requirement:
Get the movie information of Douban top250, including:
ranking
name
country
particular year
director
score
Number of raters
type
Slogan
Save the movie information in a file called movie Txt file
Idea:
1. Get the source code with requests
2. Obtain information with re
3. Store the obtained data in movie Txt
Example browser: chrome
1. Forerunner warehousing, define url(requests should be installed in advance, instruction pip install requests, how to download Baidu without pip)
import requests import re import os import time # os and time modules will be used at that time url = "https://movie.douban.com/top250"
2. Open the browser, enter the Douban page (movie.douban.com/top250), press f12, and the following interface will appear:
Then, locate the network and click Open:
Click an item randomly (refresh if not), find the user agent in the "header" and save it. The next step is to use:
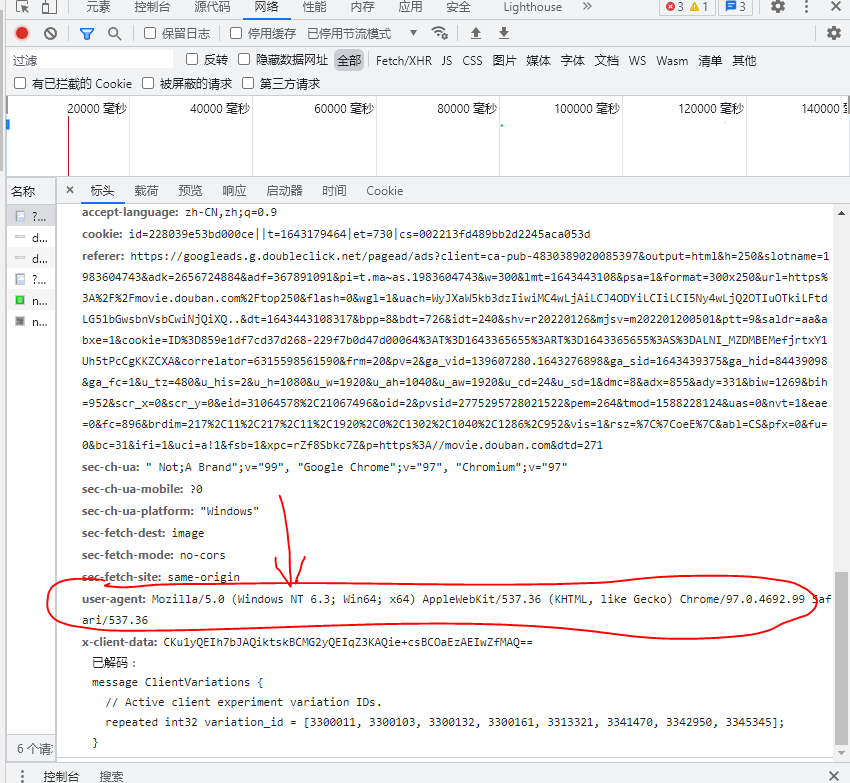
3. Because Douban has an anti crawling mechanism, we need to manually specify headers: the code is also very simple. Just copy the above user agent (the headers of different systems are different and need to be viewed by ourselves)
headers = {
"user-agent":
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}Next, we need to check the request method of the web page. The request method is divided into get and post, which is shown in the user agent
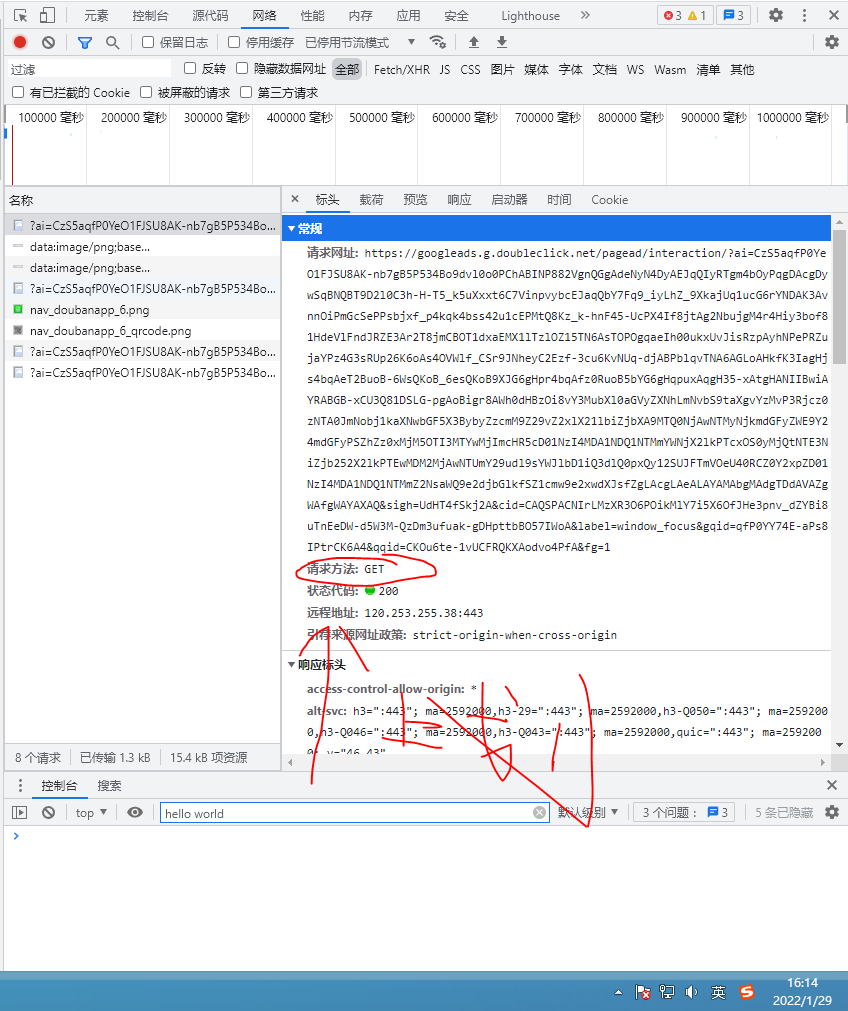
You can see that Douban is the get request method. OK, let's get the web page source code requests Get (URL address, your headers). Because the return value of the get method is not text, we use the text method + a variable to save the source code text
resp = requests.get(url, headers=headers) page_content = resp.text # page_content save source code
