[data acquisition and fusion technology] the third major operation
Operation ①
- Requirements: specify a website and crawl all the pictures in the website, such as China Meteorological Network( http://www.weather.com.cn ). Single thread and multi thread crawling are used respectively. (the number of crawling pictures is limited to the last 3 digits of the student number)
- Output information:
Output the downloaded Url information on the console, store the downloaded image in the images subfolder, and give a screenshot.
1) Completion process:
- General idea: after initiating the visit to the specified web page, crawl all the picture URLs and download them. If the number is insufficient, crawl all the links in the web page to visit them in turn, and then download the pictures in the new web page. Repeat the above process until enough pictures are downloaded.
1. Check the required information in the html document of the web page through the browser
- Need picture url and new link
- Picture url (src attribute under img tag):
- New link (href attribute under any label):

- Picture url (src attribute under img tag):
2. Crawl the information according to the results of the previous step
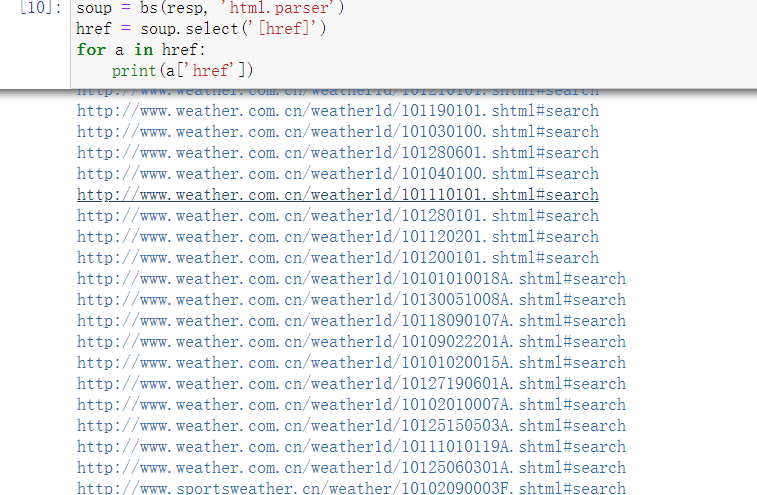
- href attribute crawling
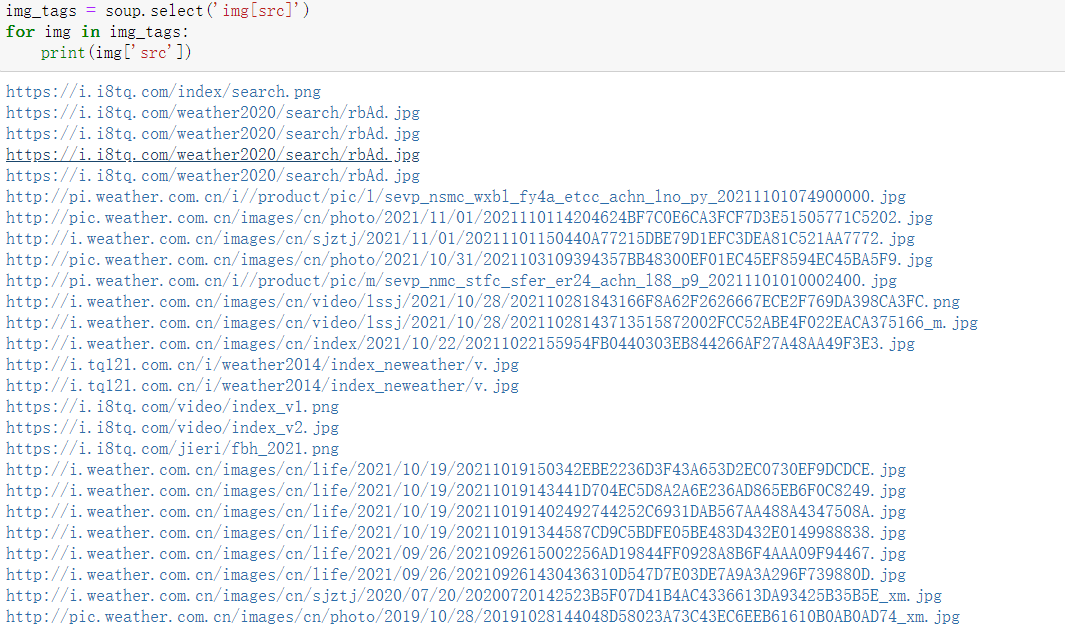
- Image url crawling
3. Image download (single thread and multi thread)
- Get the picture information through request.get (URL) and write it locally
def img_download(pic_url, count): # Download the picture according to the picture url
if len(pic_url) > 4 and pic_url[-4] == '.': # Set the download file suffix according to the url suffix
end_with = pic_url[-4:]
else:
end_with = ''
path = './EX3_1_images/' + 'img' + str(count) + end_with
try: # Download pictures
resp = requests.get(pic_url)
resp = resp.content
f = open(path, 'wb')
f.write(resp)
f.close()
print('Download img', str(count), ' successfully!')
