.0:8090->8090/tcp, :::8090->8090/tcp halo
View the corresponding cpu limit configuration in / sys / FS / CGroup / cpu / docker / ee4a4efd4a5b2a9a6e8154bc4336bf2a7f1528205e9f53adb8443868add7eeb
root@10-9-175-15:/sys/fs/cgroup/cpu/docker/ee4a4efd4a5b2a9a6e8154bc4336bf2a7f1528205e9f53adb8443868adad7eeb# ls cgroup.clone_children cpuacct.usage cpuacct.usage_percpu_sys cpuacct.usage_user cpu.shares cpu.uclamp.min cgroup.procs cpuacct.usage_all cpuacct.usage_percpu_user cpu.cfs_period_us cpu.stat notify_on_release cpuacct.stat cpuacct.usage_percpu cpuacct.usage_sys cpu.cfs_quota_us cpu.uclamp.max tasks root@10-9-175-15:/sys/fs/cgroup/cpu/docker# tree ee4a4efd4a5b2a9a6e8154bc4336bf2a7f1528205e9f53adb8443868adad7eeb ee4a4efd4a5b2a9a6e8154bc4336bf2a7f1528205e9f53adb8443868adad7eeb ├── cgroup.clone_children ├── cgroup.procs ├── cpuacct.stat ├── cpuacct.usage ├── cpuacct.usage_all ├── cpuacct.usage_percpu ├── cpuacct.usage_percpu_sys ├── cpuacct.usage_percpu_user ├── cpuacct.usage_sys ├── cpuacct.usage_user ├── cpu.cfs_period_us ├── cpu.cfs_quota_us ├── cpu.shares ├── cpu.stat ├── cpu.uclamp.max ├── cpu.uclamp.min ├── notify_on_release └── tasks
You can see that there are many files, and each file corresponds to a CPU configuration or monitoring value. Note that the tasks file is a task managed by cgroup. Check any one, such as cpu.cfs_quota_us, the CPU quota. The default is - 1, which means there is no limit
root@10-9-175-15:/sys/fs/cgroup/cpu/docker/ee4a4efd4a5b2a9a6e8154bc4336bf2a7f1528205e9f53adb8443868adad7eeb# cat cpu.cfs_quota_us -1
Of course, we can add our own processes to cgroup for restriction. The method is to create a folder in the corresponding subsystem file, and the system will automatically add the above configuration file under the folder. We can add tasks to tasks and add configuration to the specified file.
I won't describe it specifically. You can refer to it This article and Official manual.
ending
It can be seen that with namespace and cgroup, the process creation is no different from the usual process creation, and the resulting container is very lightweight. Container and process creation can be compared with Ctrip and method call. They all use ordinary methods to achieve the goal of light weight and fast.
Anyway. Whenever you read these contents, you will feel the lack of Linux knowledge. Therefore, it is necessary to learn Linux. The most important ones are process management, Linux network, file system, etc.