Previously, we introduced the classes related to metadata management in CryptDB and the storage format of these classes in MySQL. This article describes when these metadata were created, when and how they were written to the database, when they were read, and where they were used.
Initialization and Metadata Reading
SchemaInfo and SchemaCache:
Last article This paper introduces a hierarchical structure from DatabaseMeta to represent metadata. In fact, the above two structures are also related to the storage of metadata. SchemaInfo is in the upper layer of DatabaseMeta, and its inheritance structure is as follows:
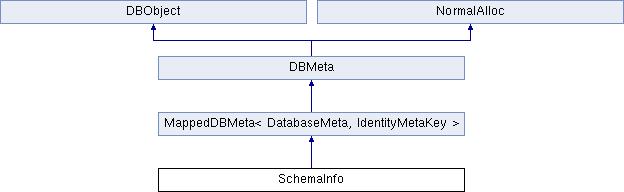
Similar to the previous article, SchemaInfo inherits MappedDBMeta and stores all database information created in current CryptDB in the form of Key-Value. SchemaCache is a simple encapsulation of SchemaInfo. Its main members are defined as follows:
class SchemaCache {
public:
....
private:
mutable std::shared_ptr<const SchemaInfo> schema;
//Let's set this stale state.
mutable bool no_loads;
//Random id
const unsigned int id;
};
We know that in CryptDB, metadata is stored in local embedded MySQL. In the initialization process, if the MySQL tables associated with these metadata are not established, there will first be a table building process, and the table building operation is located in the First article In the connect function introduced. That is, after the first user connection enters, if these tables have not been established, they will be initialized first.
With these tables, we need to have in-memory data structures to preserve hierarchical metadata structures. The first step is to get a random id SchemaCache structure, which contains an empty SchemaInfo member. If a database has been built before, or some tables already exist under the database, metadata in embedded MySQL needs to be read, deserialized and represented by the data structure in memory.
First look at the member id of SchemaCache: When initialized, a random id is assigned to the cache and no_loads is set to true. Then no_loads are checked and found to be true, and the following sql statements are executed by entering the initial Staleness function:
INSERT INTO embedded_db.generic_prefix_staleness (cache_id, stale) VALUES (2313589110, TRUE);At the same time, set no_loads to false. The stale information is then queried through the following sql statements:
SELECT stale FROM embedded_db.generic_prefix_staleness WHERE cache_id = 2313589110;Because of the no_loads settings just now, the random id found in the current cache must be stale to true. Because stale is ture, it goes into the process of loading SchemaInfo. The relevant sample code is as follows:
//Code is located main/schema.cc
std::shared_ptr<const SchemaInfo>
SchemaCache::getSchema(const std::unique_ptr<Connect> &conn,
const std::unique_ptr<Connect> &e_conn) const {
if (true == this->no_loads) {
initialStaleness(e_conn);
this->no_loads = false;
}
if (true == lowLevelGetCurrentStaleness(e_conn, this->id)) {
this->schema =
std::shared_ptr<SchemaInfo>(loadSchemaInfo(conn, e_conn));
}
return this->schema;
}After this process of loading SchemaInfo, SchemaCache began to have its own SchemaInfo, which contains metadata equivalent to disk data. Let's look at the concrete implementation:
//Code is located main/rewrite_main.cc
DBMeta* loadChildren(DBMeta *const parent,const std::unique_ptr<Connect> &e_conn){
auto kids = parent->fetchChildren(e_conn);
for (auto it : kids) {
loadChildren(it,e_conn);
}
return parent;
}
std::unique_ptr<SchemaInfo>
loadSchemaInfo(const std::unique_ptr<Connect> &conn,
const std::unique_ptr<Connect> &e_conn){
loadChildren(schema.get(),e_conn);
return std::move(schema);
}
As you can see, reading SchemaInfo is a recursive call process, in which the first parameter of the loadChildren function is a DBMeta* structure, representing the metadata management class to be read currently, and the second parameter is used to access the underlying embedded database to read the serialized data. The basic logic is that, for parent, all children are read by fetchChildren function, and the kids are added to their internal map structure. Then, children are traversed and loadChildren is called recursively for each kid to complete all data reading.
