Operation ①
-
1.1 operation content
-
requirement:
- Master Selenium to find HTML elements, crawl Ajax web page data, wait for HTML elements, etc.
- Use Selenium framework to crawl the information and pictures of certain commodities in Jingdong Mall.
-
Candidate sites: http://www.jd.com/
-
Output information: the output information of MYSQL is as follows
mNo mMark mPrice mNote mFile 000001 Samsung Galaxy 9199.00 Samsung Galaxy Note20 Ultra 5G 000001.jpg 000002......
-
-
1.2 code and experimental steps
- 1.2.1 experimental steps:
Copy the xpath path and pass in the keyword

Click the search button
but = self.driver.find_element_by_xpath('//*[@id="search"]/div/div[2]/button')
but.click()
time.sleep(10)
Realize scrolling and page turning
for i in range(33):
self.driver.execute_script("var a = window.innerHeight;window.scrollBy(0,a*0.5);")
time.sleep(0.5)
Analyze the product page, and the information of each product is in the li tag
html = self.driver.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li') # crawls all li Tags
Traverse each li and crawl node information
for item in range(len(html)):
try:
mMark = html[item].find_element_by_xpath('./div//div[@class="p-name"]/a/em/font[1]').text
print(mMark)
except Exception as err:
mMark = " "
mPrice = html[item].find_element_by_xpath('./div//div[@class="p-price"]/strong/i').text
mNote = html[item].find_element_by_xpath('./div//div[@class="p-name"]/a/em').text
src = html[item].find_element_by_xpath('./div//div[@class="p-img"]/a/img').get_attribute('src')
self.picSave(src)
self.db.insert(self.count, mMark, mPrice, mNote, str(self.count)+".jpg")
self.count += 1
Realize page turning
if self.page < 2:
self.page += 1
nextPage = self.driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[1]/a[9]')
nextPage.click()
#Perform the crawl function again
self.Mining()
-
1.3 operation results:
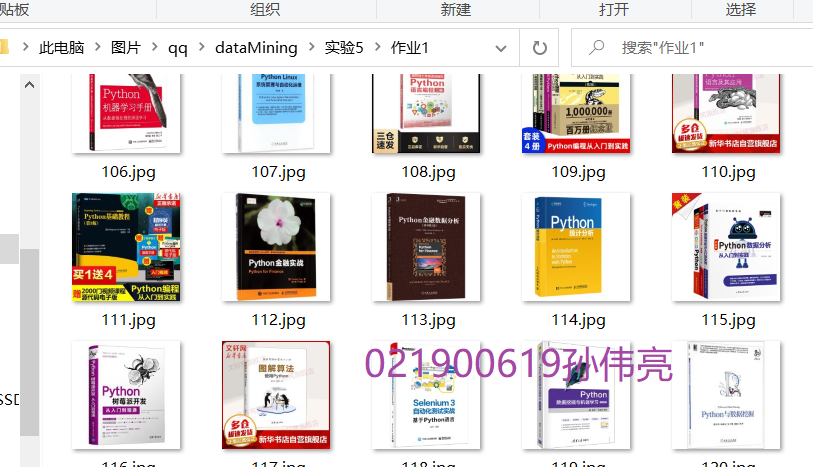
-
1.4 experience
- When crawling information, first crawl the li node of each commodity and recycle the information node
- Learned to simulate search
- During crawling, you must pay attention to setting the sleep time so that the web page can be loaded
Operation ②
-
2.1 operation contents
-
requirement:
- Proficient in Selenium's search for HTML elements, user simulated Login, crawling Ajax web page data, waiting for HTML elements, etc.
- Use Selenium framework + Mysql to simulate login to muke.com, obtain the information of the courses learned in the students' own account, save it in MySQL (course number, course name, teaching unit, teaching progress, course status and course picture address), and store the pictures in the imgs folder under the root directory of the local project. The names of the pictures are stored with the course name.
-
Candidate website: China mooc website: https://www.icourse163.org
-
Output information: MySQL database storage and output format
Id cCourse cCollege cSchedule cCourseStatus cImgUrl 1 Python web crawler and information extraction Beijing University of Technology 3 / 18 class hours learned Completed on May 18, 2021 http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg 2......