3. After the above methods are completed, the most difficult regular expression of re will come, but I will try to make it clear~
Go back to the browser, refresh the web page, and pull up to see an item called "top250". Open it
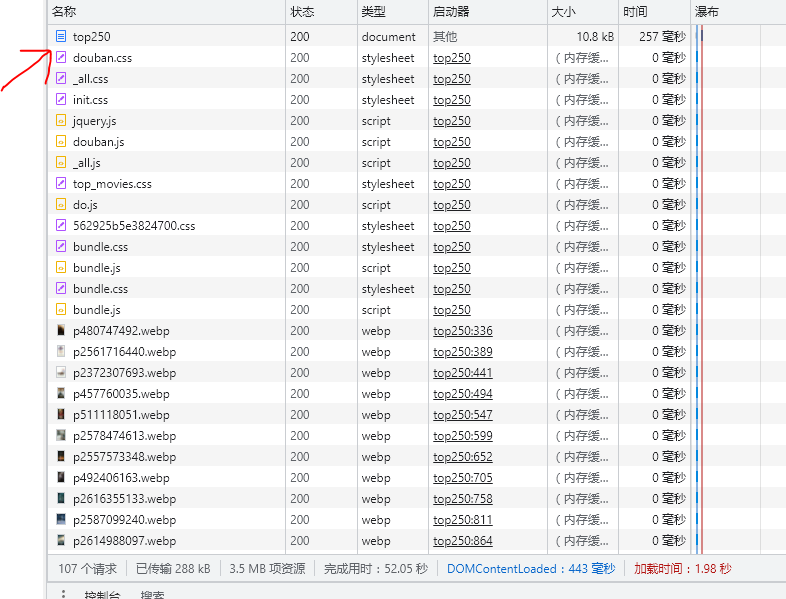
After opening, click "response", switch to the web page source code, and press ctrl+shift+f to open the search box
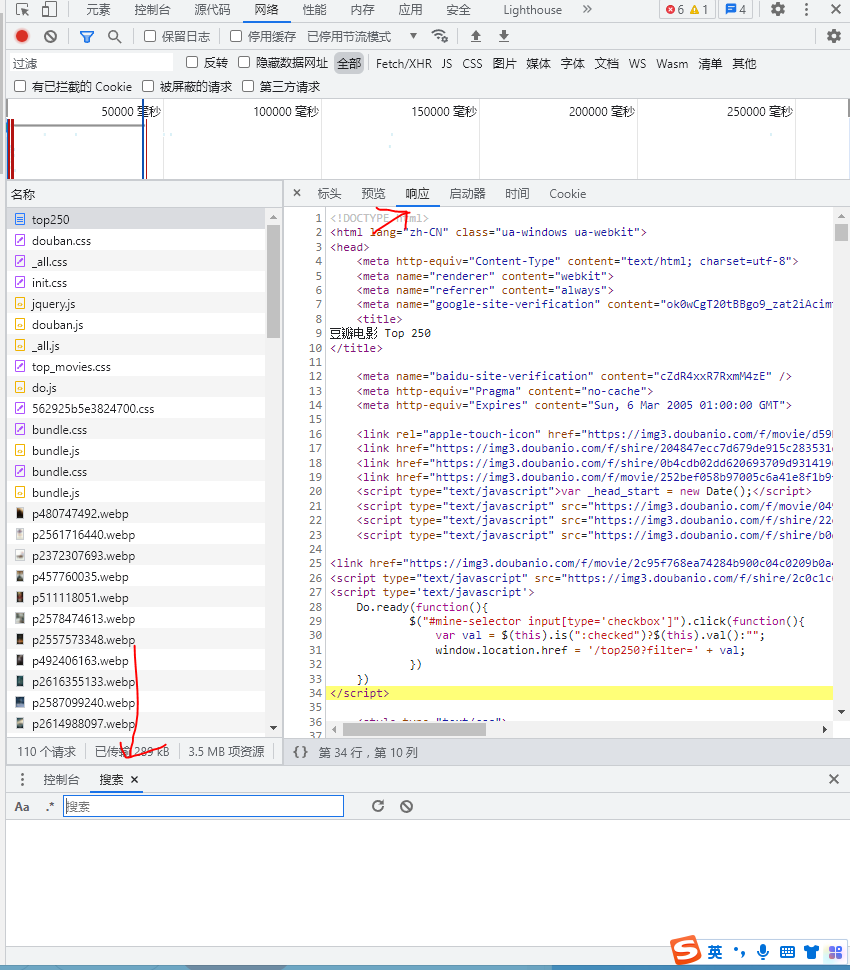
Then, let's look at the regular symbols we'll encounter this time
(one) .*? This identifier will not be understood as jumping from the content in front of the identifier to the content behind the identifier Take a chestnut: "Brother, do you have time to play games?Is brother there,Play games,It's on tonight?Hello, Hello, hello,Are you there,Play the game?" here,If your regular expression is: brother.*?Game words That matches: Brother has time to play games Not anything else,Even in the back? They don't match Can you understand? (two) ?P This identifier is easy to understand,Just think of it as a data type,Format is(?P<name>content) Take the example above,If you want to get the identifier.