In MappedDBMeta, which was first defined by fetchChildren, the lambda expression deserialize was defined internally. The lambda expression can be used to complete deserialization and add classes to map. Then call the doFetchChildren function, first read the data in the database internally, and then call the deserialize defined before to complete the deserialize and add functions, the specific code is as follows:
template <typename ChildType, typename KeyType>
std::vector<DBMeta *>
MappedDBMeta<ChildType, KeyType>::fetchChildren(const std::unique_ptr<Connect> &e_conn){
std::function<DBMeta *(const std::string &,
const std::string &,
const std::string &)>
deserialize =
[this] (const std::string &key, const std::string &serial,
const std::string &id) {
const std::unique_ptr<KeyType>
meta_key(AbstractMetaKey::factory<KeyType>(key));
auto dChild = ChildType::deserialize;
std::unique_ptr<ChildType>
new_old_meta(dChild(atoi(id.c_str()), serial));
this->addChild(*meta_key, std::move(new_old_meta));
return this->getChild(*meta_key);
};
return DBMeta::doFetchChildren(e_conn, deserialize);
}Let's continue to look at the implementation of the doFetchChildren function:
std::vector<DBMeta *>
DBMeta::doFetchChildren(const std::unique_ptr<Connect> &e_conn,
std::function<DBMeta *(const std::string &,
const std::string &,
const std::string &)>
deserialHandler) {
const std::string table_name = MetaData::Table::metaObject();
// Now that we know the table exists, SELECT the data we want.
std::vector<DBMeta *> out_vec;
std::unique_ptr<DBResult> db_res;
//this is the id of the current class.
const std::string parent_id = std::to_string(this->getDatabaseID());
const std::string serials_query =
" SELECT " + table_name + ".serial_object,"
" " + table_name + ".serial_key,"
" " + table_name + ".id"
" FROM " + table_name +
" WHERE " + table_name + ".parent_id"
" = " + parent_id + ";";
//all the metadata are fetched here.
TEST_TextMessageError(e_conn->execute(serials_query, &db_res),
"doFetchChildren query failed");
MYSQL_ROW row;
while ((row = mysql_fetch_row(db_res->n))) {
unsigned long * const l = mysql_fetch_lengths(db_res->n);
assert(l != NULL);
const std::string child_serial_object(row[0], l[0]);
const std::string child_key(row[1], l[1]);
const std::string child_id(row[2], l[2]);
DBMeta *const new_old_meta =
deserialHandler(child_key, child_serial_object, child_id);
out_vec.push_back(new_old_meta);
}
return out_vec;
}
As you can see, it first obtains the parent_id, then extracts all the child ren rows corresponding to the current parent according to the parent_id, and deserializes each row of data using the labmda function just defined, and finally returns all the children Ren in the form of a vector. At this point, we return to the loadChildren function. For this returned vector type children, each element will be traversed. For each element, we use the loadChildren function just introduced to fill in its internal map. It should be noted that, similar to the reading process, for onioneMeta, fetch Chindlren is defined differently because it stores children internally through a vector rather than a map, as follows:
std::vector<DBMeta *>
OnionMeta::fetchChildren(const std::unique_ptr<Connect> &e_conn) {
std::function<DBMeta *(const std::string &,
const std::string &,
const std::string &)>
deserialHelper =
[this] (const std::string &key, const std::string &serial,
const std::string &id) -> EncLayer * {
const std::unique_ptr<UIntMetaKey>
meta_key(AbstractMetaKey::factory<UIntMetaKey>(key));
const unsigned int index = meta_key->getValue();
if (index >= this->layers.size()) {
this->layers.resize(index + 1);
}
std::unique_ptr<EncLayer>
layer(EncLayerFactory::deserializeLayer(atoi(id.c_str()),
serial));
this->layers[index] = std::move(layer);
return this->layers[index].get();
};
return DBMeta::doFetchChildren(e_conn, deserialHelper);
}
As you can see, the main difference is that deserialHelper is different. For upper deserialHelper, its internal logic is to add new metadata management classes to map, while for OnionMeta, it is to add metadata management classes to vector.