# Show successful download
except Exception as err:
print('Fail to download img', str(count),
' with error as ', err, '!')
# Show download failed
-
Single threaded download
- Execute the above image download function for the crawled image url in turn
-
Multithreaded Download
- Add the download tasks to the new threads one by one (when the parameter t is True, the download process uses multithreading, and when False, the download process uses single thread)
if t: each_page_threads = [] for img in imgs: T = threading.Thread(target=img_download, args=(img, cc)) cc += 1 T.setDaemon(False) T.start() each_page_threads.append(T) for each_thread in each_page_threads: each_thread.join()
4. Result display

2) Experience:
Most of the content is the same as the previous job, so it is relatively simple to implement. You can continue to modify the picture download and page Jump to prevent downloading duplicate pictures
Operation ②
-
Requirements: use the sketch framework to reproduce the operation ①
-
Output information: the same as operation ①
1) Completion process
- General idea: the implementation steps are the same as that of job ①. Just transfer the code of job ① into the sketch framework. Complete the image url crawling and page Jump in the spider, encapsulate the image url into the item and submit it to pipeline for information output and image download
1.spider
import scrapy
from scrapy.selector import Selector as selector
from ..items import Ex32Item
class Ex32Spider(scrapy.Spider):
name = 'ex3_2'
allowed_domains = ['www.weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
count = 0 # Calculate the number of generated item s, i.e. crawled image URLs
def parse(self, response):
try:
data = response.body.decode()
except:
return
s = selector(text=data)
pics = s.xpath('//img/@src').extract() # crawl image url
for pic in pics: # Package item s one by one and pass them to pipeline
if self.count >= 115: # Stop when the quantity is enough
break
if len(pic) < 5: # Exclude incorrect picture URLs
continue
item = Ex32Item()
item['url'] = pic
item['count'] = self.count
self.count += 1
yield item
links = s.xpath('//@href').extract() # crawl Web links
for link in links:
if self.count >= 115: # Exit when there are enough pictures
break
try:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
# Call this function again for the new link and repeat the above operation in the new web page until enough pictures are crawled
except Exception:
continue # Try the next link when there are not enough pictures and the link fails to access
2.pipelines
import requests
from itemadapter import ItemAdapter
def img_download(pic_url, count): # Download the picture according to the picture url
if len(pic_url) > 4 and pic_url[-4] == '.': # Set the download file suffix according to the url suffix
end_with = pic_url[-4:]
else:
end_with = ''
path = 'D:\\031904115\\Data Collecting EX\\EX3\\EX3_2_images/' \
+ 'img' + str(count) + end_with
try: # Download pictures
resp = requests.get(pic_url)
resp = resp.content
f = open(path, 'wb')
f.write(resp)
f.close()
print('Download img', str(count), ' successfully!')
# Show successful download
except Exception as err:
print('Fail to download img', str(count),
' with error as ', err, '!')