-
-
2.2 code and experimental steps
- 2.2.1 experimental steps
- 2.2.1 experimental steps
# Login entry
DL = self.driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
DL.click()
# Click other methods to log in
QTDL = self.driver.find_element_by_xpath('//span[@class="ux-login-set-scan-code_ft_back"]')
QTDL.click()
# Click mobile login
phoneDL = self.driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[2]')
phoneDL.click()
# Toggle floating window
phoneI = self.driver.find_element_by_xpath('//div[@class="ux-login-set-container"][@id="j-ursContainer-1"]/iframe')
self.driver.switch_to.frame(phoneI)
# Enter phone number
phoneNum = self.driver.find_element_by_xpath('//*[@id="phoneipt"]')
phoneNum.send_keys(USERNAME)
# Input password
phonePassword = self.driver.find_element_by_xpath('//div[@class="u-input box"]/input[2]')
phonePassword.send_keys(PASSWORD)
# Click login and wait for login to succeed
DlClick = self.driver.find_element_by_xpath('//*[@id="submitBtn"]')
DlClick.click()
time.sleep(10) # Enter my course
myClass = self.driver.find_element_by_xpath('//div[@class="_1Y4Ni"]/div')
myClass.click()
time.sleep(5)
Analyze the course page, and the information of each course is in a div tag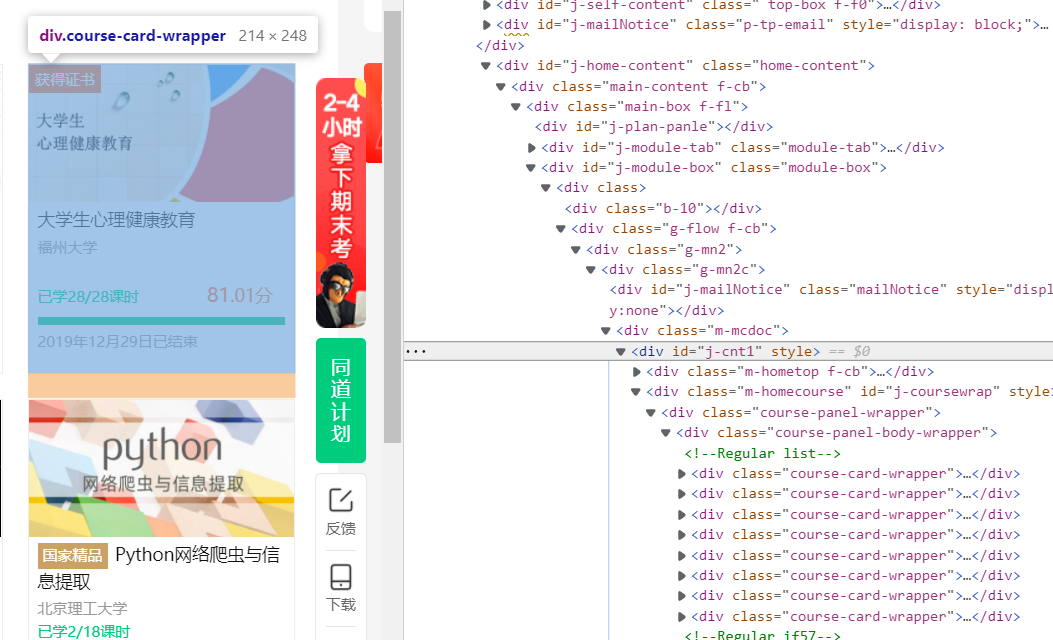
# Crawl the div tag of each course
html = self.driver.find_elements_by_xpath('//*[@id="j-coursewrap"]/div/div/div')
Traverse each div and crawl node information
# Crawling information
for item in html:
print(self.count)
cCourse = item.find_element_by_xpath('./div//div[@class="text"]/span[@class="text"]').text
print(cCourse)
cCollege = item.find_element_by_xpath('./div//div[@class="school"]/a').text
print(cCollege)
cSchedule = item.find_element_by_xpath('./div//div[@class="text"]/a/span').text
print(cSchedule)
cCourseStatus = item.find_element_by_xpath('./div//div[@class="course-status"]').text
print(cCourseStatus)
src = item.find_element_by_xpath('./div//div[@class="img"]/img').get_attribute("src")
print(src)
self.picSave(src, cCourse)
self.db.insert(self.count, cCourse, cCollege, cSchedule, cCourseStatus, src)
self.count += 1
Realize page turning
nextPage = self.driver.find_element_by_xpath('//*[@id="j-coursewrap"]/div/div[2]/ul/li[4]/a')
# Realize page turning
if nextPage.get_attribute('class') != "th-bk-disable-gh":
print(1)
nextPage.click()
time.sleep(5)
# Perform the crawl function again
self.Mining()
-
2.3 operation results:
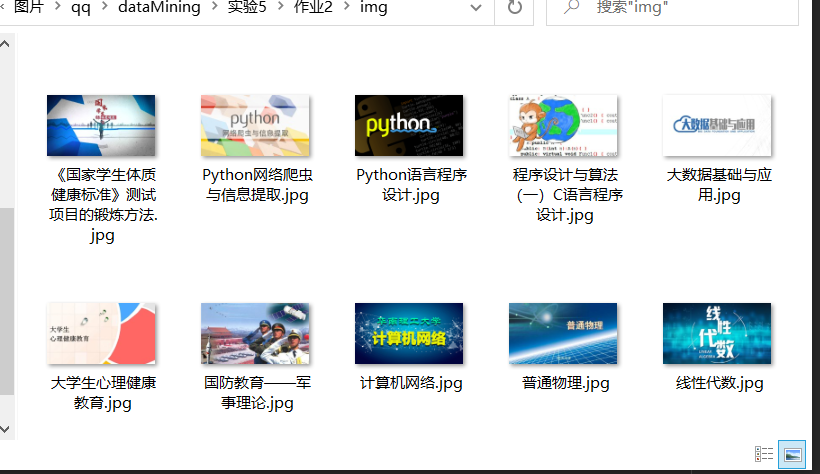
Operation ③
-
3.1 operation contents
- Requirements: Master big data related services and be familiar with the use of Xshell
- Complete the document Hua Weiyun_ Big data real-time analysis and processing experiment manual Flume log collection experiment (part) v2 The tasks in docx are the following five tasks. See the document for specific operations.
- Environment construction
- Task 1: open MapReduce service
- Real time analysis and development practice:
- Task 1: generate test data from Python script
- Task 2: configure Kafka
- Task 3: install Flume client
- Task 4: configure Flume to collect data
- Requirements: Master big data related services and be familiar with the use of Xshell
-
3.2 results
-
Task 1: generate test data from Python script
Executing python files
View generated data -
Task 2: configure Kafka
Execute source
Task 3: install Flume client -
Finally, install Flume

Restart service
-
Task 4: configure Flume to collect data
-