In addition, since EncLayer is the lowest class, as a recursive termination condition, its fetchChildren implementation is as follows:
std::vector<DBMeta *>
fetchChildren(const std::unique_ptr<Connect> &e_conn) {
return std::vector<DBMeta *>();
}Summary of Reading Process
Through the above analysis, we know how metadata is stored in memory. The schematic diagram is as follows:
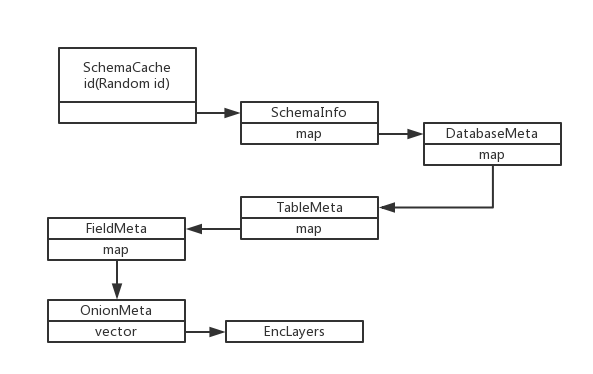
When initialized, the top schemaCache gets a random ID and saves an empty SchemaInfo structure. Later, it fills in the map in SchemaInfo through the load SchemaInfo mechanism above. In SchemaInfo layer, all database names and corresponding DatabaseMeta are saved in map, and the ID of SchemaInfo is fixed to 0. So in doFetchChildren function, with parent_id=0 as condition, all serialized DatabaseMeta can be obtained and inserted into SchemaInfo. Then, all DatabaseMetas are returned as vector s and processed recursively with the loadChildren function in turn. The recursive termination condition is EncLayer, because this is already the lowest class.
To understand this recursive process, let's give the following example: Let's assume that there are two databases db1 and db2 in CryptDB, with one table student in each database. The initialization process is as follows:
1) Initialize a schemaCache with a random id and empty schemaInfo inside, and start calling the loadSchemaInfo function through no_loads and stale mechanism.
2) Call the loadSchemaInfo function and use the recursive call of loadChildren internally. First, insert the database Meta corresponding to db1 and db2 into the schemaInfo, and return a vector of the database Meta, which has two elements.
3) Recursively process the first DatabaseMeta in the vector, insert the TableMeta corresponding to the student table inside it, and return a vector of TableMeta.
4) Recursively process the first TableMeta in the vector, insert the corresponding FieldMeta in the table, and return a vector of FieldMeta.
5) Recursively process the first FieldMeta in the vector, insert OnionMeta corresponding to the Field inside, and return a vector of OnionMeta.
6) Recursively process the first OnionMeta in the vector, insert the corresponding EncLayers in memory, and return an Enclayers vector.
7) Recursion proceeds to the first EncLayers in the vector, doing nothing, returning an empty vector, so that the recursion begins to re-enter the upper layer.
8) .....
9) After a series of processing, assuming that the first recursive processing from step 3 above is over, there are already two DatabaseMetas in the map of schemaInfo, and TableMeta in the first DatabaseMeta, FieldMeta in the TableMeta, and so on. At this point, the second DatabaseMeta is still empty, so continue the loop processing in Step 3, recursively process the second DatabaseMeta in vector and continue the process in Step 3-8.
After the above process, the metadata in memory is consistent with the data in disk. If the data in the disk changes due to the writing of metadata, the stale value is set to true again in the row corresponding to the current schemaCache. Each time the command is processed, the value of the stale is checked, and if it is found to be true, the load Schema operation above is repeated to update the metadata in memory. So the random id in SchemaCache is to record the stale, so you can decide whether to use the metadata import function above to read the metadata in disk.