*?Content in,that is"Call when you have time"This string,Then we can write that: brother(?P<string>.*?)game So our<string>The middle part is successfully stored in the middle part~ As for how to output, I'll talk about it later
After understanding, let's get the information of the movie and search the name of a movie in the search box (here I take the first one as an example):
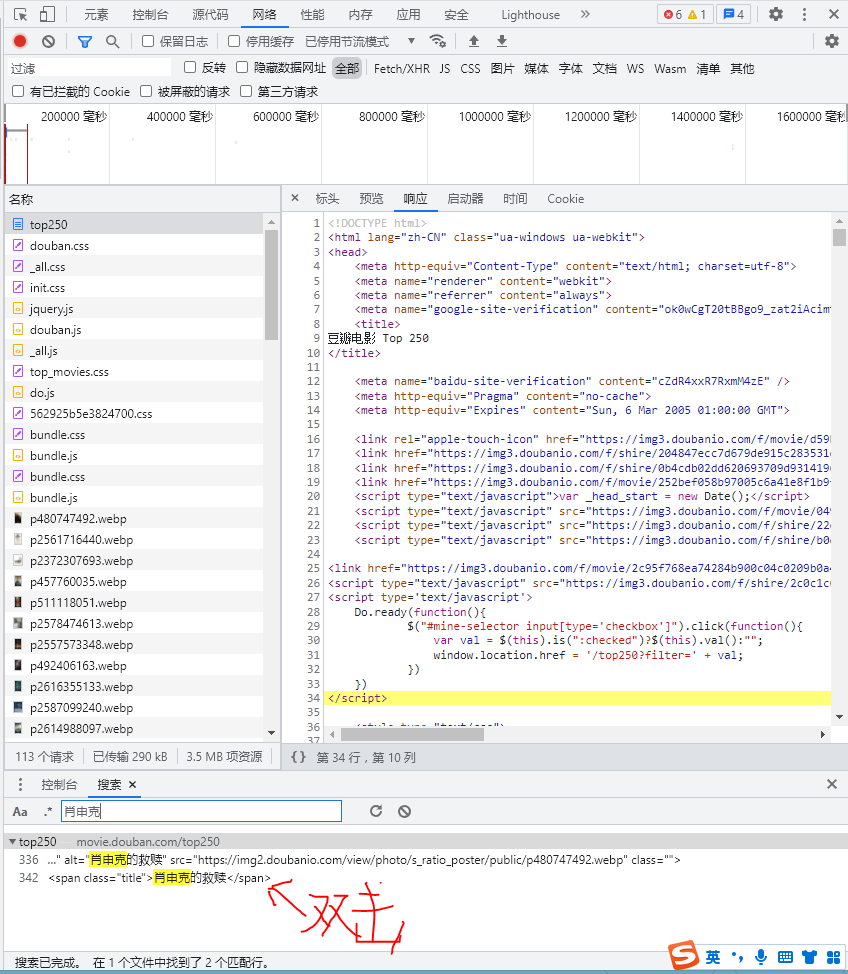
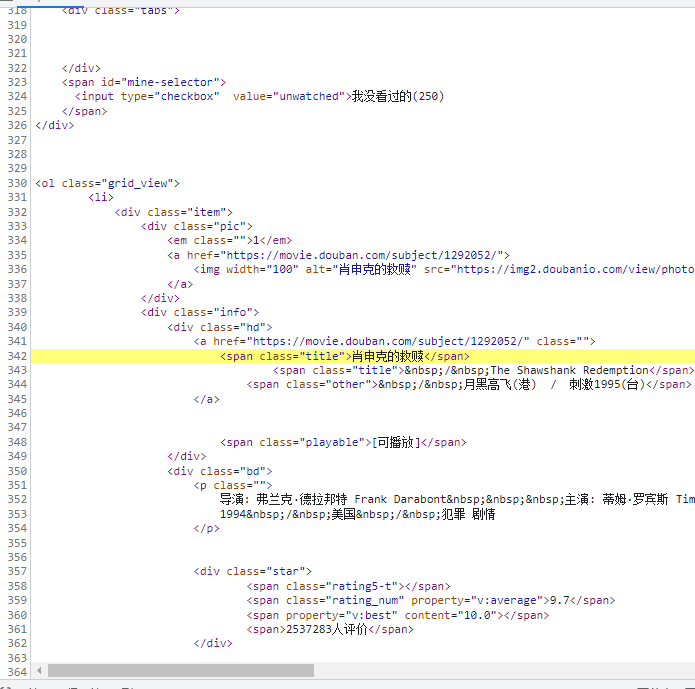
Then, we found that all the data of the film is here. Using the previous two identifiers, we can write these regularities
I wrote it for reference only In order to pretend to force me to have a clearer idea, I wrote more than 100 million unnecessary words
obj = re.compile('<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?'
