I. Detailed Framework

Scrapy is a popular python event-driven network framework written by Twisted, which uses non-blocking asynchronous processing.
[1] The role of internal components
** Scrapy Engine (scrapy engine): ** is used to control the data processing flow of the whole system and trigger transaction processing.
** Scheduler (Scheduler): ** is used to receive requests from the engine, press them into the queue, and return them when the engine requests again. It's like a priority queue of URLs, where it decides what to crawl next, and where duplicate URLs are removed.
Downloader: ** Used to download web content and return it to Spiders [Scrapy Downloader is built on Twisted, an efficient asynchronous model]
** Spiders: (Reptiles): ** Reptiles mainly work to crawl information they need from specific web pages, namely, so-called entities, and also extract URL s from them so that Scrapy can continue to crawl the next page.
** Pipeline (Project Pipeline): ** Handles entities crawled from web pages by crawlers. Its main function is to persist entities, verify their validity and remove unwanted information. When the page is parsed by the crawler, it is sent to the project pipeline and processed in several specific orders.
** Downloader Middlewares (Downloader Middleware): ** The framework between scrapy engine and downloader mainly deals with requests and responses between scrapy engine and downloader. Setting proxy ip and user proxy can be set here.
** Spider Middlewares (crawler middleware): ** The framework between scrapy engine and crawler, the main task is to deal with crawler response input and request output.
** Scheduler Middlewares (Scheduler Middleware): ** The framework between scrapy engine and scheduler is mainly used to process requests and responses sent from scrapy engine to scheduler.
[2] Scrapy Running Process
- The engine fetches a URL from the scheduler for subsequent fetches
- The engine encapsulates the URL as a Request and passes it to the downloader
- The Downloader Downloads the resources and encapsulates them as a Response.
- Reptilian Resolution Response
- What is parsed out is the entity, which is handed over to the Pipeline for further processing.
- The parsed link (URL) is handed over to the scheduler to wait for the next fetch.

II. Project Cases
Film and TV Information Collection and Analysis Based on Scrappy Framework
Project introduction
In order to make full use of the large data resources on the Internet and make the users easily use the film and television information, crawler technology based on Skapy framework is adopted.