Next, we describe when metadata will be written to disk and how the writing mechanism works.
Metadata Writing
From the above analysis, we can see that the metadata of mysql-proxy side mainly stores a hierarchical structure from database to EncLayer. Therefore, metadata writing corresponds to two common statements: CREATE DATABASE and CRATE TABLE. The former results in writing a row of DatabaseMeta data, while the latter results in writing multiple rows of data, including a row of TableMeta and multiple FieldMeta, OnionMeta, and EncLayer at the lower level.
Let's first consider the write caused by the CREATE DATABASE statement:
Establishment of delta
std::unique_ptr<DatabaseMeta> dm(new DatabaseMeta());
a.deltas.push_back(std::unique_ptr<Delta>(
new CreateDelta(std::move(dm), a.getSchema(),
IdentityMetaKey(dbname))));
return new DDLQueryExecutor(*copyWithTHD(lex), std::move(a.deltas));
When the CREATE DATABASE statement is executed, an empty DatabaseMeta is created to represent the newly added database, and then a CreateDelta structure is built based on it. Delta series classes are used to represent metadata changes, and the inheritance structure of their related classes is shown in the following figure:

Delta is defined as follows:
class Delta {
public:
Delta(const DBMeta &parent_meta) : parent_meta(parent_meta) {}
virtual bool apply(const std::unique_ptr<Connect> &e_conn,
TableType table_type) = 0;
protected:
const DBMeta &parent_meta;
};
There is a parent_meta inside. When new metadata is added or deleted, this metadata class has an upper class, parent_meta. For example, for DatabaseMeta to be added, the upper class is SchemaInfo. After adding DatabaseMeta, you also need to save a message at the same time: the database name corresponding to this DatabaseMeta. So the AbstractCreateDelta at the bottom extends Delta as follows:
template <typename KeyType>
class AbstractCreateDelta : public Delta {
public:
AbstractCreateDelta(const DBMeta &parent_meta,
const KeyType &key)
: Delta(parent_meta), key(key) {}
protected:
const KeyType key;
};
Finally, let's look at the definition of CreateDelta:
class CreateDelta : public AbstractCreateDelta<IdentityMetaKey> {
public:
CreateDelta(std::unique_ptr<DBMeta> &&meta,
const DBMeta &parent_meta,
IdentityMetaKey key)
: AbstractCreateDelta(parent_meta, key), meta(std::move(meta)) {}
bool apply(const std::unique_ptr<Connect> &e_conn,
TableType table_type);
std::map<const DBMeta *, unsigned int> & get_id_cache(){return id_cache;}
private:
const std::unique_ptr<DBMeta> meta;
std::map<const DBMeta *, unsigned int> id_cache;
};
As you can see, it adds a new member: meta. Used to represent the current metadata class. In this way, we can understand the meaning of the following statement:
std::unique_ptr<Delta>( new CreateDelta(std::move(dm), a.getSchema(),IdentityMetaKey(dbname)));Its representation adds a new Delta record: a DatabaseMeta, whose corresponding database name is dbname, is saved with Identify MetaKey. The upper class is SchemaInfo(a.getSchema call is to return SchemaInfo).