# Show download failed
class Ex32Pipeline:
def process_item(self, item, spider):
print(str(item['count']), ':', item['url']) # Picture information display
img_download(item['url'], item['count']) # Picture download
return item
3. Result display

2) Experience:
Assignment ② is mainly to convert the crawler into the skeleton of the sketch. After the process, I became more familiar with the skeleton and learned more about the operation methods in the framework
Operation ③
-
Requirements: crawl the Douban movie data, use scene and xpath, store the content in the database, and store the pictures in the imgs path
-
Candidate sites: https://movie.douban.com/top250
-
Output information:
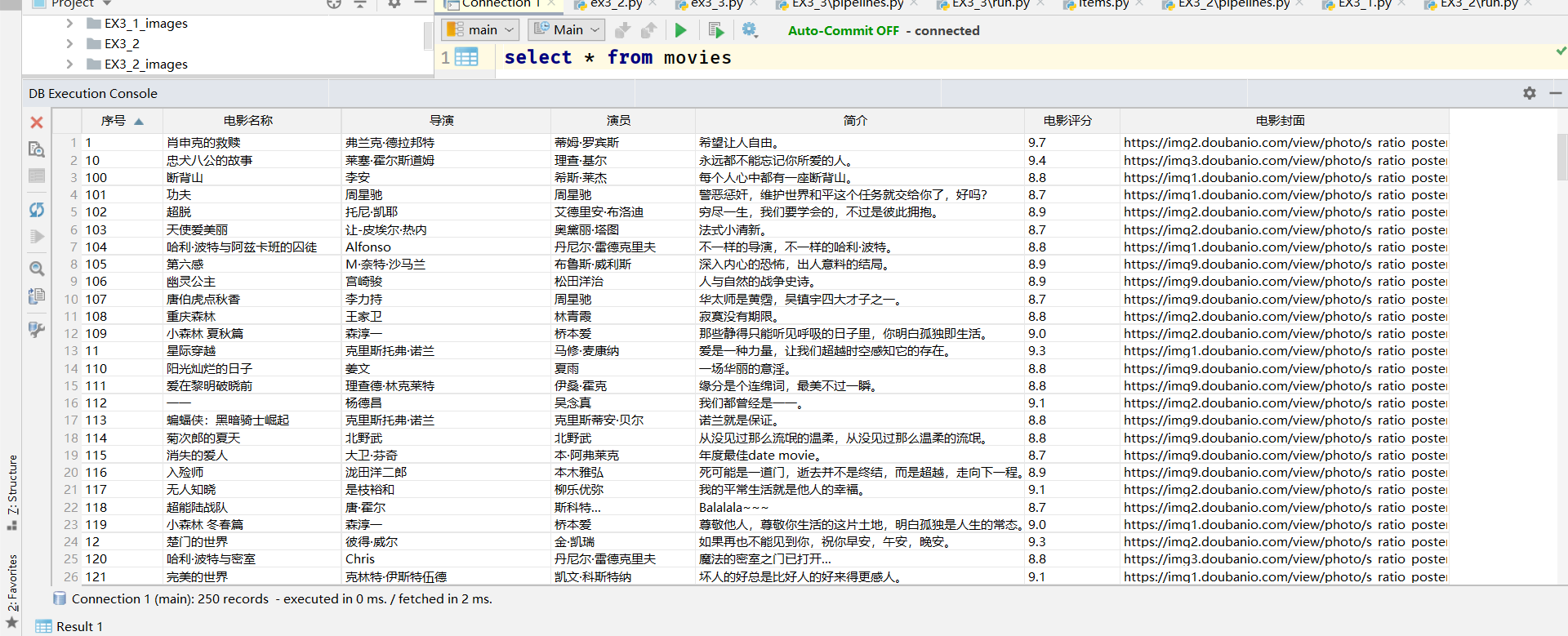
| Serial number | Movie title | director | performer | brief introduction | Film rating | Film cover |
|---|---|---|---|---|---|---|
| 1 | The Shawshank Redemption | Frank delabond | Tim Robbins | Want to set people free | 9.7 | ./imgs/xsk.jpg |
| 2.... |
1) Completion process:
- General idea: realize page turning processing in spider, use xpath to obtain information, and package it item by item in item. Download pictures in pipeline and save data in database
1. Open the target web page to view the label information

- It is not difficult to find that the information of a movie is all in a single li tag. After simple verification, it is found that all the required information is in it
2. Try information crawling
-
HTML document acquisition

-
Movie information crawling

-
Since the director and the actor are in the same text, further separation is required

-
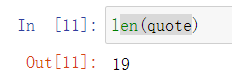
Through practice, it is found that the above crawling methods are not accurate enough in terms of actors and profiles

-
The reason for the above problems is that some films in the original web page have no introduction or actor information, which leads to the mismatch between the follow-up films and the introduction
- No profile:

- No actors:

- No profile:
-
resolvent
- Replace the missing actor information with 'None'
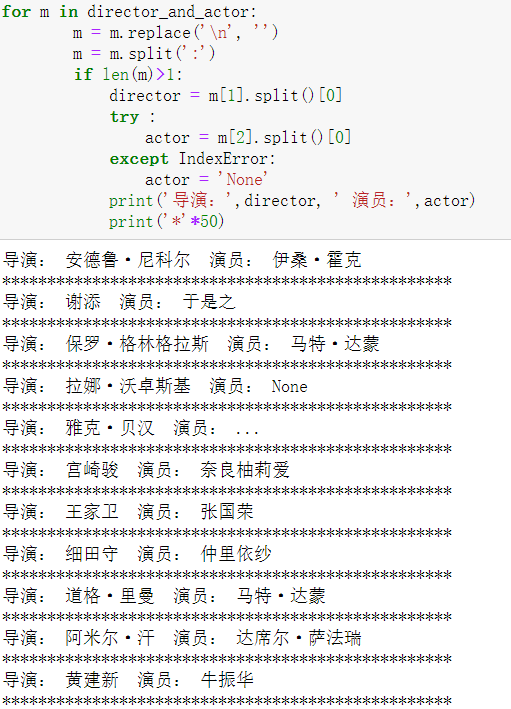
- Replace the missing profile with 'None' to prevent subsequent information pairing dislocation
- Replace the missing actor information with 'None'
3. Page turning operation
- Through observation and attempt, it can be seen that modifying the start value in the url can correspond to the page number page_ Num = int (start / 25) + 1, the multiple of start 25 is the best

4. Code actual installation
- spider
import scrapy
from scrapy.selector import Selector as selector
from ..items import Ex33Item
class Ex33Spider(scrapy.Spider):
name = 'ex3_3'
allowed_domains = ['movie.douban.com/top250']
start_urls = ['https://movie.douban.com/top250/']
url = start_urls[0][:-1]
for i in range(1, 10):
start_urls.append(url + '?start=' + str(i * 25)) # Generate and load all page URLs
def parse(self, response):
try:
data = response.body.decode()
except:
return
s = selector(text=data)
movies = s.xpath('//ol/li ') # crawl the li tag of the corresponding movie
ranks = movies.xpath('.//EM / text()). Extract() # crawling ranking
director_and_actor = movies.xpath('.//Div [@ class = "BD"] / P / text() [position() = 1]). Extract() # crawls director and actor
quotes = []
scores = movies.xpath('.//Div [@ class = "BD"] / / span [@ class = "rating_num"] / text()). Extract() # crawling score
titles = movies.xpath('.//img/@alt').extract() # crawls the Chinese name of the movie
imgs = movies.xpath('.//img/@src').extract() # crawl movie picture url
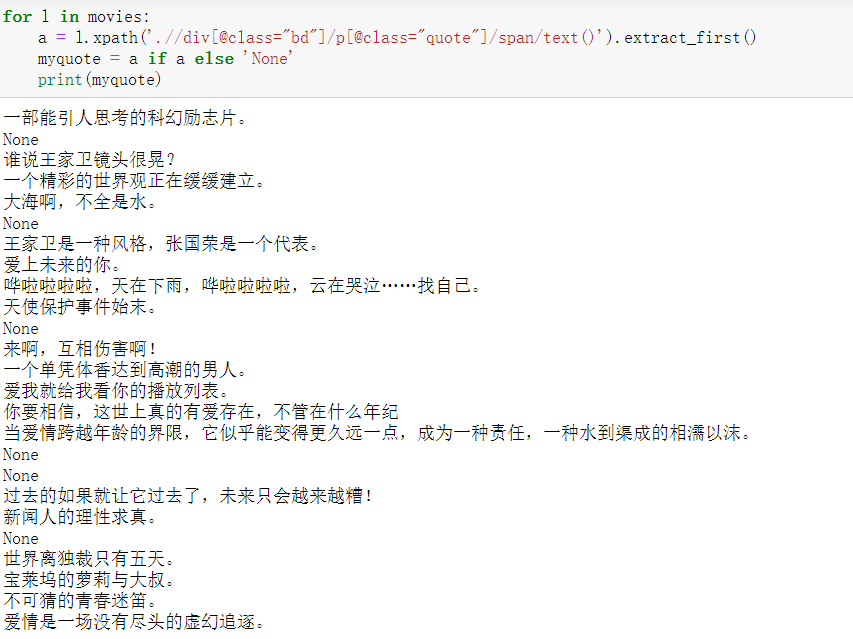
for movie in movies: # Item by item crawling film introduction
a = movie.xpath('.//div[@class="bd"]/p[@class="quote"]/span/text()').extract_first()
quote = a if a else 'None'
quotes.append(quote)
directors = []
actors = []
for m in director_and_actor: # Split the film director and actor information, and only keep the first director and actor from left to right
m = m.replace('\n', '')
m = m.split(':')