hair
Search engine to retrieve movie information. Douban website for video information crawling, in order to facilitate users to accurately access the latest film information.
Project code
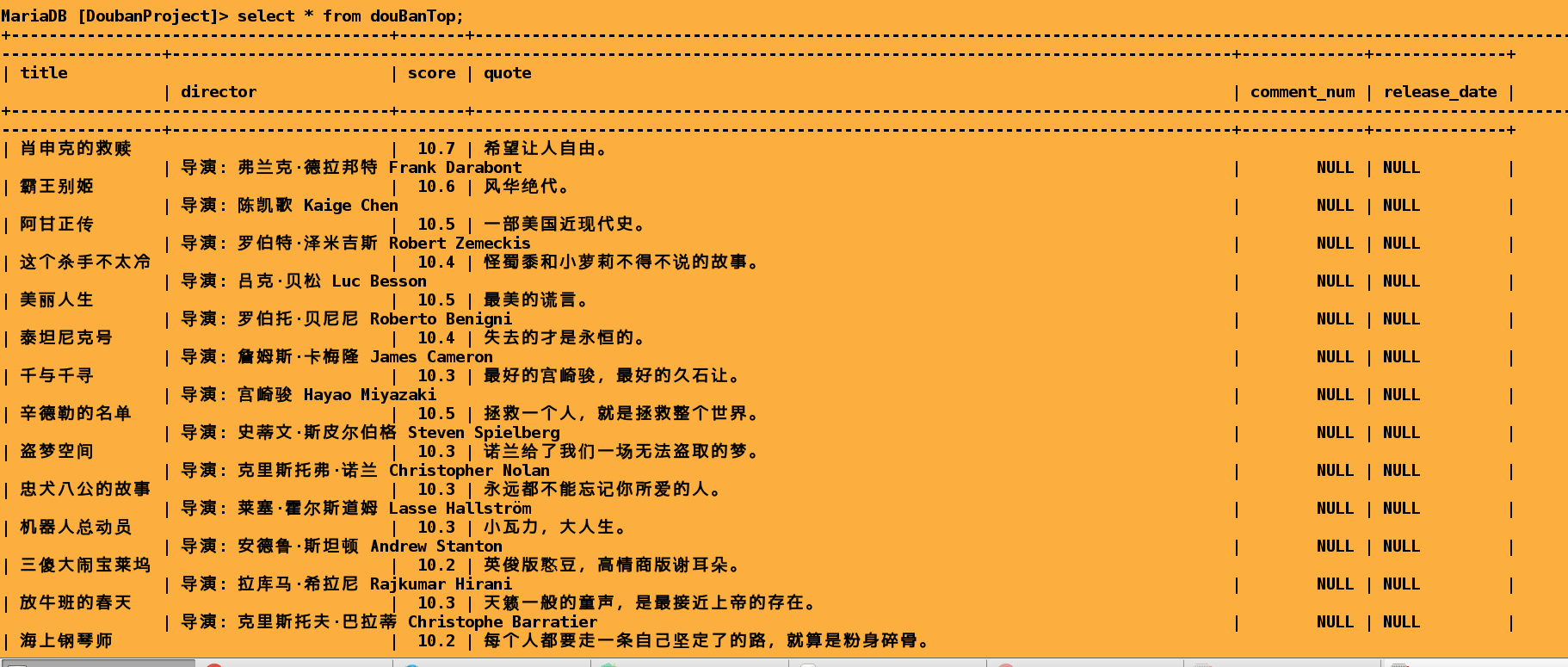
Take "Douban Movie" as the crawling target, crawl the movie and television information in the website. Mainly includes the website ranking "Top250" and comedy, action movies
Film title, film rating, film director, film release time and film reviews.
[1] Creating Engineering
scrapy startproject Douban
[2] Create a crawler program
cd Douban/ scrapy genspider douban 'douban.com'
The crawler framework automatically creates directories and files
[3] Determine the crawling target "item.py"
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()#Film Name
score = scrapy.Field()#Film Scoring
quote = scrapy.Field()#Movie Review
director =scrapy.Field()#Film Director
release_date = scrapy.Field() #Show time
comment_num = scrapy.Field()#Number of comments
image_url = scrapy.Field()#url address of movie pictures
detail_url = scrapy.Field() #Film Details Page Information
image_path =scrapy.Field() #Downloaded Cover Local Storage Location
[4] Change the setting configuration file.
1. Adding Useragent and Prohibiting Crawler Protocol
# Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'Douban (+http://www.yourdomain.com)' #Setting up Random User Agent from fake_useragent import UserAgent ua =UserAgent() USER_AGENT = ua.random # Obey robots.txt rules # ROBOTSTXT_OBEY = True ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
# 'Douban.pipelines.DoubanPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 1,
'scrapy.pipelines.files.FilesPipeline': 2,
'DouBan.pipelines.MyImagesPipeline': 2,
'DouBan.pipelines.DoubanPipeline': 300,
'DouBan.pipelines.JsonWriterPipeline': 200, # The smaller the number, the earlier the execution.
'DouBan.pipelines.AddScoreNum': 100, # Processing the crawled data and saving it after processing.
'DouBan.pipelines.MysqlPipeline': 200, # Processing the crawled data and saving it after processing.
}
FILES_STORE ='/tmp/files'
IMAGES_STORE = '/tmp/images'
IMAGES_EXPIRES = 30
# Picture thumbnails
IMAGES_THUMBS = {
'small': (250, 250),
'big': (270, 270),
}
# Image filter, minimum height and width
IMAGES_MIN_HEIGHT = 110
IMAGES_MIN_WIDTH = 110
2. Setting up pipeline,
When Item is collected in Spider, it will be passed to Item Pipeline, which is processed by Item Pipeline components in the defined order.