There is already a database Meta in memory, so there is inconsistency between memory data and disk data, which requires a process of writing to disk to keep synchronization. This action is achieved by the following functions:
bool
writeDeltas(const std::unique_ptr<Connect> &e_conn,
const std::vector<std::unique_ptr<Delta> > &deltas,
Delta::TableType table_type){
for (const auto &it : deltas) {
RFIF(it->apply(e_conn, table_type));
}
return true;
}As you can see, it is written to the database by calling the application function on delta. The implementation of the application function is as follows:
bool CreateDelta::apply(const std::unique_ptr<Connect> &e_conn,
Delta::TableType table_type){
//Get the database table name
const std::string &table_name = tableNameFromType(table_type);
//Write in
const bool b =
create_delta_helper(this,e_conn,table_type,table_name,
*meta.get(), parent_meta, key, parent_meta.getDatabaseID());
return b;
}In the create_delta_helper function, it is also a recursive call process. Its main code is as follows:
//
static
bool create_delta_helper(CreateDelta* this_is, const std::unique_ptr<Connect> &e_conn,
Delta::TableType table_type, std::string table_name,
const DBMeta &meta_me, const DBMeta &parent,
const AbstractMetaKey &meta_me_key, const unsigned int parent_id) {
const std::string &child_serial = meta_me.serialize(parent);
const std::string &serial_key = meta_me_key.getSerial();
//SQL statement for inserting metadata
const std::string &query =
" INSERT INTO " + table_name +
" (serial_object, serial_key, parent_id, id) VALUES ("
" '" + esc_child_serial + "',"
" '" + esc_serial_key + "',"
" " + std::to_string(parent_id) + ","
" " + std::to_string(old_object_id.get()) + ");";
//Execute SQL statement to insert data
e_conn->execute(query);
std::function<bool(const DBMeta &)> localCreateHandler =
[&meta_me, object_id, this_is,&e_conn,table_type,table_name]
(const DBMeta &child){
return create_delta_helper(this_is,e_conn, table_type, table_name,
child, meta_me, meta_me.getKey(child), object_id);
};
//For the children of the current DBMeta, do the same thing
return meta_me.applyToChildren(localCreateHandler);
}
In a layer invocation, meta_me and meta_me_key represent the DBMeta class that needs to be written at present and the corresponding key, respectively. For this example, it's DatabaseMeta and the corresponding Identify MetaKey. These two classes need to be serialized and written to the database. Pare_id also needs to be written to the database. As for the current DBMeta's own id, it is obtained by combining MySQL's auto increment with last_insert_id().
The following is the last SQL statement to execute the write operation:
//Because of auto increment, the id actually written is 1
INSERT INTO embedded_db.generic_prefix_BleedingMetaObject (serial_object, serial_key, parent_id, id) VALUES ( 'Serialize to associate database name with DatabaseMeta', 'db', 0, 0);
INSERT INTO embedded_db.generic_prefix_MetaObject (serial_object, serial_key, parent_id, id) VALUES ( 'Serialize to associate database name with DatabaseMeta', 'temp', 0, 1);
CryptDB establishes two metadata tables in the same format, writes two different metadata tables in different SQL execution stages, and finally ensures that the data in the two tables are consistent.
Then look at the changes caused by the CREATE TABLE statement:
// ddl_handler.cc
AbstractQueryExecutor *
CreateTableHandler::rewriteAndUpdate(Analysis &a, LEX *lex, const Preamble &pre) const{
//Create Tablemeta, which is empty
std::unique_ptr<TableMeta> tm(new TableMeta(true, true));
//The createAndRewriteField function traverses the field of the table and creates a FieldMeta for each field, which is then added to the map of the TableMeta.
...
...
//Create Delta for recording
a.deltas.push_back(std::unique_ptr<Delta>(
new CreateDelta(std::move(tm),
a.getDatabaseMeta(pre.dbname),
IdentityMetaKey(pre.table))));
...
...
}
FieldMeta::FieldMeta(){
//In the constructor of FieldMeta described above, call onion_layout to construct
//The corresponding OnionMeta is added to the map of the corresponding FieldMeta
init_onions_layout();
}
OnionMeta::OnionMeta{
//Call the EncLayerFactory::encLayer function to construct the encryption layer of onion and add it to the vector s of onion Meta
}
The processing flow of the CREATE TABLE statement is as shown above. We only intercept some of the schematic codes related to this article, and introduce which functions are called and what they are used for respectively. The following points should be noted:
- For the CREATE TABLE statement, the constructor of TableMeta is first called to construct an empty TableMeta.
- For fields in table s, the constructors of FieldMeta are called to construct multiple FieldMetas and added to the map of TableMeta.