if len(m) > 1:
director = m[1].split()[0]
try:
actor = m[2].split()[0]
except IndexError:
actor = 'None'
directors.append(director)
actors.append(actor)
for i in range(len(movies)): # Data encapsulated into item
item = Ex33Item()
item['rank'] = ranks[i]
item['title'] = titles[i]
item['director'] = directors[i]
item['actor'] = actors[i]
item['quote'] = quotes[i]
item['score'] = scores[i]
item['img'] = imgs[i]
yield item
- pipelines (picture download and database are described in the previous or previous assignments)
import requests
import sqlite3
from itemadapter import ItemAdapter
class MovieDB:
def openDB(self):
self.con=sqlite3.connect("movies.db")
self.cursor=self.con.cursor()
try: # Build table
self.cursor.execute("create table movies (Serial number varchar(16),Movie title varchar(16),director varchar(64),performer varchar(32),brief introduction varchar(100),Film rating varchar(16),Film cover varchar(100),constraint pk_weather primary key (Serial number))")
except Exception as err: # If the table already exists, delete the original data and add again
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, item):
try: # Data insertion
self.cursor.execute("insert into movies (Serial number,Movie title,director,performer,brief introduction,Film rating,Film cover) values (?,?,?,?,?,?,?)",
(item['rank'], item['title'], item['director'], item['actor'], item['quote'], item['score'], item['img']))
print('film:', item['title'], ' Saved successfully!')
except Exception as err:
print(err)
def img_download(pic_url, title): # Download the picture according to the picture url
if len(pic_url) > 4 and pic_url[-4] == '.': # Set the download file suffix according to the url suffix
end_with = pic_url[-4:]
else:
end_with = ''
path = 'D:\\031904115\\Data Collecting EX\\EX3\\EX3_3_images/' \
+ 'img' + title + end_with
try: # Download pictures
resp = requests.get(pic_url)
resp = resp.content
f = open(path, 'wb')
f.write(resp)
f.close()
print('Download img', title, ' successfully!')
