brief introduction
Objective: To obtain the names and trading information of all stocks on the Shanghai Stock Exchange and Shenzhen Stock Exchange.
Output: Save to file.
Technical Route: Scrapy Crawler Framework
Language: Python 3.5
Since the principles of stock information crawling have been described in the previous blog post, there are no more descriptions here. For more information, you can refer to the blog: Link Description In this article, we will focus on how this project is implemented within the Scrappy framework.
Principle analysis
The Scrapy framework is shown below:
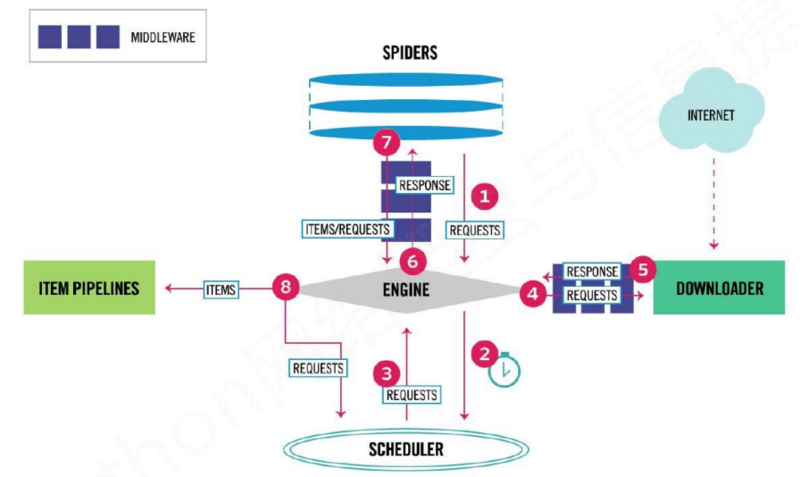
We mainly do two steps:
(1) First, you need to write a crawler spider in the framework for link crawling and page parsing;
(2) Write pipelines to process parsed stock data and store them in files.
Coding
Steps:
(1) Create a project-generated Spider template
Open the cmd command line, navigate to the path where the project is placed, type: scrapy start project BaiduStocks, and a new project named BaiduStocks will be created in the directory.Re-enter: cd BaiduStocks enters the catalog, then enter: scrapy genspider stocks baidu.com to generate a crawl.Then we can see a stocks.py file in the spiders/directory, as shown in the following figure:
(2) Write Spider: configure the stocks.py file, modify the processing of return pages, and modify the processing of new URL crawl requests
Open the stocks.py file with the following code:
# -*- coding: utf-8 -*- import scrapy class StocksSpider(scrapy.Spider): name = 'stocks' allowed_domains = ['baidu.com'] start_urls = ['http://baidu.com/'] def parse(self, response): pass
Modify the above code as follows:
# -*- coding: utf-8 -*- import scrapy import re class StocksSpider(scrapy.Spider): name = "stocks" start_urls = ['http://quote.eastmoney.com/stocklist.html'] def parse(self, response): for href in response.css('a::attr(href)').extract(): try: stock = re.findall(r"[s][hz]\d{6}", href)[0] url = 'https://gupiao.baidu.com/stock/' + stock + '.html' yield scrapy.Request(url, callback=self.parse_stock) except: continue def parse_stock(self, response): infoDict = {} stockInfo = response.css('.stock-bets') name = stockInfo.css('.bets-name').extract()[0] keyList = stockInfo.css('dt').extract() valueList = stockInfo.css('dd').extract() for i in range(len(keyList)): key = re.findall(r'>.*</dt>', keyList[i])[0][1:-5] try: val = re.findall(r'\d+\.?.*</dd>', valueList[i])[0][0:-5] except: val = '--' infoDict[key]=val infoDict.update( {'Stock Name': re.findall('\s.*\(',name)[0].split()[0] + \ re.findall('\>.*\<', name)[0][1:-1]}) yield infoDict
(3) Configure the pipelines.py file to define the processing class for the Scraped Item
Open the pipelinse.py file as shown below:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class BaidustocksPipeline(object): def process_item(self, item, spider): return item
Modify the above code as follows:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class BaidustocksPipeline(object): def process_item(self, item, spider): return item #There are three methods in each pipelines class class BaidustocksInfoPipeline(object): #When a crawler is called, the corresponding pipelines initiate the method def open_spider(self, spider): self.f = open('BaiduStockInfo.txt', 'w') #A method for pipelines where a crawl closes or ends def close_spider(self, spider): self.f.close() #The method used to process each Item item is also the most principal function in pipelines def process_item(self, item, spider): try: line = str(dict(item)) + '\n' self.f.write(line) except: pass return item
(4) Modifying settings.py is when the framework finds the class we wrote in pipelinse.py
Add in settings.py:
# Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300, }
At this point, the program is complete.
(4) Execution Procedure
On the command line, type: scrapy crawl stocks