- Within FieldMeta's constructor, there are already OnionMeta's constructs and added code. The OnionMeta constructor also includes the construction and addition of EncLayer
- So, at the level of FieldMeta, after constructing itself and adding it to TableMeta, the whole hierarchical metadata management class is constructed.
- The Create Delta added at the end of the article can be done on the table layer without adding delta to the classes in each layer.
In this way, through the above process, we have established a hierarchical structure in memory from TableMeta to EncLayer. And record the TableMeta, the name of the new table, and the database Meta on top of it through delta.
When metadata is written, it is still handled recursively by using the application function. Let's illustrate with an example:
Suppose we execute the statement: CREATE TABLE student (id integer) and set two onion DETs and OPEs for this column id, where DET contains two layers DET and RND and OPE contains two layers ope and rnd. The order of construction and writing is as follows:
First, the memory data structure establishment stage:
1) Constructing TableMeta for student s
2) Constructing FieldMeta for id
** 3)**FieldMeta constructs two onion Metas, representing DET and OPE, respectively. When onion Meta constructs, two onion layers are initialized respectively.
4) Add FieldMeta to TableMeta's internal map
5) Construct delta to record changes in this metadata
Then the data writing to disk phase:
1) Write to TableMeta
2) Write FieldMeta corresponding to id
3) Write OnionMeta corresponding to DET
4) The first Enclayer written to DET
5) The second Enclayer written to DET
6) The first EncLayer written to OPE
7) The second EncLayer written to OPE
Metadata usage
The use of metadata is mainly embodied in hierarchical encryption and decryption. From the beginning of DatabaseMeta down to OnionMeta's structure, it is helpful to locate the EncLayer that actually works at the end. After getting EncLayer, we can call the functions related to encryption and decryption to realize onion encryption and decryption. The relevant codes are as follows.
Hierarchical encryption:
Item *
encrypt_item_layers(const Item &i, onion o, const OnionMeta &om,
const Analysis &a, uint64_t IV) {
const auto &enc_layers = a.getEncLayers(om);
const Item *enc = &i;
Item *new_enc = NULL;
for (const auto &it : enc_layers) {
new_enc = it->encrypt(*enc, IV);
enc = new_enc;
}
return new_enc;
}
Hierarchical decryption:
Item *
decrypt_item_layers(const Item &i, const FieldMeta *const fm, onion o,
uint64_t IV) {
const Item *dec = &i;
const OnionMeta *const om = fm->getOnionMeta(o);
const auto &enc_layers = om->getLayers();
for (auto it = enc_layers.rbegin(); it != enc_layers.rend(); ++it) {
out_i = (*it)->decrypt(*dec, IV);
assert(out_i);
dec = out_i;
}
return out_i;
}
As you can see, encryption and decryption operations are all done for Item type, and all of them need to obtain EncLayer. In order to get the correct EncLayer, the hierarchical data structure mentioned above is needed.
summary
In CryptDB, in order to accomplish the functions of hierarchical encryption and decryption, it is necessary to construct classes related to the encryption layer and a hierarchical structure starting from database to manage the encryption layer. This paper introduces the key classes and functions involved in loading metadata from disk to memory and writing metadata from memory to disk. There are many details of the code involved in this paper. The key points need to be paid attention to are the data structure representation of memory, load SchemInfo, stale query mechanism and the record and write of delta. Specifically, how these mechanisms can be combined with the actual implementation of SQL will be introduced in subsequent articles, as well as links to references, which contain the source code I am annotating.
The next article will introduce the encryption algorithm, as well as the connection between the encryption algorithm and the metadata class.
Related literature
https://github.com/yiwenshao/Practical-Cryptdb
Original link: yiwenshao.github.io/2018/03/19/CryptDB Code Analysis 4-Encrypted Metadata Reading and Writing/
Author: Yiwen Shao
License Agreement: Attribution-NonCommercial 4.0
Please retain the above information, thank you!