# Show successful download
except Exception as err:
print('Fail to download img', title,
' with error as:', err)
# Show download failed
class Ex33Pipeline:
def __init__(self): # Set database object
self.db = MovieDB()
def open_spider(self, spider): # Open the database when the spider starts running
self.db.openDB()
def process_item(self, item, spider): # Data saving and picture downloading
self.db.insert(item)
img_download(item['img'], item['title'])
return item
def close_spider(self, spider): # Close the database when the spider finishes running
self.db.closeDB()
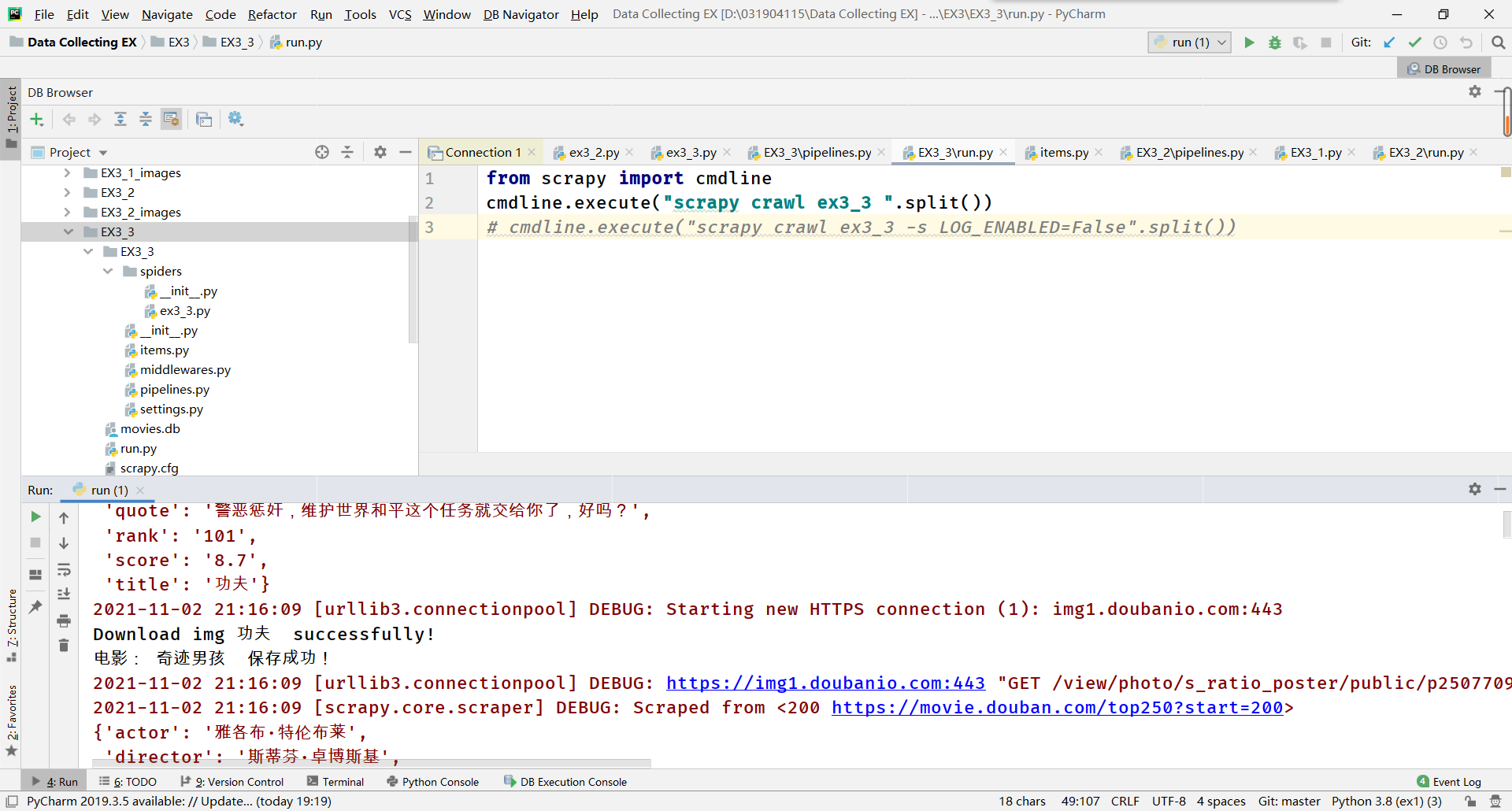
5. Result display
- Console:
- Database content:
- Save results:
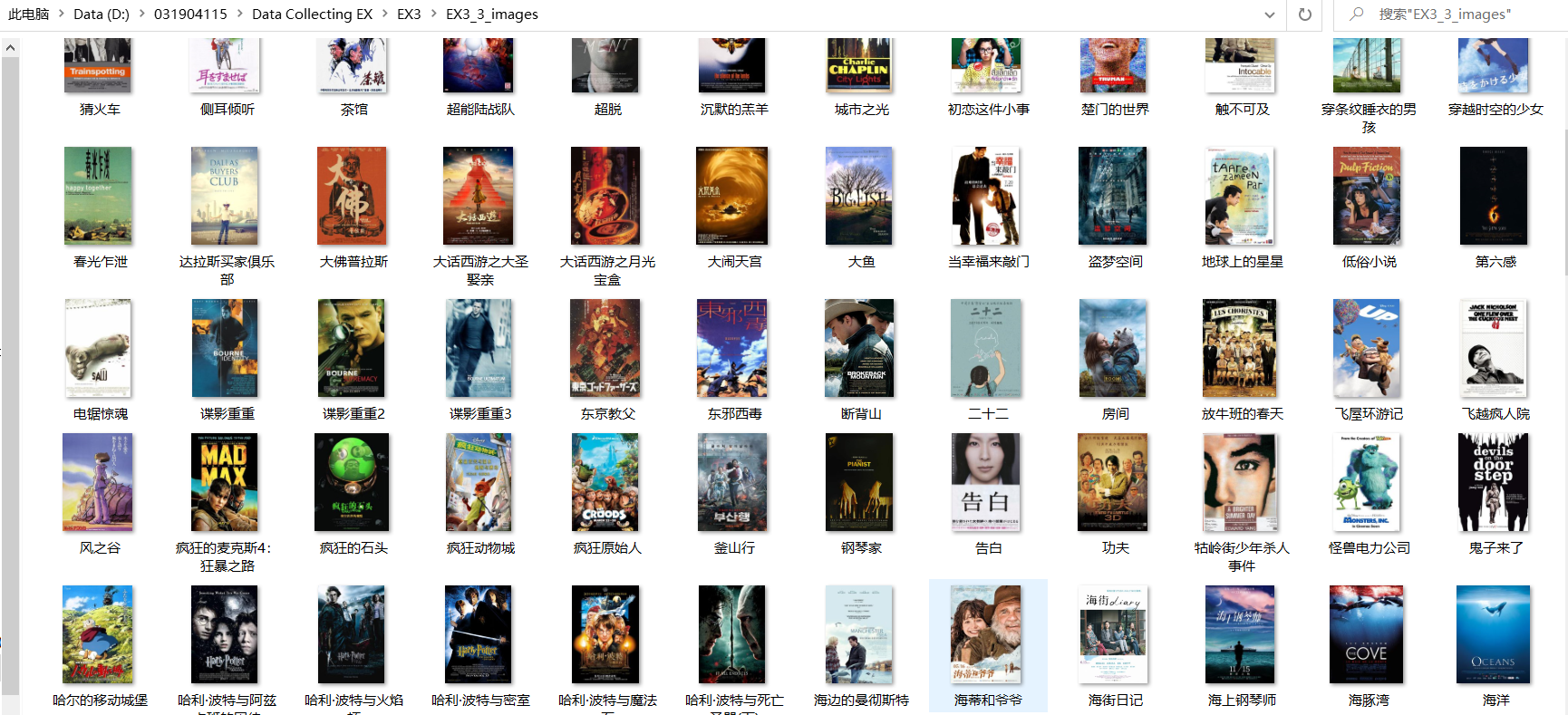
2) Experience:
Homework ③ basically integrates all the crawler knowledge learned before, and it still has a little sense of achievement. It's really a big headache to constantly find mistakes in the process. Fortunately, it has been corrected as much as possible. Of course, there are still many deficiencies. I hope I can be more proficient in completing such tasks in the future.
code
- Code cloud address: https://gitee.com/Poootato/crawl_project