urllib
urllib is a built-in HTTP request Library in python. I don't think it's commonly used now. It's not easy to use, but I know the basis of crawlers
Four modules
- urllib.request: request module
- urllib.error: exception handling module (ensure that the program will not terminate unexpectedly)
- urllib.parse: url parsing module (split, merge, etc.)
- urllib.robotparser : robots.txt parsing module
Request module urlopen
get request from urlopen
Send requests to the server:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
#Output Baidu home page source code
import urllib.request
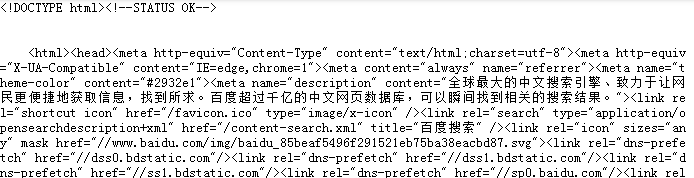
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
post request for urlopen
import urllib.parse
import urllib.request
#The data parameter needs to be passed in (the following is the test)
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())

(the result is also the source code for reading the web page. To understand, the post request needs to pass in parameters)
Timeout timeout setting
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://www.baidu.com', timeout=0.01)
'''Must be at 0.01s Get this response. If not, throw an exception'''
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout): #Judge the cause of e. if the timeout is abnormal, print it out
print('TIME OUT')
#Here is just a test. The time of 0.01s is too short to output TIME OUT without such a fast response
Output: TIME OUT
Response response
Response type
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(type(response)) #type of output
<class 'http.client.HTTPResponse'>
Status code, response header
Flag to judge whether the response is successful
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.status,'\n') #Get status code
print(response.getheaders(),'\n') #Get the response header. Array form
print(response.getheader('Server')) #Gets a specific response header.
#What is the Server used to get this web page

response.read() response body
import urllib.request
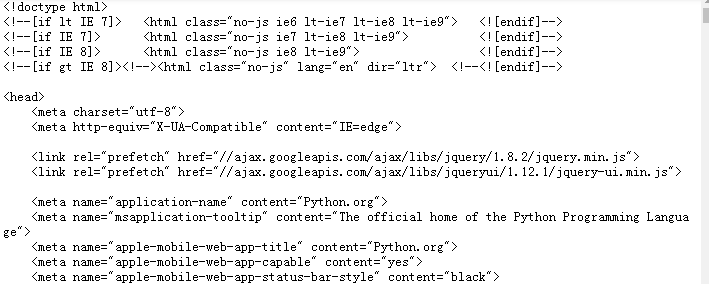
response = urllib.request.urlopen('https://www.python.org')
'''Get the content of the response body'''
print(response.read().decode('utf-8'))
#Encoding conversion is required for calling decode
More complicated Request
Urlopen does not provide parameters such as headers. If we want to send some more complex requests, we can use urlopen to send a request object, which also belongs to urllib Request module, where you can directly declare a request object and pass in the url
import urllib.request
req = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(req)
print(response.read().decode('utf-8'))
Handler
agent
Camouflage your own IP address. The server recognizes it as a proxy IP and can switch IP. What the server recognizes is requests from different regions, so it won't block the crawler. Deal with anti climbing
(not here, just an example)
import urllib.request
proxy_handler = urllib.request.ProxyHandler({
'http': 'http://127.0.0.1:9743',
'https': 'https://127.0.0.1: 9743 '# set proxy (not here)
})
'''structure opener'''
opener = urllib.request.build_opener(proxy_handler)
response = opener.open('http://www.baidu.com')
print(response.read())
Cookie
A text file saved on the client to record the user's identity. When crawling, cookie s are mainly a mechanism used to maintain login status.
Click Taobao, log in to the account, clear the cookie information in the developer tool Application, refresh the web page, and the account has exited. That is, cookies can maintain login information and login status
import http.cookiejar, urllib.request
#First declare it as a CookieJar object
cookie = http.cookiejar.CookieJar()
#Handle cookie s with the help of handler
handler = urllib.request.HTTPCookieProcessor(cookie)
#Build opener and open Baidu web page
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
#Traversal printing
for item in cookie:
print(item.name+"="+item.value) #Print the name and value of the cookie