Each Item Pipeline is a Python class that implements simple methods, such as deciding that the Item is discarded and stored. The following are some typical applications of item pipeline:
1. Verify crawled data (check that item contains certain fields, such as name field)
2. Check (and discard)
3. Store crawl results in files or databases
Here I process the crawled data (plus 1), then store it in mysql database, get the picture and download it.
import json
import pymysql
import scrapy
from scrapy.exceptions import DropItem
class DoubanPipeline(object):
def process_item(self, item, spider):
return item
class AddScoreNum(object):
"""Add one to the original score"""
def process_item(self,item,spider):
if item['score']:
score = float(item['score'])
item['score'] = str(score + 1)
return item
else:
raise Exception("Not crawling to score")
class JsonWriterPipeline(object):
"""Open the file object before the crawler, close the file object after the crawler"""
def open_spider(self, spider):
self.file = open('douban.json', 'w')
def process_item(self, item, spider):
# dict(item): Convert item objects into Dictionaries
# json.dumps: serialize dictionaries into json strings;
# indent=4: Storage is indented to 4;
# ensure_ascii=False: Solving the Chinese scrambling problem
line = json.dumps(dict(item), indent=4, ensure_ascii=False)
self.file.write(line)
return item
def close_spider(self, spider):
self.file.close()
class MysqlPipeline(object):
"""To write MySQL Storage plug-in"""
def open_spider(self, spider):
# Connect to the database
self.connect = pymysql.connect(
host='127.0.0.1', # Database Address
port=3306, # Database Port
db='DoubanProject', # Database name
user='root', # Database username
passwd='westos', # Database password
charset='utf8', # Coding method
use_unicode=True,
autocommit=True
)
# Added, deleted, and modified through cursor -- cursor
self.cursor = self.connect.cursor()
self.cursor.execute("create table if not exists douBanTop("
"title varchar(50) unique, "
"score float , "
"quote varchar(100), "
"director varchar(100), "
"comment_num int, "
"release_date varchar(10));")
def process_item(self, item, spider):
insert_sqli = "insert into douBanTop(title, score, quote,director) values ('%s', '%s', '%s', '%s')" % (
item['title'], item['score'], item['quote'], item['director'],)
print(insert_sqli)
try:
self.cursor.execute(insert_sqli)
# Submit sql statement
self.connect.commit()
except Exception as e:
self.connect.rollback()
return item # Return must be achieved
def close_spider(self, spider):
self.connect.commit()
self.cursor.close()
self.connect.close()
class MyImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info): # A single item object;
#Automatically retrieve requests and download images
print("item: ", item)
yield scrapy.Request(item['image_url'])
def item_completed(self, results, item, info):
"""
:param results:
[(True, {'url': 'https://img3.doubanio.com/view/photo/s_ratio_poster/public/p1454261925.jpg',
'path': 'full/e9cc62a6d6a0165314b832b1f31a74ca2487547a.jpg',
'checksum': '5d77f59d4d634b795780b2138c1bf572'})]
:param item:
:param info:
:return:
"""
# for result in results:
# print("result: ", result)
image_paths = [x['path'] for isok, x in results if isok]
# print("image_paths: ", image_paths[0])
if not image_paths:
raise DropItem("Item contains no images")
item['image_path'] = image_paths[0]
return item
[5] compiling spider "douban.py"
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from Douban.items import DoubanItem
class DoubanSpider(scrapy.Spider):
#Reptilian name, not repeatable
name = 'douban'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/',
'https://movie.douban.com/top250']
url ='https://movie.douban.com/top250'
def parse(self, response):
item =DoubanItem()
#<ol class="grid_view">
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
#Film Name <span class="title">Shawshank's Redemption</span>
item['title'] = movie.xpath('.//span[@class="title"]/text()').extract()[0]
#Film Scoring
item['score'] = movie.xpath('.//span[@class="rating_num"]/text()').extract()[0]
#Movie Review
quote = movie.xpath('.//span[@class="inq"]/text()').extract()
item['quote'] = quote[0] if quote else ''
#Film Director
info = movie.xpath('.//div[@class="bd"]/p/text()').extract()
director = info[0].split('To star')[0].strip()
item['director'] = director
#url address of movie pictures
item['image_url'] = movie.xpath('.//div[@class="pic"]/a/img/@src').extract()[0]
# Film Details Page Information
item['detail_url'] = movie.xpath('.//div[@class="hd"]//a/@href').extract()[0]
yield item
#<a href="? Start=25& filter="> back page & gt;"</a>
nextLink = response.xpath('.//Span [@class= "next"]/ link /@href'. extract ()# returns a list
if nextLink:
nextLink = nextLink[0]
print('Next Link: ', nextLink)
yield Request(self.url + nextLink, callback=self.parse)