'<div class="bd">.*?<p class="">(?P<dy>.*?) .*?<br>(P<year>.*?) '
'.*?/ (?P<country>.*?) .*? (?P<lx>.*?)</p>'
'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
'.*?<span>(?P<people>.*?)</span>'
'.*?</div>.*?<span class="inq">(?P<xcy>.*?)</span>', re.S)Use the finder method in obj to obtain the result, and save the same variable
result = obj.finditer(page_content)
When writing to a file, to access variables such as name and dy in obj, use group("variable name") method
Here, I defined an s=0 at the beginning to calculate the ranking
with open("movie.txt", mode="a", encoding="utf-8") as f:
for it in result:
s+=1
f.write("ranking:"+str(s)+"\n")
f.write("Movie title:"+it.group("name").strip()+"\n")
f.write("country:"+it.group("country").strip()+"\n")
f.write("particular year:"+it.group("year").strip()+"\n")
f.write(it.group("dy").strip()+"\n")
f.write("score:"+it.group("score").strip()+"\n")
f.write("Number of raters:"+it.group("people").strip()+"\n")
f.write("type:"+it.group("lx").strip()+"\n")
f.write("Slogan:"+it.group("xcy").strip()+"\n")
f.write("----------------------------------\n")
f.write("\n")
print("Successfully crawled", s, "Item movie information")Don't forget to turn off resp, or it will be blocked
resp.close()
But then we will find a problem in movie Txt contains only one page. At this time, don't think you have a problem with your code. Switch to the next page to see the address bar:


See? The start value increases by 25 for each page, so let's rewrite the beginning and remember to indent the following code
for i in range(10):
a = i * 25
url = "https://movie.douban.com/top250?start="+str(a)+"&filter="
That's no problem!
Then, we just need to polish the code a little
Because we use the "a" append mode when writing, if we write multiple times, the information will explode, so our os module works. Use os path. The exists method determines whether the file exists and deletes it if it exists
if not os.path.exists("./movie.txt"):
pass
else:
os.remove("./movie.txt")Because I'm used to running programs on the terminal, I added OS System ("CLS"), please use clear for Linux. Then, in order to make the program run at the beginning, I added a few sentences at the beginning
os.system("cls")
print("Start crawling for watercress in 3 seconds top250 Movie information...")
time.sleep(1)
print("3...")
time.sleep(1)
print("2...")
time.sleep(1)
print("1...")
time.sleep(1)So far, the program is finished! Full code:
import requests
import re
import os
import time
s = 0
os.system("@echo off")
# Delete files to avoid duplicate text
if not os.path.exists("./movie.txt"):
pass
else:
os.remove("./movie.txt")
os.system("cls")
print("Start crawling for watercress in 3 seconds top250 Movie information...")
time.sleep(1)
print("3...")
time.sleep(1)
print("2...")
time.sleep(1)
print("1...")
time.sleep(1)
for i in range(10):
a = i * 25
url = "https://movie.douban.com/top250?start="+str(a)+"&filter="
headers = {
"user-agent":
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
resp = requests.get(url, headers=headers)
page_content = resp.text # page_content save source code
obj = re.compile('<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?</span>.*?'
'<div class="bd">.*?<p class="">(?P<dy>.*?) .*?<br>(?P<year>.*?) '
'.*?/ (?P<country>.*?) .*? (?P<lx>.*?)</p>'
'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
'.*?<span>(?P<people>.*?)</span>'
'.*?</div>.*?<span class="inq">(?P<xcy>.*?)</span>', re.S)
result = obj.finditer(page_content)
with open("movie.txt", mode="a", encoding="utf-8") as f:
for it in result:
s+=1
f.write("ranking:"+str(s)+"\n")
f.write("Movie title:"+it.group("name").strip()+"\n")
f.write("country:"+it.group("country").strip()+"\n")
f.write("particular year:"+it.group("year").strip()+"\n")
f.write(it.group("dy").strip()+"\n")
f.write("score:"+it.group("score").strip()+"\n")
f.write("Number of raters:"+it.group("people").strip()+"\n")
f.write("type:"+it.group("lx").strip()+"\n")
f.write("Slogan:"+it.group("xcy").strip()+"\n")
f.write("----------------------------------\n")
f.write("\n")
print("Successfully crawled", s, "Item movie information")
resp.close()
os.system("cls")
print("Crawling completed,Please enter movie.txt see")
New blogger, welcome to join us