Cookies can be saved
It can be saved as a text file. If it is not invalid, it can be read from it again and continue to maintain the login status when requesting
import http.cookiejar, urllib.request
filename = "cookie.txt"
#Declared as a subclass object of CookieJar, save can be called
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
#Locally generated cookie file
#Another form of preservation
import http.cookiejar, urllib.request
filename = 'cookie.txt'
cookie = http.cookiejar.LWPCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
exception handling
'''Request a website that does not exist'''
from urllib import request, error
try:
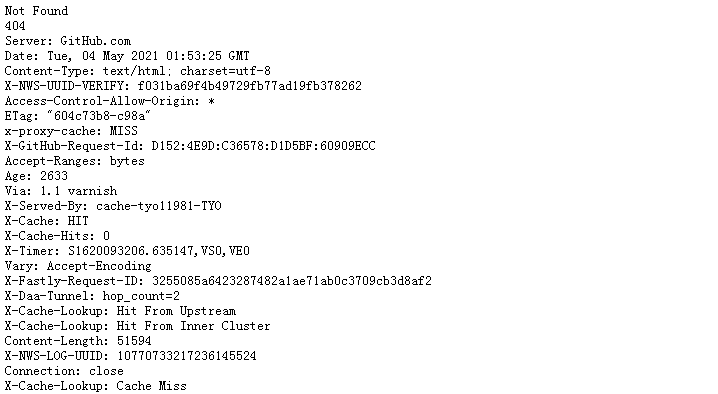
response = request.urlopen('http://cuiqingcai.com/index.htm')
except error.URLError as e:
print(e.reason) #Catch exception and print reason
Output: Not Found
What exceptions can be caught?
Baidu urllib Python 3 search official documents
from urllib import request, error
try:
response = request.urlopen('http://c.com/index.htm')
except error.HTTPError as e: #First, catch subclass exceptions
print(e.reason,e.code,e.headers,sep='\n')
except error.URLError as e: #Catch the parent class exception again
print(e.reason)
else:
print('Request Successfully')
#Error reason
#Status code
#response.headers information
##Description error is an http error
- Verify the reason with isinstance (small application)
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('https://www.baidu.com', timeout=0.01)
except urllib.error.URLError as e:
print(type(e.reason))
if isinstance(e.reason, socket.timeout):
print('TIME OUT')
URL resolution URL parse
urlparse segmentation
Divide the incoming url and divide each part
Type, domain name, path, parameter, query, fragment - 6 parts, standard structure
If you need to split the url, you can call this function directly
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result), result)

'''No, scheme'''
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result) #The default scheme is https
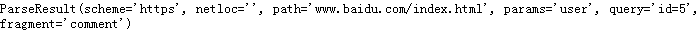
- allow_fragments parameter
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', scheme='https')
print(result)
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False)
print(result)
#Splice to the previous query section
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5#comment', fragment='')
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html#comment', allow_fragments=False)
print(result)
#Forward splicing
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html#comment', params='', query='', fragment='')
urlunparse splice
from urllib.parse import urlunparse data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment'] print(urlunparse(data))
http://www.baidu.com/index.html;user?a=6#comment
urljoin splice
Based on the latter, some of the latter will replace the former, and those not in the latter will be supplemented by the former
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com', 'FAQ.html'))
print(urljoin('http://www.baidu.com', 'https://c.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://c.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html', 'https://c.com/FAQ.html?question=2'))
print(urljoin('http://www.baidu.com?wd=abc', 'https://c.com/index.php'))
print(urljoin('http://www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com#comment', '?category=2'))

urlencode
Convert dictionary object to get request parameter
from urllib.parse import urlencode
params = {
'name': 'germey',
'age': 22
}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)
http://www.baidu.com?name=germey&age=22